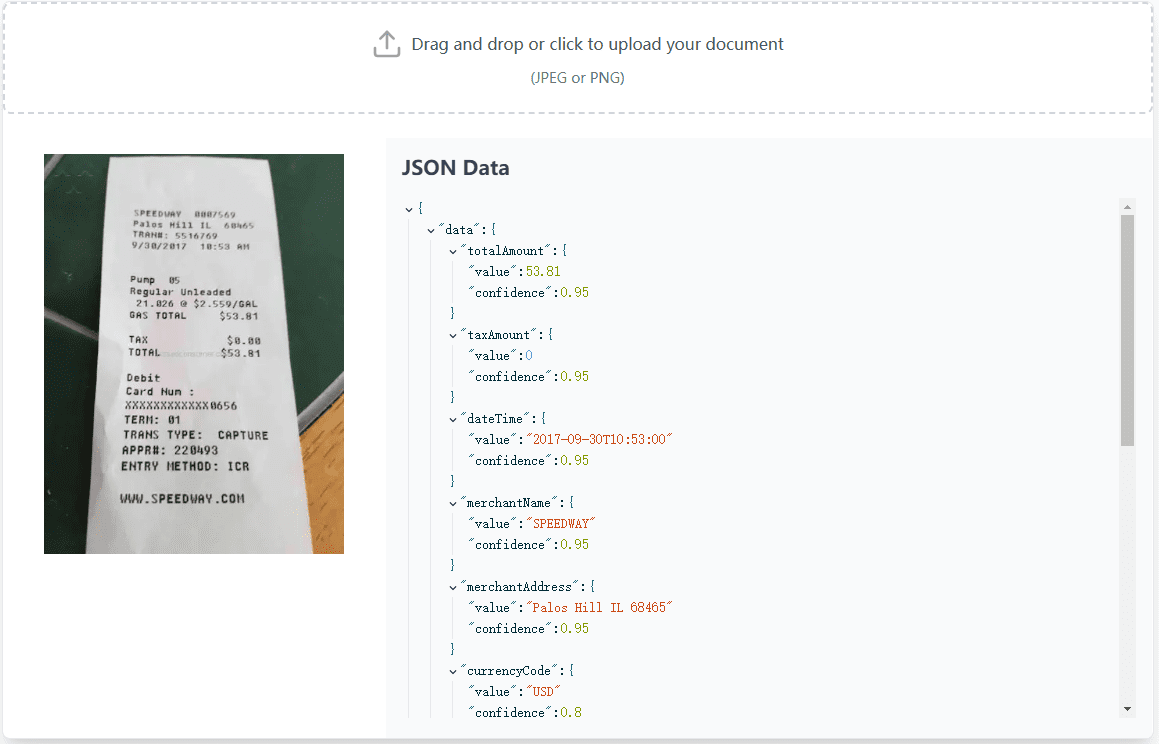
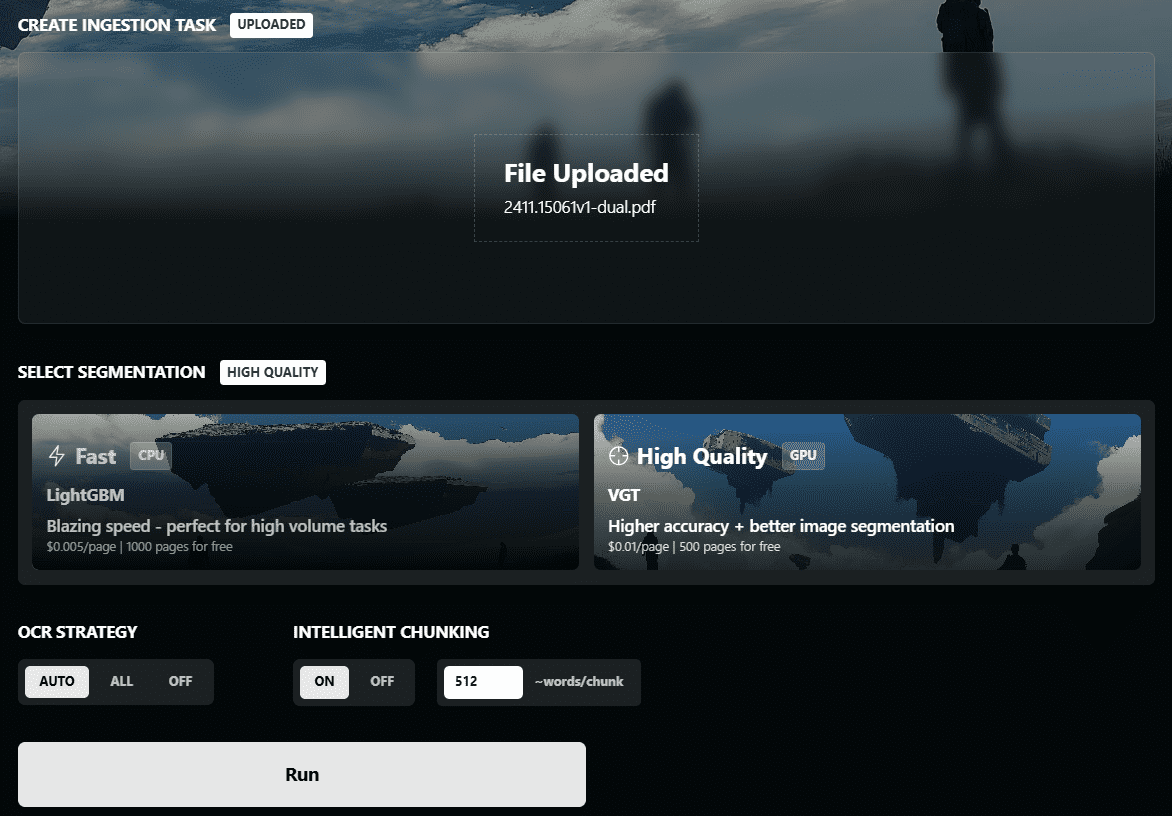
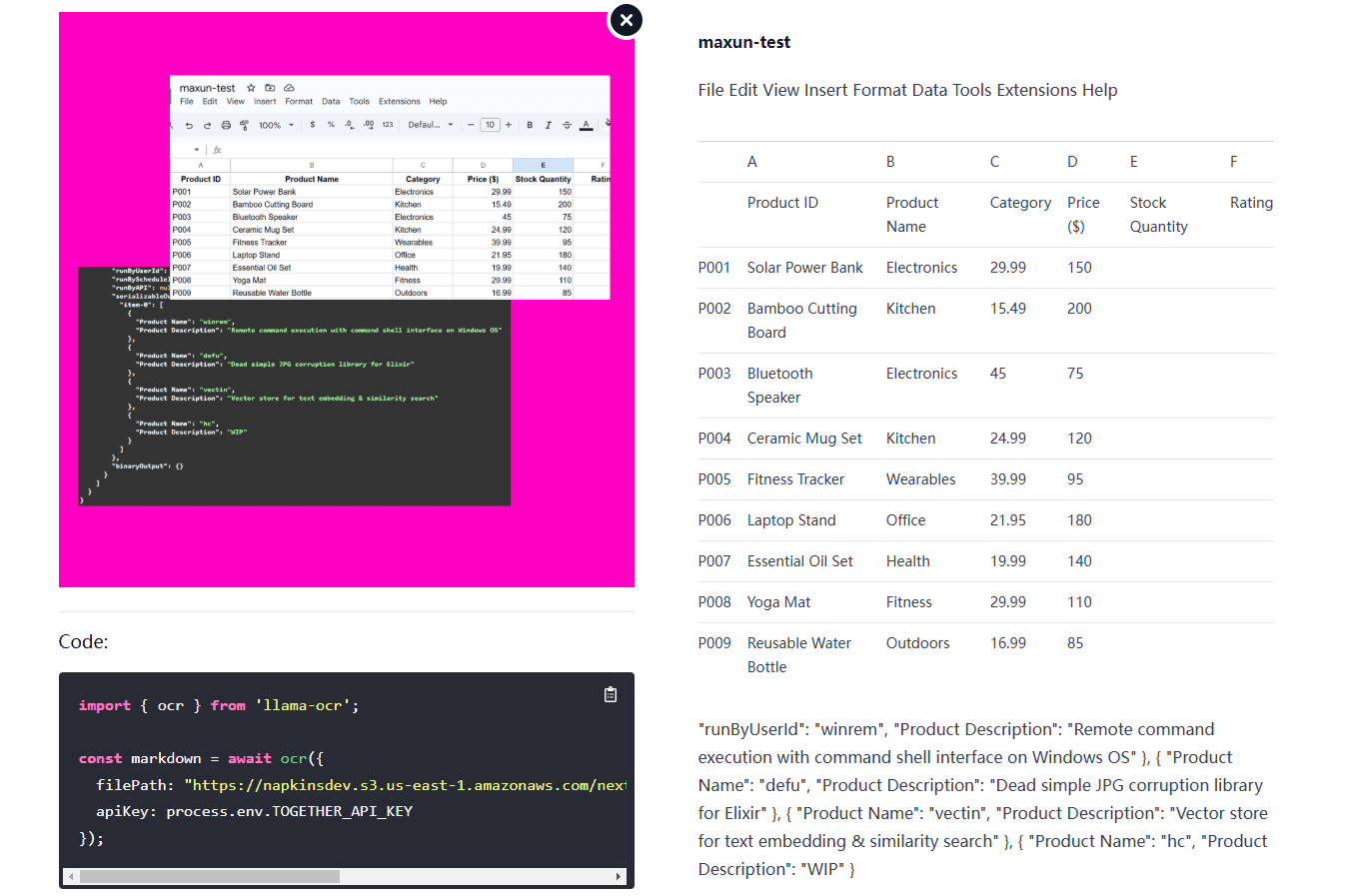
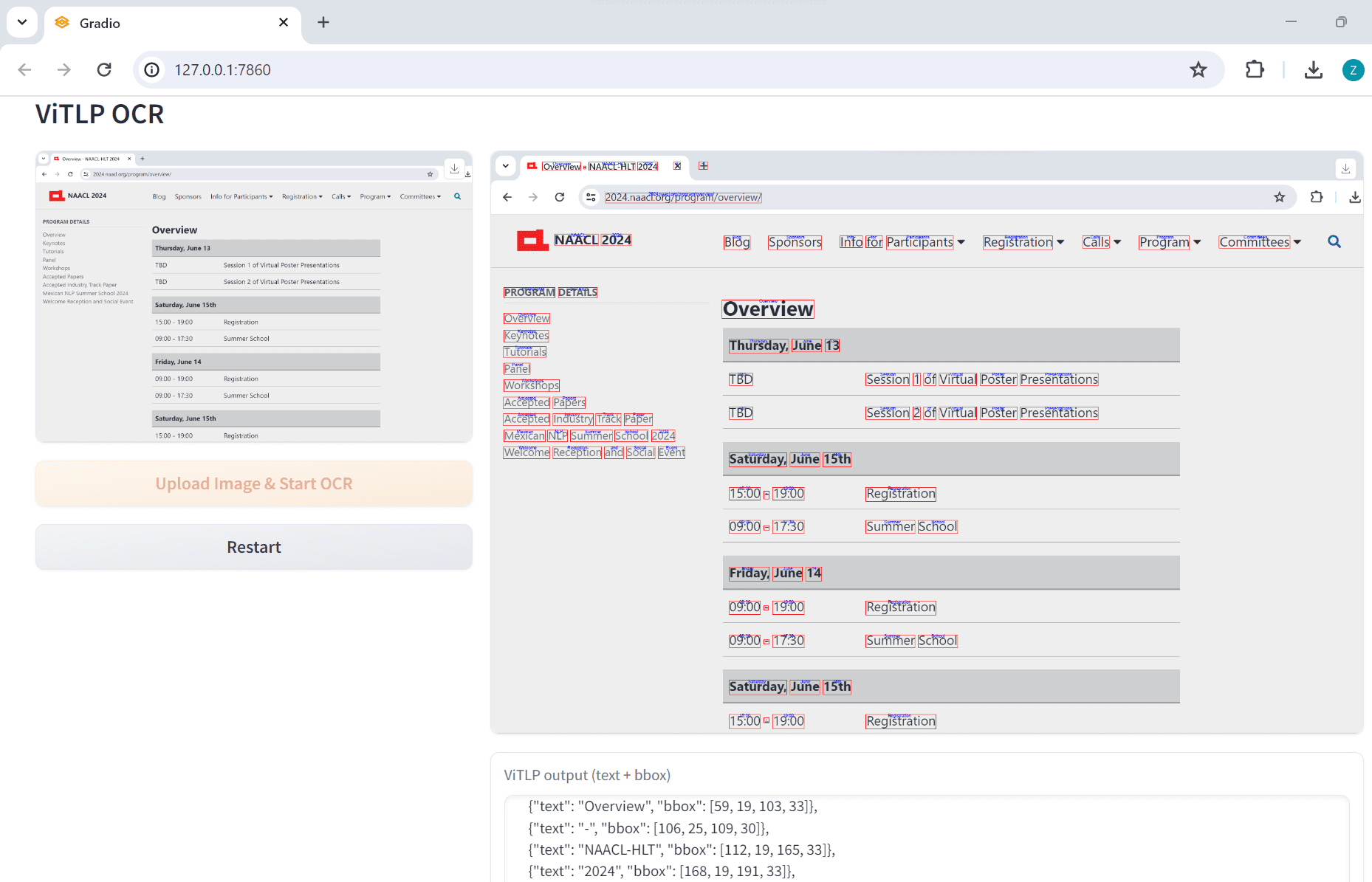
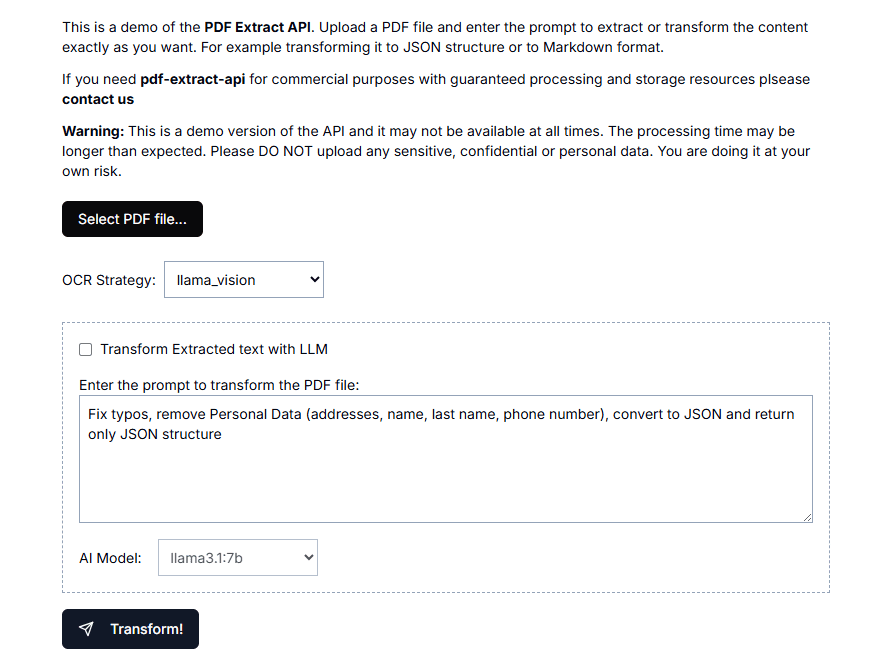
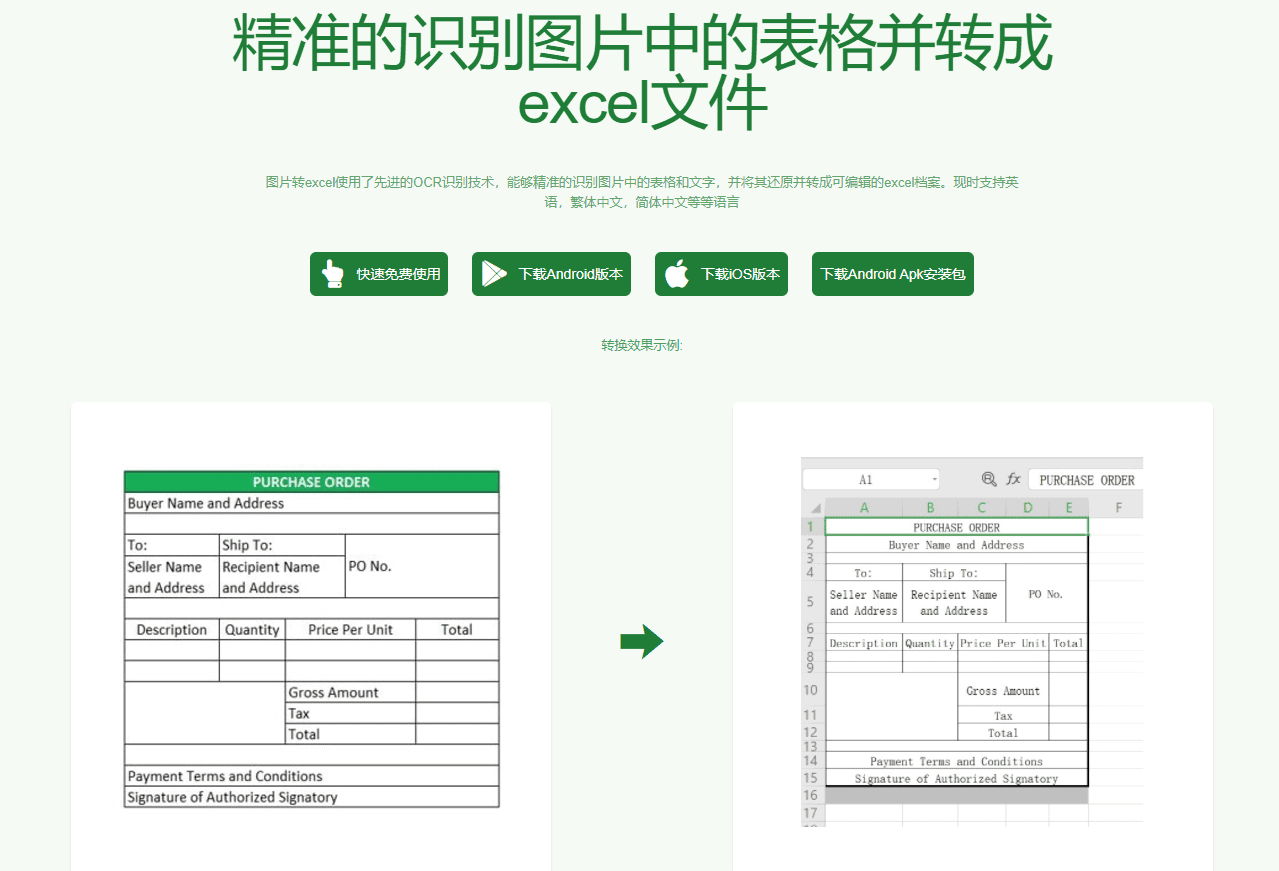
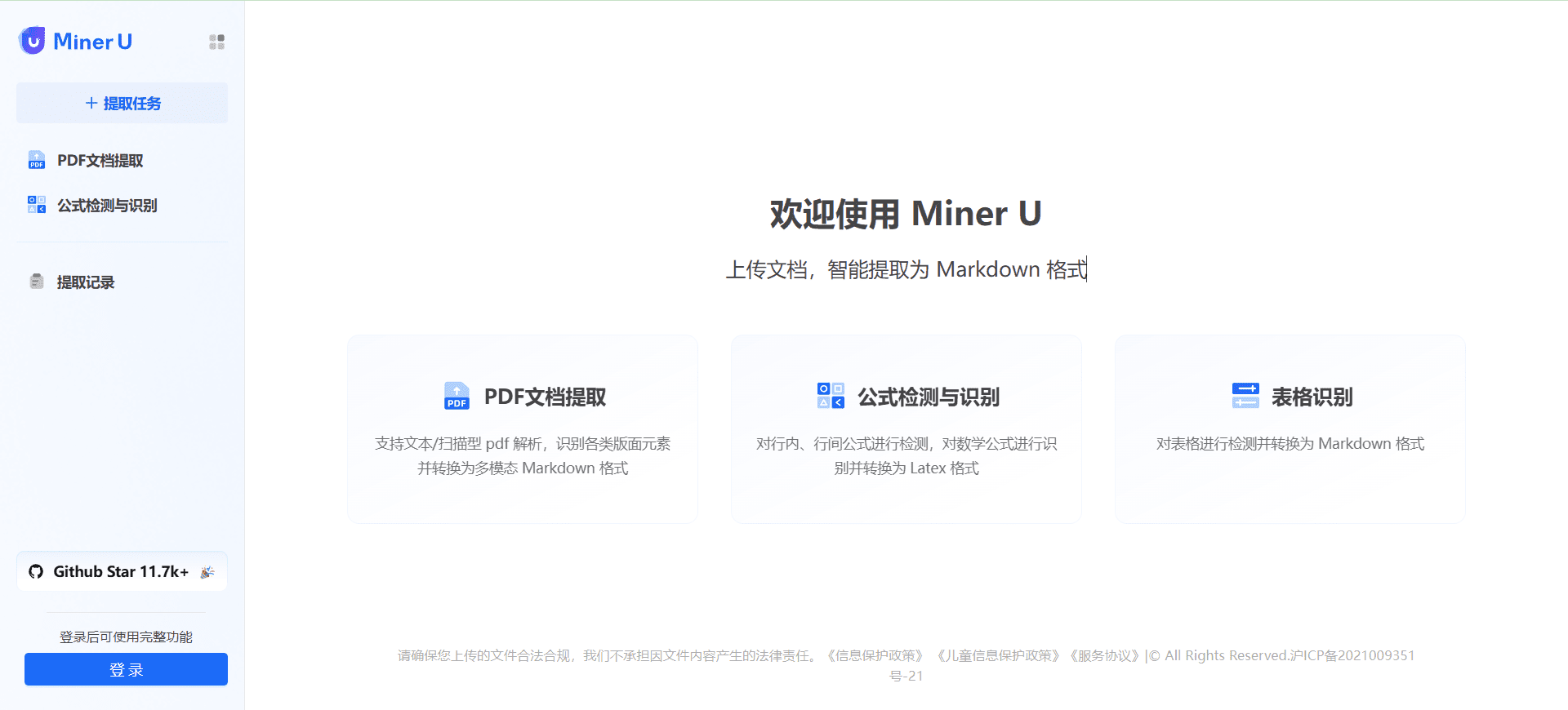
VOP: ferramenta de OCR para extração de diagramas complexos e fórmulas matemáticas
Introdução abrangente O Versatile OCR Program é uma ferramenta de reconhecimento óptico de caracteres (OCR) de código aberto projetada para trabalhar com documentos acadêmicos e educacionais complexos. Ele pode extrair texto, tabelas, fórmulas matemáticas, diagramas e esquemas de PDFs, imagens e outros documentos e gerar...