Introdução geral
O Vision-is-all-you-need é um projeto inovador de demonstração do sistema RAG (Retrieval Augmented Generation) visual que abre novos caminhos na aplicação da modelagem de linguagem visual (VLM) ao domínio de processamento de documentos. Diferentemente dos métodos tradicionais de fragmentação de texto, o sistema usa diretamente o modelo de linguagem visual para processar as imagens de páginas de arquivos PDF, convertendo-as em formato vetorial para armazenamento. O sistema adota o ColPali como o principal modelo de linguagem visual, juntamente com o banco de dados de vetores QDrant para obter uma recuperação eficiente, e integra o modelo GPT4 ou GPT4-mini para perguntas e respostas inteligentes. O projeto realiza todo o processo, desde a importação de documentos PDF, a conversão de imagens, o armazenamento vetorial até a recuperação inteligente, além de oferecer uma interface API conveniente e uma interface de front-end fácil de usar, o que proporciona uma solução totalmente nova para o campo de processamento inteligente de documentos.
-1")
Endereço de demonstração: https://softlandia-ltd-prod--vision-is-all-you-need-web.modal.run/
Lista de funções
- Incorporação de páginas PDFConverte páginas de um arquivo PDF em imagens e as incorpora como vetores usando um modelo de linguagem visual.
- Armazenamento de banco de dados vetorialUse o Qdrant como um banco de dados vetorial para armazenar vetores de imagens incorporadas.
- Pesquisa de consultasImagem incorporada: O usuário pode consultar vetores semelhantes à imagem incorporada e gerar uma resposta.
- Interface APIInterface de API RESTful: forneça uma interface de API RESTful para facilitar as operações de upload, consulta e recuperação de arquivos.
- Interação de front-end: através de Reagir A interface de front-end interage com a API para proporcionar uma experiência amigável ao usuário.
Usando a Ajuda
Processo de instalação
- Instalação do Python 3.11 ou posterior::
pip install modal
configuração do modal
- Configuração de variáveis de ambiente: Criar um
.enve adicione o seguinte:
OPENAI_API_KEY=sua_openai_api_key
HF_TOKEN=seu_token_huggingface
- exemplo de execução::
modal serve main.py
exemplo de uso
- Carregar arquivos PDFAbra seu navegador, acesse o URL fornecido pelo Modal e adicione o seguinte ao URL
/docs. Clique emPOST /collectionsponto de extremidade, selecioneExperimentepara carregar o arquivo PDF e executá-lo. - Consultar páginas semelhantes: Uso
POST /searchenvia imagens de página e consultas para a API da OpenAI e retorna a resposta.
desenvolvimento front-end
- Instalação do Node.js::
cd frontend
npm install
npm run dev
- Configuração do ambiente de front-endModificação
.env.developmentadicione o URL do backend:
VITE_BACKEND_URL=seu_backend_url
- Front-end de lançamento::
npm run dev
Procedimento de operação detalhado
- Incorporação de páginas PDF::
- fazer uso de
pypdfiumConverta páginas de PDF em imagens. - Passe a imagem para um modelo de linguagem visual (por exemplo, ColPali) para obter o vetor de incorporação.
- Armazena vetores de incorporação no banco de dados de vetores Qdrant.
- fazer uso de
- Pesquisa de consultas::
- O usuário insere uma consulta e o vetor de incorporação da consulta é obtido por meio de um modelo de linguagem visual.
- Pesquise vetores de incorporação semelhantes no banco de dados de vetores.
- A consulta e a melhor imagem correspondente são passadas para um modelo (por exemplo, GPT4o) para gerar uma resposta.
- Uso da API::
- Carregar arquivos PDF: via
POST /collectionsOs pontos de extremidade fazem upload de arquivos. - Consultar páginas semelhantes: por
POST /searchO ponto de extremidade envia uma consulta e obtém uma resposta.
- Carregar arquivos PDF: via
- Interação de front-end::
- Use a interface de front-end do React para interagir com a API.
- Oferece funções de upload de arquivos, entrada de consultas e exibição de resultados.
Artigo de referência: construindo um RAG? Cansado de fazer pedaços? Talvez a visão seja tudo o que você precisa!
-2")
No centro da maioria das soluções modernas de IA generativa (GenAI), há algo chamado RAG O método Retrieval-Augmented Generation (RAG) é frequentemente chamado de "RAG" pelos engenheiros de software no campo da IA aplicada. Os engenheiros de software da área de IA aplicada geralmente se referem a isso como "RAG". Com o RAG, os modelos de linguagem podem responder a perguntas com base nos dados proprietários de uma organização.
A primeira letra R em RAG significa Retrieve (recuperação), referindo-se ao processo de pesquisa. Quando um usuário faz uma pergunta a um robô GenAI, o mecanismo de busca em segundo plano deve encontrar exatamente o material relevante para a pergunta a fim de gerar uma resposta perfeita e sem alucinações. A e G referem-se à entrada dos dados recuperados no modelo de linguagem e à geração da resposta final, respectivamente.
Neste documento, concentramo-nos no processo de recuperação, pois é a parte mais crítica, demorada e desafiadora da implementação de uma arquitetura RAG. Primeiro, exploraremos o conceito geral de recuperação e, em seguida, apresentaremos o mecanismo tradicional de recuperação RAG baseado em pedaços. A segunda metade do artigo se concentra em uma nova abordagem RAG que se baseia em dados de imagem para recuperação e geração.
Uma breve história da recuperação de informações
O Google e outras grandes empresas de mecanismos de busca vêm tentando resolver o problema da recuperação de informações há décadas - "tentando" é a palavra-chave. A recuperação de informações ainda não é tão simples quanto se espera. Um dos motivos é que os seres humanos processam as informações de forma diferente das máquinas. Não é fácil traduzir a linguagem natural em consultas de pesquisa sensatas em diversos conjuntos de dados. Os usuários avançados do Google podem estar familiarizados com todas as técnicas possíveis para manipular o mecanismo de pesquisa. Mas o processo ainda é complicado e os resultados da pesquisa podem ser bastante insatisfatórios.
Com os avanços nos modelos de linguagem, a recuperação de informações passou a ter uma interface de linguagem natural. No entanto, os modelos de linguagem têm um desempenho ruim no fornecimento de informações baseadas em fatos porque seus dados de treinamento refletem um instantâneo do mundo no momento do treinamento. Além disso, o conhecimento é compactado no modelo, e o conhecido problema da ilusão é inevitável. Afinal de contas, os modelos de linguagem não são mecanismos de pesquisa, mas máquinas de raciocínio.
A vantagem de um modelo de linguagem é que ele pode ser fornecido com amostras de dados e instruções e solicitado a responder com base nessas entradas. Isso é ChatGPT e casos de uso típicos para interfaces de IA de conversação semelhantes. Mas as pessoas são preguiçosas e, com a mesma quantidade de esforço, você mesmo poderia ter feito a tarefa. É por isso que precisamos do RAG: podemos simplesmente fazer perguntas a uma solução de IA aplicada e obter respostas com base em informações precisas. Pelo menos, em um mundo de busca perfeita, essa é a situação ideal.
Como funciona a recuperação no RAG tradicional?
Os métodos de pesquisa do RAG são tão variados quanto as próprias implementações do RAG. A pesquisa é sempre um problema de otimização, e não há uma solução genérica que possa ser aplicada a todos os cenários: a arquitetura de IA deve ser adaptada a cada solução específica, seja ela de pesquisa ou outra funcionalidade.
No entanto, a solução de linha de base típica é a chamada técnica de chunking. Nessa abordagem, as informações armazenadas no banco de dados (geralmente documentos) são divididas em pequenos pedaços, aproximadamente do tamanho de um parágrafo. Cada bloco é então convertido em um vetor numérico por meio de um modelo de incorporação associado a um modelo de linguagem. Os vetores numéricos gerados são armazenados em um banco de dados de vetores dedicado.
Uma pesquisa simples em um banco de dados vetorial é implementada da seguinte forma:
- O usuário faz uma pergunta.
- Gerar um vetor de incorporação a partir do problema.
- Realizar pesquisa semântica em um banco de dados vetorial.
- Na pesquisa semântica, a proximidade entre os vetores de perguntas e os vetores no banco de dados é medida matematicamente, levando em conta o contexto e o significado do bloco de texto.
- A pesquisa vetorial retorna, por exemplo, os 10 blocos de texto com maior correspondência.
O bloco de texto recuperado é então inserido no contexto (sugestão) do modelo de linguagem e o modelo é solicitado a gerar a resposta para a pergunta original. Essas duas etapas após a recuperação são as fases A e G do RAG.
As técnicas de fragmentação e outros pré-processamentos antes da indexação podem ter um impacto significativo na qualidade da pesquisa. Há dezenas desses métodos de pré-processamento, e as informações também podem ser organizadas ou filtradas (chamadas de reordenação) após a pesquisa. Além das pesquisas vetoriais, também podem ser usadas pesquisas tradicionais por palavras-chave ou qualquer outra interface de programação para recuperar informações estruturadas. Os exemplos incluem técnicas de texto para SQL ou texto para API para gerar novas consultas SQL ou API com base nas perguntas do usuário. Para dados não estruturados, a pesquisa vetorial e de chunking são as técnicas de recuperação mais comumente usadas.
O chunking tem seus problemas. Lidar com diferentes formatos de arquivos e dados é complicado e é necessário escrever um código de fragmentação separado para cada formato. Embora existam bibliotecas de software prontas para uso, elas não são perfeitas. Além disso, o tamanho dos blocos e as áreas sobrepostas devem ser considerados. Em seguida, você se depara com o desafio de imagens, gráficos, tabelas e outros dados, em que é fundamental compreender as informações visuais e o contexto ao redor (como títulos, tamanhos de fonte e outras dicas visuais sutis). E essas dicas são completamente perdidas nas técnicas de fragmentação.
E se essa fragmentação for completamente desnecessária e a pesquisa for como a de um ser humano navegando em uma página inteira de um documento?
As imagens retêm informações visuais
Os métodos de pesquisa baseados em imagens tornaram-se possíveis devido ao desenvolvimento de modelos multimodais avançados. Um exemplo de solução de IA baseada em dados de imagem é a solução de condução autônoma da Tesla, que depende inteiramente de câmeras. A ideia por trás da abordagem é que os seres humanos percebem seus arredores principalmente por meio da visão.
O mesmo conceito se aplica à implementação do RAG. Ao contrário do chunking, as páginas inteiras são indexadas diretamente como imagens, ou seja, no mesmo formato em que seriam visualizadas por um ser humano. Por exemplo, cada página de um documento PDF é alimentada em um modelo de IA dedicado como uma imagem (por exemplo ColPali), o modelo cria representações vetoriais com base no conteúdo visual e no texto. Esses vetores são então adicionados ao banco de dados de vetores. Podemos nos referir a essa nova arquitetura RAG como a Geração aprimorada de recuperação visual(Vision Retrieval-Augmented Generation, ou V-RAG).
A vantagem dessa abordagem pode ser uma maior precisão de recuperação do que os métodos tradicionais, pois o modelo multimodal gera uma representação vetorial que leva em conta os elementos textuais e visuais. O resultado da pesquisa será as páginas inteiras do documento, que são então alimentadas como imagens em um modelo multimodal avançado, como o GPT-4. O modelo pode se referir diretamente às informações em gráficos ou tabelas.
O V-RAG elimina a necessidade de primeiro extrair estruturas complexas (como diagramas ou tabelas) em texto, depois reconstruir esse texto em um novo formato, armazená-lo em um banco de dados vetorial, recuperá-lo, reordená-lo para formar dicas coerentes e, por fim, gerar respostas. Essa é uma vantagem significativa ao lidar com manuais antigos, documentos com muitas tabelas e qualquer formato de documento centrado no ser humano em que o conteúdo seja mais do que apenas texto simples. A indexação também é muito mais rápida do que os processos tradicionais de detecção de layout e OCR.
-3")
Estatísticas de velocidade de indexação em documentos ColPali
No entanto, a extração de texto de documentos ainda é valiosa e pode ajudar na pesquisa de imagens. No entanto, o chunking logo será uma das muitas opções disponíveis como forma de implementar um sistema de pesquisa com IA.
Visão-RAG na prática: bancos de dados Paligemma, ColPali e Vector
Diferentemente do RAG tradicional baseado em texto, as implementações de V-RAG ainda exigem acesso a modelos especializados e computação de GPU. A melhor implementação de V-RAG é usar um modelo desenvolvido especificamente para essa finalidade ColPali.
O ColPali baseia-se na abordagem de pesquisa multivetorial introduzida pelo modelo ColBERT e pelo modelo de linguagem multimodal Paligemma do Google. O ColPali é um modelo de pesquisa multimodal, o que significa que ele compreende não apenas o conteúdo textual, mas também os elementos visuais de um documento. De fato, os desenvolvedores do ColPali estenderam a abordagem de pesquisa baseada em texto do ColBERT para abranger o domínio visual, utilizando o Paligemma.
Ao criar a incorporação, o ColPali divide cada imagem em uma grade de 32 x 32, com cada imagem tendo aproximadamente 1024 blocos, cada um representado por um vetor de 128 dimensões. O número total de pedaços é 1030, porque cada imagem também é anexada a um token de comando "describe image".
A consulta baseada em texto do usuário é convertida no mesmo espaço de incorporação para comparar os blocos com a parte da consulta no processo de pesquisa. O processo de pesquisa em si é baseado no chamado método MaxSim no este artigo Ele é descrito em detalhes em. Esse método de pesquisa foi implementado em muitos bancos de dados vetoriais que suportam a pesquisa multivetorial.
Vision is All You Need - Demonstração e código do V-RAG
Criamos uma demonstração do V-RAG e o código está disponível no repositório GitHub da Softlandia! visão-é-tudo-o-que-você-precisa Encontre-o em. Você também pode encontrar outras demonstrações da Applied AI em nossa conta!
A execução do ColPali requer uma GPU com muita memória, portanto, a maneira mais fácil de executá-lo é em uma plataforma de nuvem que permita o uso de GPUs. Por esse motivo, escolhemos a excelente plataforma Modal, que torna o uso de GPUs sem servidor simples e econômico.
Diferentemente da maioria das apresentações acadêmicas on-line do Jupyter Notebook, nossa Visão é tudo o que você precisa A demonstração oferece uma experiência prática exclusiva. Você pode clonar o repositório, implantá-lo você mesmo e executar o pipeline completo em GPUs na nuvem em minutos e gratuitamente. Esse exemplo de engenharia de IA de aplicativos de ponta a ponta se destaca por fornecer uma experiência do mundo real que a maioria das outras demonstrações não consegue igualar.
Nessa demonstração, também usamos o Qdrant A versão em memória do Qdrant. Observe que, ao executar a demonstração, os dados indexados desaparecem depois que o contêiner subjacente deixa de existir. O Qdrant oferece suporte à pesquisa multivetorial desde a versão 1.10.0. A demonstração suporta apenas arquivos PDF, cujas páginas são convertidas em imagens usando a biblioteca pypdfium2. Além disso, usamos a biblioteca de transformadores e o colpali-engine criado pelos desenvolvedores do ColPali para executar o modelo ColPali. Outras bibliotecas, como a opencv-python-headless (que, a propósito, é meu trabalho), também estão em uso.
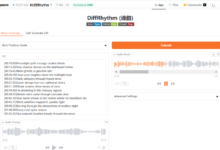
A demonstração fornece uma interface HTTP para indexar e fazer perguntas. Além disso, criamos uma interface de usuário simples usando o React. A UI também visualiza cada Token do mapa de atenção, facilitando a visualização das partes da imagem que o modelo ColPali considera importantes.
 -4")
Capturas de tela da demonstração Vision is All You Need
A visão é realmente o que você precisa?
Apesar do título da demonstração, os modelos de pesquisa como o ColPali ainda não são suficientemente bons, especialmente para dados multilíngues. Esses modelos geralmente são treinados em um número limitado de exemplos, que quase sempre são arquivos PDF de algum tipo específico. Como resultado, a demonstração só é compatível com arquivos PDF.
Outro problema é o tamanho dos dados da imagem e os embeddings computados a partir deles. Esses dados ocupam um espaço considerável e a pesquisa em grandes conjuntos de dados consome muito mais poder computacional do que as pesquisas tradicionais de vetores unidimensionais. Esse problema pode ser parcialmente resolvido com a quantificação dos embeddings em formas menores (até mesmo binárias). No entanto, isso leva à perda de informações e a uma pequena redução na precisão da pesquisa. Em nossa demonstração, a quantificação ainda não foi implementada, pois a otimização não é importante para a demonstração. Além disso, é importante observar que O Qdrant ainda não oferece suporte direto a vetores binários.Mas pode Habilitando a quantificação na Qdranto Qdrant otimizará os vetores internamente. No entanto, ainda não há suporte para o MaxSim baseado na distância de Hamming.
Por esse motivo, ainda é recomendável que a filtragem inicial seja feita em conjunto com pesquisas tradicionais baseadas em palavras-chave antes de usar o ColPali para a recuperação final da página.
Os modelos de pesquisa multimodal continuarão a evoluir, assim como os modelos de incorporação que tradicionalmente geram incorporação de texto. Tenho certeza de que a OpenAI ou uma organização semelhante lançará em breve um modelo de incorporação do tipo ColPali que elevará a precisão da pesquisa a um novo patamar. No entanto, isso derrubará todos os sistemas atuais baseados em chunking e métodos tradicionais de pesquisa vetorial.
Sem uma arquitetura de IA flexível, você ficará para trás
Modelos de linguagem, métodos de pesquisa e outras inovações estão sendo lançados em um ritmo acelerado no espaço da IA. Mais importante do que essas inovações em si é a capacidade de adotá-las rapidamente, o que proporciona uma vantagem competitiva significativa para as empresas que são mais rápidas do que seus concorrentes.
A arquitetura de IA do seu software, incluindo a função de pesquisa, deve, portanto, ser flexível e escalonável para que possa se adaptar rapidamente às mais recentes inovações tecnológicas. À medida que o desenvolvimento se acelera, é fundamental que a arquitetura central do seu sistema não se limite a uma única solução, mas ofereça suporte a uma gama diversificada de métodos de pesquisa, seja a pesquisa tradicional de texto, a pesquisa de imagens multimodais ou até mesmo modelos de pesquisa totalmente novos.
O ColPali é apenas a ponta do iceberg para o futuro. As soluções RAG do futuro combinarão várias fontes de dados e tecnologias de pesquisa, e somente uma arquitetura ágil e personalizável permitirá sua integração perfeita.
Para resolver esse problema, oferecemos os seguintes serviços:
- Avalie o estado de sua arquitetura de IA existente
- Mergulhe fundo nas tecnologias de IA com seus líderes técnicos e desenvolvedores, incluindo detalhes em nível de código
- Examinamos os métodos de pesquisa, o dimensionamento, a flexibilidade arquitetônica, a segurança e se a IA (generativa) está sendo usada de acordo com as práticas recomendadas
- Sugere melhorias e lista as próximas etapas específicas para o desenvolvimento
- Implementar um recurso de IA ou uma plataforma de IA como parte de sua equipe
- Engenheiros de IA de aplicativos dedicados garantem que seus projetos de IA não fiquem para trás em relação a outras tarefas de desenvolvimento
- Desenvolvimento de produtos de IA como uma equipe terceirizada de desenvolvimento de produtos
- Fornecemos soluções completas baseadas em IA do início ao fim
Ajudamos nossos clientes a obter uma vantagem competitiva significativa, acelerando a adoção da IA e garantindo sua integração perfeita. Se estiver interessado em saber mais, entre em contato conosco para discutir como podemos ajudar sua empresa a permanecer na vanguarda do desenvolvimento da IA.