conceito básico
Na área de tecnologia da informação.Recuperação significa que, a partir de um grande conjunto de dados (geralmente um documento, página da Web, imagem, áudio, vídeo ou outra forma de informação), com base em uma consulta ou necessidade do usuário, oO processo de localização e extração eficiente de informações relevantes. Seu objetivo principal é encontrarInformações mais relevantes para as necessidades do usuárioe apresentá-lo ao usuário.
- ConsultaTermo de pesquisa: Um termo ou condição de pesquisa inserido pelo usuário.
- ÍndiceEstrutura de dados: uma estrutura de dados que pré-processa os dados para melhorar a eficiência da recuperação.
- RelevânciaNível de correspondência entre os resultados recuperados e a consulta.
Os esquemas de RAG baseados na criação de grandes bases de conhecimento de modelos geralmente não usam uma única técnica de "recuperação", por exemplo, a comumente usada: recuperação híbrida esparsa + densa. A seleção da técnica de recuperação precisa ser cuidadosamente adaptada ao conteúdo a ser recuperado, o que exige muita depuração.

O modelo de recuperação convencional
Os modelos de recuperação são classificados principalmente como: modelos booleanos, modelos de espaço vetorial, modelos probabilísticos, modelos de rede neural, modelos de gráfico (por exemplo, Knowledge Graph) e modelos de linguagem (por exemplo, GPT3).
Os principais modelos de recuperação podem ser "simplesmente" divididos em duas categorias, sendo que a principal diferença é como eles entendem e combinam o texto:
1. correspondência baseada em léxico/palavra-chave.
Esse tipo de modelo se concentra em consultas e documentos emPalavras que combinam literalmentesem uma compreensão mais profunda do significado por trás das palavras.
-
Ideia central. Contar as ocorrências de palavras em documentos e consultas e combiná-las.
-
Principais modelos.
-
Modelo booleano. Simplesmente faça a correspondência com base na presença ou ausência da palavra-chave (AND, OR, NOT).
-
Modelo de espaço vetorial (VSM). Os documentos e as consultas são representados como vetores de pesos de palavras, que são combinados por similaridade de vetores (por exemplo, similaridade de cosseno). Um método de ponderação comum é o TF-IDF.
-
BM25. Um modelo aprimorado baseado em estatísticas probabilísticas que leva em conta fatores como o tamanho do documento é a base de muitos mecanismos de pesquisa.
-
Prós. Simples, eficiente e fácil de implementar.
Desvantagens. Incapacidade de entender as relações semânticas das palavras e suscetibilidade a problemas como sinônimos e polissemia.
2. correspondência baseada em semântica/significado.
Os modelos de incorporação baseados em semântica, além de oferecer suporte a diferentes comprimentos e dimensões de texto incorporado, diferentes modelos de incorporação também têm diferentes maneiras de entender "frases", o que é uma prioridade na seleção de modelos de incorporação (embora a maioria deles use modelos mais gerais).
Por exemplo, a palavra "apple" (maçã) é semanticamente preferida a "fruit" (fruta) por alguns modelos e a "mobile phone" (telefone celular) por outros.
Esses modelos tentam entender a consulta e o documentoinformações semânticas profundase não apenas a correspondência superficial de palavras.
-
Ideia central. Mapeamento de texto para espaço semântico e correspondência por similaridade semântica.
-
Principais modelos.
-
Modelos de tópicos. Mineração de documentos para possíveis tópicos, recuperados por similaridade de tópicos (por exemplo, LDA).
-
Modelos de incorporação. O mapeamento de palavras, frases ou documentos em um espaço vetorial denso e de baixa dimensão captura informações semânticas.
-
Embeddings de palavras. Os exemplos incluem Word2Vec, GloVe, FastText.
-
Embeddings de frases. Os exemplos incluem o Sentence-BERT e o Universal Sentence Encoder. Embeddings da OpenAI.
-
-
Modelos de recuperação densos. As consultas e os documentos são codificados em vetores densos de alta dimensão usando modelos de aprendizagem profunda (geralmente o Transformer) e recuperados por similaridade de vetores. Os exemplos incluem DPR, Contriever e o Embeddings da OpenAI O sistema de recuperação construído.
-
Modelos de interação neural. Modelagem mais refinada das interações entre consultas e documentos, por exemplo, ColBERT, RocketQA.
-
Modelos de redes neurais de grafos. Os documentos e as consultas são construídos em gráficos e recuperados usando a estrutura do gráfico.
-
Prós. A capacidade de entender melhor o significado do texto, lidar com correlações semânticas e encontrar informações relevantes com mais precisão.
Desvantagens. Geralmente mais complexo e computacionalmente caro.
Principal diferença:
-
Modelos de correspondência lexical parecem "literais"concentrando-se nas ocorrências de palavras-chave.
-
Modelos de correspondência semântica analisam o "significado"O foco está nos significados intrínsecos e nas relações do texto.
Tabela de resumo:
| categorização | ideia central | Modelos principais | RAG Foco do aplicativo em |
| Correspondência baseada em vocabulário | Palavras que combinam literalmente | Modelos booleanos, modelos de espaço vetorial (VSMs), BM25 | Cenários iniciais ou simples |
| Correspondência baseada em semântica | Compreensão de informações semânticas profundas | Modelos de tópicos, modelos de incorporação de palavras, modelos de incorporação de frases (com Embeddings da OpenAI), modelos de pesquisa densos (incluindo aqueles baseados em Embeddings da OpenAI sistemas), modelos de interação de redes neurais, modelos de redes neurais gráficas | Seleção convencional, com foco especial em incorporação de frases e pesquisa intensiva |
Aplicativos no RAG
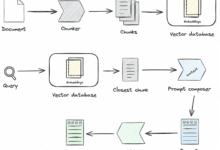
RAG (Recuperação-Augmented Generation)é uma estrutura de IA que combina técnicas de recuperação e geração cujo principal uso é melhorar a precisão e a relevância contextual do conteúdo gerado.
- estágio de recuperaçãoIdentificação de documentos ou trechos de uma grande base de conhecimento que sejam relevantes para a entrada do usuário.
- fase de geraçãoUse as informações recuperadas como contexto para gerar respostas ou conteúdo.
No RAG, o modelo de recuperação é responsável por fornecer fontes de informação de alta qualidade, enquanto o modelo generativo é responsável por gerar respostas em linguagem natural com base nessas informações. Como o RAG pode obter informações atualizadas de fontes de conhecimento externas, ele tem um desempenho particularmente bom ao responder a perguntas com uso intensivo de conhecimento.
Foco do aplicativo no RAG:
Em RAG (Retrieval Augmentation Generation).Os modelos de correspondência semântica são geralmente preferidosporque eles podem recuperar com mais precisão informações contextuais relevantes para a consulta do usuário, ajudando assim o modelo generativo a produzir respostas mais precisas e coerentes. Em particular.Modelos de incorporação de frases e modelos de recuperação densosPor exemplo, com base em Embeddings da OpenAI de recuperação, que é amplamente usado em sistemas RAG devido à sua excelente capacidade de representação semântica e eficiência de recuperação.
caso (lei)
1. aplicação da recuperação lexical (Lexical Retrieval)
-
Ideias centrais: O sistema de recuperação depende muito de consultas e documentos emLiteralmente, correspondência de palavras-chave.
-
Caso 1: localização de um comando específico na documentação técnica
-
Cena: Você está usando um software e quer saber como executar uma operação de cópia de arquivo e precisa encontrar o comando relevante.
-
Mecanismo de recuperação: O sistema RAG usa um modelo baseado em vocabulário (por exemplo, BM25) para pesquisar nos arquivos de ajuda do software passagens que contenham as palavras-chave "copy file", "file copy command" ou "copy file".
-
Exemplo de resultados de pesquisa: O sistema pode encontrar uma seção do documento intitulada "Comandos de gerenciamento de arquivos" que contém a seção "Usando o cp A seguir, há uma descrição do comando "Command to Copy File" (Comando para copiar arquivo).
-
Como ajudar a gerar: As instruções específicas para os comandos de contenção recuperados são fornecidas ao modelo de geração, que pode gerar etapas de ação mais precisas, por exemplo, "You can use the cp para copiar um arquivo. Por exemplo.cp source.txt destination.txt copiará source.txt para destination.txt."
-
Pontos principais: A recuperação se baseia na correspondência exata de palavras-chave. Se você usar uma frase diferente, como "mover cópias de documentos", talvez não obtenha os mesmos resultados.
-
-
Caso 2: Localizar um modelo específico em um catálogo
-
Cena: Você deseja comprar um modelo específico de impressora, por exemplo, "Modelo XYZ-123".
-
Mecanismo de recuperação: O sistema RAG pesquisa no banco de dados do catálogo as entradas que contêm o nome exato do modelo "XYZ-123".
-
Exemplo de resultados de pesquisa: O sistema encontrará entradas de produtos que contêm o nome, as especificações detalhadas, o preço e outras informações sobre a "Printer XYZ-123".
-
Como ajudar a gerar: As informações recuperadas sobre o produto podem ser usadas diretamente para gerar apresentações, consultas de preços ou links de compra, etc., sobre o modelo da impressora.
-
Pontos principais: Depende da correspondência exata dos modelos de produtos. Se o usuário inserir uma descrição vaga, como "impressora de alto desempenho", uma pesquisa baseada em termos pode não funcionar bem.
-
2. aplicativos de recuperação semântica
-
Ideias centrais: O sistema de recuperação entende a consulta e o documentoinformações semânticas profundasSe você não tiver exatamente as mesmas palavras-chave, poderá encontrar conteúdo relevante.
-
Caso 3: Como encontrar informações sobre os sintomas de uma doença na literatura médica
-
Cena: Você quer saber "Quais são os desconfortos comuns causados pela pressão alta?"
-
Mecanismo de recuperação: O sistema RAG usa um modelo baseado em semântica (por exemplo, pesquisa densa baseada em Sentence-BERT ou OpenAI Embeddings) para vetorizar a consulta e a literatura médica e, em seguida, encontra a passagem mais próxima do vetor de consulta no espaço semântico. Mesmo que os documentos não contenham exatamente o mesmo texto, por exemplo, usando "pressão arterial elevada" em vez de "hipertensão" ou descrições de sintomas específicos em vez de "mal-estar", eles ainda podem ser recuperados. ser pesquisados.
-
Exemplo de resultados de pesquisa: O sistema pode encontrar passagens que contenham o seguinte texto: "Pessoas com pressão alta geralmente relatam sintomas como dores de cabeça, tontura e aperto no peito. A pressão alta não controlada e prolongada pode levar a palpitações e dificuldade para respirar."
-
Como ajudar a gerar: As descrições recuperadas dos sintomas da hipertensão são fornecidas ao modelo generativo, que pode produzir uma resposta mais natural e abrangente: "A hipertensão pode causar uma variedade de desconfortos, geralmente incluindo dor de cabeça, tontura e aperto no peito. A hipertensão grave ou prolongada também pode causar palpitações cardíacas e dificuldade para respirar."
-
Pontos principais: Ser capaz de entender sinônimos ("pressão arterial elevada" vs. "pressão arterial alta"), expressões próximas ("desconforto físico" vs. "dor de cabeça, tontura ") e conceitos relacionados que fornecem um contexto mais rico.
-
-
Caso 4: Como encontrar estilos de texto semelhantes na assistência à escrita criativa
-
Cena: Você está trabalhando em um romance de ficção científica e quer encontrar algumas passagens em um estilo literário semelhante para usar como inspiração. Você digita: "Descreva uma visão próspera de uma cidade do futuro repleta de edifícios imponentes e tráfego intenso".
-
Mecanismo de recuperação: O sistema RAG usa um modelo baseado em semântica para pesquisar em uma grande biblioteca de textos de ficção científica, procurando passagens que sejam semanticamente mais próximas de sua descrição, mesmo que não usem exatamente palavras-chave como "cidade do futuro" ou "boom".
-
Exemplo de resultados de pesquisa: O sistema pode encontrar passagens como: "Os gigantes de aço perfuravam as nuvens e as cortinas de vidro refletiam uma luz colorida. Carros voadores circulavam como ônibus entre os prédios, multidões se agitavam no chão e o zumbido da energia enchia a cidade que nunca dorme."
-
Como ajudar a gerar: As passagens recuperadas com humor e descrições semelhantes podem ser usadas como referência para o modelo generativo, ajudando-o a criar um texto mais alinhado com o estilo desejado.
-
Pontos principais: Ser capaz de entender o significado implícito, a coloração emocional e o estilo do texto vai além da simples correspondência de palavras-chave e se concentra mais nas semelhanças semânticas.
-
![Agente de IA: explorando o mundo fronteiriço da interação multimodal [Fei-Fei Li - clássico de leitura obrigatória] - Chief AI Sharing Circle](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)