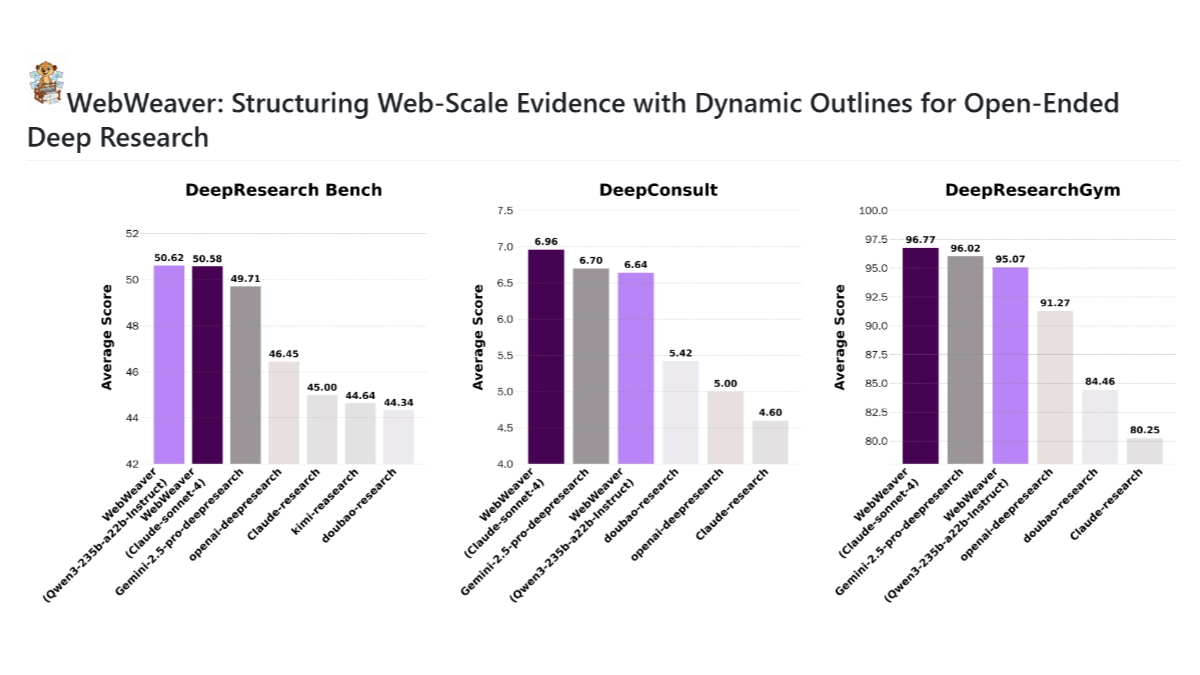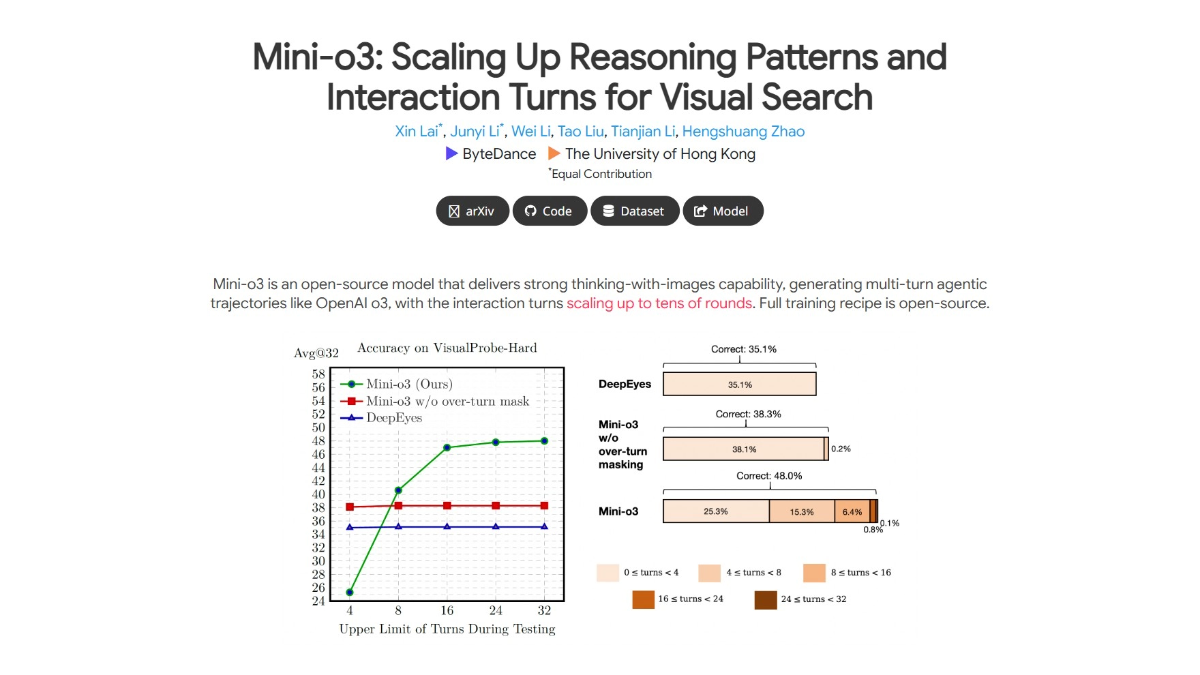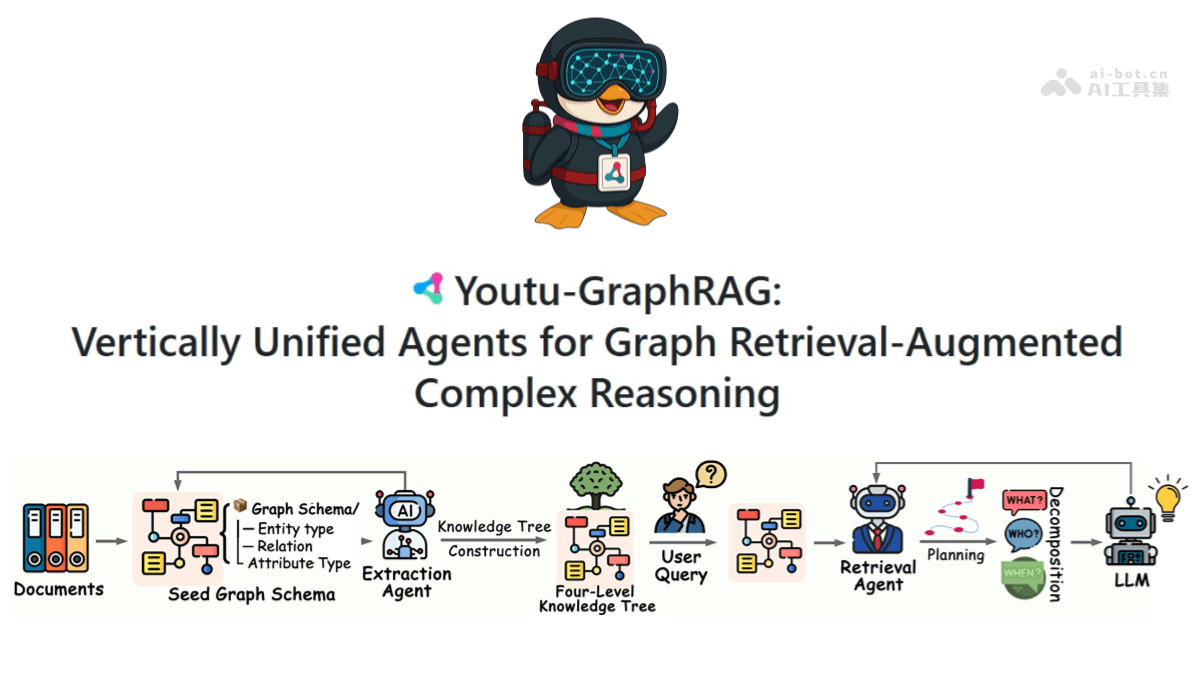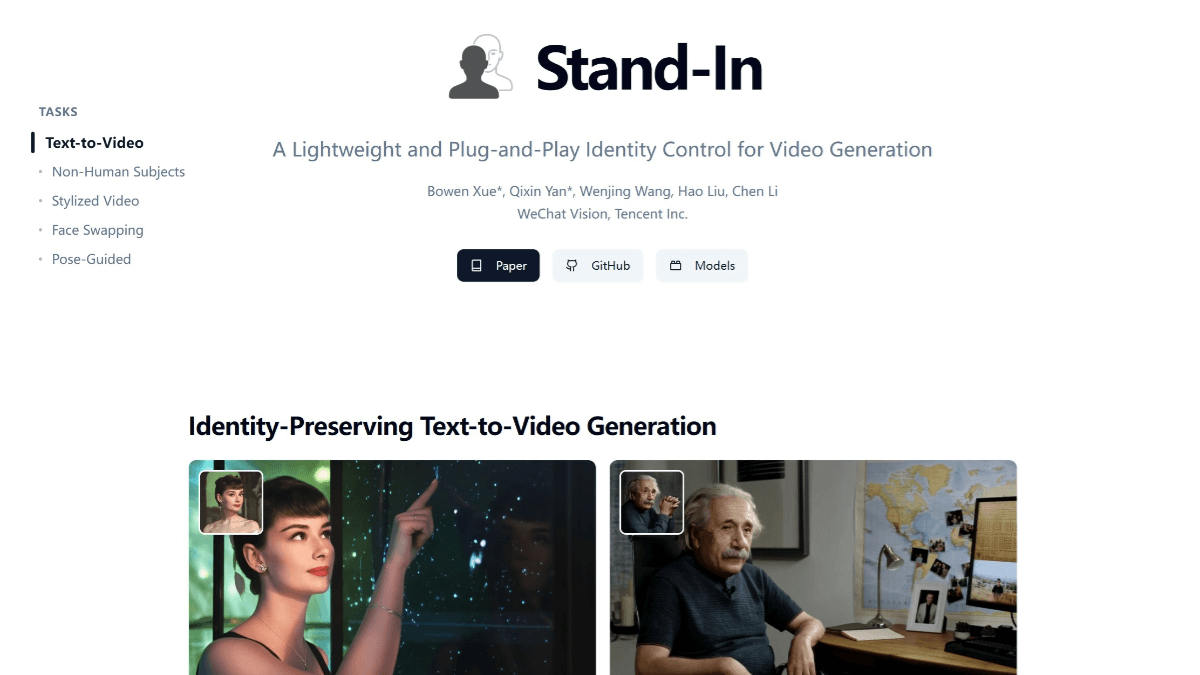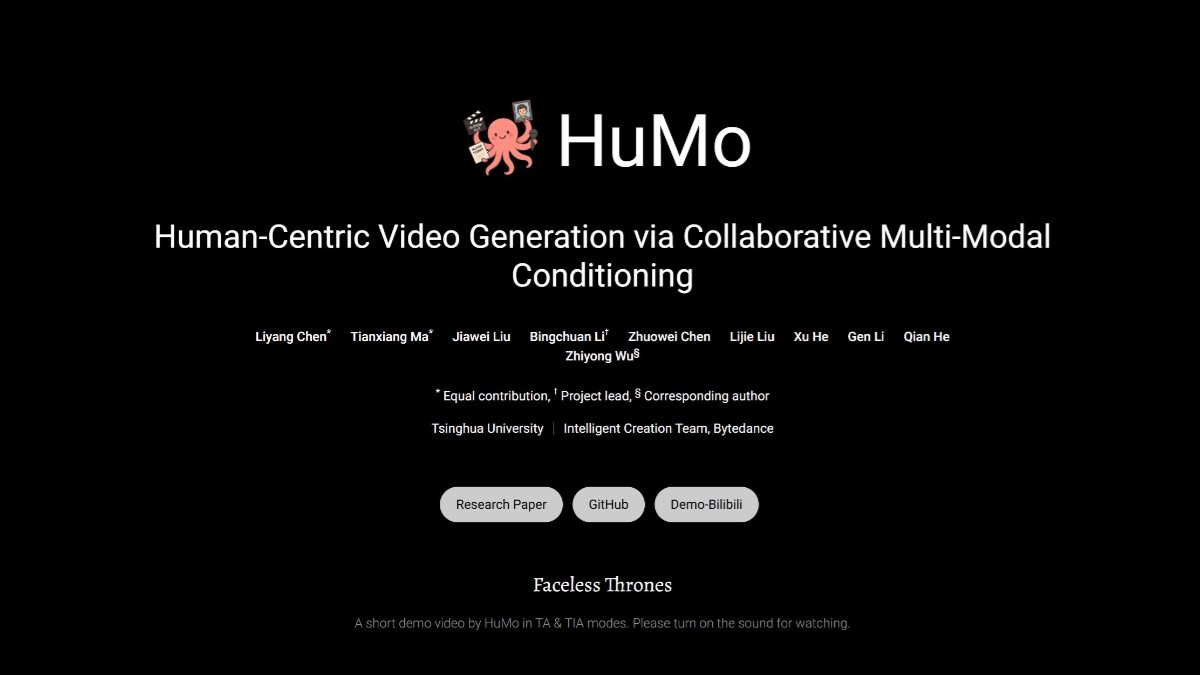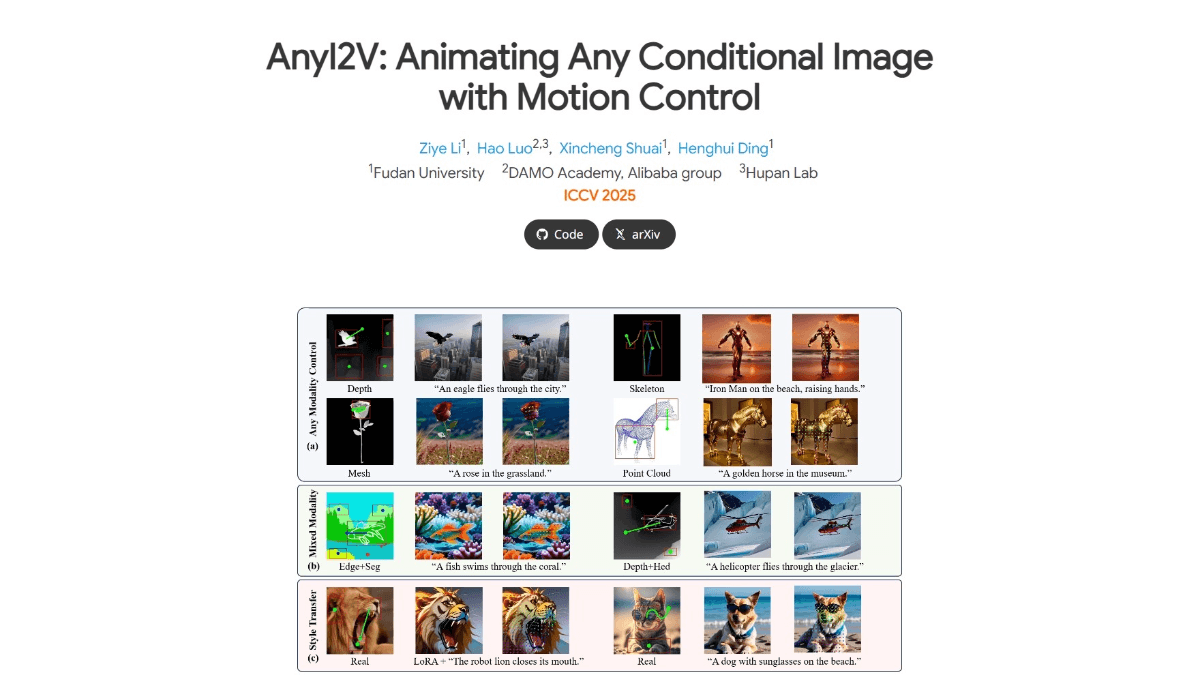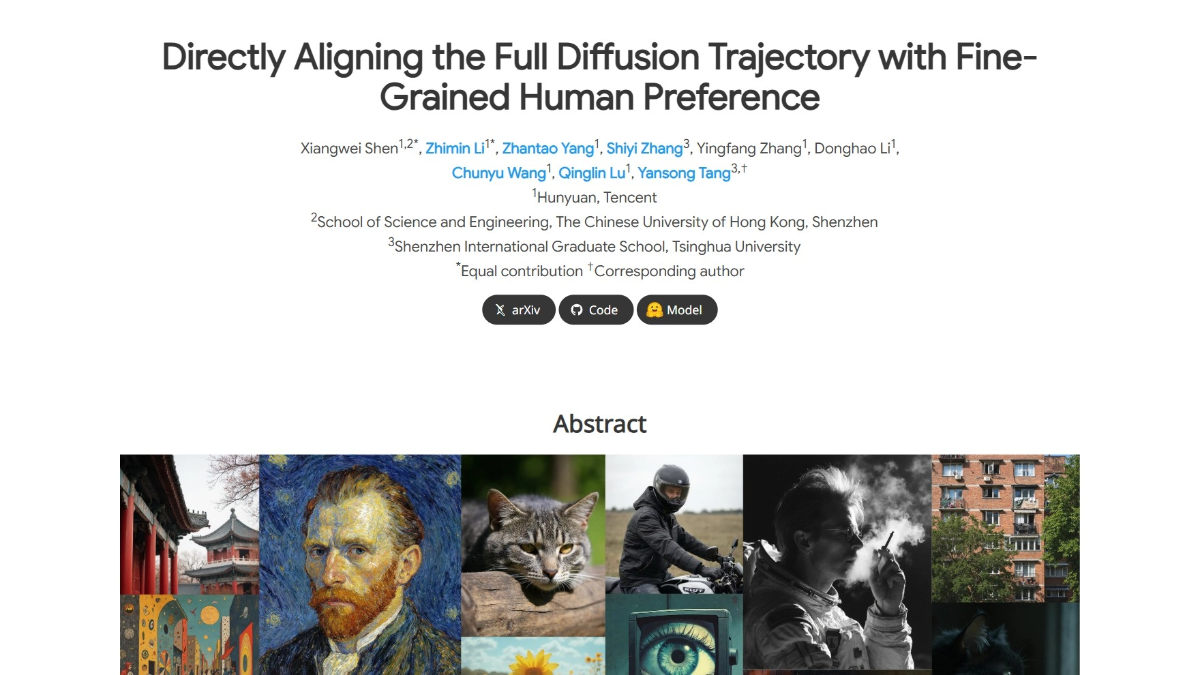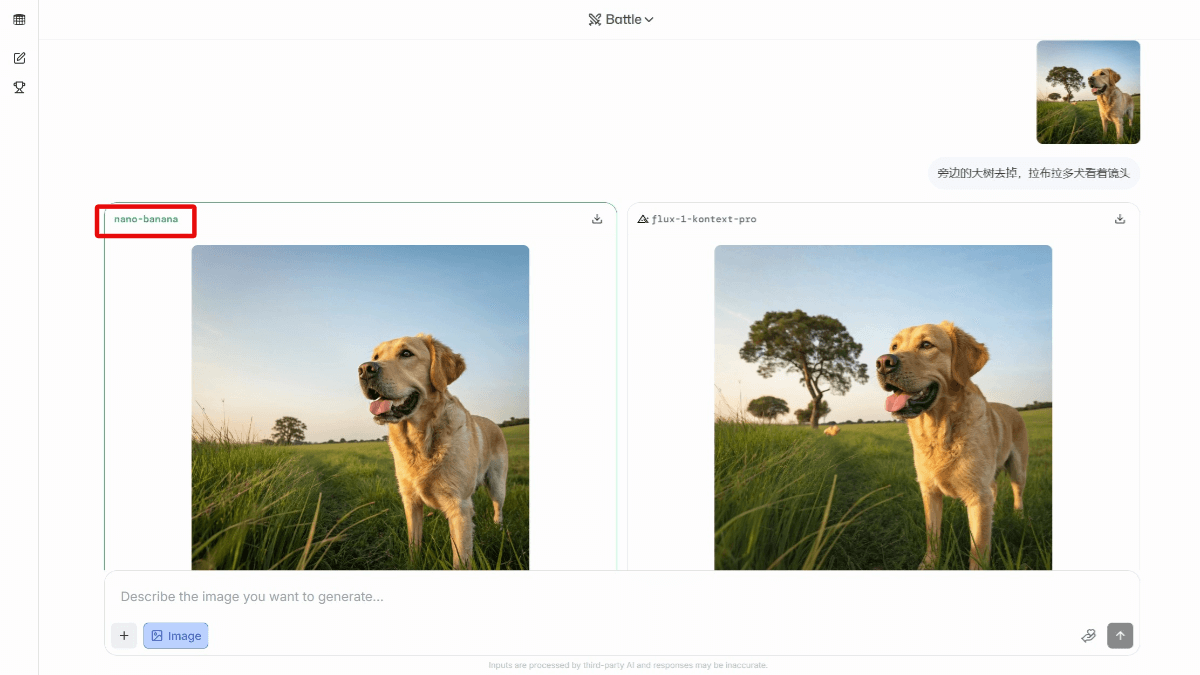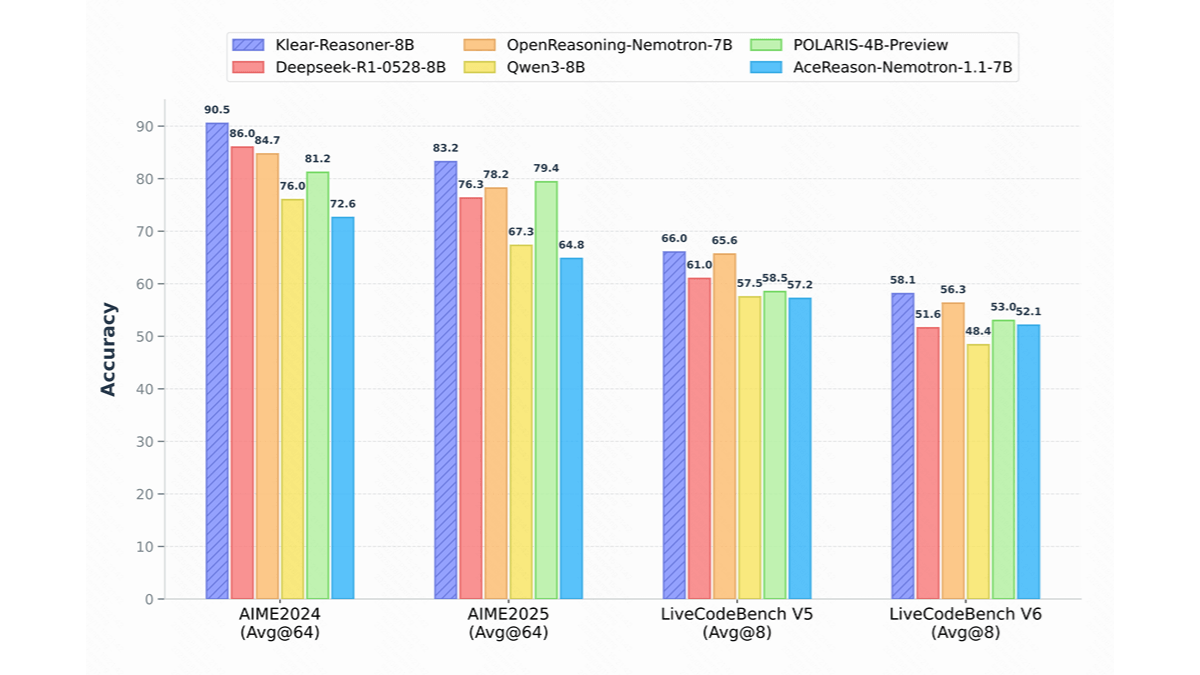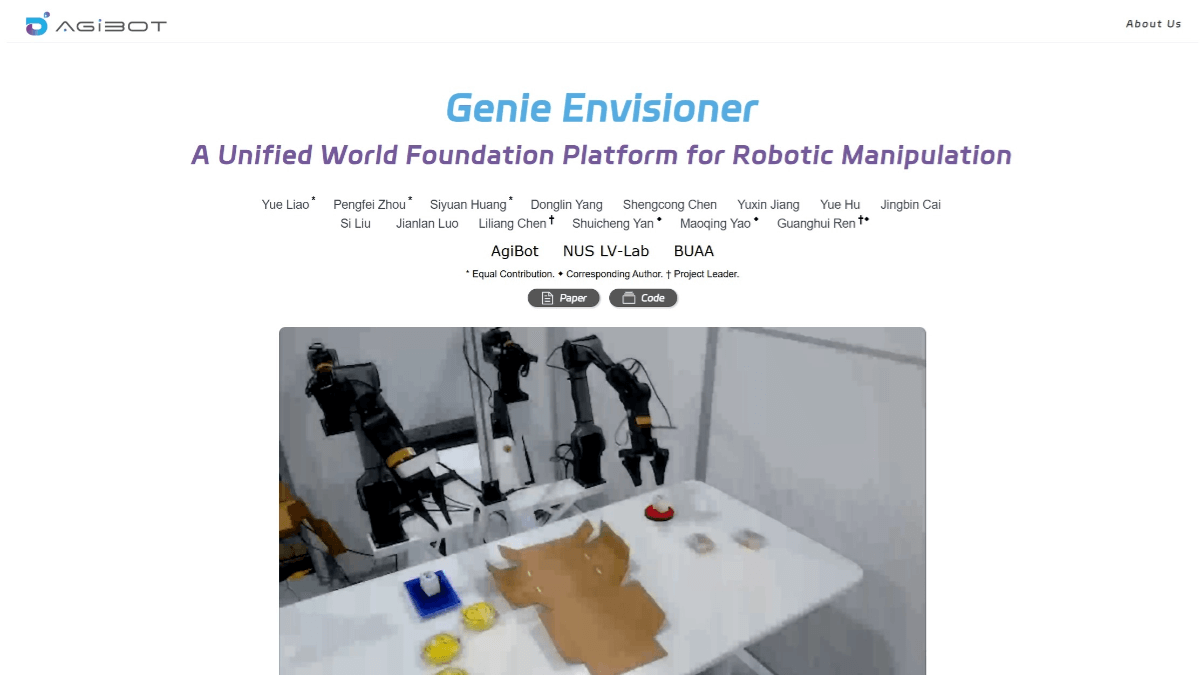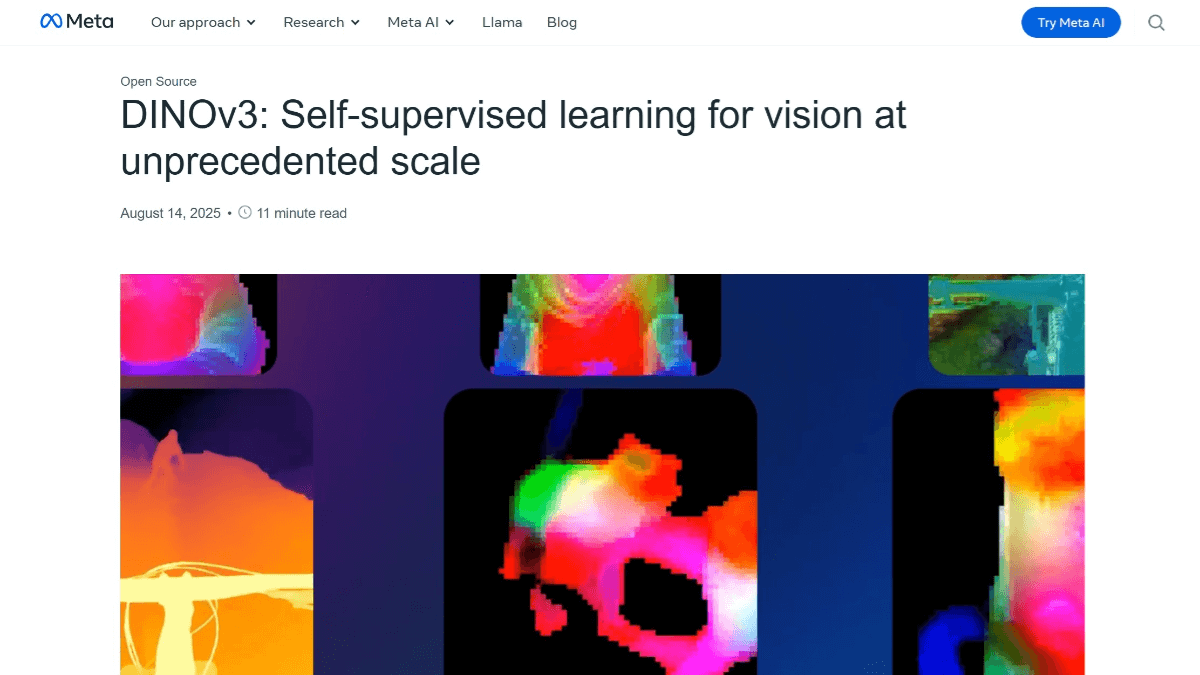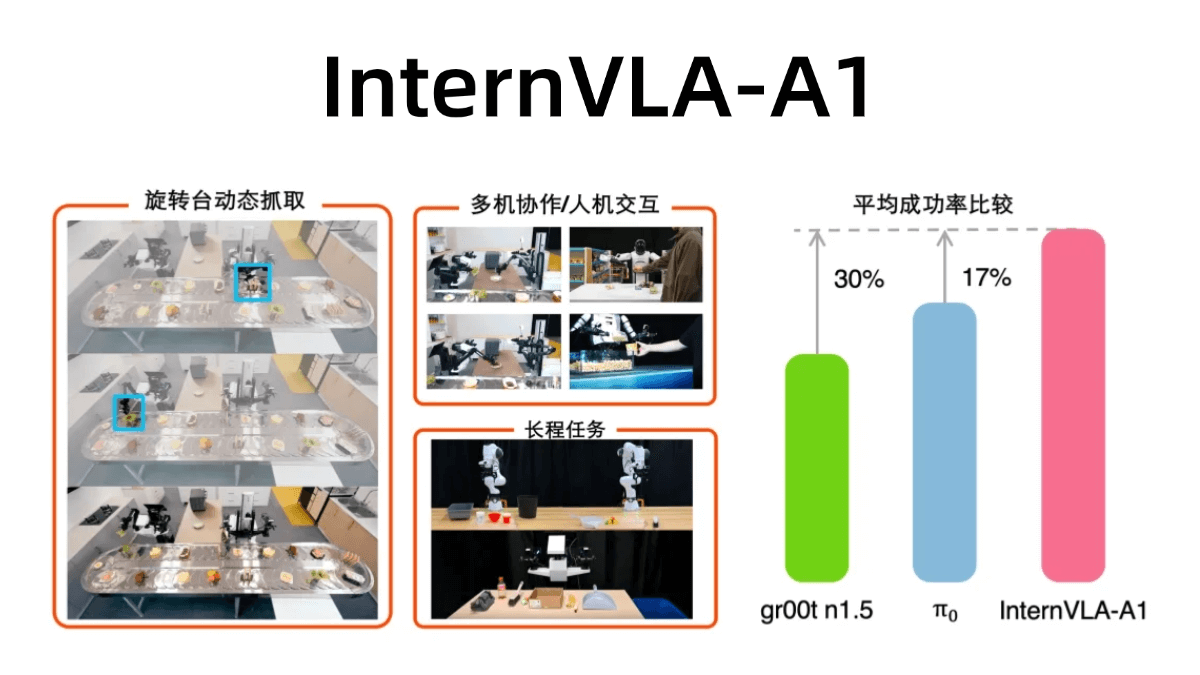
meso (química)InternVLA-A1 - Integração de código aberto do Shanghai AI Lab de recursos operacionais para grandes modelos incorporados
O InternVLA-A1 é um grande modelo de operação incorporada de código aberto do Shanghai Artificial Intelligence Laboratory. Ele tem a capacidade de entender, imaginar e executar a integração, e pode concluir a tarefa com precisão. O modelo funde dados de operação reais e simulados e automatiza a construção de multimodais maciços por meio de ativos de cena híbrida virtual-real em grande escala...