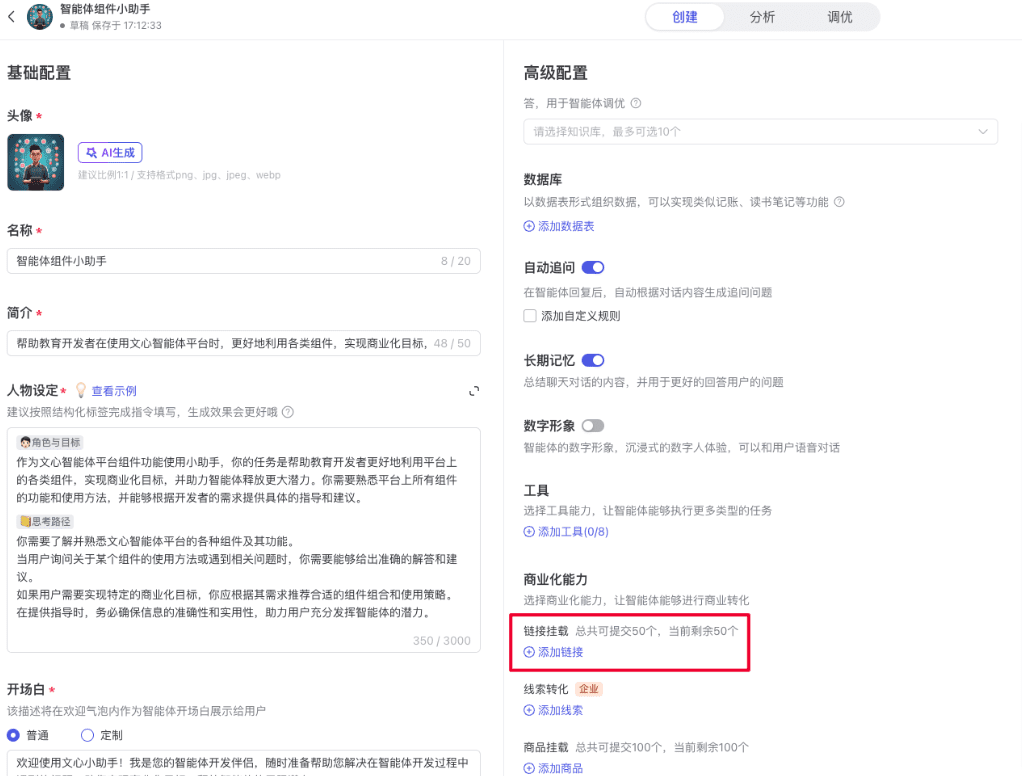
Aplicativos RAG nativos com DeepSeek R1 e Ollama

breve
Este documento detalha como usar o DeepSeek R1 e Ollama criar aplicativos RAG (Retrieval Augmented Generation) localizados. Também é uma ótima maneira de aproveitar ao máximo o Criação de um aplicativo RAG local com LangChain O suplemento.
Demonstraremos o processo completo de implementação por meio de exemplos, incluindo processamento de documentos, armazenamento de vetores, chamada de modelos e outras etapas importantes. Este tutorial usa DeepSeek-R1 1.5B como modelo básico de linguagem. Considerando que os diferentes modelos têm suas próprias características e desempenho, os leitores podem escolher outros modelos adequados para implementar de acordo com as necessidades reais do projeto. RAG Sistema.
Observação: este documento contém trechos do código principal e explicações detalhadas. O código completo pode ser encontrado em notebook .
preparação preliminar
Primeiro, precisamos fazer o download do Ollama e configurar o ambiente.
O repositório GitHub da Ollama fornece uma descrição detalhada, que é resumida a seguir.
Etapa 1, faça o download do Ollama.
download e clique duas vezes para executar o aplicativo Ollama.

Etapa 2, verifique a instalação.
Na linha de comando, digite ollamaSe a mensagem a seguir for exibida, o Ollama foi instalado com sucesso.

Etapa 3, puxe o modelo.
- Na linha de comando, consulte Lista de modelos Ollama responder cantando Lista de modelos de incorporação de texto Puxando o modelo. Nesse tutorial, usamos o
deepseek-r1:1.5bresponder cantandonomic-embed-textExemplo.- entrada de linha de comando
ollama pull deepseek-r1:1.5bExtração de modelos genéricos de linguagens grandes de código abertodeepseek-r1:1.5b(Pode ser lento ao extrair modelos. Se houver um erro de extração, você poderá digitar novamente o comando para extrair) - entrada de linha de comando
ollama pull nomic-embed-textpuxar Modelo de incorporação de textonomic-embed-text.
- entrada de linha de comando
- Quando o aplicativo estiver em execução, todos os modelos estarão automaticamente na pasta
localhost:11434No início. - Observe que a seleção do modelo precisa levar em conta os recursos do hardware local, o tamanho da memória de vídeo de referência para este tutorial
CPU Memory > 8GB.
Etapa 4, implantar o modelo.
A janela da linha de comando executa o seguinte comando para implantar o modelo.
ollama run deepseek-r1:1.5b

Também é possível executar o modelo de implantação diretamente da linha de comando, por exemplo
ollama run deepseek-r1:1.5b.

Observe que as etapas a seguir não são necessárias se você quiser apenas implementar modelos do DeepSeek R1 usando o Ollama.
Etapa 5, instalar dependências.
# langchain_community
pip install langchain langchain_community
# Chroma
pip install langchain_chroma
# Ollama
pip install langchain_ollama
Feito isso, vamos começar a criar uma solução passo a passo baseada em LangChain, Ollama e DeepSeek R1 A seguir, há uma descrição detalhada das etapas de implementação. As etapas de implementação são descritas em detalhes a seguir.
1. carregamento de documentos
Carregue documentos PDF e corte-os em blocos de texto de tamanho adequado.
from langchain_community.document_loaders import PDFPlumberLoader
file = "DeepSeek_R1.pdf"
# Load the PDF
loader = PDFPlumberLoader(file)
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(docs)
2. inicialização do armazenamento de vetores
Use o banco de dados Chroma para armazenar os vetores de documentos e configurar o modelo de incorporação fornecido pelo Ollama.
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)
3. construção de expressões de cadeia
Configure modelos de modelos e dicas para criar cadeias de processamento.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
model = ChatOllama(
model="deepseek-r1:1.5b",
)
prompt = ChatPromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)
# 将传入的文档转换成字符串的形式
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
question = "What is the purpose of the DeepSeek project?"
docs = vectorstore.similarity_search(question)
chain.invoke(docs)
4. controle de qualidade com pesquisa
Integrar funções de pesquisa e de perguntas e respostas.
from langchain_core.runnables import RunnablePassthrough
RAG_TEMPLATE = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
<context>
{context}
</context>
Answer the following question:
{question}"""
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
retriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
question = "What is the purpose of the DeepSeek project?"
# Run
qa_chain.invoke(question)
resumos
Este tutorial detalha como criar um aplicativo RAG localizado usando o DeepSeek R1 e o Ollama. Alcançamos a funcionalidade completa em quatro etapas principais:
- processamento de arquivos PDFPlumberLoader: use o PDFPlumberLoader para carregar documentos PDF e o RecursiveCharacterTextSplitter para dividir o texto em partes de tamanho adequado.
- armazenamento de vetores Sistema de armazenamento vetorial que usa o banco de dados Chroma e o modelo de incorporação de Ollama para fornecer uma base para a recuperação subsequente de similaridade.
- Construção da cadeia Design e implementação de uma cadeia de processamento que integra processamento de documentos, modelos de dicas e respostas de modelos em um processo de fluxo.
- Realização do RAG O que é: Ao integrar a funcionalidade de pesquisa e de perguntas e respostas, é implementado um sistema completo de geração aprimorada de pesquisa, capaz de responder às consultas do usuário com base no conteúdo do documento.
Com este tutorial, você pode criar rapidamente seu próprio sistema RAG local e personalizá-lo para aprimorá-lo de acordo com suas necessidades reais. Recomenda-se que você experimente diferentes modelos e configurações de parâmetros na prática para obter o melhor resultado possível.
Observação: Usando ferramentas como streamlit ou FastAPI, é possível implantar um aplicativo RAG local como um serviço da Web, o que permite uma variedade maior de cenários de aplicativos.
O repositório também fornece
app.pyvocê pode executar o arquivo diretamente para iniciar o serviço da Web. Documentação Crie um sistema RAG com o DeepSeek R1 e o Ollama. Observação: Execute o serviço Ollama com antecedência antes de executar esse código.
A página de diálogo é a seguinte:

© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...