2025 acabou de começar e a geração de vídeos com IA está prestes a ter um avanço tecnológico?
Nesta manhã, o modelo de geração de vídeo Tongyi Wanphase da Ali anunciou uma grande atualização para a versão 2.1.
Há duas versões do modelo recém-lançado, que sãoTomix 2.1 Extreme e Professional, sendo que o primeiro se concentra no alto desempenho e o segundo visa à alta expressividade..
De acordo com a introdução, Tongyi Wanxiang atualizou de forma abrangente o desempenho geral do modelo desta vez, especialmente no processamento de movimentos complexos, restaurando as leis físicas reais, aprimorando a textura do filme e otimizando as instruções a serem seguidas, o que abre uma nova porta para a criação artística da IA.
Vamos dar uma olhada no efeito de geração de vídeo e ver se ele pode surpreendê-lo.
Vamos começar com o clássico "corte de bife", por exemplo, você pode ver que o grão do bife é claramente visível, a superfície é coberta com uma fina camada de gordura, brilhando, e a lâmina corta lentamente ao longo das fibras musculares, a carne é saliente e cheia de detalhes. 
Prompt: Em um restaurante, um homem está cortando um bife que está fumegando. Em uma tomada aérea em close-up, o homem segura uma faca afiada na mão direita, coloca a faca sobre o bife e corta o centro do bife. A pessoa está vestida de preto com esmalte branco nas mãos, o fundo é bokeh com um prato branco com comida amarela e uma mesa marrom.
Em seguida, observe um efeito de geração de personagem em close-up. A expressão facial da menina, os movimentos das mãos e do corpo são naturais e coordenados, e o vento que passa pelo cabelo também está de acordo com as leis do movimento.

Prompt:Uma linda garota em pé em um arbusto de flores, com as mãos comparadas ao coração e todos os tipos de pequenos corações dançando ao seu redor. Ela está usando um vestido rosa, com seus longos cabelos ao vento e um sorriso doce. O fundo é um jardim de primavera com flores em plena floração e sol brilhante. Fotografia realista em HD, close-up de perto, luz natural suave.
O modelo é forte o suficiente para obter outra pontuação? Atualmente, no VBench Leaderboard, a lista definitiva de análise de geração de vídeo, oO Tongyi Wanxiang atualizado alcançou o topo da lista com uma pontuação total de 84,7%, superando modelos nacionais e internacionais de geração de vídeo, como Gen3, Pika e CausVid... Parece que o cenário competitivo da geração de vídeos passou por outra onda de mudanças.
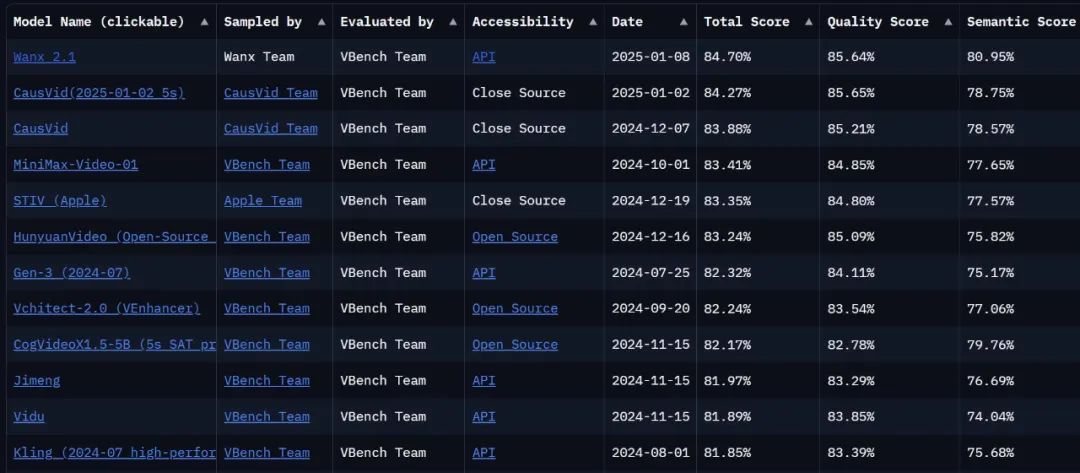
Link para a lista: https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
A partir de agora, os usuários poderão usar a última geração de modelos no site da Tongyi Wanxiang. Da mesma forma, os desenvolvedores também podem chamar a API de modelo grande no AliCloud Bai Lian.
Endereço do site oficial: https://tongyi.aliyun.com/wanxiang/
experiência em primeira mãoMaior expressividade e capacidade de brincar com fontes de efeitos especiais
Nos últimos tempos, houve uma rápida taxa de iteração de modelos grandes para geração de vídeo. A nova versão do Tongyi Wanxiang alcançou um nível de aprimoramento de geração? Fizemos alguns testes no mundo real.
O vídeo de IA agora pode escrever.
Em primeiro lugar, os vídeos gerados por IA podem finalmente dizer adeus ao "ghostwriting".
Anteriormente, o principal modelo de geração de vídeo de IA no mercado não conseguia gerar com precisão chinês e inglês, desde que o local onde o texto deveria estar fosse uma pilha de lixo ilegível. Agora, esse problema do setor foi resolvido pelo Tongyi Wanxiang 2.1.
Tornou-seO primeiro modelo de geração de vídeo com a capacidade de gerar texto em chinês e suportar efeitos de texto em inglês e chinês..
Os usuários agora podem gerar texto e animações com efeitos cinematográficos simplesmente inserindo uma breve descrição de texto.
Por exemplo, um gatinho está digitando na frente de um computador e sete palavras grandes "Work or Eat" (Trabalhar ou comer) aparecem na tela.

No vídeo gerado por Tongyi Wanxiang, o gato senta-se na estação de trabalho e toca o teclado e o mouse de maneira séria, parecendo uma máquina de escrever contemporânea, e as legendas pop-up, juntamente com a trilha sonora gerada automaticamente, dão à imagem toda uma sensação mais espirituosa.
Em seguida, há a palavra em inglês "Synced" (sincronizado) que aparece em uma pequena caixa quadrada laranja.

Seja gerando em chinês ou em inglês, a Tongyi Wanxiang faz tudo certo, sem erros de digitação ou "ghost writing".
Além disso, ele também suporta a aplicação de fontes em uma variedade de cenários queIncluindo fontes de efeitos especiais, fontes de pôsteres e fontes exibidas em cenários reais..
Por exemplo, perto da Torre Eiffel, às margens do Sena, fogos de artifício brilhantes florescem no ar e, à medida que a câmera se aproxima, o número rosa "2025" aumenta gradualmente de tamanho até preencher todo o quadro.

O movimento vigoroso não é mais "assustador"
O movimento complexo de personagens já foi um "pesadelo" para os modelos de geração de vídeo de IA e, no passado, os vídeos gerados por IA tinham mãos e pés voadores, transformavam-se em uma pessoa viva ou mostravam movimentos bizarros de "apenas se virar, mas não virar a cabeça". 
E, por meio da otimização avançada de algoritmos e do treinamento de dados, a Tongyi Wanxiang consegue gerar movimentos estáveis e complexos em vários cenários, especialmente em termos de movimento de membros em grande escala e rotação precisa dos membros, e o breakdancing gerado na imagem acima é muito suave.
Por outro lado, no vídeo gerado abaixo, os movimentos do homem são suaves e naturais à medida que ele corre, sem problemas de indistinção entre as pernas esquerda e direita ou de torção fora de forma. E ele também presta muita atenção aos detalhes, pois cada vez que o homem toca o chão com os dedos dos pés, ele deixa uma marca e levanta levemente a areia fina.

Sugestão: luz dourada do sol sobre o mar cintilante ao pôr do sol, um jovem bonito correndo pela praia, tomada de rastreamento estável.
A cinematografia é comparável à de um mestre do cinema.
O grande diretor Spielberg disse certa vez que o segredo de um bom filme está na linguagem da câmera. Para produzir filmagens impressionantes, os cinegrafistas não gostam de subir ao céu e voar sobre as paredes. 
Mas nesta era da IA, é muito mais fácil "fazer" um filme.
Tudo o que precisamos fazer é inserir um comando de texto simples, como lente esquerda, lente mais distante, avanço da lente etc., e o Tongyi Wanxiang poderáEmite automaticamente um vídeo razoável de acordo com o conteúdo principal do vídeo e as necessidades da câmera..
Digitamos Prompt: banda de rock tocando no gramado da frente, à medida que a câmera avança, ela foca no guitarrista, vestido com uma jaqueta de couro, com seu longo cabelo bagunçado balançando ao ritmo da música. Os dedos do guitarrista saltam rapidamente sobre as cordas enquanto o resto da banda ao fundo dá o seu melhor.

uma visão completa de tudo 2.1 As instruções foram rigorosamente seguidas. O vídeo começa com o guitarrista e o baterista tocando apaixonadamente e, à medida que a câmera se aproxima lentamente, o fundo fica desfocado e diminui o zoom para enfatizar o comportamento do guitarrista e os movimentos das mãos.
Comandos de texto longos não se perdem
Para que os vídeos gerados por IA sejam impressionantes, é essencial que haja instruções de texto precisas.
No entanto, às vezes o modelo grande tem uma memória limitada e, quando confrontado com comandos textuais que contêm várias mudanças de cena, interações de personagens e ações complexas, ele tende a perder o controle dos detalhes ou ficar confuso quanto à ordem lógica.
O novo Tongyi Manxiang é um grande avanço em termos de instruções de texto longo a serem seguidas.
Prompt: Um motociclista acelera em uma rua estreita da cidade a uma velocidade vertiginosa, evitando uma explosão maciça em um prédio próximo, enquanto as chamas rugem violentamente, lançando um brilho laranja brilhante, e detritos e fragmentos de metal voam pelo ar, aumentando o caos na cena. O motociclista, vestido com equipamento de cor escura, curvado e segurando o guidão com firmeza, parecia concentrado enquanto avançava a uma velocidade vertiginosa, sem se deixar abater pelo fogo que se alastrava atrás dele. A espessa fumaça preta deixada pela explosão enche o ar, envolvendo o fundo em um caos apocalíptico. No entanto, o piloto permanece implacável, atravessando o caos com precisão e extrema cinematografia, detalhes ultrafinos, imersão em 3D e ação coerente.

Nessa longa descrição textual acima, as ruas estreitas, as chamas brilhantes, a fumaça negra, os destroços voando e os cavaleiros em equipamentos de cor escura ...... são todos detalhes capturados por Tongyi Manxiang.
Tongyi Wanxiang também tem uma capacidade mais poderosa de combinar conceitos para entender com precisão uma variedade de ideias, elementos ou estilos diferentes e combiná-los para criar um conteúdo de vídeo totalmente novo.
A imagem de um idoso de terno saindo de um ovo e olhando com os olhos arregalados para o idoso de cabelos brancos da câmera é hilária, juntamente com o som de um galo cacarejando.

Especializado em pinturas a óleo de desenhos animados e outros estilos
A nova versão do Tongyi Manphase também gera imagens de vídeo cinematográficas e oferece bom suporte a vários estilos de arte, como desenho animado, cores de cinema, estilos 3D, pinturas a óleo, estilos clássicos e assim por diante.
Veja esse lindo monstrinho animado em 3D em pé em uma videira e dançando.

Prompt: um pequeno monstro titi verde, fofo e feliz, está em um galho de videira cantando alegremente, gire a câmera no sentido anti-horário.
Além disso, ele suporta diferentes proporções, incluindo 1:1, 3:4, 4:3, 16:9 e 9:16, que podem ser melhor adaptadas a diferentes dispositivos finais, como TVs, computadores e telefones celulares. 
A partir do desempenho acima, já podemos fazer algum trabalho criativo usando o Tongyi Manxiang para transformar a inspiração em "realidade".
É claro que essa série de avanços também é atribuída às atualizações do AliCloud no modelo básico de geração de vídeo.
Modelo básico significativamente otimizadoEstrutura, treinamento, avaliação e "transformação" geral.
Em 19 de setembro do ano passado, a AliCloud lançou o modelo de geração de vídeo Tongyi Wanphase na Conferência Yunqi, trazendo a capacidade de gerar vídeos HD de nível cinematográfico e televisivo. Como um modelo de geração visual totalmente desenvolvido pelo AliCloud, ele adota a tecnologia Diffusion + Transformador A arquitetura suporta tarefas de classe de geração de imagem e vídeo e oferece recursos de geração visual líderes do setor com muitas inovações em estruturas de modelos, dados de treinamento, métodos de anotação e design de produtos.
Nesse modelo atualizado, a equipe da Tongyi Wanxiang (doravante denominada equipe) tambémArquiteturas eficientes de VAE e DiT desenvolvidas pelo próprio usuárioO sistema de gerenciamento de dados da empresa, aprimorado para a modelagem de relações contextuais espaço-temporais, otimiza significativamente a geração.
O Flow Matching é uma estrutura emergente para o treinamento de modelos generativos nos últimos anos, que é mais simples de treinar, alcança qualidade comparável ou até melhor do que os modelos de difusão por meio do Continuous Normalising Flow e tem velocidades de inferência mais rápidas, e está sendo gradualmente aplicada ao campo de geração de vídeo. Por exemplo, o modelo de vídeo Movie Gen lançado anteriormente pela Meta usa o Flow Matching.
Para a seleção dos métodos de treinamento, o Tongyi Wanxiang 2.1 usa oEsquema de correspondência de fluxo baseado em trajetórias de ruído lineare foi projetado em profundidade para a estrutura, resultando em melhor convergência do modelo, qualidade de geração e eficiência.
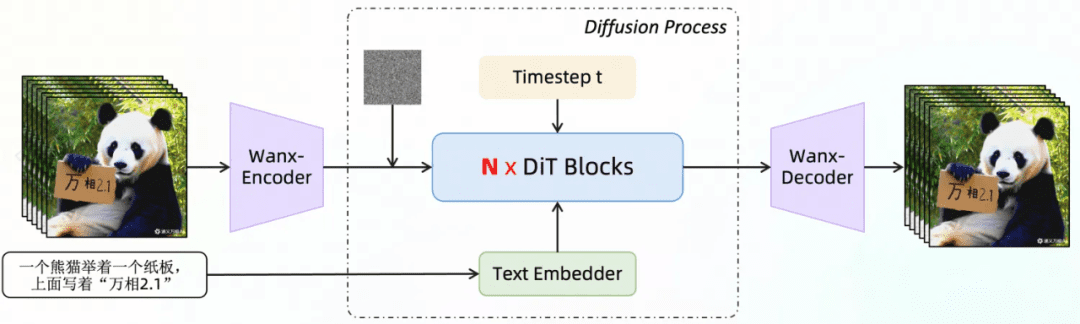
Tongyi Wanxiang 2.1 Diagrama de arquitetura de geração de vídeo
Para o VAE de vídeo, a equipe projetou um esquema inovador de codec de vídeo combinando o mecanismo de cache e a convolução causal.. Entre eles, o mecanismo de cache pode manter as informações necessárias no processamento de vídeo, reduzindo assim a repetição de cálculos e aumentando a eficiência computacional; a convolução causal pode capturar os recursos temporais do vídeo e se adaptar às mudanças incrementais do conteúdo do vídeo.
Em vez do processo direto de decodificação E2E para vídeos longos, a implementação substitui o processo direto de decodificação E2E para vídeos longos, dividindo o vídeo em partes e armazenando em cache os recursos intermediários, de modo que o uso da placa de vídeo esteja relacionado apenas ao tamanho das partes, independentemente da duração do vídeo original, permitindo que o modelo codifique e decodifique com eficiência comprimentos ilimitados de vídeo 1080P. A equipe afirma que essa tecnologia fundamental oferece um caminho viável para o treinamento de vídeos de tamanho arbitrário.
A figura a seguir mostra a comparação dos resultados de diferentes modelos de VAE. Em termos de métricas de eficiência computacional do modelo (quadro/atraso) e de reconstrução da compactação de vídeo (Peak Signal to Noise Ratio, PSNR), o VAE adotado por Tongyi Wanxiang ainda alcança os seguintes resultados sem parâmetros dominantesQualidade de compressão e reconstrução de vídeo líder do setor.
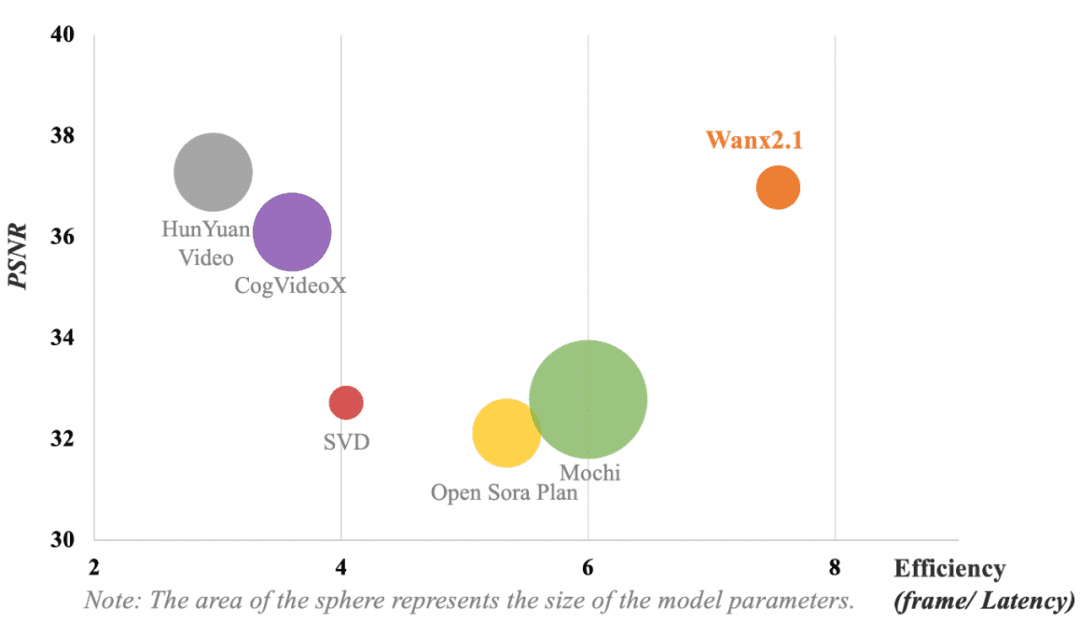
Observação: A área do círculo representa o tamanho do parâmetro do modelo.
A principal meta de design da equipe para o DiT (Diffusion Transformer) era obter recursos avançados de modelagem espaço-temporal e, ao mesmo tempo, manter um processo de treinamento eficiente. Para isso, foram necessárias várias mudanças inovadoras.
Em primeiro lugar, para melhorar a capacidade de modelagem das relações espaço-temporais, a equipe adota um mecanismo de atenção total espaço-temporal, que permite que o modelo simule com mais precisão a dinâmica complexa do mundo real. Em segundo lugar, a introdução do mecanismo de compartilhamento de parâmetros reduz efetivamente o custo de treinamento e melhora o desempenho. Além disso, a equipe otimizou o desempenho da incorporação de texto usando o mecanismo de atenção cruzada para incorporar recursos de texto, o que proporciona melhor controlabilidade do texto e reduz os requisitos de computação.
Graças a esses aprimoramentos e tentativas, a estrutura DiT da Fase Universal generalizada alcança uma superioridade de convergência mais pronunciada com o mesmo custo computacional.
Além das inovações na arquitetura do modelo, a equipeAlgumas otimizações foram feitas nas áreas de treinamento e inferência de sequências ultralongas, pipeline de construção de dados e avaliação de modelos, bem comopermitindo que o modelo lide com eficiência com tarefas geradoras complexas com vantagens de eficiência aprimoradas.
Como treinar de forma eficiente com milhões de sequências ultralongas
Ao lidar com sequências visuais ultralongas, os modelos grandes geralmente enfrentam desafios em vários níveis, como computação, memória, estabilidade de treinamento, latência de inferência e, portanto, soluções eficientes para lidar com eles.
Para isso, a equipe combinou as características da nova carga de trabalho do modelo e o desempenho do hardware do cluster de treinamento para desenvolver uma estratégia de treinamento distribuída e otimizada para a memória a fim de otimizar o desempenho do treinamento sob a premissa de garantir o tempo de iteração do modelo e, por fimObteve MFU líder do setor e treinamento eficiente de 1 milhão de sequências ultralongas.
Por um lado, a equipe inova a estratégia distribuída ao adotar o treinamento paralelo 4D com DP, FSDP, RingAttention e Ulysses, o que melhora o desempenho do treinamento e a escalabilidade distribuída. Por outro lado, para otimizar a memória, a equipe adota uma estratégia de otimização de memória hierárquica para otimizar a memória de ativação e resolver o problema de fragmentação da memória com base no volume de computação e comunicação causado pelo comprimento da sequência.
Além disso, a otimização computacional pode melhorar a eficiência do treinamento de modelos e economizar recursos, de modo que a equipe adota o FlashAttention3 para o cálculo de atenção total espaço-temporal e escolhe a estratégia de CP apropriada para o particionamento combinando o desempenho computacional de clusters de treinamento de diferentes tamanhos. Ao mesmo tempo, a equipe remove a redundância computacional de alguns módulos principais, reduz a sobrecarga de acesso e melhora a eficiência computacional por meio da implementação eficiente do Kernel. Em termos de sistema de arquivos, a equipe faz uso total das características de leitura/gravação do sistema de arquivos de alto desempenho no cluster de treinamento do AliCloud e melhora o desempenho de leitura/gravação por meio do slicing Save/Load.
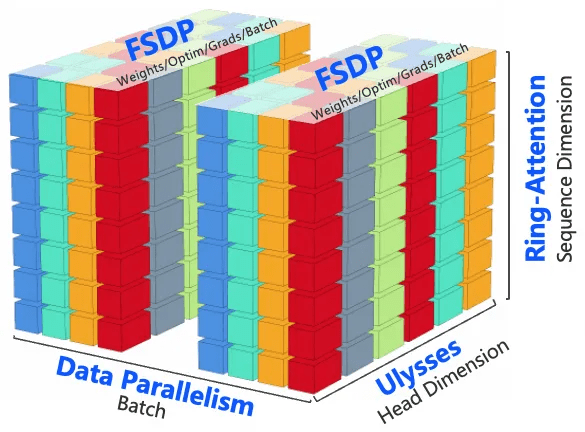
Estratégia de treinamento distribuído paralelo 4D
Ao mesmo tempo, a equipe escolheu um esquema de uso de memória escalonado para resolver os problemas de OOM causados por Dataloader Prefetch, CPU Offloading e Save Checkpoint durante o treinamento. Além disso, para garantir a estabilidade do treinamento, a equipe aproveitou o agendamento inteligente, a detecção de máquinas lentas e os recursos de autocorreção dos clusters de treinamento do AliCloud para identificar automaticamente os nós defeituosos e reiniciar as tarefas rapidamente.
Introdução da automação na construção de dados e na avaliação de modelos
Grandes modelos de geração de vídeo não podem ser treinados sem dados de alta qualidade em escala e avaliação eficaz do modeloO primeiro garante que o modelo aprenda diversos cenários, dependências espaço-temporais complexas e melhore a generalização, formando a base do treinamento do modelo; o segundo ajuda a monitorar o desempenho do modelo para que ele atinja melhor os resultados esperados e serve como um cata-vento para o treinamento do modelo.
Em termos de construção de dados, a equipe criou um pipeline de construção de dados automatizado com alta qualidade como critério, o que é altamente consistente com a distribuição de preferências humanas em termos de qualidade visual, qualidade de movimento etc., de modo que os dados de vídeo de alta qualidade possam ser construídos automaticamente com alta diversidade, distribuição equilibrada e outras características.
Para a avaliação do modelo, a equipe projetou de forma semelhante um conjunto abrangente de métricas automatizadas, incorporando mais de duas dúzias de dimensões, como pontuação estética, análise de movimento e aderência ao comando, além de avaliadores profissionais treinados e direcionados, capazes de se alinhar às preferências humanas. Com o feedback eficaz dessas métricas, o processo de iteração e otimização do modelo foi significativamente acelerado.
Pode-se dizer que as inovações sinérgicas em vários aspectos, como arquitetura, treinamento e avaliação, permitiram que o modelo de geração de vídeo atualizado da Tongyi Wanphase obtivesse melhorias significativas de geração na experiência do mundo real.
Momentos GPT-3 para geração de vídeoPor quanto tempo mais?
Desde fevereiro do ano passado, a equipe da OpenAI Sora Desde sua introdução, o modelo de geração de vídeo se tornou o campo mais competitivo do mundo da tecnologia. De nacionais a estrangeiros, as startups e os gigantes da tecnologia estão lançando suas próprias ferramentas de geração de vídeo. Entretanto, em comparação com a geração de texto, o vídeo com IA tem mais de um nível de dificuldade para atingir o grau de aceitabilidade.
Se, como diz o CEO da OpenAI, Sam Altman, a Sora representa o momento GPT-1 no grande modelo de geração de vídeo, então podemos nos basear nisso para obter o controle preciso dos comandos textuais e a capacidade de ajustar os ângulos e as posições da câmera para garantir a consistência dos personagens. Se nos basearmos nisso para obter um controle preciso da IA com comandos de texto, ângulos e posições de câmera ajustáveis, caracterização consistente e outros recursos de geração de vídeo, e acrescentarmos a capacidade exclusiva da IA de mudar rapidamente estilos e cenas, poderemos ver em breve um novo "momento GPT-3".
Do ponto de vista do caminho do desenvolvimento tecnológico, o modelo de geração de vídeo é um processo de verificação das leis de escala. À medida que a capacidade do modelo básico melhorar, a IA entenderá cada vez mais os comandos humanos e poderá criar ambientes cada vez mais realistas e razoáveis.
Do ponto de vista prático, na verdade, não podemos esperar: desde o ano passado, pessoas que trabalham com vídeos curtos, animação e até mesmo cinema e televisão começaram a usar a IA de geração de vídeo para exploração criativa. Se conseguirmos romper as limitações da realidade e fazer coisas antes inimagináveis com a IA de geração de vídeo, uma nova rodada de mudanças no setor está bem próxima.
Agora parece que Tongyi Manxiang deu o primeiro passo.