Step-Audio: uma estrutura de interação de voz multimodal que reconhece a fala e se comunica usando a fala clonada, entre outros recursos

Introdução geral
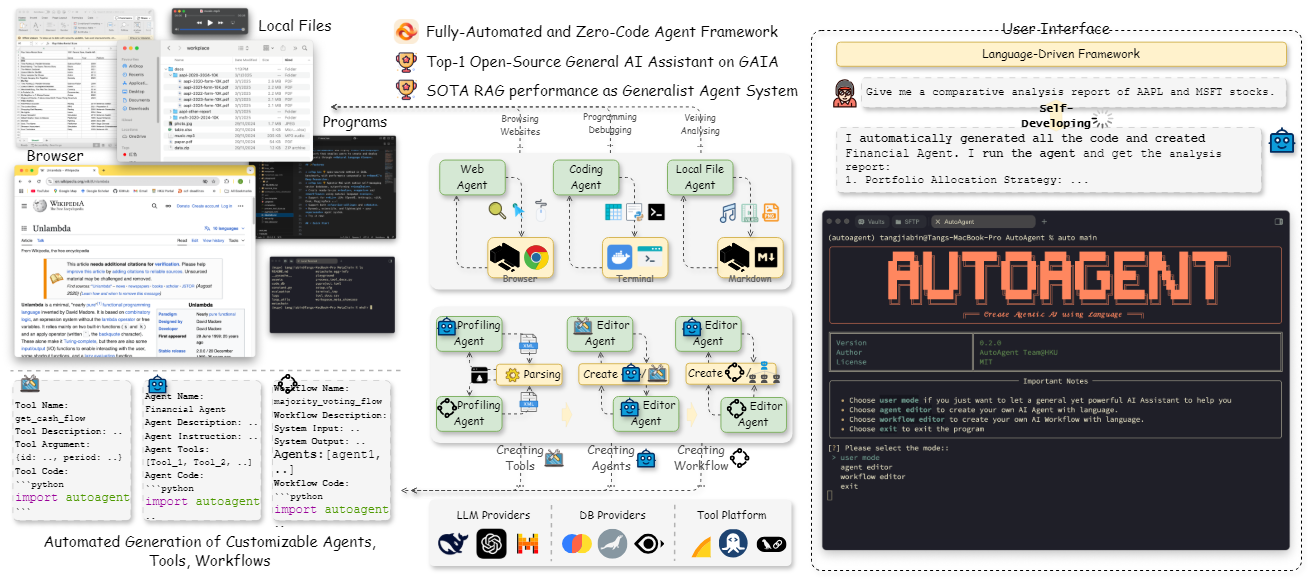
O Step-Audio é uma estrutura de interação de voz inteligente de código aberto projetada para fornecer recursos de geração e compreensão de fala prontos para uso em ambientes de produção. A estrutura oferece suporte a diálogos em vários idiomas (por exemplo, chinês, inglês, japonês), fala emocional (por exemplo, feliz, triste), dialetos regionais (por exemplo, cantonês, Szechuan) e taxa de fala ajustável e estilos de rima (por exemplo, rap). O Step-Audio implementa reconhecimento de fala, compreensão semântica, diálogo, clonagem de fala e síntese de fala por meio de um modelo multimodal de 130B parâmetros. Seu mecanismo de dados generativos elimina a dependência da coleta manual de dados TTS tradicional, gerando áudio de alta qualidade para treinar e publicar o modelo Step-Audio-TTS-3B com recursos eficientes.

Lista de funções
- Reconhecimento de fala em tempo real (ASR): converte a fala em texto e oferece suporte ao reconhecimento de alta precisão.
- Síntese de texto para fala (TTS): converte texto em fala natural, suportando uma ampla gama de emoções e entonações.
- Suporte a vários idiomas: lida com idiomas como chinês, inglês, japonês e dialetos como cantonês e sichuan.
- Controle de emoção e entonação: ajuste da emoção de saída da fala (por exemplo, feliz, triste) e do estilo de rima (por exemplo, RAP, cantarolar).
- Clonagem de voz: gere uma voz semelhante com base na voz de entrada, ofereça suporte ao design de voz personalizado.
- Gerenciamento de diálogo: mantenha a continuidade do diálogo e aprimore a experiência do usuário com o Context Manager.
- Cadeia de ferramentas de código aberto: fornece código completo e pesos de modelos que os desenvolvedores podem usar diretamente ou desenvolver duas vezes.
Usando a Ajuda
O Step-Audio é uma poderosa estrutura de interação de voz multimodal de código aberto para que os desenvolvedores criem aplicativos de voz em tempo real. A seguir, apresentamos um guia passo a passo detalhado para instalar e usar o Step-Audio, bem como seus recursos, para garantir que você possa começar a usá-lo com facilidade e aproveitar todo o seu potencial.
Processo de instalação
Para usar o Step-Audio, é necessário instalar o software em um ambiente com uma GPU NVIDIA. Abaixo estão as etapas detalhadas:
- Preparação ambiental::
- Certifique-se de que você tenha o Python 3.10 instalado em seu sistema.
- Instale o Anaconda ou o Miniconda para gerenciar o ambiente virtual.
- Verifique se o driver da GPU NVIDIA e o suporte CUDA estão instalados. Recomenda-se 4xA800/H800 GPUs (80 GB de RAM) para obter a melhor qualidade de geração.
- armazém de clones::
- Abra um terminal e execute o seguinte comando para clonar o repositório Step-Audio:
git clone https://github.com/stepfun-ai/Step-Audio.git cd Step-Audio
- Abra um terminal e execute o seguinte comando para clonar o repositório Step-Audio:
- Criação de um ambiente virtual::
- Crie e ative um ambiente virtual Python:
conda create -n stepaudio python=3.10 conda activate stepaudio
- Crie e ative um ambiente virtual Python:
- Instalação de dependências::
- Instale as bibliotecas e ferramentas necessárias:
pip install -r requirements.txt git lfs install - Clonagem de pesos adicionais do modelo:
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
- Instale as bibliotecas e ferramentas necessárias:
- Verificar a instalação::
- Executar um script de teste simples (como no código de exemplo)
run_example.py) para garantir que todos os componentes estejam funcionando corretamente.
- Executar um script de teste simples (como no código de exemplo)
Quando a instalação estiver concluída, você poderá começar a usar os vários recursos do Step-Audio. A seguir, há instruções detalhadas para operar as funções principais e as funções em destaque.
Funções principais
1. reconhecimento de fala em tempo real (ASR)
O recurso de reconhecimento de voz do Step-Audio converte a entrada de voz do usuário em texto, tornando-o adequado para a criação de assistentes de voz ou sistemas de transcrição em tempo real.
- procedimento::
- Certifique-se de que o microfone esteja conectado e configurado.
- Use o
stream_audio.pyScript para iniciar a transmissão de áudio ao vivo:python stream_audio.py --model Step-Audio-Chat - Quando você fala, o sistema converte a fala em texto em tempo real e exibe o resultado no terminal. É possível verificar o registro para confirmar a precisão do reconhecimento.
- Funções em destaqueReconhecimento de vários idiomas e dialetos, como entrada mista de chinês e inglês, ou fala localizada, como cantonês e sichuanês.
2. síntese de texto para fala (TTS)
Com o recurso TTS, você pode converter qualquer texto em fala natural, com suporte a uma ampla gama de emoções, velocidades de fala e estilos.
- procedimento::
- Prepare o texto a ser sintetizado, por exemplo, salve como
input.txt. - fazer uso de
text_to_speech.pyScripts para gerar fala:python text_to_speech.py --model Step-Audio-TTS-3B --input input.txt --output output.wav --emotion happy --speed 1.0 - Descrição do parâmetro:
--emotionEmoção: Defina a emoção (por exemplo, feliz, triste, neutra).--speedVelocidade da fala: ajuste a velocidade da fala (0,5 para lenta, 1,0 para normal, 2,0 para rápida).--outputEspecifica o caminho do arquivo de áudio de saída.
- Prepare o texto a ser sintetizado, por exemplo, salve como
- Funções em destaqueSuporte à geração de estilos de fala RAP e cantarolando, por exemplo:
python text_to_speech.py --model Step-Audio-TTS-3B --input rap_lyrics.txt --style rap --output rap_output.wav
这将生成一段带有 RAP 节奏的音频,非常适合音乐或娱乐应用。
#### 3. 多语言与情感控制
Step-Audio 支持多种语言和情感控制,适合国际化应用开发。
- **操作步骤**:
- 选择目标语言和情感,例如生成日语悲伤语气语音:
python generate_speech.py --language japanese --emotion sad --text "私は悲しいです" --output sad_jp.wav
- 方言支持:如果需要粤语输出,可以指定:
python generate_speech.py --dialect cantonese --text "I'm so hung up on you" --output cantonese.wav
- **特色功能**:通过指令可以无缝切换语言和方言,适合构建跨文化语音交互系统。
#### 4. 语音克隆
语音克隆允许用户上传一段语音样本,生成相似的声音,适用于个性化语音设计。
- **操作步骤**:
- 准备一个音频样本(如 `sample.wav`),确保音频清晰。
- 使用 `voice_clone.py` 进行克隆:
python voice_clone.py --input sample.wav --output cloned_voice.wav --model Step-Audio-Chat
- 生成的 `cloned_voice.wav` 将模仿输入样本的音色和风格。
- **特色功能**:支持高保真克隆,适用于虚拟主播或定制语音助手。
#### 5. 对话管理与上下文保持
Step-Audio 内置上下文管理器,确保对话的连续性和逻辑性。
- **操作步骤**:
- 启动对话系统:
python chat_system.py --model Step-Audio-Chat
- Insira texto ou fala e o sistema gera uma resposta com base no contexto. Exemplo:
- Usuário: "Como está o tempo hoje?"
- SISTEMA: "Por favor, diga-me sua localização e eu verificarei".
- Usuário: "Estou em Pequim".
- SISTEMA: "Pequim está ensolarada hoje, com uma temperatura de 15°C."
- Funções em destaqueSuporte a várias rodadas de diálogo, mantém informações contextuais e é adequado para bots de atendimento ao cliente ou assistentes inteligentes.
advertência
- Requisitos de hardwareMemória: Certifique-se de que a GPU tenha memória suficiente; recomenda-se 80 GB ou mais para obter o desempenho ideal.
- conexão de redeAlguns dos pesos do modelo precisam ser baixados do Hugging Face para garantir uma rede estável.
- detecção de errosSe você encontrar erros de instalação ou de tempo de execução, verifique os arquivos de registro ou consulte a página de problemas do GitHub para obter ajuda.
Seguindo essas etapas, você pode aproveitar ao máximo o poder do Step-Audio, quer esteja desenvolvendo aplicativos de fala em tempo real, criando conteúdo de fala personalizado ou construindo um sistema de diálogo multilíngue. A natureza de código aberto do Step-Audio também permite modificar o código e otimizar o modelo conforme necessário para atender às necessidades específicas do seu projeto.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...