Modelo de geração de imagens CogView4, anunciado como código aberto!


Uma fusão de arte clássica chinesa e elementos modernos, esta imagem é inspirada na obra A Thousand Miles of Rivers and Mountains (Mil milhas de rios e montanhas), do pintor da dinastia Song do Norte Wang Ximeng. A imagem mostra um magnífico rolo de paisagem, com a técnica de paisagem verde resultando em colinas ondulantes e vastos rios, camadas ricas de cores e detalhes requintados. No topo dessa paisagem pitoresca, um caractere de pincel "CogView4" aparece sutilmente, com uma fonte forte e poderosa, e a tinta está no tom certo, como se fosse uma pincelada improvisada feita por um antigo literato enquanto apreciava a paisagem. As palavras "CogView4" complementam a paisagem ao redor, não sendo nem muito abruptas nem muito harmoniosas, mas acrescentando uma sensação de diálogo entre o tempo e o espaço. A imagem inteira tem o sabor da paisagem clássica, mas também incorpora elementos da tecnologia moderna, apresentando uma tensão artística única, permitindo que as pessoas apreciem a estética tradicional e, ao mesmo tempo, sintam a colisão e a fusão da criatividade moderna.
Hoje lançamos oficialmente e abrimos o código-fonte de nosso mais recente modelo de geração de imagens, o CogView4.
O modelo tem recursos avançados de alinhamento semântico complexo e de acompanhamento de comandos, suporta entradas bilíngues de comprimento arbitrário, gera imagens de resolução arbitrária dentro de um determinado intervalo e tem recursos avançados de geração de texto. O modelo também é o primeiro modelo de geração de imagens a ter o código aberto sob o protocolo Apache 2.0.
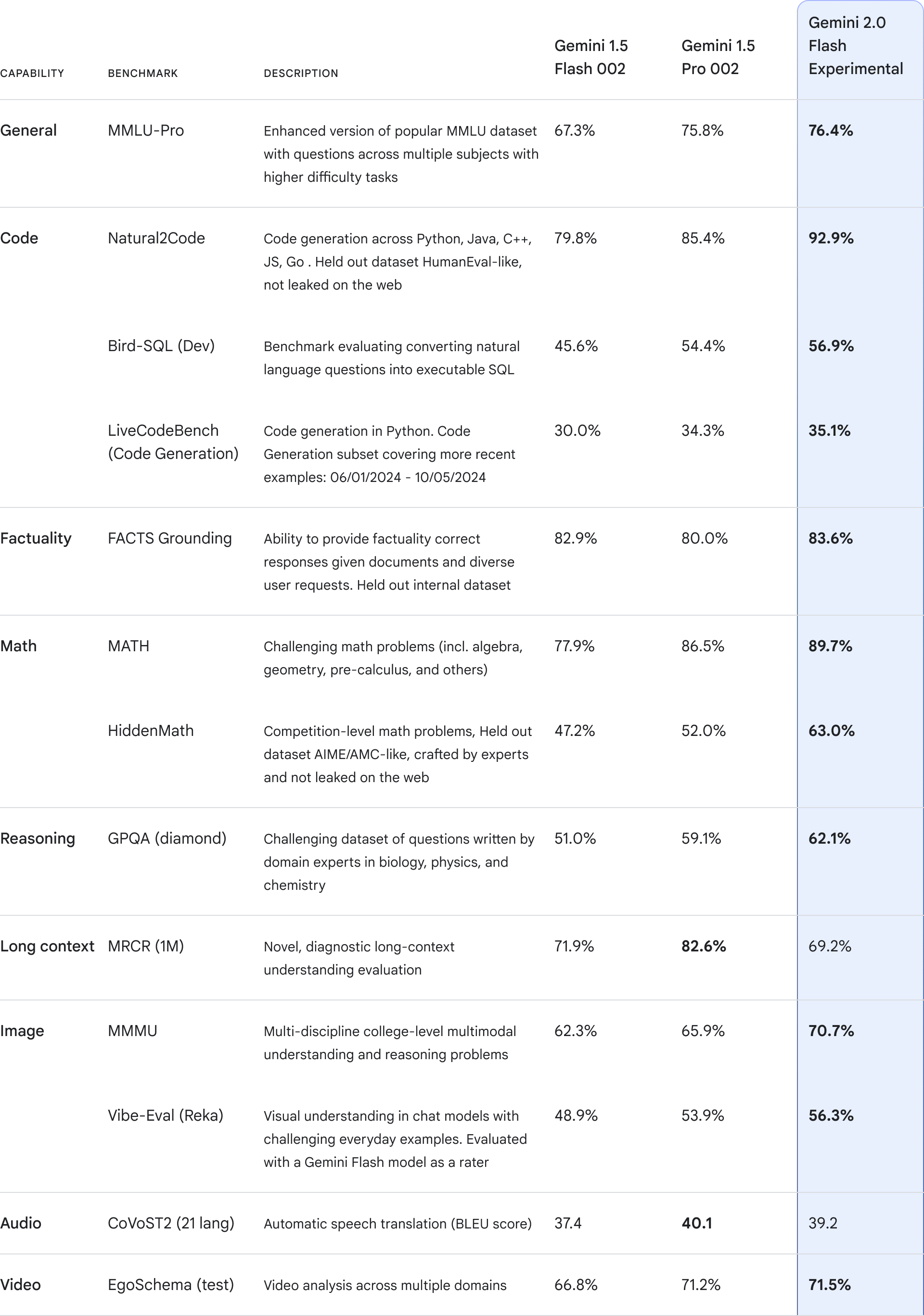
I. Avaliação
O DPG-Bench (Dense Prompt Graph Benchmark) é um teste de referência para avaliar modelos de geração de texto para imagem, com foco no desempenho dos modelos em termos de alinhamento semântico complexo e recursos de acompanhamento de instruções.
CogView4-6B, que tem a pontuação geral nº 1 no benchmark DPG-Bench e atinge o SOTA no modelo gráfico Vincennes de código aberto.
II. comprimento arbitrário e resolução arbitrária
O modelo CogView4 implementa um paradigma de treinamento híbrido de descrições de texto de comprimento arbitrário e imagens de resolução arbitrária.
1、Codificação da posição da imagem
O CogView4 usa a codificação de posição rotacional 2D (2D RoPE) para modelar as informações de posição de uma imagem e oferece suporte a tarefas de geração de imagens em diferentes resoluções por meio da interpolação da codificação de posição.
2. modelagem de geração de difusão
O modelo é modelado usando um esquema de correspondência de fluxo para geração de difusão, combinado com planejamento de ruído dinâmico linear paramétrico para acomodar os requisitos de relação sinal-ruído de imagens de diferentes resoluções.
3、Projeto arquitetônico
Em termos de arquitetura do modelo DiT, o CogView4 dá continuidade à arquitetura Share-param DiT de seu antecessor e projeta camadas LayerNorm adaptativas independentes para as modalidades de texto e imagem separadamente para obter uma adaptação intermodal eficiente.
4. treinamento em vários estágios
O CogView4 emprega uma estratégia de treinamento em vários estágios que inclui treinamento de resolução de base, treinamento de resolução panorâmica, ajuste fino de dados de alta qualidade e treinamento de alinhamento de preferências humanas. Essa abordagem de treinamento em estágios não apenas abrange uma ampla gama de distribuições de imagens, mas também garante que as imagens geradas sejam altamente agradáveis esteticamente e alinhadas com as preferências humanas.
5. otimização da estrutura de treinamento
Do ponto de vista textual, o CogView4 rompe a limitação do comprimento fixo tradicional de tokens, permitindo limites mais altos de tokens e reduzindo significativamente a redundância de tokens textuais durante o treinamento. Quando o comprimento médio da legenda de treinamento está na faixa de 200 a 300 tokens, o CogView4 reduz a redundância de tokens em cerca de 50% em comparação com o esquema tradicional com 512 tokens fixos e alcança uma melhoria de eficiência de 5% a 30% na fase de treinamento progressivo do modelo.
Do ponto de vista da imagem, o treinamento com resolução mista permite que o modelo ofereça suporte à geração de resolução arbitrária em uma ampla faixa, aumentando consideravelmente a liberdade criativa. A resolução alvo só precisa satisfazer as seguintes condições:
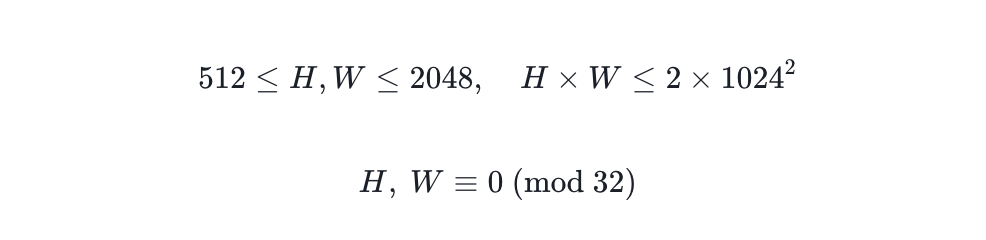
Ambos podem aumentar muito a liberdade criativa.
Exemplo: História extralonga (quadrinhos de quatro painéis)

Princesa: uma mulher humana, bonita e elegante, vestida em um lindo traje de princesa, aprisionada no covil de um monstro.
O rei: um homem humano, majestoso e benevolente, vestido com trajes reais ornamentados e sentado no trono do reino.
Flame Dragon: um monstro coberto de escamas semelhantes a chamas, cuspindo chamas e de tamanho enorme.
Senhor das Trevas: monstro, de tamanho enorme e envolto em escuridão, possui grande poder mágico.
Cena 1: Xiao Ming embarca em uma jornada
Crie uma cena no estilo anime com um magnífico pátio de um reino ao fundo. O personagem principal da cena é Kotomine (um menino humano com um coração corajoso, segurando uma espada e vestindo um traje simples de guerreiro), que é mostrado em uma pose embarcando em sua jornada. Inclui detalhes das flores no pátio e do castelo ao longe, com a luz do sol da manhã transmitindo bravura e determinação. Qualidade: obra-prima, melhor qualidade, superdetalhado, 4k
Cena 2: Ming derrota o Dragão das Chamas
Crie uma cena em estilo anime com uma cratera de fogo ao fundo. O personagem principal da cena é Kotomine (um garoto humano com um coração corajoso, segurando uma espada e vestindo um traje simples de guerreiro), que está no momento da vitória sobre um dragão flamejante. Inclui detalhes das rochas e da lava na cratera, e a iluminação vermelha ardente transmite ferocidade e coragem. Qualidade: obra-prima, melhor qualidade, superdetalhado, 4k
Cena 3: Ming luta contra o Senhor das Trevas!
Crie uma cena em estilo anime com um covil de monstros sombrios ao fundo. O personagem principal da cena é Ming (um garoto humano com um coração corajoso, espada na mão e um traje simples de guerreiro), que está no meio de uma batalha feroz contra o Senhor das Trevas. Inclui detalhes da escuridão e das energias mágicas do covil, e a iluminação sombria transmite intensidade e tensão. Qualidade: obra-prima, melhor qualidade, superdetalhado, 4k
Cena 4: Ming resgata a princesa
Crie uma cena em estilo anime com o interior de um castelo abandonado ao fundo. Os personagens principais da cena são Ming (um garoto humano com coração valente, segurando uma espada e usando um traje simples de guerreiro) e a Princesa (uma mulher humana, bonita e elegante, usando um lindo traje de princesa), que estão na cena emocionante de Ming resgatando a Princesa. Inclui detalhes das ruínas do interior do castelo e iluminação fraca, e a iluminação suave transmite comoção e redenção. Qualidade: obra-prima, melhor qualidade, superdetalhado, 4k
C. Suporte para chinês e inglês
Em termos de implementação técnica, o CogView4 muda o codificador de texto de um codificador T5 somente em inglês para um codificador GLM-4 bilíngue e é treinado com pares de gráficos bilíngues, de modo que o modelo do CogView4 possa inserir palavras de alerta bilíngues.
Até o momento, o CogView4 é o primeiro modelo gráfico de código aberto gerado por texto que suporta a entrada de palavras-chave bilíngues e é especialmente bom para compreender e seguir pistas chinesas e gerar caracteres chineses na tela. Esses dois recursos são mais adequados para uma ampla gama de necessidades criativas em publicidade nacional, vídeos curtos e outros campos.

IV. protocolo Apache
O modelo CogView4-6B é compatível com o protocolo Apache2.0 e, posteriormente, adicionará o ControlNet, o ComfyUI e outros suportes ecológicos; um conjunto completo de ferramentas de ajuste fino estará disponível em breve.
Armazém de modelos:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B
atualizado CogView4 O modelo entrará no ar em 13 de março no chatglm.cn.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...