Introdução geral O Chonkie é uma biblioteca de fragmentação de texto RAG (Retrieval-Augmented Generation) leve e eficiente, criada para ajudar os desenvolvedores a fragmentar o texto de forma rápida e fácil. A biblioteca oferece suporte a uma variedade de métodos de fragmentação, incluindo a fragmentação baseada em tokens, palavras, frases e similaridade semântica...
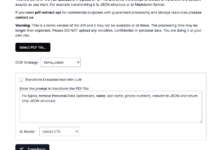
Introdução abrangente O TextIn é uma ferramenta profissional de PDF para Markdown projetada para ajudar os usuários a converter eficientemente documentos PDF para o formato Markdown. A ferramenta é compatível com vários formatos de arquivo, é fácil de operar, tem velocidade de conversão rápida e é capaz de manter o formato e o conteúdo originais do PDF para aumentar a eficiência do processamento de documentos. Quer se trate de um ...
Habilite o modo de programação inteligente Builder, uso ilimitado do DeepSeek-R1 e DeepSeek-V3, experiência mais suave do que a versão internacional. Basta digitar os comandos chineses, sem conhecimento de programação, para escrever seus próprios aplicativos.
Descrição geral A API de extração de texto (text-extract-api) é uma ferramenta avançada projetada para extrair e analisar o conteúdo de uma variedade de formatos de documentos (por exemplo, PDF, Word, PPTX etc.). A API utiliza a tecnologia de reconhecimento óptico de caracteres (OCR) de última geração e modelos compatíveis com Ollama para poder pegar qualquer documento ou imagem...
Introdução abrangente O Datalab oferece uma variedade de modelos avançados de IA com foco em OCR, análise de layout, PDF para Markdown e muito mais. Esses modelos não são apenas de alto desempenho, mas também fáceis de usar e de código aberto. Os modelos Marker da plataforma podem converter PDF em Markdown de forma rápida e precisa, incluindo tabelas...
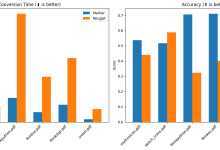
Introdução abrangente O MinerU é uma ferramenta de extração de dados de código aberto desenvolvida pela equipe do OpenDataLab no Laboratório de Inteligência Artificial de Xangai, com foco na extração eficiente de conteúdo de documentos PDF complexos, páginas da Web e eBooks. Ele pode converter documentos PDF multimodais que contenham imagens, fórmulas, tabelas e outros elementos em m...
Introdução geral O Marker é uma ferramenta de processamento de documentos baseada em aprendizagem profunda, projetada para converter arquivos PDF para o formato Markdown com rapidez e precisão. Ele oferece suporte a uma ampla variedade de tipos de documentos e é especialmente otimizado para a conversão de livros e artigos científicos. O Marker é capaz de remover conteúdo redundante, como cabeçalhos e rodapés, formatar tabelas e...
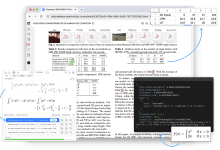
Introdução geral O Mathpix é uma poderosa ferramenta de automação de documentos orientada por IA, projetada para pesquisadores, desenvolvedores e empresas. Ele converte PDFs e imagens de forma rápida e precisa em texto pesquisável, exportável e legível por máquina. O Mathpix oferece uma ampla variedade de recursos, incluindo reconhecimento de fórmulas matemáticas, LaT...
Introdução abrangente O Unstructured-IO fornece um conjunto de componentes de código aberto para processamento e pré-processamento de imagens e documentos de texto, como PDF, HTML, documentos do Word etc. O Unstructured-IO fornece um conjunto de componentes de código aberto para processamento e pré-processamento de imagens e documentos de texto, como PDF, HTML, documentos do Word etc. Seu principal objetivo é simplificar e otimizar os fluxos de trabalho de processamento de dados, especialmente para aplicativos de modelo de linguagem grande (LLM), para fornecer suporte. Seu principal objetivo é simplificar e otimizar os fluxos de trabalho de processamento de dados, especialmente para aplicativos de modelo de linguagem grande (LLM) para fornecer suporte.
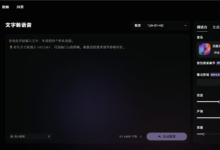
Introdução abrangente O projeto Reader da Jina AI é uma ferramenta de código aberto (endereço de código aberto do Reader), pode ser qualquer URL adicionando o prefixo https://r.jina.ai/转换成适合大型语言模型 (Large Language Models, LLM), formato de entrada, suporte para o modo de fluxo dinâmico e leitura de imagens...
Não consegue encontrar ferramentas de IA? Tente aqui!
Basta digitar a palavra-chave Acessibilidade Bing SearchA seção Ferramentas de IA deste site é uma maneira rápida e fácil de encontrar todas as ferramentas de IA deste site.