
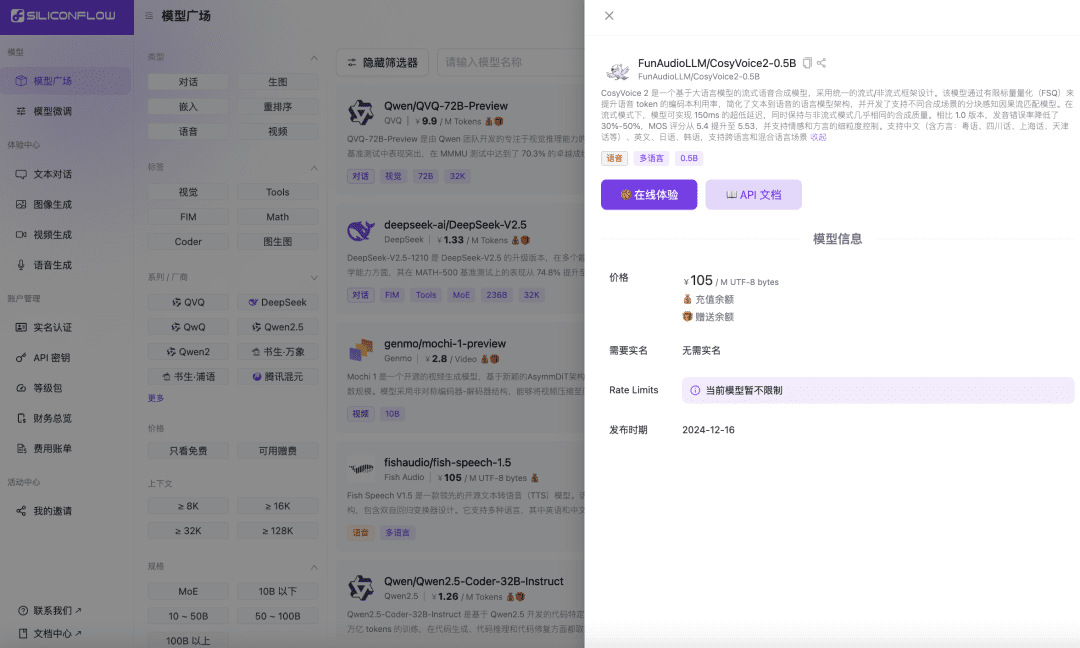
Siliconcloud entra em operação com o CosyVoice2 acelerado: síntese de fala em tempo real de 150 ms, suporte para idiomas e dialetos mistos


Recentemente, a equipe de fala do Ali Tongyi Lab lançou oficialmente o modelo de síntese de falaCosyVoice2. O modelo suporta streaming bidirecional de texto e fala, suporta multilinguismo, idiomas mistos e dialetos e oferece recursos de geração de fala mais precisos, estáveis, rápidos e melhores. Agora, o Siliconcloud, o fluxo baseado em silício do Siliconcloud, está oficialmente on-line com a versão de aceleração de inferência CosyVoice2-0.5B (preço ¥105/ M UTF-8 bytes, cada caractere ocupa de 1 a 4 bytes), que inclui o tempo de transmissão da rede, tornando a latência de saída do modelo tão baixa quanto 150 ms, trazendo uma experiência de usuário mais eficiente para seus aplicativos de IA generativa. Como outros modelos de síntese de linguagem no SiliconCloud, o CosyVoice2 suporta 8 tons predefinidos prontos para uso, tons predefinidos pelo usuário e tons dinâmicos, além de taxa de fala personalizável, ganho de áudio e taxa de amostragem de saída.
Experiência on-line
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
Documentação da API
https://docs.siliconflow.cn/api-reference/audio/create-speech
Conheça a versão acelerada por inferência do CosyVoice 2.0 do SiliconCloud.
Combinado com o serviço deModelo de reconhecimento de fala Ali SenseVoice-Small (disponível gratuitamente)Com a ajuda da API modelo, os desenvolvedores podem desenvolver com eficiência aplicativos de interação por voz de ponta a ponta, incluindo audiolivros, saídas de streaming de áudio, assistentes virtuais e outros aplicativos.
Recursos e desempenho do modelo
CosyVoice2 é um modelo de síntese de fala de streaming baseado em um grande modelo de linguagem, projetado usando uma estrutura unificada de streaming/não-streaming. O modelo aprimora a utilização do livro de códigos dos tokens de fala por meio da FSQ (Finite Scalar Quantisation), simplifica a arquitetura do modelo de linguagem de texto para fala e desenvolve um modelo de correspondência de fluxo causal com reconhecimento de pedaços que oferece suporte a diferentes cenários de síntese. No modo de streaming, o modelo atinge uma latência ultrabaixa de 150 ms, mantendo praticamente a mesma qualidade de síntese do modo sem streaming.
Além disso, o CosyVoice2 fez um progresso significativo na integração do modelo básico e do modelo de comando, não apenas continuando a oferecer suporte a emoções, estilos de fala e comandos de controle refinados, mas também adicionando a capacidade de lidar com comandos em chinês.
Especificamente, a versão 2.0 tem as seguintes vantagens em relação à versão 1.0 do CosyVoice:
Suporte a vários idiomas
- Idiomas compatíveis: chinês, inglês, japonês, coreano, dialetos chineses (cantonês, sichuan, shanghainês, tianjin, wuhan etc.)
- Idiomas cruzados e idiomas mistos: oferece suporte à clonagem de fala com amostra zero em cenários de idiomas cruzados e de troca de código.
latência ultrabaixa
- Suporte a streaming bidirecional: o CosyVoice 2.0 integra tecnologias de modelagem off-line e de streaming.
- Síntese rápida do primeiro pacote: alcance atrasos tão baixos quanto 150 ms, mantendo a saída de áudio de alta qualidade.
altamente preciso
- Melhoria da pronúncia: os erros de pronúncia foram reduzidos em 30% a 50% em comparação com o CosyVoice 1.0.
- Realização de benchmark: atingir a menor taxa de erro de caracteres no conjunto de testes difíceis do conjunto de avaliação do Seed-TTS.
alta estabilidade
- Consistência de tons: garante consistência de tons confiável para síntese de fala de amostra zero e entre idiomas.
- Síntese entre idiomas: aprimoramentos significativos em relação à versão 1.0.
fluência natural
- Aprimoramento rítmico e tonal: aumento da pontuação de avaliação MOS de 5,4 para 5,53.
- Flexibilidade de emoção e dialeto: suporta um controle mais preciso da emoção e o ajuste do sotaque do dialeto.
Avaliação do desenvolvedor
Quando o CosyVoice 2.0 foi lançado, alguns desenvolvedores o experimentaram primeiro. Alguns desenvolvedores disseram que ele suporta funções de controle ultrafinas e síntese de voz mais realista e natural. 
 No entanto, alguns usuários disseram que, apesar de terem sido atraídos por seu excelente desempenho na geração de fala, a implementação se tornou um grande desafio.
No entanto, alguns usuários disseram que, apesar de terem sido atraídos por seu excelente desempenho na geração de fala, a implementação se tornou um grande desafio.  Agora que o Siliconcloud lançou o CosyVoice 2.0, eliminando a necessidade de implantações complexas, você pode simplesmente chamar a API e acessar seus próprios aplicativos.
Agora que o Siliconcloud lançou o CosyVoice 2.0, eliminando a necessidade de implantações complexas, você pode simplesmente chamar a API e acessar seus próprios aplicativos.
Token Factory SiliconCloud Qwen 2.5 (7B) e mais de 20 modelos gratuitos!
Como uma grande plataforma de serviços em nuvem de modelo único, o SiliconCloud tem o compromisso de fornecer aos desenvolvedores APIs de modelo extremamente responsivas, acessíveis, completas e suaves. Além do CosyVoice2, o SiliconCloud já arquivou uma variedade de APIs de modelo, incluindo QVQ-72B-Preview, DeepSeek-VL2, DeepSeek- V2.5-1210, mochi-1-preview, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, QwQ-32B-Preview, Qwen2.5-Coder-32B-Instruct, InternVL2 Qwen2.5-7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat e dezenas de modelos de linguagem grandes e de código aberto, modelos de geração de imagem/vídeo, modelos de fala, modelos de código/matemáticos e modelos de vetor e reordenação. e modelos de reordenação. 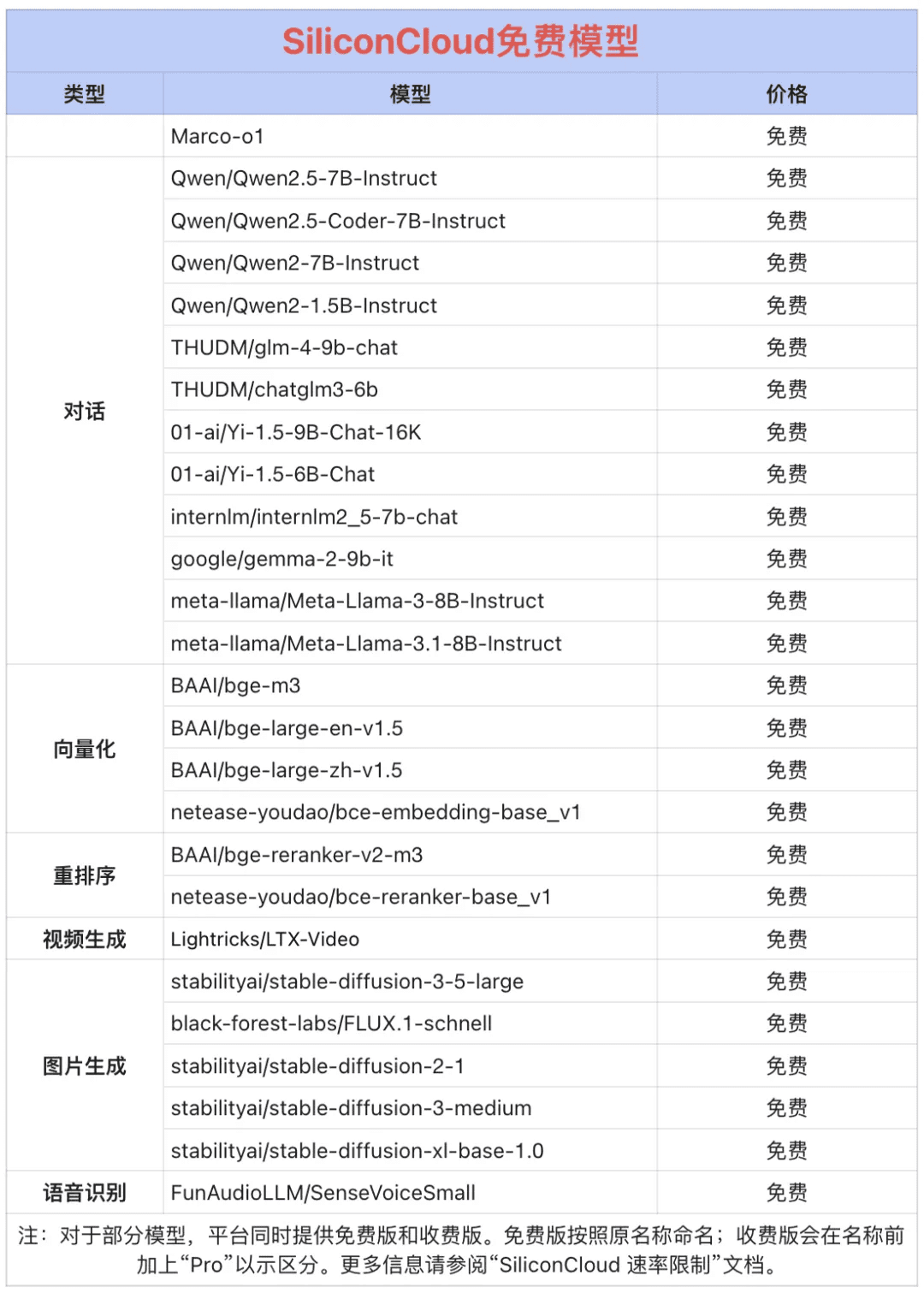 Entre elas, Qwen2.5 (7B), Llama3.1 (8B) e outras mais de 20 APIs de grandes modelos são de uso gratuito, para que os desenvolvedores e gerentes de produtos não precisem se preocupar com o custo aritmético do estágio de pesquisa e desenvolvimento e com a promoção em larga escala, e realizem o "Token Freedom".
Entre elas, Qwen2.5 (7B), Llama3.1 (8B) e outras mais de 20 APIs de grandes modelos são de uso gratuito, para que os desenvolvedores e gerentes de produtos não precisem se preocupar com o custo aritmético do estágio de pesquisa e desenvolvimento e com a promoção em larga escala, e realizem o "Token Freedom".
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...