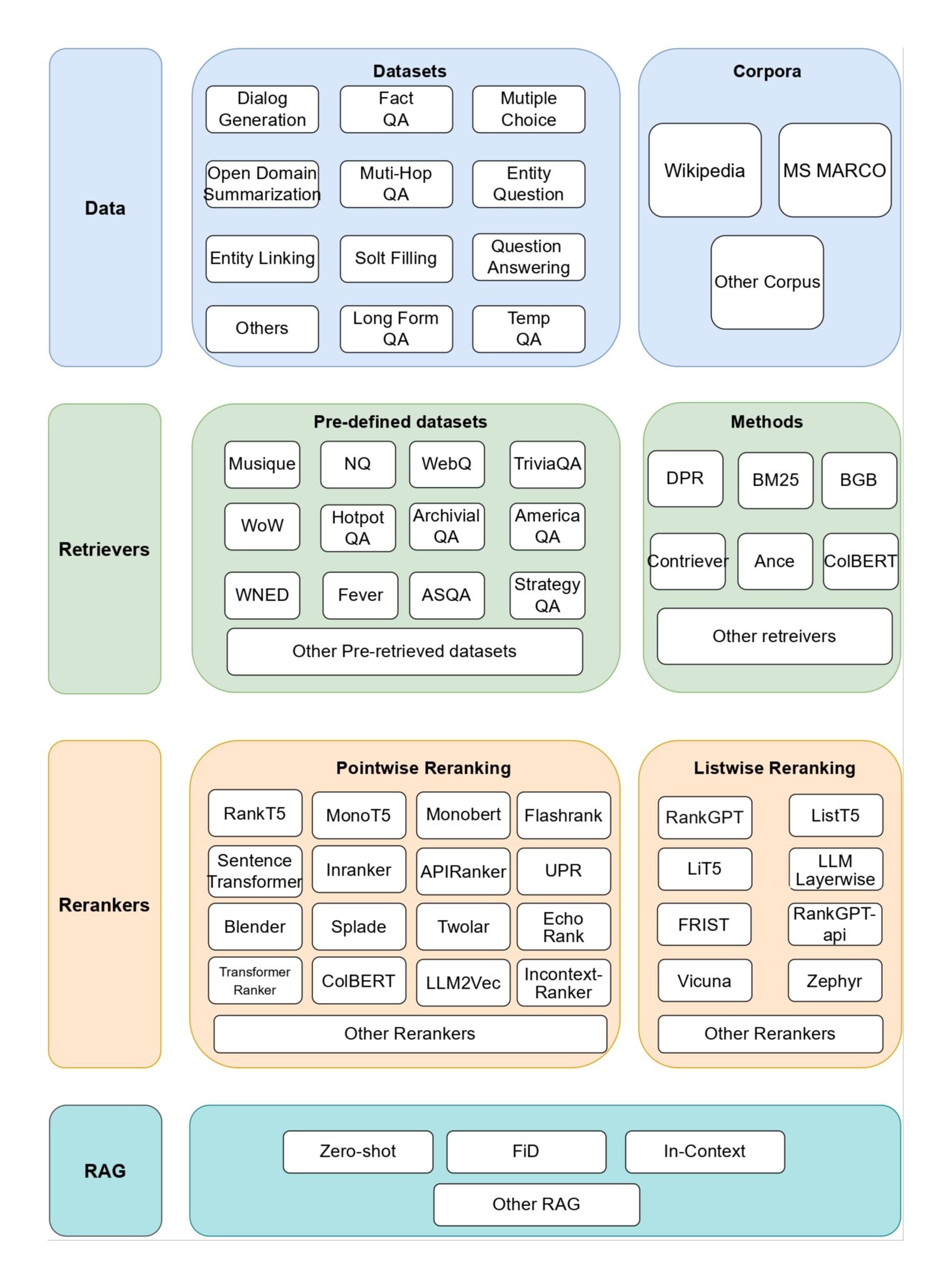
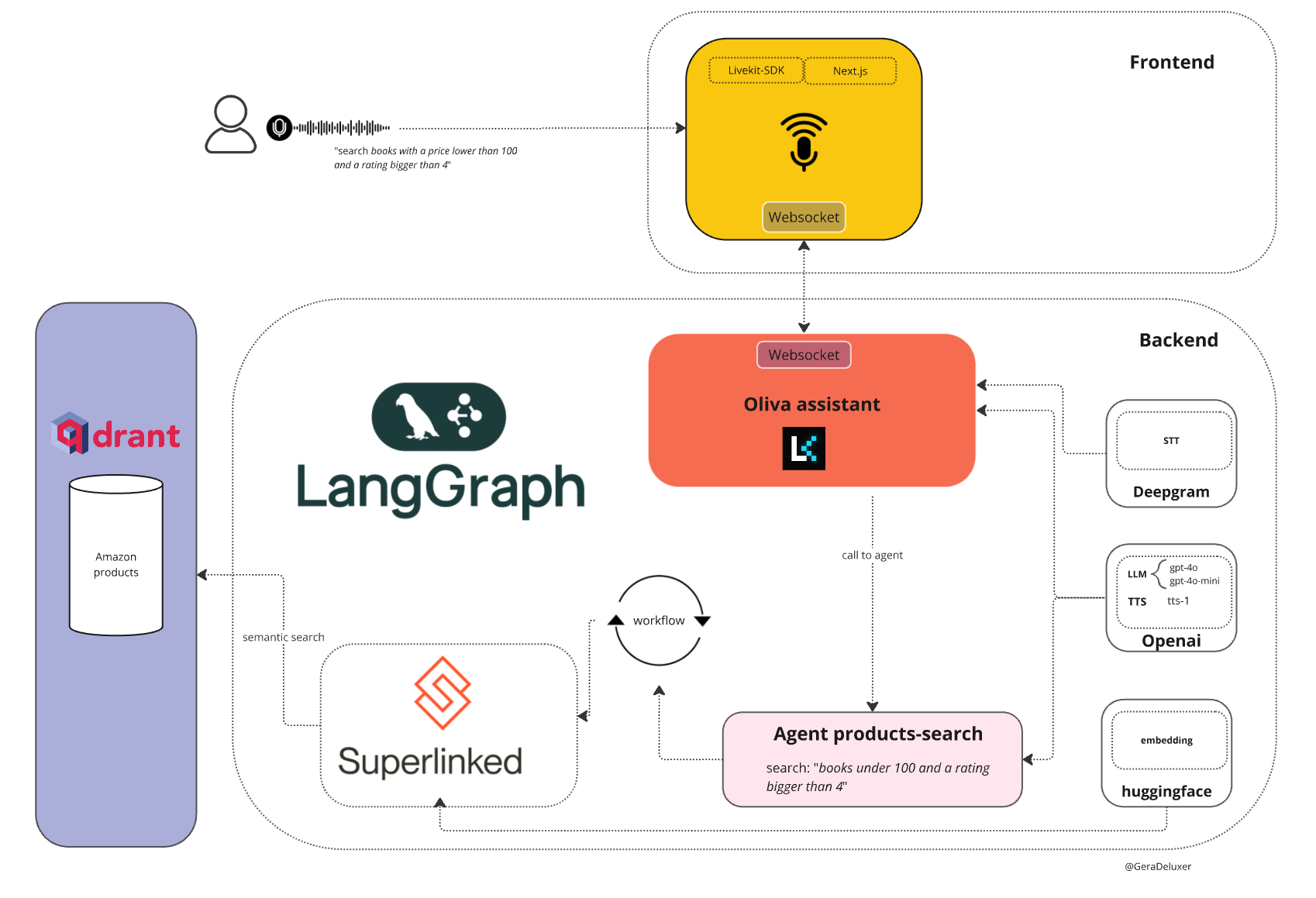
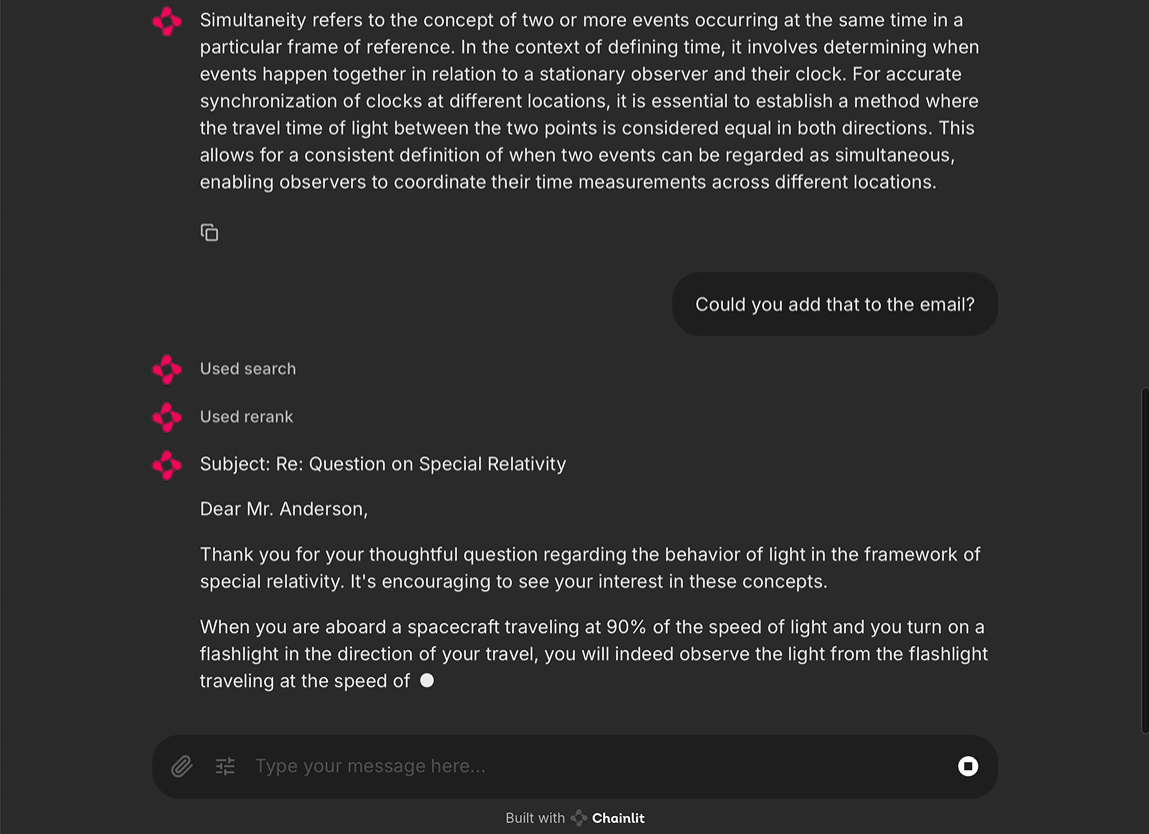
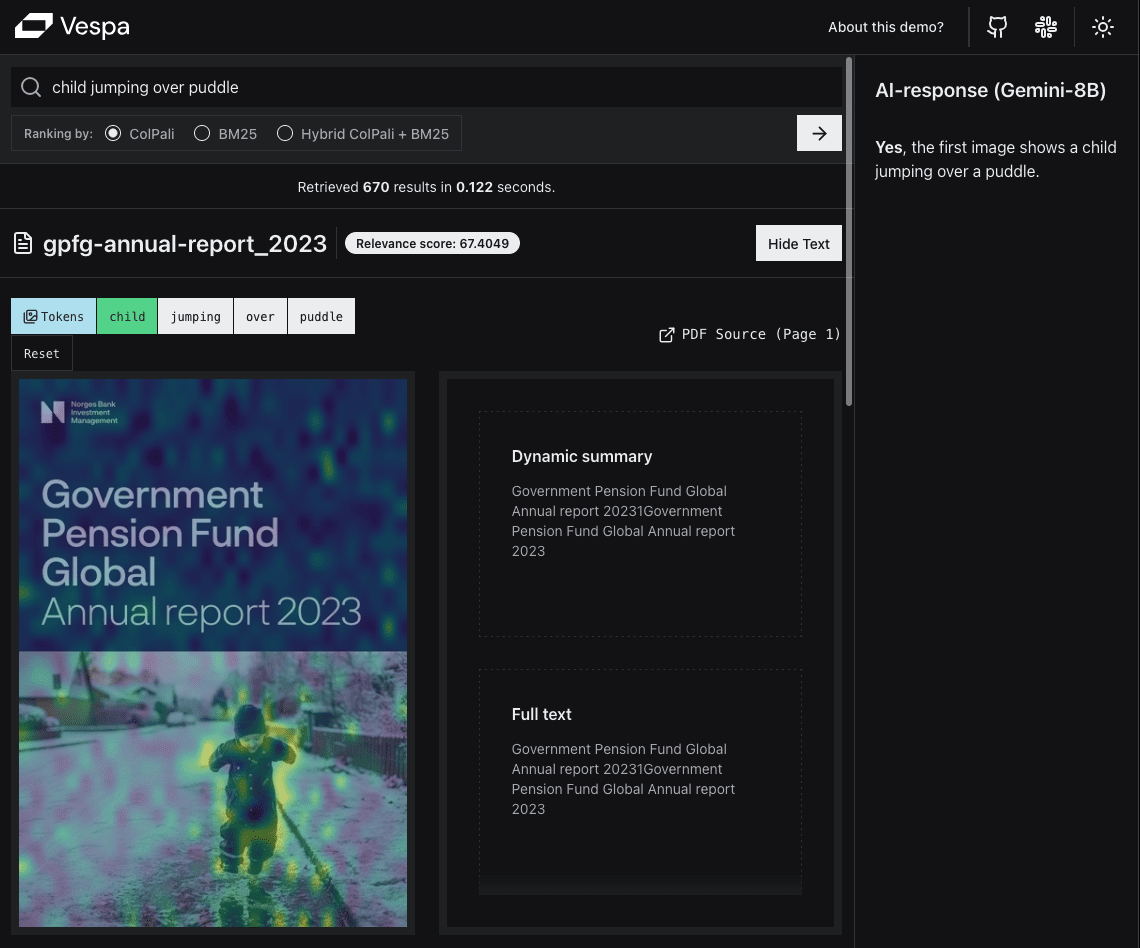
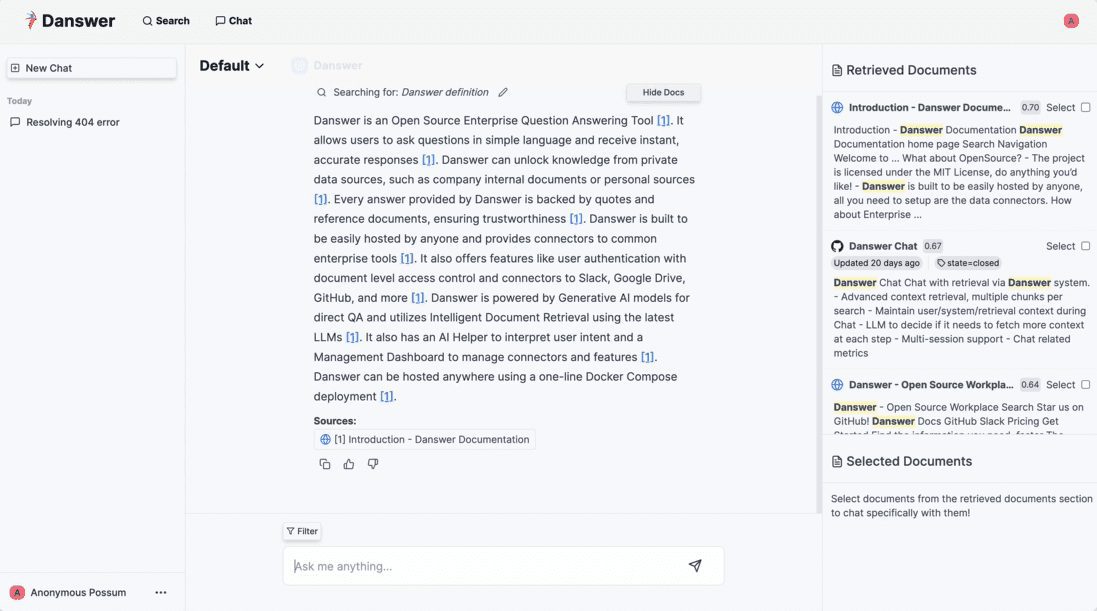
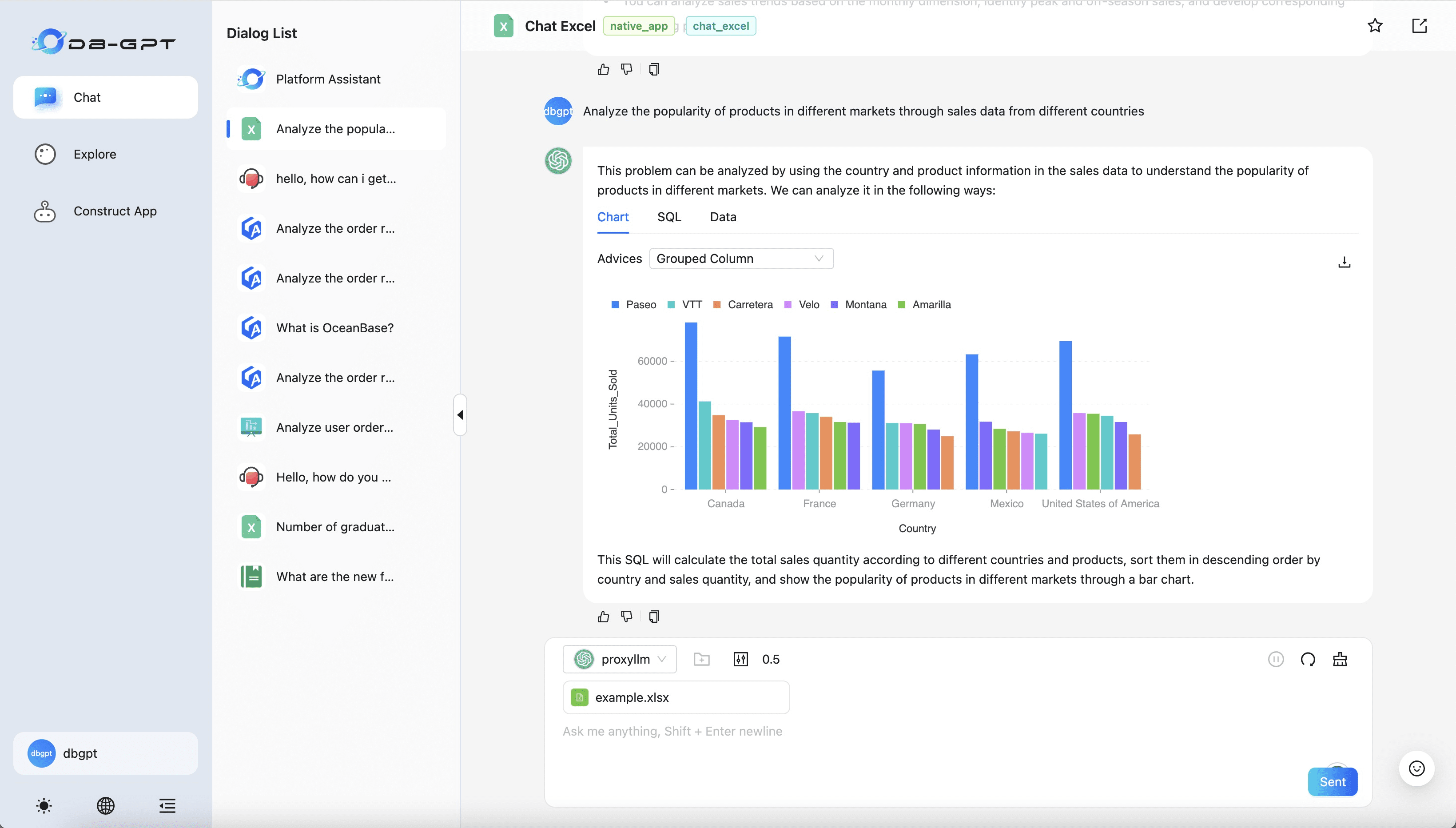
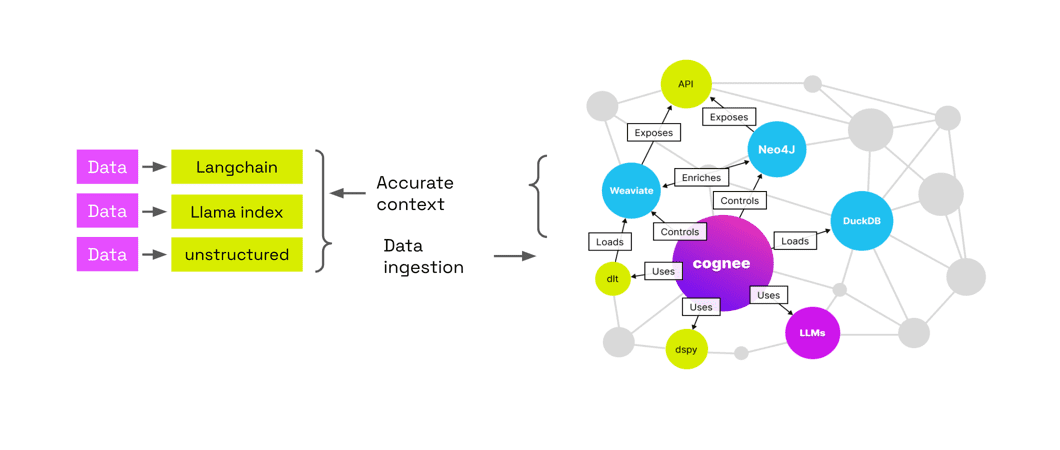
Deep Recall: uma ferramenta de código aberto que fornece uma estrutura de memória de nível empresarial para modelos grandes
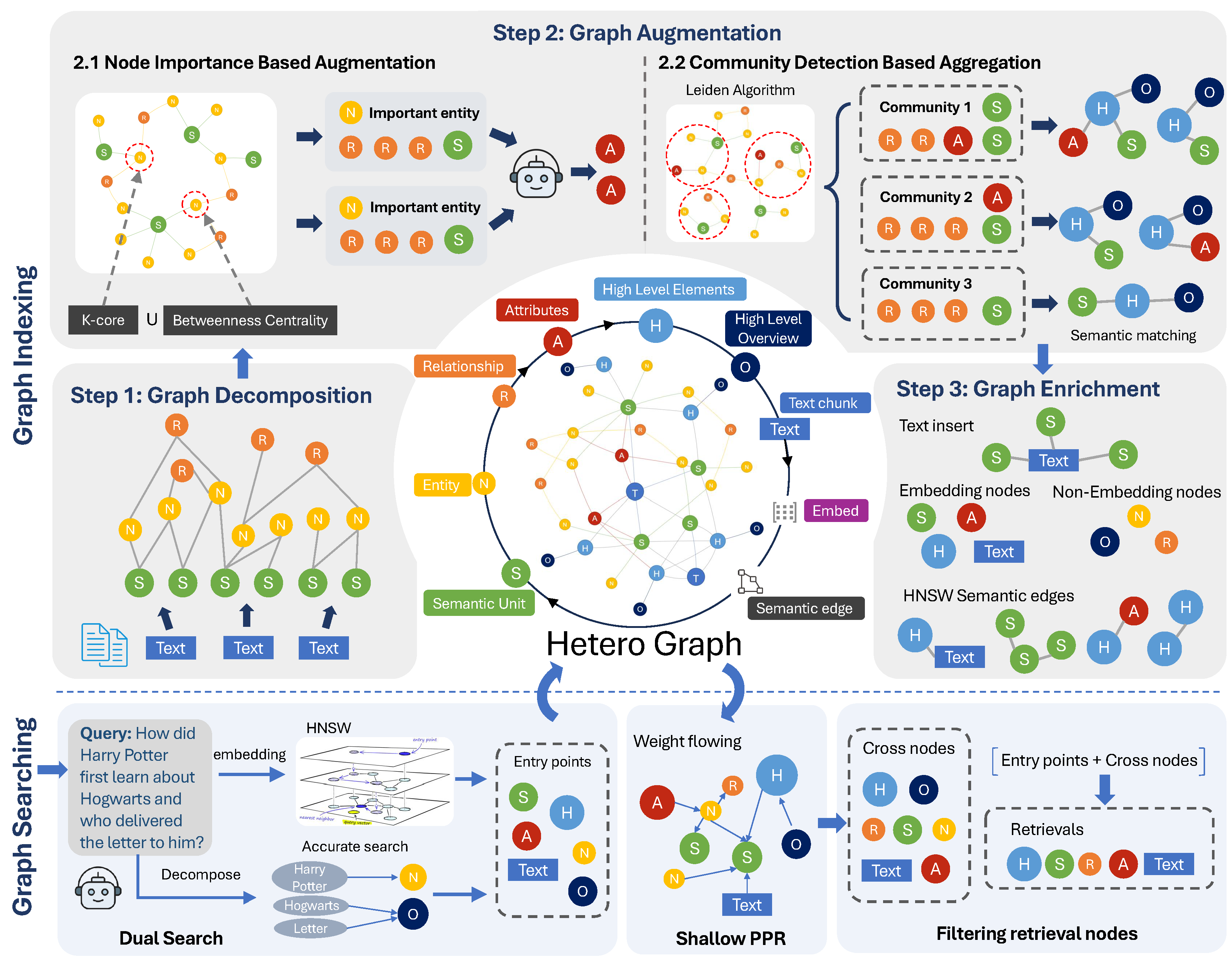
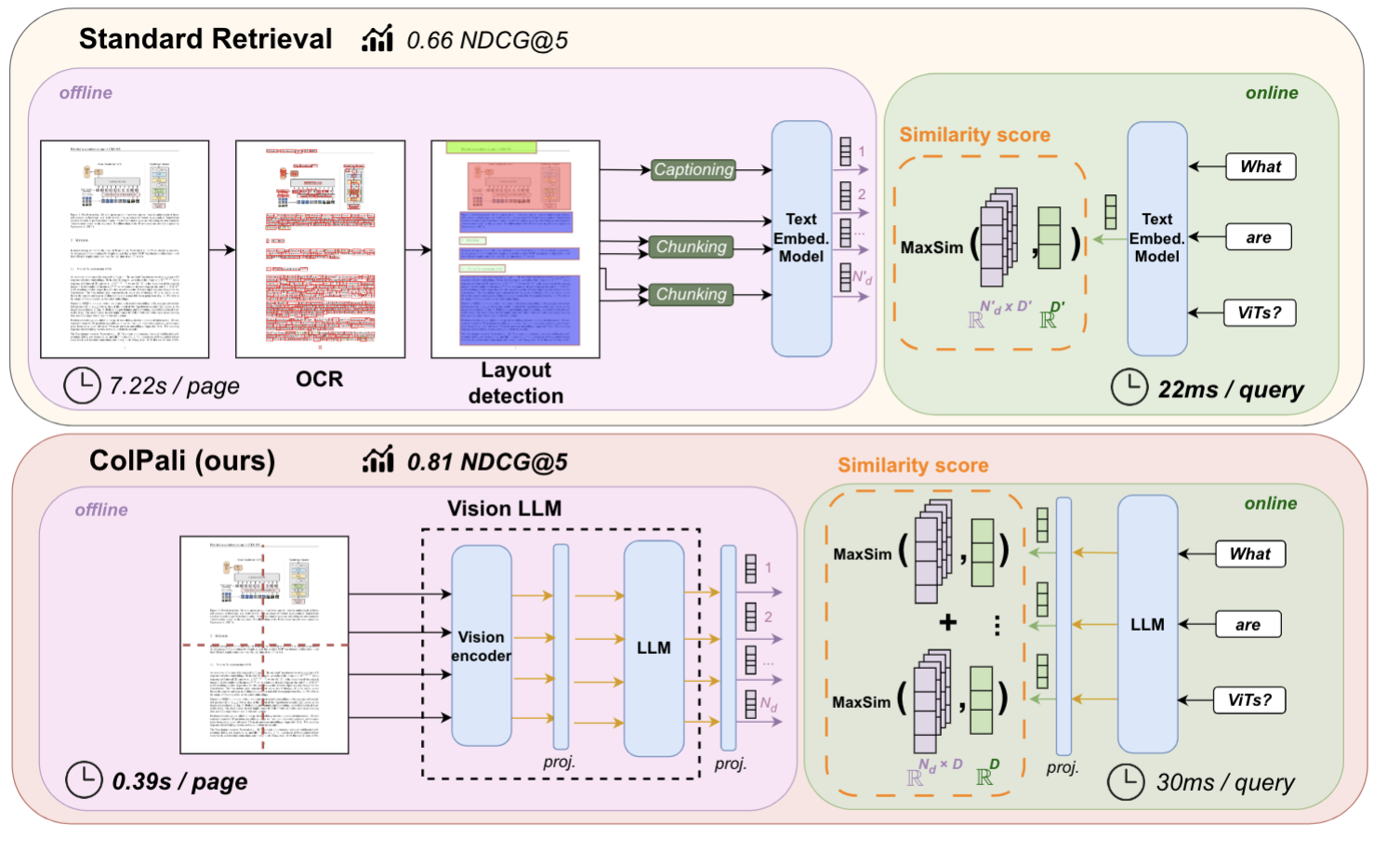
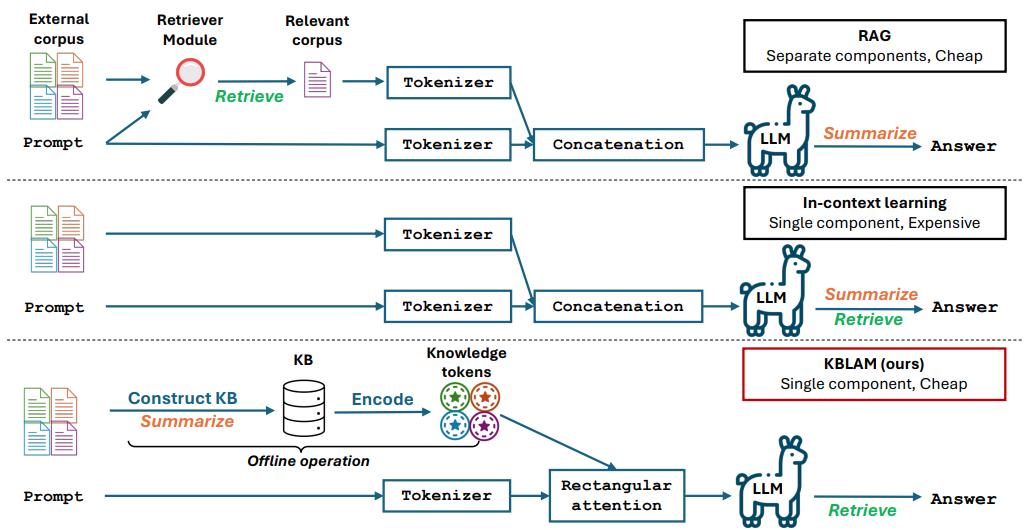
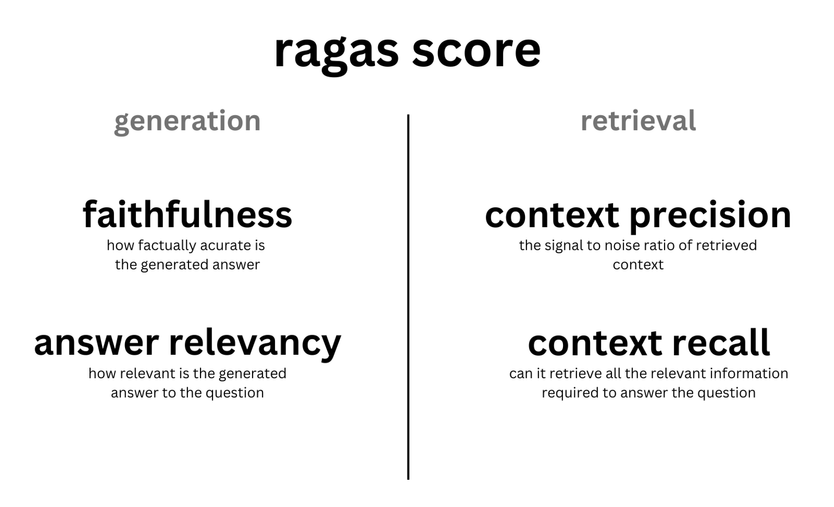
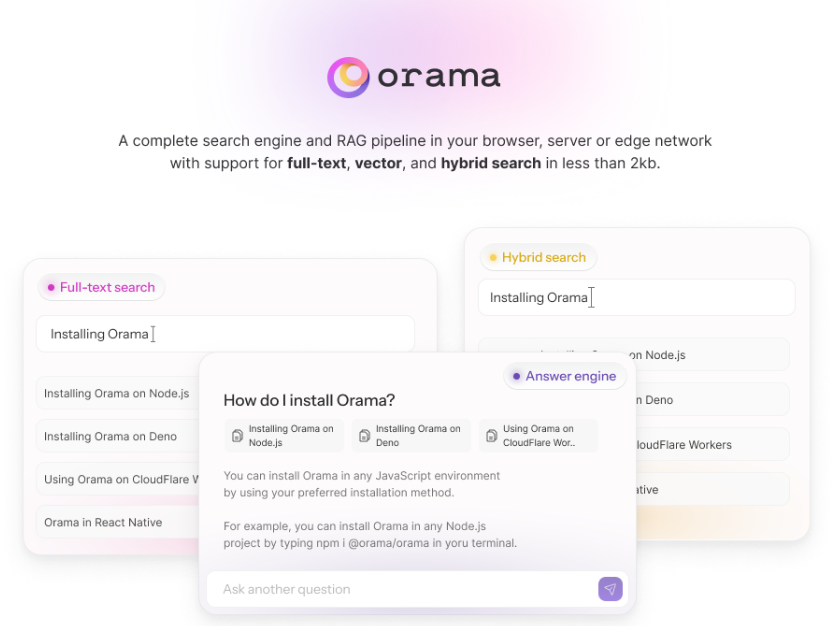
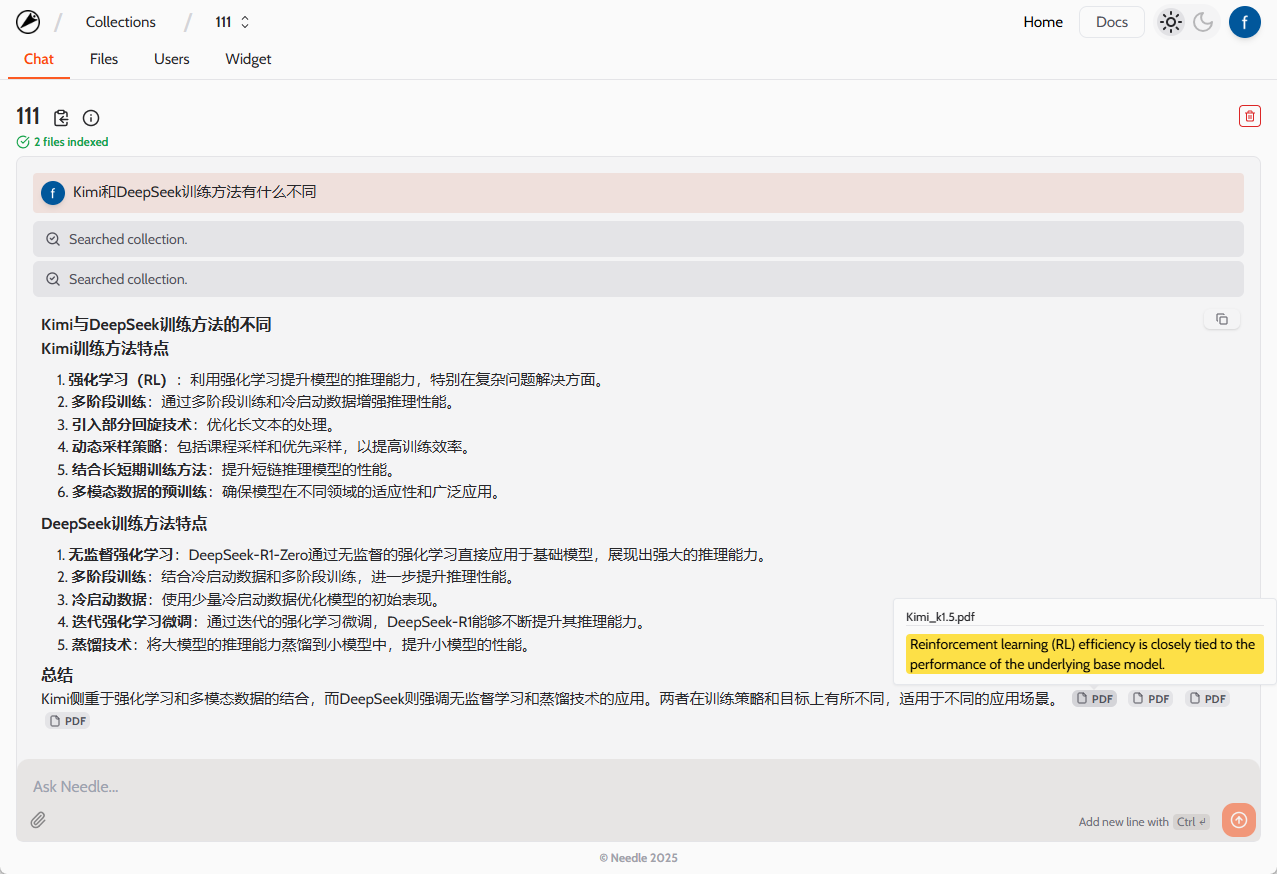
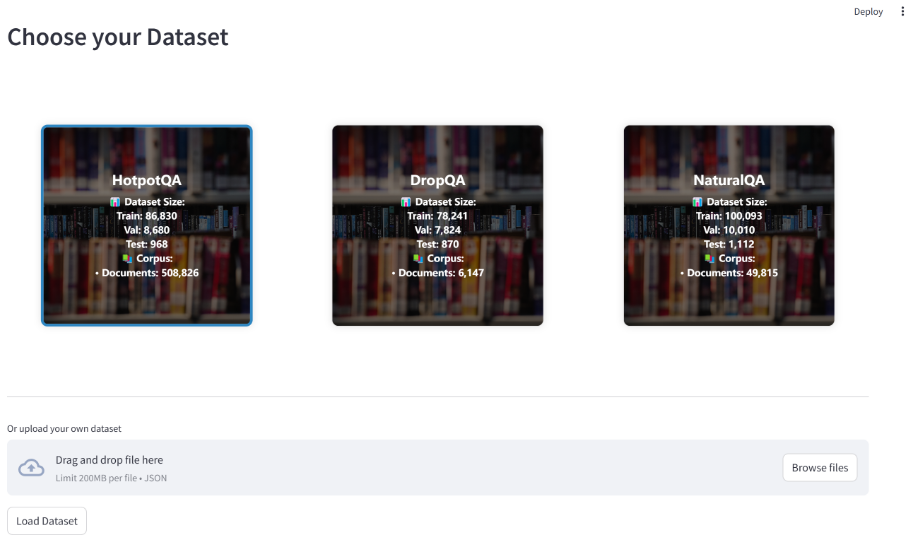
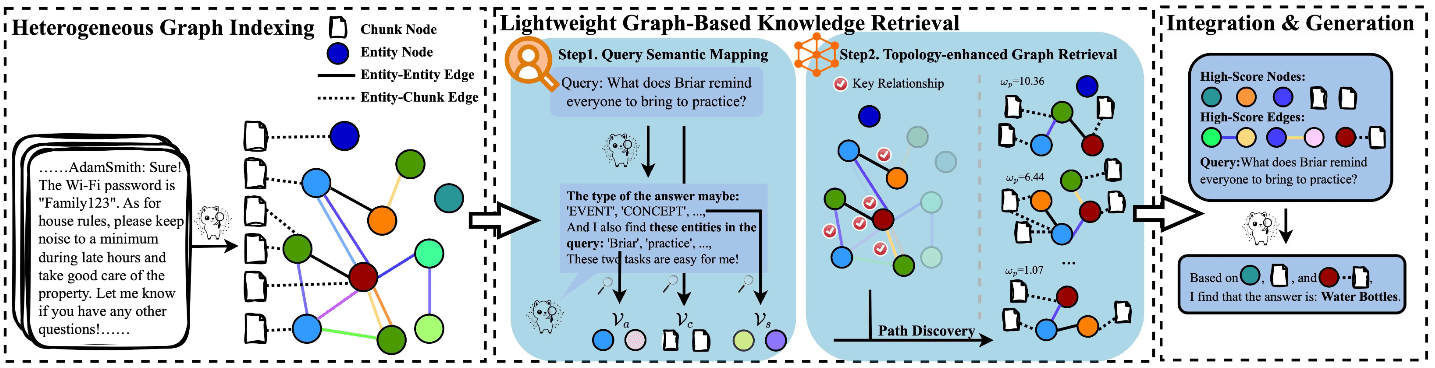
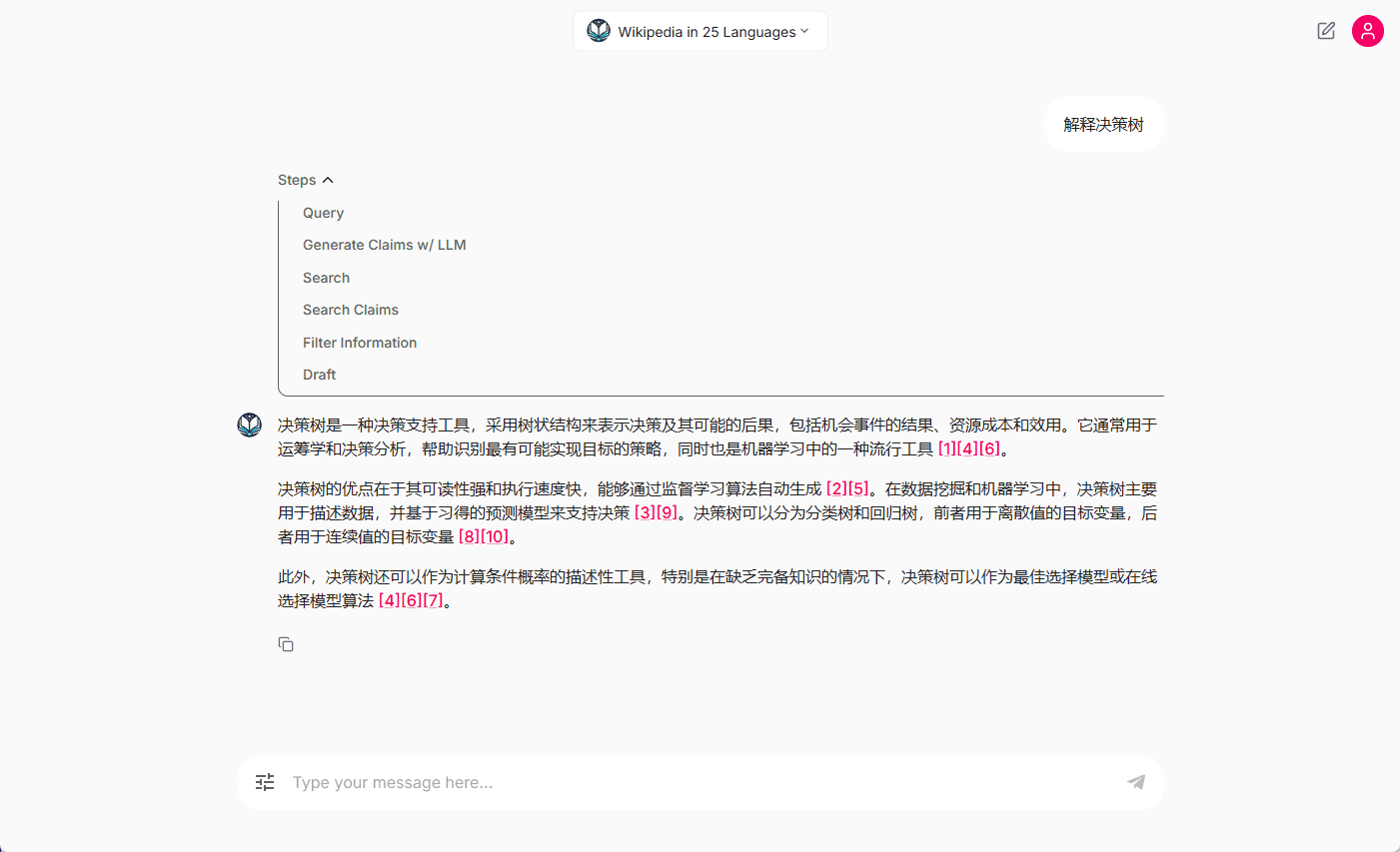
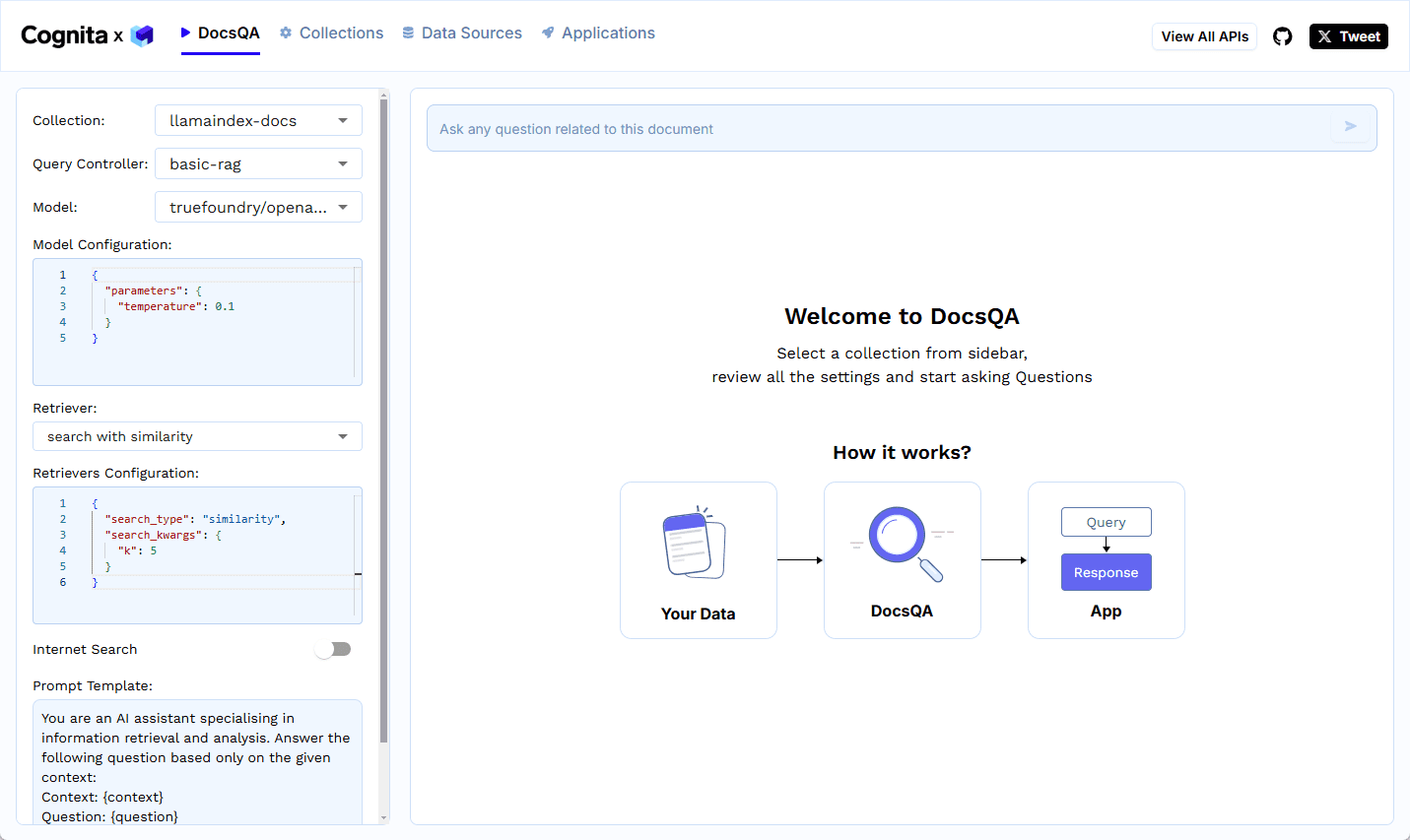
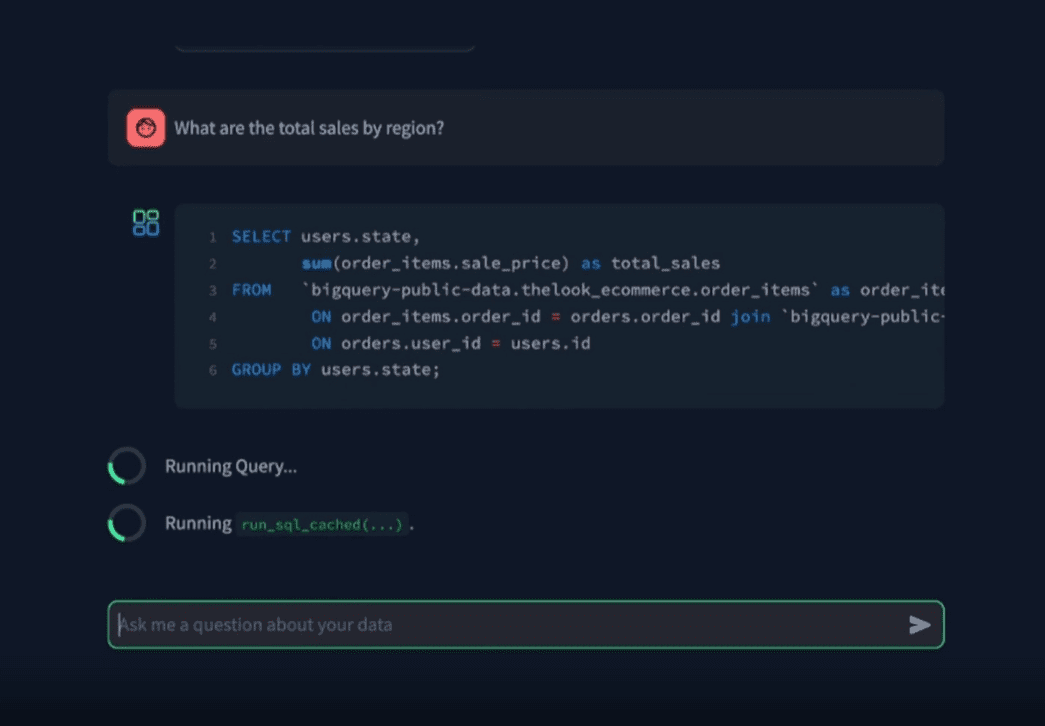
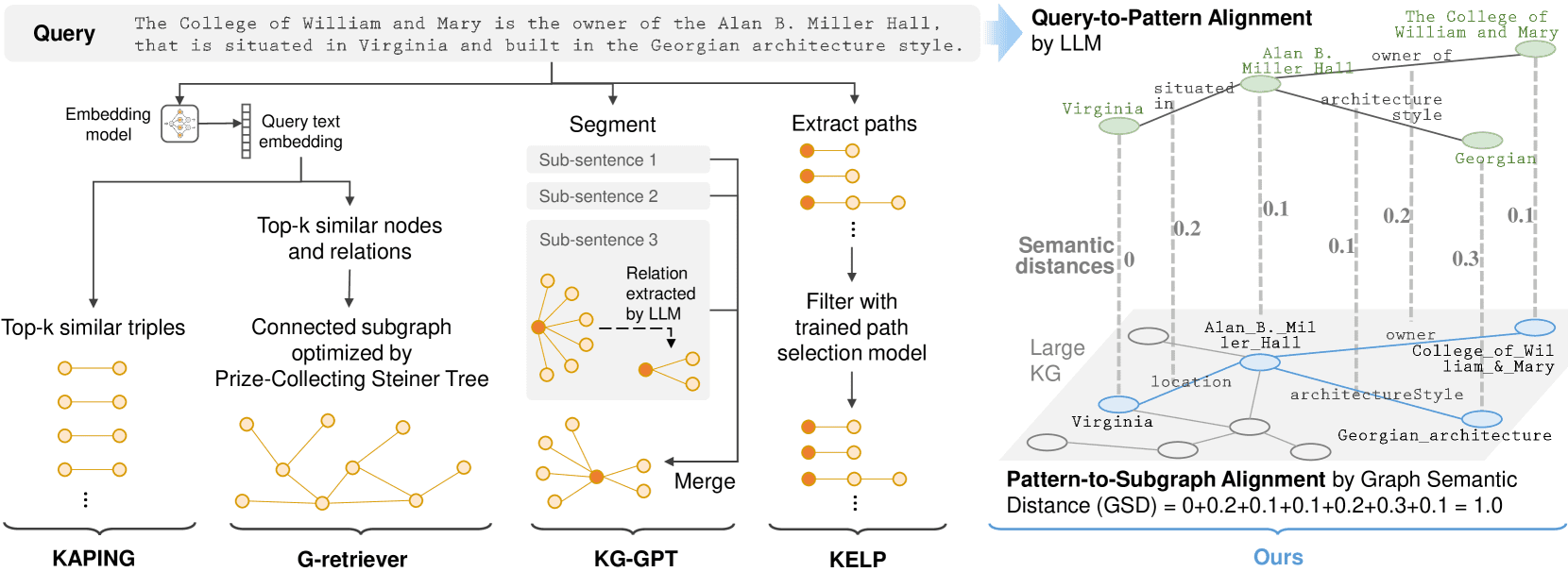
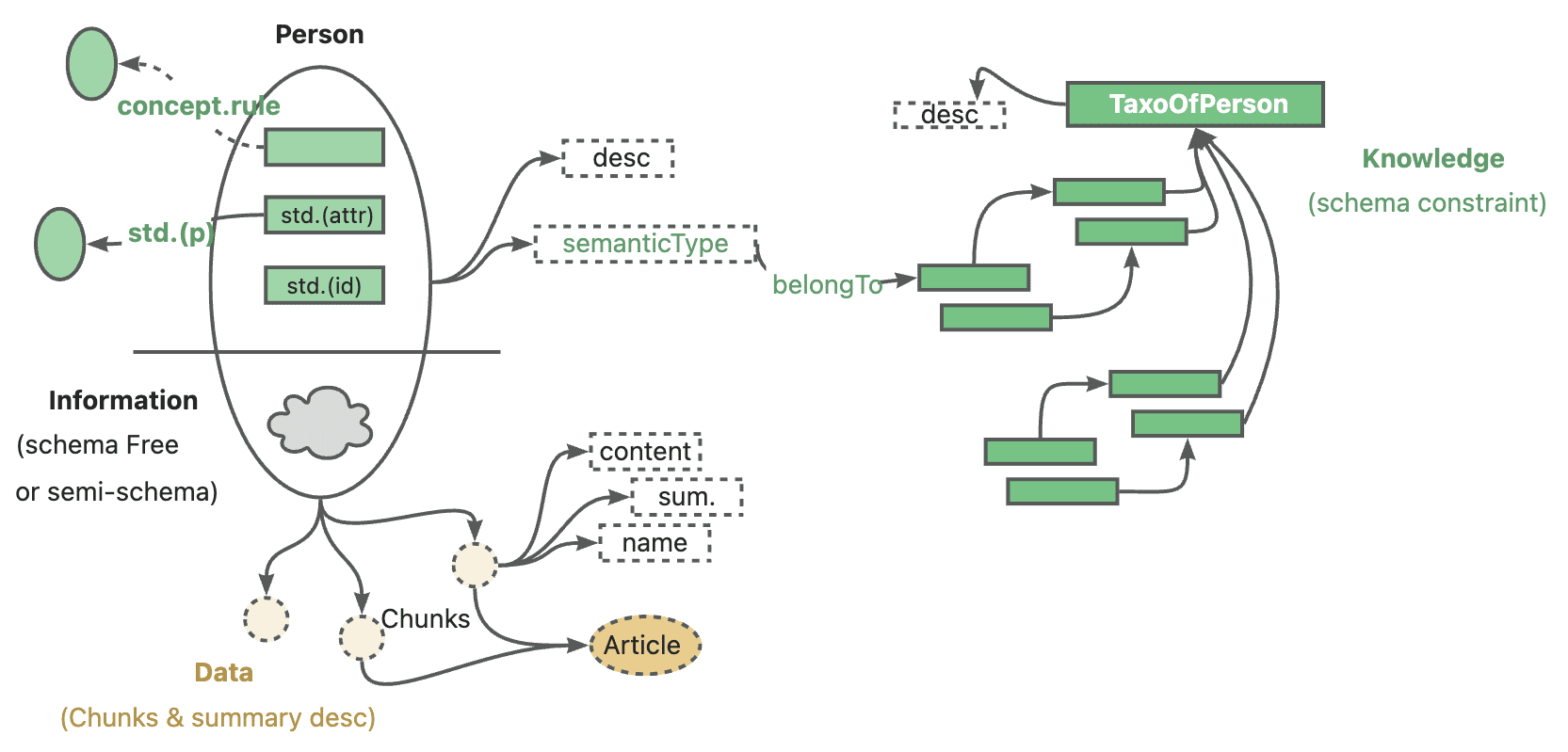
Introdução abrangente O Deep Recall é uma estrutura de memória de código aberto e de classe empresarial projetada para modelos de linguagem grandes (LLMs). Ele oferece capacidade de resposta hiperpersonalizada por meio de recuperação e integração contextuais eficientes. A estrutura usa uma arquitetura de três camadas, incluindo um serviço de memória, um serviço de raciocínio e um coordenador, com suporte...