O Transformer é uma arquitetura de modelo de aprendizagem profunda para processamento de linguagem natural (NLP), proposta por Vaswani et al. em 2017. Ele é usado principalmente para processar tarefas de sequência a sequência, como tradução automática, geração de texto etc.
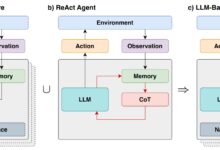
Em termos simples, o modelo Transformer para geração de texto funciona com base no princípio de "prever a próxima palavra".
Com um texto (prompt) do usuário, o modelo prevê qual é a palavra seguinte mais provável. A principal inovação e o poder dos Transformers é o uso do mecanismo de autoatenção, que permite processar sequências inteiras e capturar dependências de longa distância com mais eficiência do que as arquiteturas anteriores (RNNs).
Também digno de nota, huggingface/transformers no GitHub é um repositório da implementação do Transformer pela HuggingFace, incluindo a implementação do Transformer e um grande número de modelos pré-treinados.
Os LLMs atuais são basicamente baseados na arquitetura Transformer, com técnicas de otimização e métodos de treinamento aprimorados.
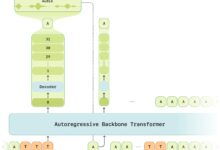
Estrutura do transformador
Cada transformador de geração de texto consiste em três componentes principais:
Camada de incorporação (Embedding) ::
- A entrada de texto é dividida em unidades menores chamadas tokens, que podem ser palavras ou subpalavras.
- Esses elementos léxicos são convertidos em vetores numéricos chamados de embeddings.
- Esses vetores de incorporação capturam o significado semântico das palavras
Bloco do transformador ::
Esse é o componente básico do modelo para processar e transformar os dados de entrada. Cada bloco consiste em:
- Mecanismo de atenção ::
- Componentes principais do bloco do transformador
- Permitir que os elementos lexicais se comuniquem entre si
- Captura de informações contextuais e relações entre palavras
- Camada de Perceptron Multicamada (MLP) ::
- Uma rede de alimentação, que processa cada elemento lexical de forma independente
- O objetivo da camada de atenção é direcionar as informações entre os elementos lexicais
- O objetivo do MLP é otimizar a representação de cada elemento lexical
Probabilidades de saída ::
- Camadas lineares e softmax finais
- Converter embeddings processados em probabilidades
- Permite que o modelo preveja o próximo elemento lexical na sequência
Benefícios do transformador:
- paralelização Ao contrário dos RNNs, os Transformers não precisam processar dados sequencialmente, portanto, podem usar melhor as GPUs para computação paralela e aumentar a velocidade de treinamento.
- dependência de longa distância O mecanismo de autoatenção permite que o Transformer capture eficientemente dependências de longo alcance em sequências.
- destreza Transformer: O Transformer pode ser facilmente dimensionado para modelos maiores (por exemplo, BERT, GPT etc.) e tem bom desempenho em várias tarefas de PNL.
Desvantagens do transformador:
- Alta complexidade computacional A complexidade computacional do mecanismo de autoatenção é O(n^2), que consome mais recursos computacionais quando o comprimento da sequência de entrada é longo.
- Alta demanda por dados Transformadores: Os transformadores geralmente exigem uma grande quantidade de dados para treinamento, a fim de explorar totalmente seu desempenho.
- Falta de informações intrínsecas sobre a sequência Como não há um mecanismo de processamento de sequência incorporado (por exemplo, etapas de tempo em RNNs), são necessários mecanismos adicionais (por exemplo, codificação de posição) para introduzir informações de sequência.
Refs
A primeira dessas duas referências é o artigo clássico sobre transformadores, Attention Is All You Need (Atenção é tudo o que você precisa). Foi esse artigo que propôs o transformador pela primeira vez.
A segunda é uma explicação visual do transformador, para que você possa ver a estrutura interna do transformador.