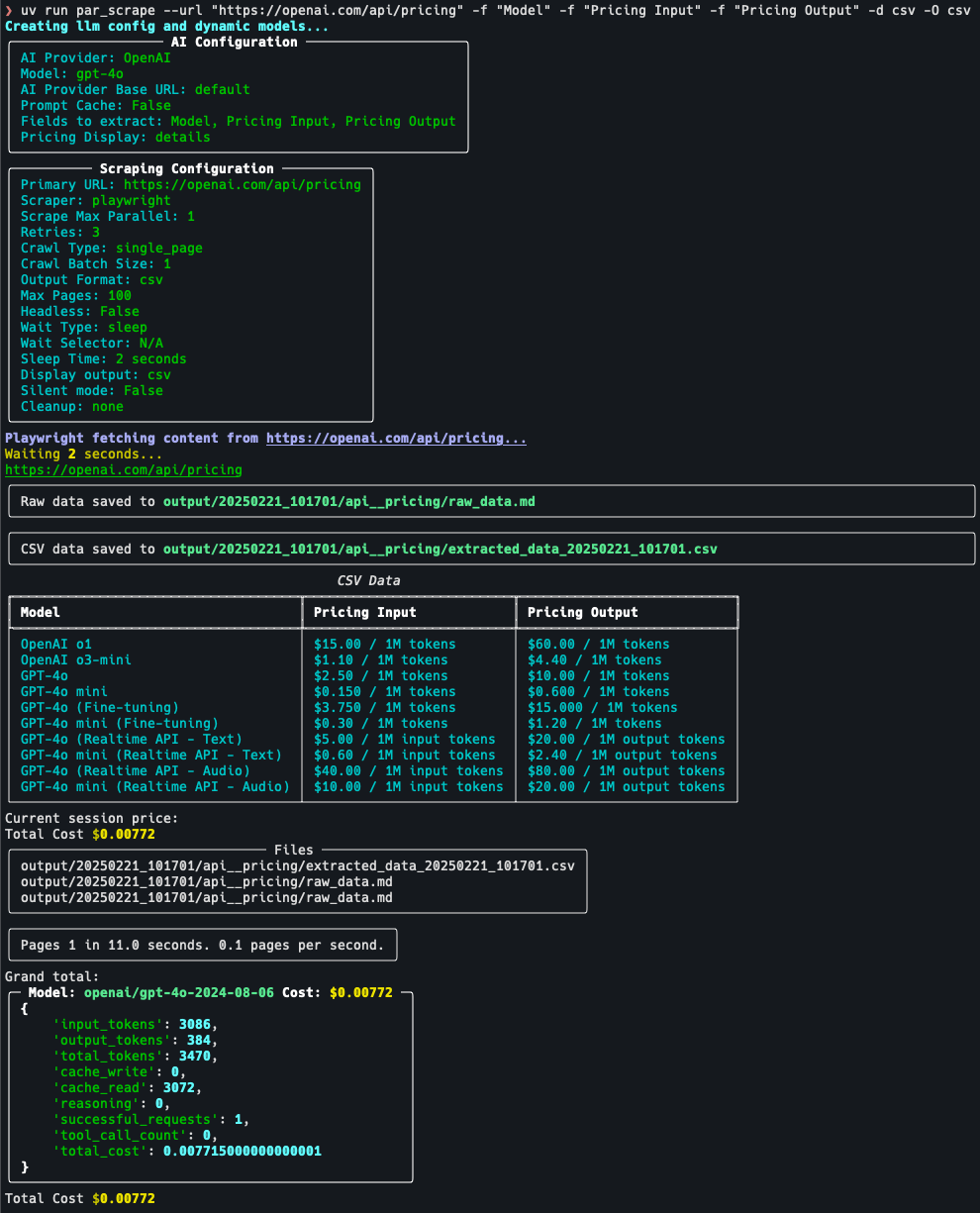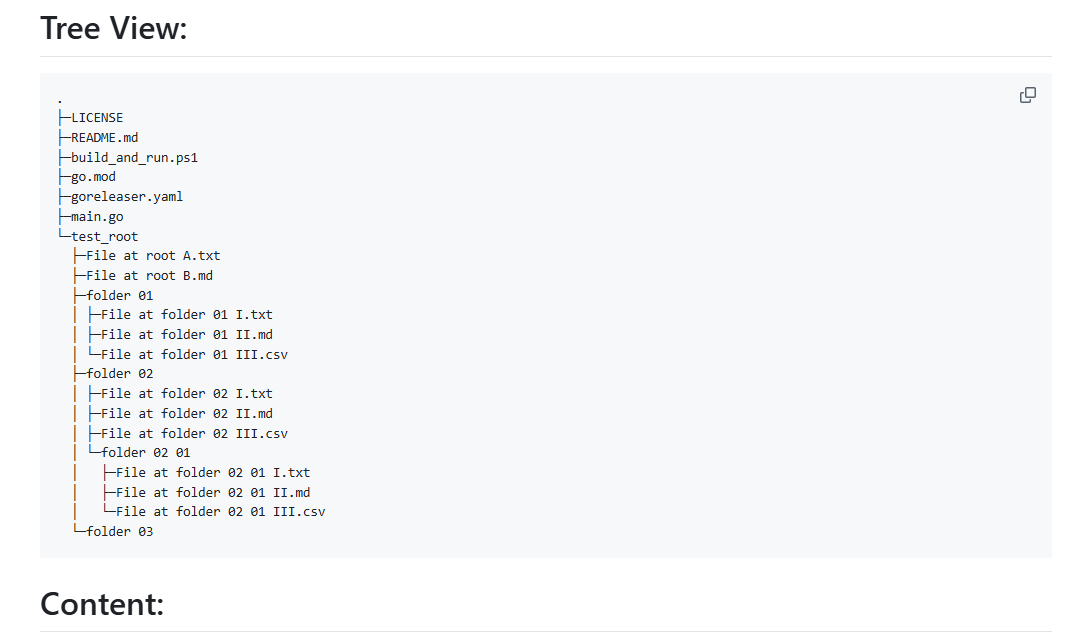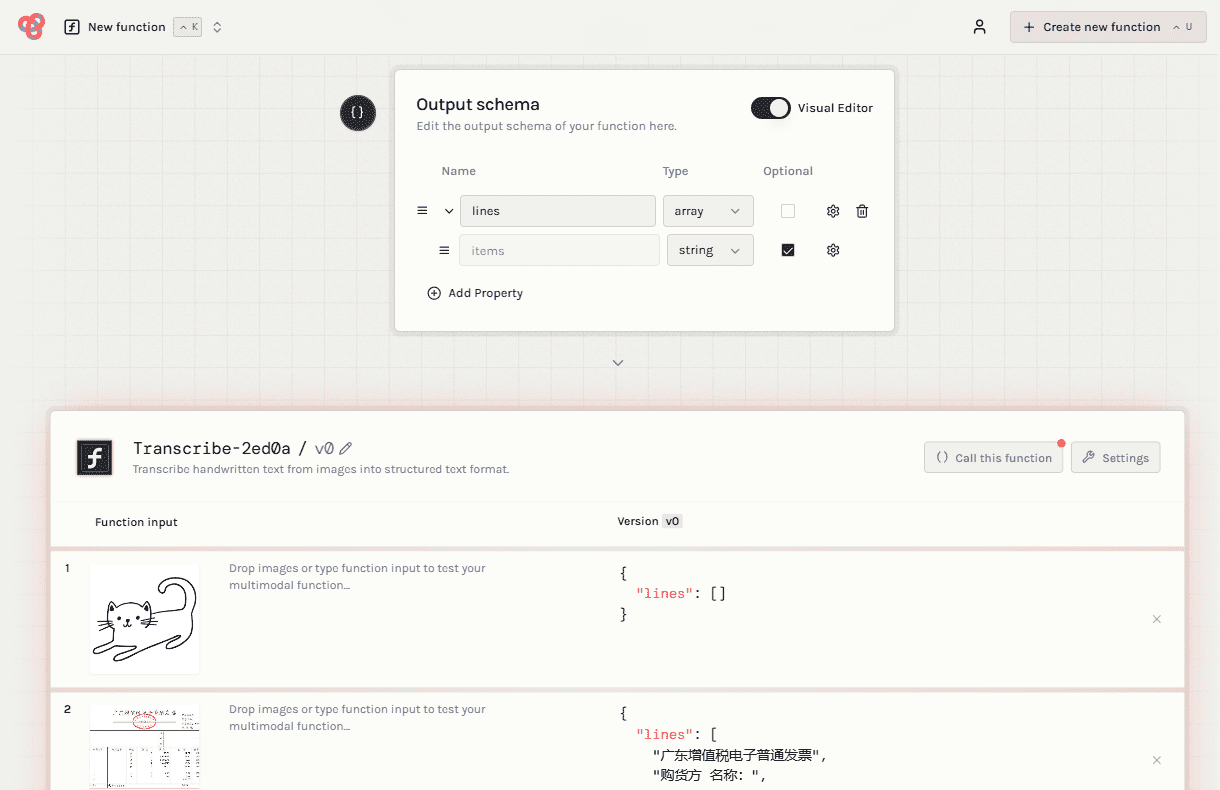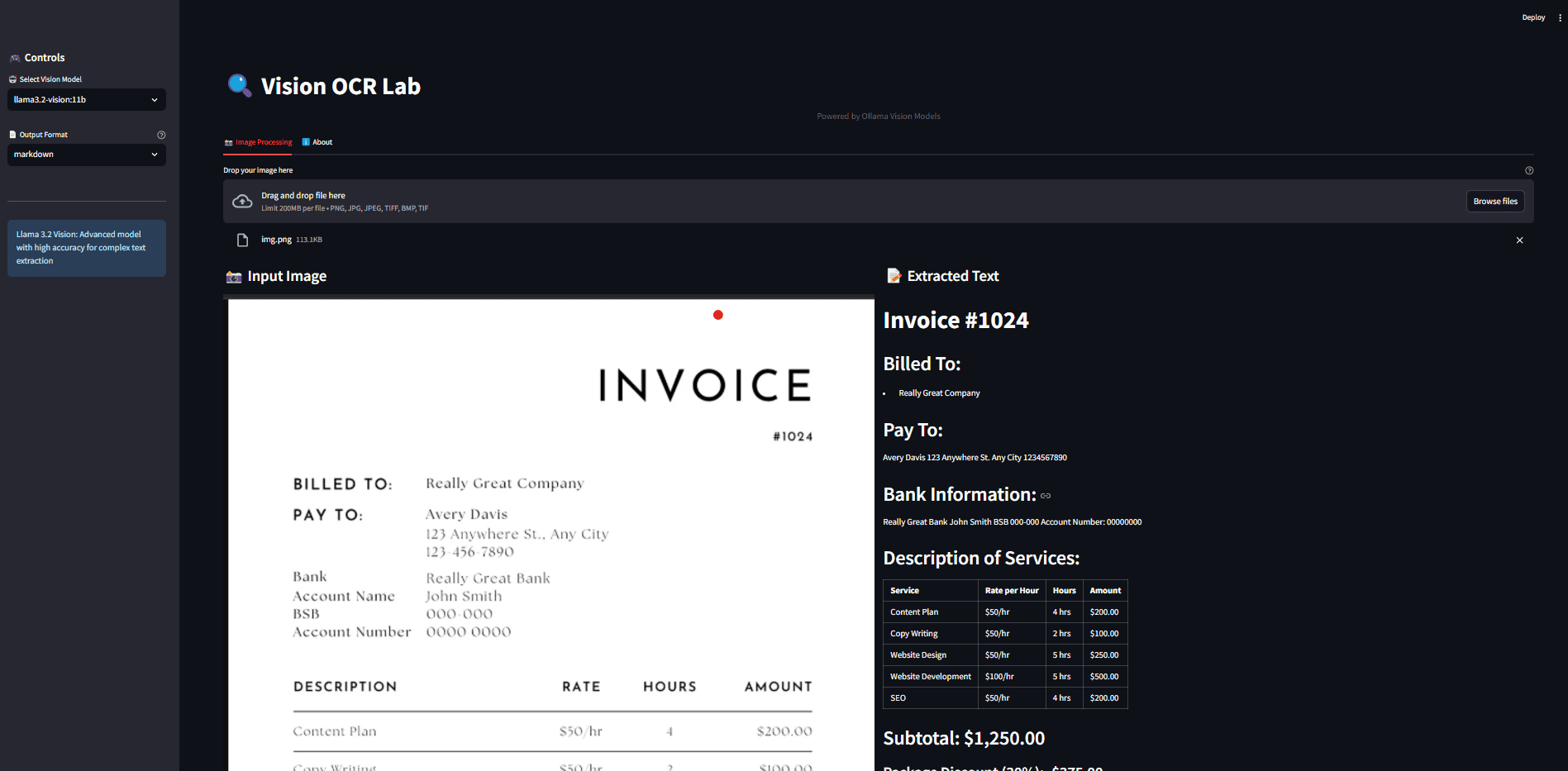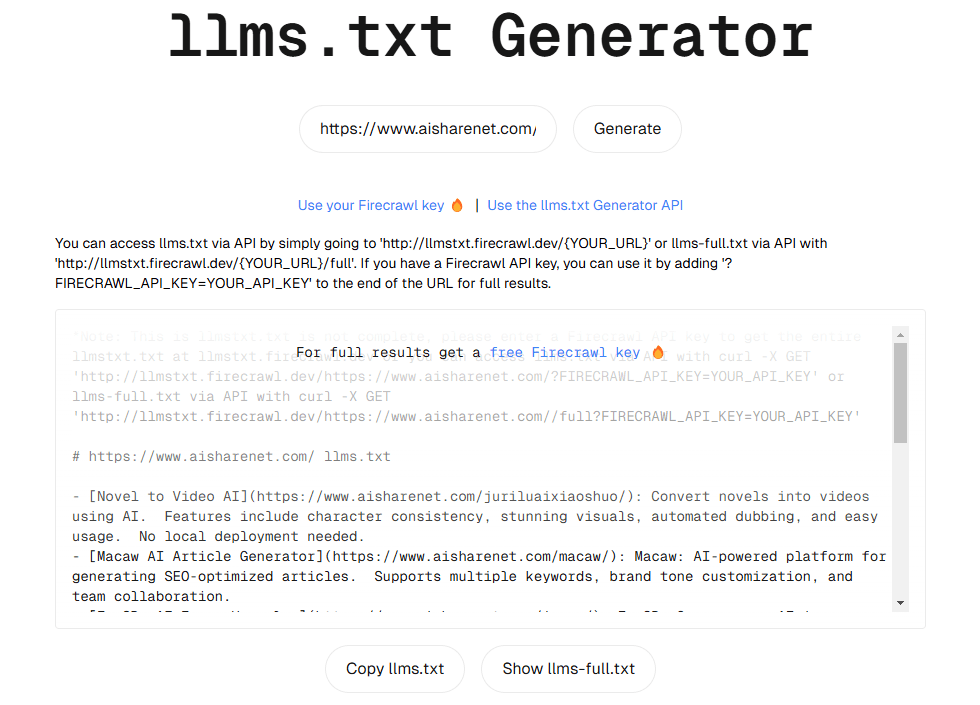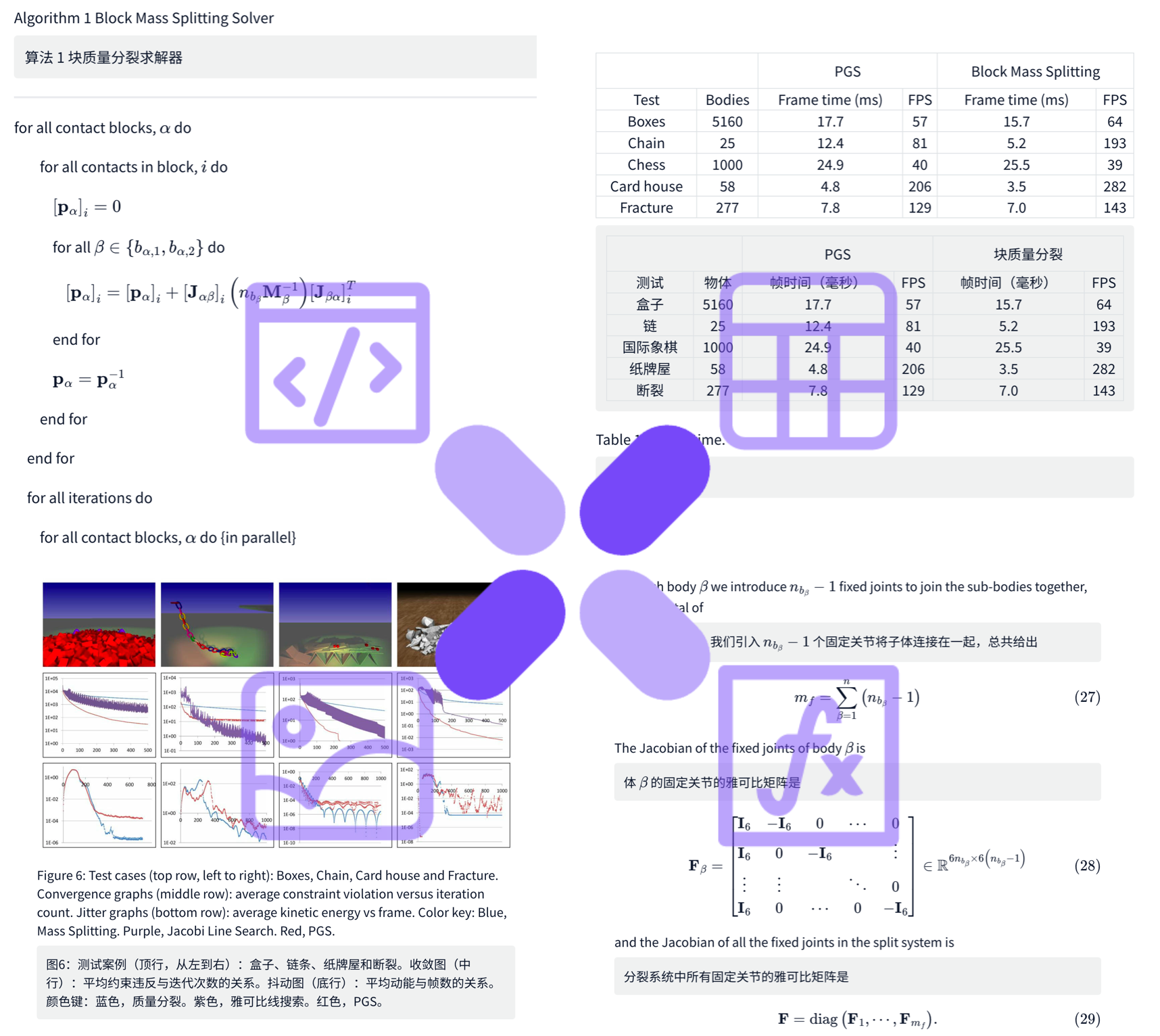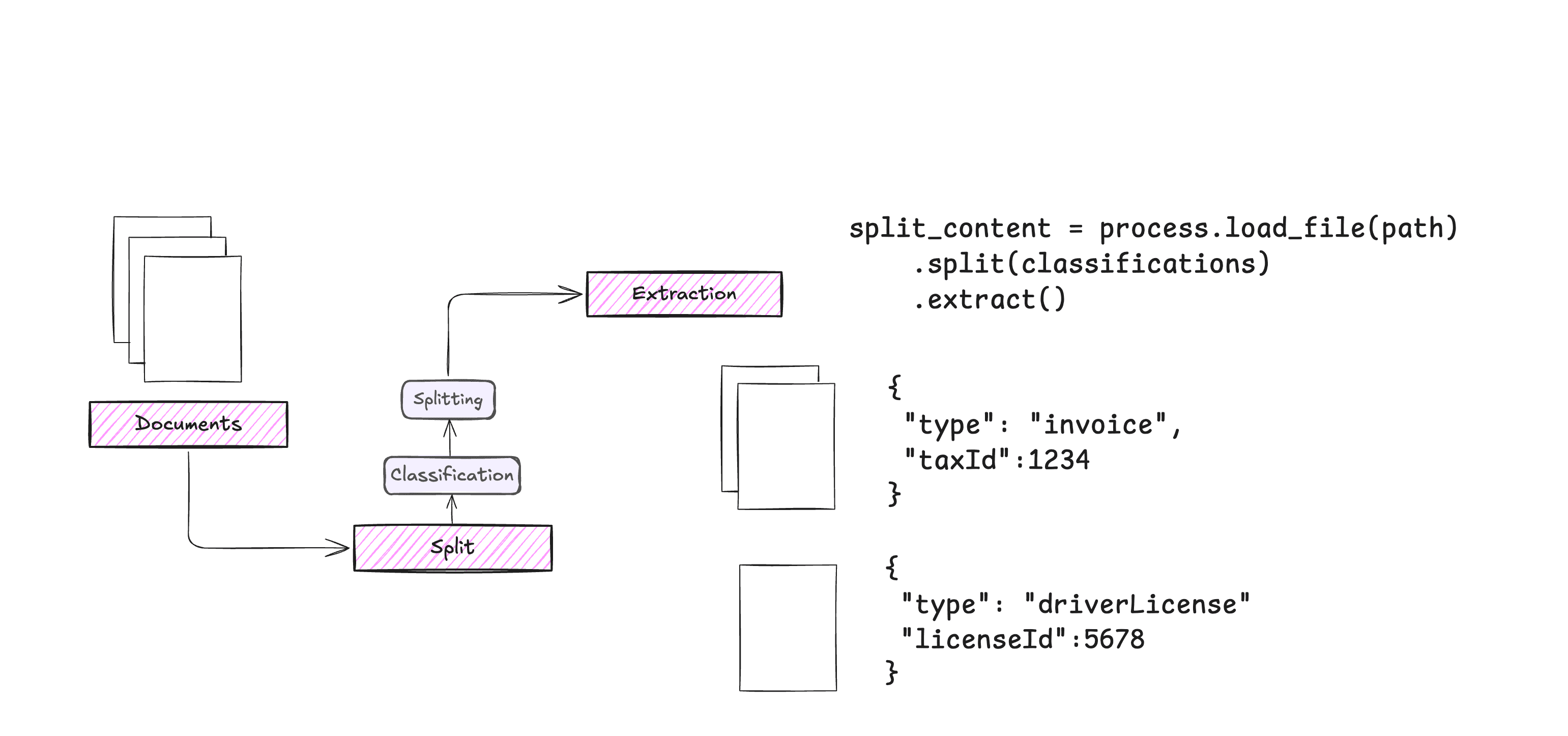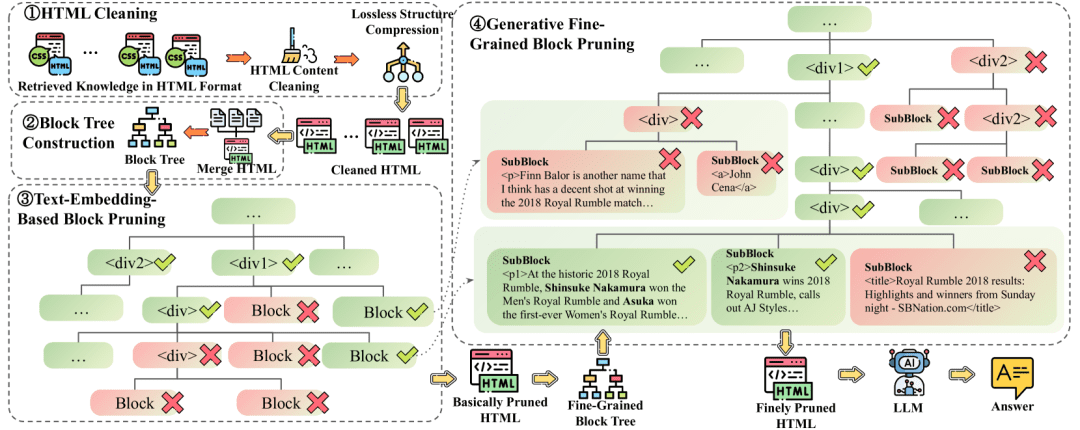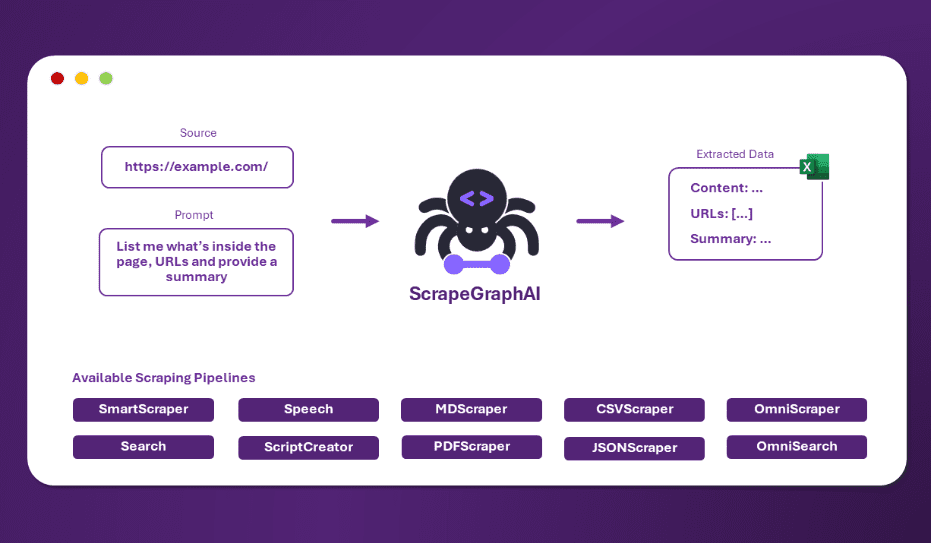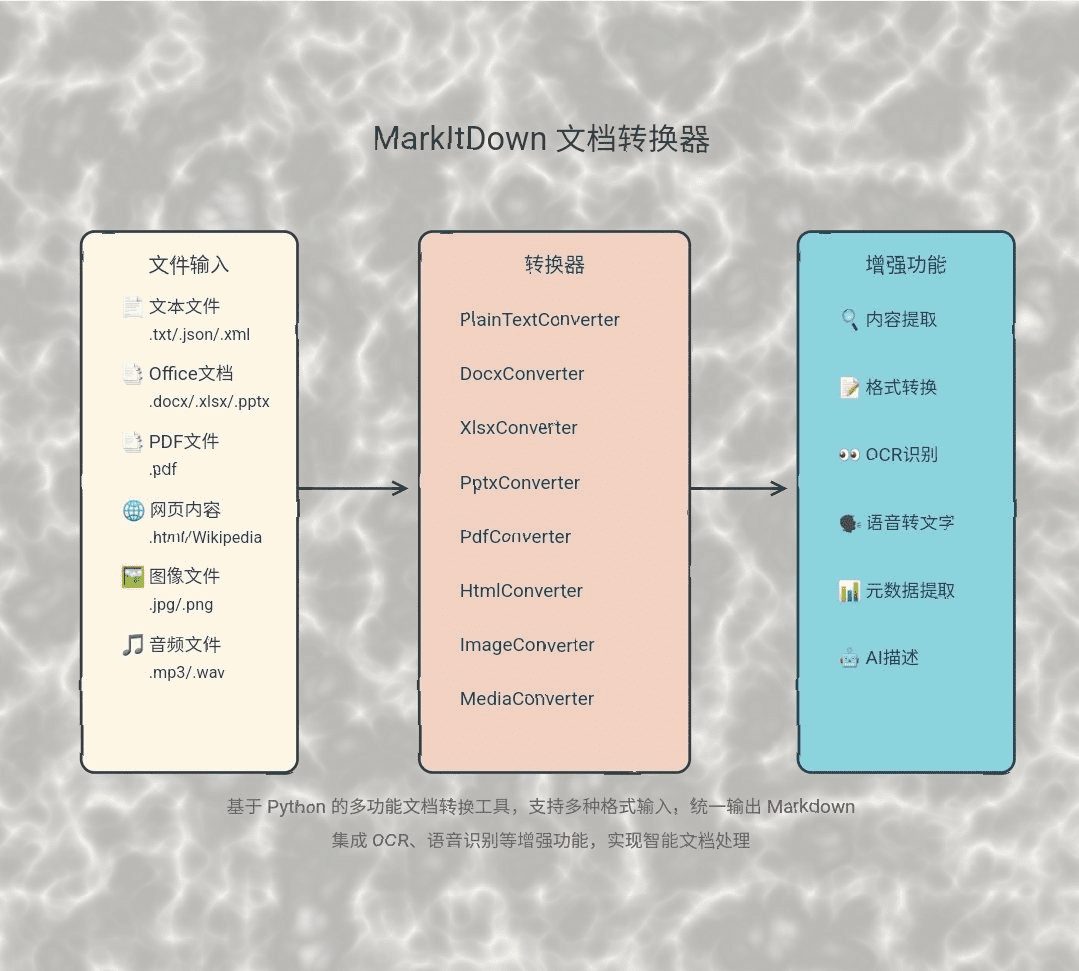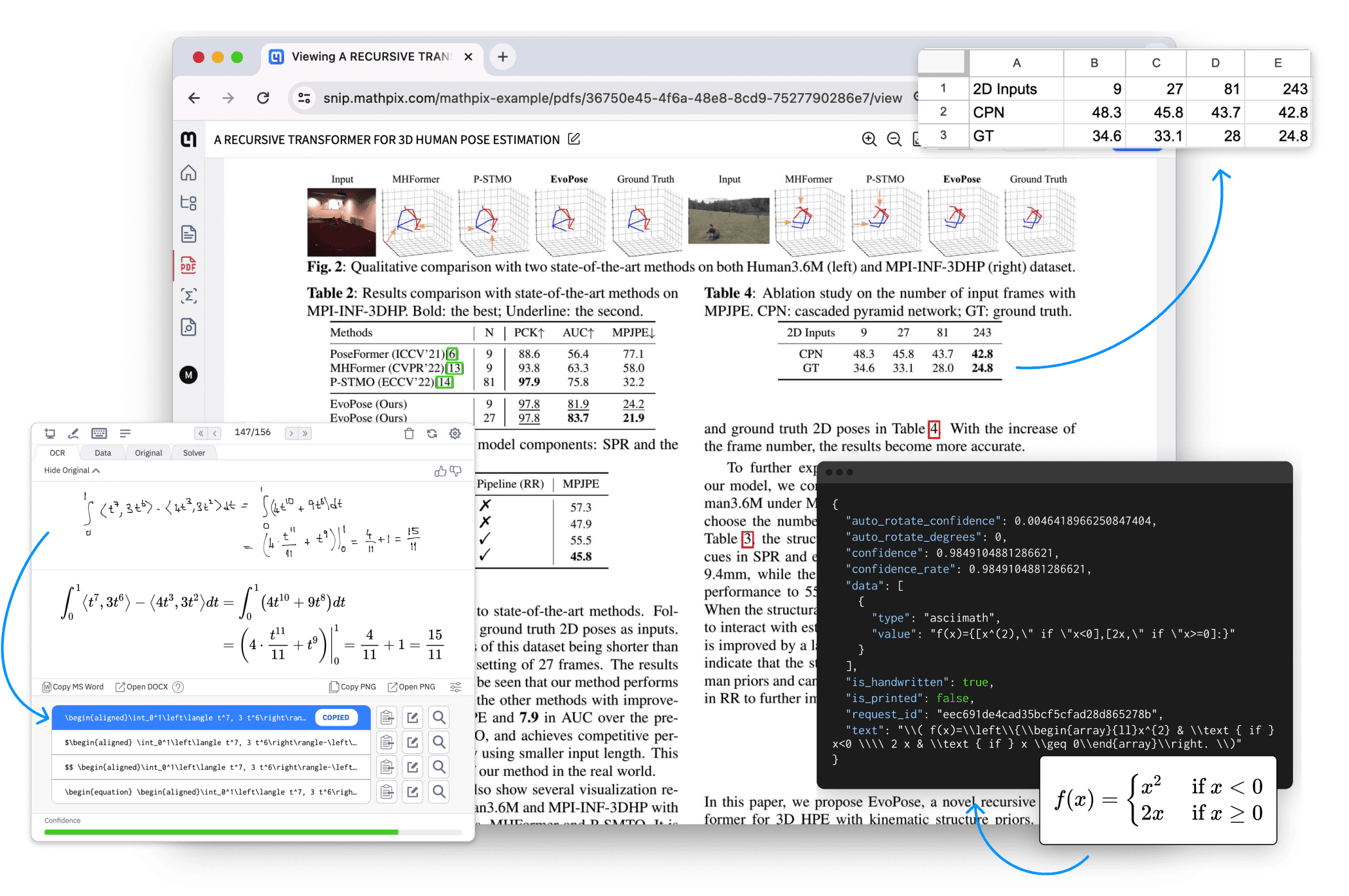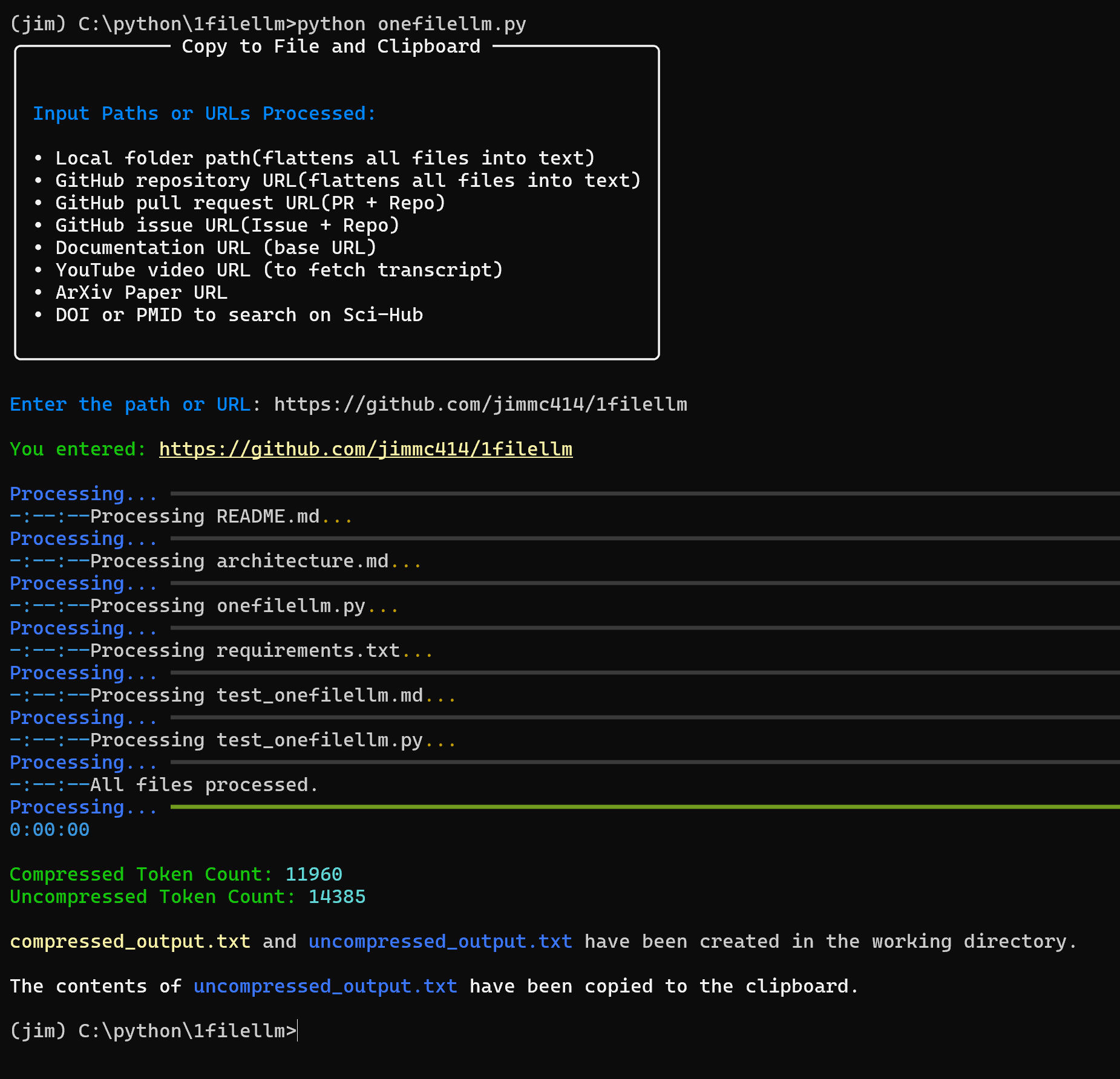
OneFileLLM: integração de várias fontes de dados em um único arquivo de texto
Introdução abrangente O OneFileLLM é uma ferramenta de linha de comando de código aberto projetada para consolidar várias fontes de dados em um único arquivo de texto para facilitar a entrada em modelos de linguagem grande (LLMs). Ele é compatível com o processamento de repositórios do GitHub, artigos do ArXiv, transcrições de vídeos do YouTube,...