Data Formulator:AI驱动的数据可视化工具
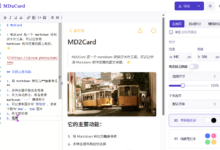
综合介绍 Data Formulator是由微软研究院开发的一款开源AI驱动的数据可视化工具。该工具结合了图形化用户界面(GUI)和自然语言输入(NL),使用户能够通过简单的交互和指令,快速创建和迭代复杂的数据可视化作品...

综合介绍 Data Formulator是由微软研究院开发的一款开源AI驱动的数据可视化工具。该工具结合了图形化用户界面(GUI)和自然语言输入(NL),使用户能够通过简单的交互和指令,快速创建和迭代复杂的数据可视化作品...
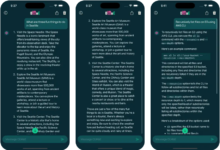
综合介绍 Ai2 OLMoE是由Allen Institute for AI(简称Ai2,艾伦人工智能研究所)开发的一款开源iOS应用,旨在提供完全在设备上运行的AI模型。该应用利用了Ai2的开源OLMoE模型,能够在没有云连接的情况下离线运行...

开启 Builder 智能编程模式,无限量使用 DeepSeek-R1 和 DeepSeek-V3 ,对比海外版体验更加流畅。只需输入中文指令,不懂编程的小白也可以零门槛编写自己的应用。
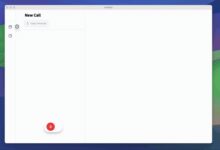
综合介绍 Meetily是一款由Zackriya Solutions开发的AI驱动会议助手,能够实时捕捉会议音频,进行语音转录,并生成会议摘要。其独特之处在于所有处理均在本地设备上完成,确保用户隐私。Meetily适用于希望专注讨论...

综合介绍 DeepSeek-VL2 是一系列高级的 Mixture-of-Experts (MoE) 视觉语言模型,显著提升了其前身 DeepSeek-VL 的性能。该模型在视觉问答、光学字符识别、文档/表格/图表理解和视觉定位等任务中表现出色。DeepSe...

综合介绍 Zonos 是由 Zyphra 开发的一款开源语音合成与语音克隆工具。Zonos-v0.1 版本采用了先进的 Transformer 和混合模型,能够生成高质量的语音输出。该工具支持多种语言,包括英语、日语、中文、法语和德语,...
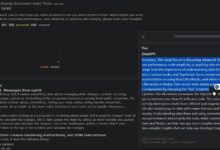
综合介绍 ChatGPT Box 是一个开源的浏览器扩展工具,旨在将 ChatGPT 深度集成到用户的浏览器中。该工具由 josStorer 开发,支持多种语言,并提供多种功能,如在任意页面调用聊天对话框、支持移动设备、右键菜单摘...

综合介绍 WordPress AI助手插件(wp-ai-chat)是一个开源的WordPress插件,旨在为用户提供多种AI功能,包括AI对话、文章生成、文章总结、文章翻译和内容朗读。该插件支持对接多种AI模型,如deepseek、豆包和通义...
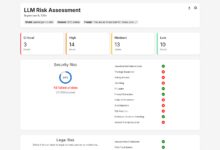
综合介绍 promptfoo 是一个开源的命令行工具和库,专门用于评估和红队测试大语言模型(LLM)应用。它为开发者提供了一套完整的工具,用于构建可靠的提示、模型和基于检索的生成(RAGs),并通过自动化红队测试和...

综合介绍 NoneBot DeepSeek 插件是一个集成了 DeepSeek 模型的 NoneBot 插件,旨在提供智能对话与问答功能。通过接入 DeepSeek 模型,用户可以在 NoneBot 平台上实现多轮对话、深度思考等功能。该插件支持多种安...

综合介绍 Solana Agent Kit是一个开源工具包,旨在将AI智能体与Solana区块链协议无缝连接。无论是AI研究人员还是加密货币开发者,都可以使用任何模型训练的智能体,通过该工具包执行超过60种Solana操作,包括代币...

综合介绍 LiberSonora,寓意“自由的声音”,是一个AI赋能的强大开源有声书工具集。该工具集支持智能字幕提取、AI标题生成、多语言翻译等功能,能够在GPU加速下进行批量离线处理。LiberSonora的设计理念是通过模块...

综合介绍 go-stock 是一个基于 Wails 和 NaiveUI 构建的 AI 赋能股票分析工具。该工具能够实时监控自选股行情,提供成本盈亏展示和涨跌报警推送功能。所有数据均保存在本地,确保用户隐私安全。go-stock 还集成了...
综合介绍 RSS Translator 是一个开源、简洁且可自部署的工具,旨在帮助用户实时翻译和订阅RSS内容。该工具支持多种翻译引擎,包括Google Translate、Microsoft Translate、DeepL等,用户可以根据需要选择合适的翻...

综合介绍 KTransformers:专为突破大模型推理瓶颈而生的高性能 Python 框架。 它不仅仅是一个简单的模型运行工具,更是一套 极致的性能优化引擎 和 灵活的接口赋能平台。 KTransformers 致力于从底层提升大模型推...
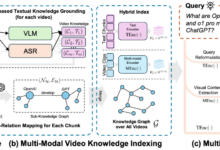
综合介绍 VideoRAG是一个专为处理和理解超长上下文视频而设计的检索增强生成框架。该工具结合了图驱动的文本知识基础和分层多模态上下文编码,能够在单个NVIDIA RTX 3090 GPU上高效处理数百小时的视频内容。Video...

综合介绍 Tifa-Deepsex-14b-CoT 是一个基于 Deepseek-R1-14B 深度优化的大模型,专注于角色扮演、小说文本生成以及思维链(Chain of Thought, CoT)推理能力的提升。该模型通过多阶段训练和优化,解决了原始模型...
综合介绍 Instructor 是一个流行的 Python 库,专为处理大语言模型(LLMs)的结构化输出而设计。它基于 Pydantic 构建,提供了一个简单、透明且用户友好的 API,用于管理数据验证、重试和流式响应。Instructor 每...

综合介绍 MedRAX是一个专为胸部X光片(CXR)分析设计的先进AI智能体。它集成了最先进的CXR分析工具和多模态大语言模型,能够动态处理复杂的医学查询,而无需额外训练。MedRAX通过其模块化设计和强大的技术基础,...

综合介绍 LangBot 是一个基于大模型的即时通信机器人平台,支持多种消息平台和大模型。该平台适配 QQ、微信(企业微信、个人微信)、飞书、Discord、OneBot 等消息平台,并支持 OpenAI GPT、ChatGPT、DeepSeek、D...