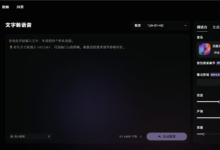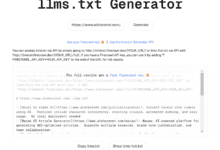
llms.txt Generator:快速抓取网站内容并,生成LLM训练文本数据集
综合介绍 llmstxt-generator 是一个专业的网站内容提取和整合工具,专门为大语言模型(LLM)的训练和推理准备高质量文本数据集。该工具由 Mendable AI 开发,采用 @firecrawl_dev 提供的网页爬虫技术和 GPT-4-mini ...

综合介绍 llmstxt-generator 是一个专业的网站内容提取和整合工具,专门为大语言模型(LLM)的训练和推理准备高质量文本数据集。该工具由 Mendable AI 开发,采用 @firecrawl_dev 提供的网页爬虫技术和 GPT-4-mini ...

综合介绍 Doc2X 是一款功能强大的文档图片公式识别与转换工具,致力于提供高效智能的文档处理解决方案。无论是学术科研论文、教辅书籍、企业文档还是财报研报,Doc2X 都能精准识别 PDF 中的表格和公式,并一键转...

开启 Builder 智能编程模式,无限量使用 DeepSeek-R1 和 DeepSeek-V3 ,对比海外版体验更加流畅。只需输入中文指令,不懂编程的小白也可以零门槛编写自己的应用。

综合介绍 ExtractThinker 是一个灵活的文档智能工具,利用大型语言模型(LLMs)从文档中提取和分类结构化数据,提供类似 ORM 的无缝文档处理工作流。它支持多种文档加载器,包括 Tesseract OCR、Azure Form Recog...

综合介绍 HtmlRAG是一个创新的开源项目,专注于改进检索增强生成(RAG)系统中的HTML文档处理方法。该项目提出了一种新颖的方法,认为在RAG系统中使用HTML格式比纯文本更有效。项目包含了完整的数据处理流程,从查...
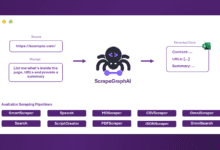
综合介绍 ScrapeGraphAI是一个创新的Python网页抓取库,它巧妙地结合了大语言模型(LLM)和直接图逻辑来创建网站和本地文档的抓取管道。这个工具的独特之处在于它的简单性和强大功能的完美平衡:用户只需描述想要提...

综合介绍 Vision Parse是一个革命性的文档处理工具,它巧妙地结合了最先进的视觉语言模型(Vision Language Models)技术,能够将PDF文档智能转换为优质的Markdown格式内容。该工具支持多种顶级视觉语言模型,包括O...

综合介绍 Outlines 是一个由 dottxt-ai 开发的开源库,旨在通过结构化文本生成来提升大语言模型(LLM)的应用能力。该库支持多种模型集成,包括 OpenAI、transformers、llama.cpp 等,提供简单而强大的提示原语,...

综合介绍 MarkItDown是由微软开发的一个Python工具,旨在将各种文件和办公文档转换为Markdown格式。该工具支持多种文件类型,包括PDF、PowerPoint、Word、Excel、图片(EXIF元数据和OCR)、音频(EXIF元数据和语...

综合介绍 Chunkr 是一个自托管的 API,专门用于将 PDF、PPTX、DOCX 和 Excel 文件转换为适合 RAG(检索增强生成)和 LLM(大语言模型)使用的数据。该项目由 Lumina AI Inc. 开发,利用先进的视觉模型进行文档摄...

综合介绍 GitIngest 是一个开源工具,旨在将 GitHub 代码库转化为适合大语言模型(LLM)提示的文本。通过简单的操作,用户可以将任何 GitHub 仓库的内容提取并格式化为适合 LLM 使用的文本。该工具提供了一键分析...

综合介绍 E2M(Everything to Markdown)是一个开源的Python库,旨在将多种文件格式转换为Markdown格式。该工具支持包括doc、docx、epub、html、htm、url、pdf、ppt、pptx、mp3和m4a在内的多种文件类型。E2M采用...

综合介绍 Docling 是一个强大的文档解析和导出工具,支持多种文档格式,包括 PDF、DOCX、PPTX、XLSX、图像、HTML、AsciiDoc 和 Markdown。它能够将这些文档解析并导出为 HTML、Markdown 和 JSON 格式,支持嵌入和...
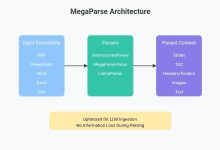
综合介绍 MegaParse 是一个强大且多功能的文件解析工具,专为大语言模型(LLM)的数据处理优化而设计。无论是处理文本、PDF、PowerPoint 演示文稿还是 Word 文档,MegaParse 都能轻松应对,并确保在解析过程中不...
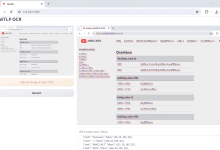
综合介绍 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)是一个开源项目,旨在通过视觉引导的生成文本布局预训练模型提升文档智能处理能力。该项目由Veason-silverbul...

综合介绍 Trieve 是由 Devflow, Inc. 开发的全方位基础设施,专为搜索、推荐、RAG(检索增强生成)和分析而设计。该平台通过 API 提供服务,支持自托管,适用于 AWS、GCP、Kubernetes 和 Docker Compose 等环境。...

综合介绍 pdf2htmlEX 是一个开源工具,旨在将 PDF 文件转换为 HTML 格式,通过分析 PDF 文件的内容并使用 HTML + CSS 精确还原其视觉效果, 将 PDF 文档转换为浏览器中可直接查看的网页。该工具特别适用于包含大量...

综合介绍 Maxun是一个开源的无代码网页数据提取平台,用户可以在几分钟内训练机器人,自动抓取网页数据并将其转换为API或电子表格。该平台支持分页和滚动,能够适应网站布局的变化,提供强大的数据抓取功能,适用...

综合介绍 OmniParse是一个强大的数据解析与优化平台,旨在将任何非结构化数据转换为结构化、可操作的数据,优化后适用于GenAI(生成式人工智能)框架。无论是处理文档、表格、图像、视频、音频文件还是网页内容,...
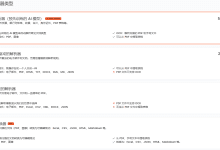
综合介绍 Parsio 是一款基于 AI 技术的文档和邮件数据提取工具,能够自动从 PDF、电子邮件及其他文档中提取结构化数据。该平台提供强大的 PDF 解析器和 OCR 功能,支持多种文档类型,包括发票、名片和身份证件等...