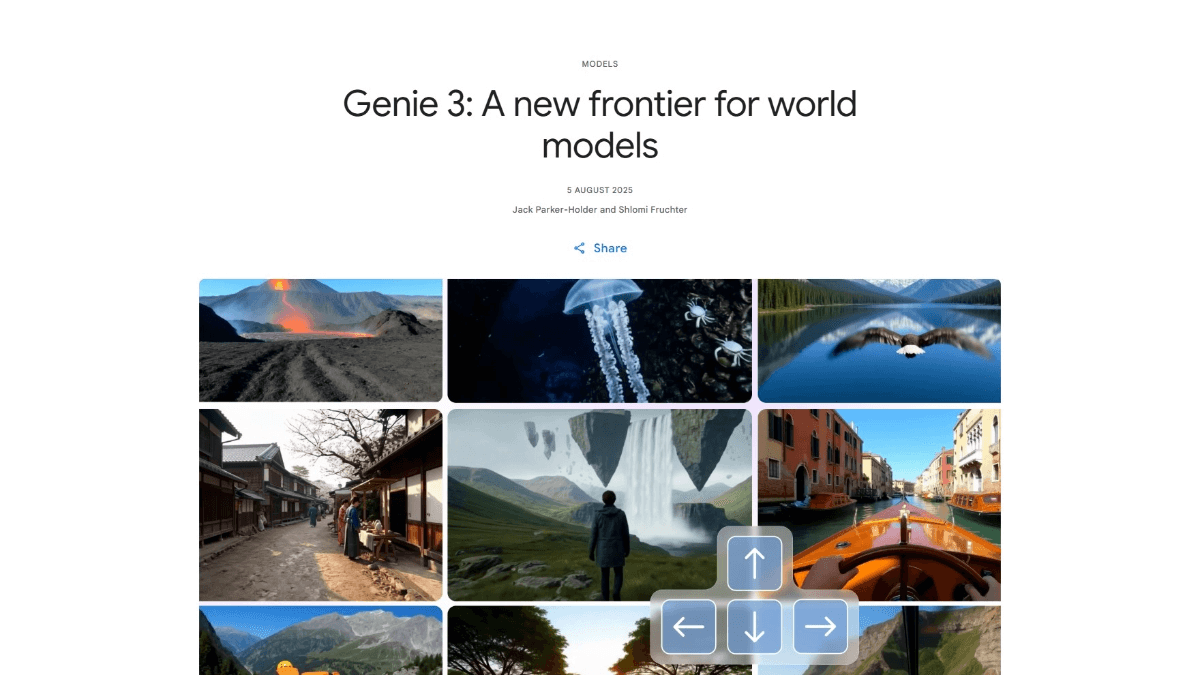
Flying Paddle PP-TableMagic: extração de informações estruturadas para tabelas complexas

O objetivo do reconhecimento de tabelas é analisar tabelas em imagens, identificar com precisão as estruturas das tabelas e os locais das células e reduzi-las a formatos de tabelas estruturadas (por exemplo, HTML). Na atual era da informação, uma grande quantidade de dados de tabela importantes ainda existe em um estado não estruturado (por exemplo, imagens de tabelas de estatísticas de informações em documentos digitalizados, tabelas de estatísticas de dados em declarações financeiras em PDF etc.), que não podem ser processadas diretamente de forma automática. Portanto, o reconhecimento de formulários tornou-se uma tecnologia fundamental nos cenários de aplicação da compreensão inteligente de documentos e da análise automática de dados. As soluções de reconhecimento de formulários de alto desempenho têm um valor de aplicação importante nas áreas de processamento de demonstrativos financeiros, análise de dados de pesquisa científica, contabilidade de sinistros de seguros etc., o que pode melhorar significativamente a eficiência do trabalho e reduzir os erros humanos. No entanto, diante de formatos de formulários complexos em diferentes cenários de aplicação, os modelos tradicionais de reconhecimento de formulários de uso geral geralmente são difíceis de adaptar. Por esse motivo, a Flying Paddle lançou uma nova solução de reconhecimento de tabelas, o PP-TableMagic.

PP-TableEfeito mágico




Análise técnica do PP-TableMagic
Deficiências na tecnologia atual
Atualmente, as soluções comuns de reconhecimento de tabelas geralmente adotam a seguinte estrutura: o usuário insere uma imagem de tabela, e o modelo prevê a estrutura HTML e as posições das células da tabela na imagem e, em seguida, a reduz a uma tabela HTML completa. Essa solução consegue um bom desempenho de previsão em cenários de tabelas simples e comuns, mas sofre de dois problemas:
- O número de parâmetros do modelo de reconhecimento de tabela geralmente é pequeno, e as duas tarefas, previsão da estrutura da tabela e previsão da posição da célula, têm grandes diferenças em objetivos e hierarquias semânticas de recursos dependentes, e há um limite superior de desempenho para a otimização conjunta.
- Quando os usuários ajustam o modelo em um cenário específico, o ajuste fino de determinados tipos de dados tabulares pode levar a uma "queda dupla" no desempenho do modelo, ou seja, o desempenho das categorias tabulares ajustadas aumenta, mas o desempenho de outras categorias diminui, e o desempenho geral pode diminuir em vez de aumentar.

Soluções e princípios técnicos do PP-TableMagic
Para aproveitar ao máximo o desempenho do modelo de reconhecimento de tabela leve e oferecer suporte ao ajuste fino direcionado ao usuário de qualquer tipo de dados de tabela, o PP-TableMagic adota a estrutura mostrada na figura abaixo:

O PP-TableMagic adota uma arquitetura de fluxo duplo para dividir as tabelas em tabelas com e sem fio. Em seguida, a tarefa de reconhecimento da tabela de ponta a ponta é dividida em duas subtarefas: detecção de células e reconhecimento da estrutura da tabela e, por fim, o resultado completo da previsão da tabela HTML é obtido pelo algoritmo de fusão de resultados auto-otimizado. Especificamente:
- A equipe da Flying Paddle pesquisa seu próprio modelo de classificação de tabela leve PP-LCNet_x1_0_table_cls para obter uma classificação de alta precisão de tabelas com e sem fio.
- A equipe de P&D lançou o primeiro modelo de detecção de table cell de código aberto do setor, o RT-DETR-L_table_cell_det, incluindo pesos de pré-treinamento de detecção de table cell com fio RT-DETR-L_wired_table_cell_det e pesos de pré-treinamento de detecção de table cell sem fio RT-DETR-L_wireless_table _cell_det para obter um posicionamento preciso de vários tipos de células de tabela.
- O Flying Paddle apresenta um novo modelo de reconhecimento de estrutura de tabela, o SLANeXt, que oferece melhor análise de estruturas de tabela do que o SLANet e o SLANet_plus, resultando em estruturas HTML de tabela mais precisas.
Na estrutura do PP-TableMagic, o SLANeXt, um novo modelo de reconhecimento de estrutura de tabela desenvolvido pela FeiPaddle, é particularmente importante. O reconhecimento da estrutura da tabela é o aspecto mais crítico do reconhecimento de tabelas, e a previsão de imagens de tabelas para expressões HTML depende de recursos de alto nível nas imagens. Portanto, o SLANeXt usa o Vary-ViT-B, que é mais capaz de representar recursos, como um codificador visual e alimenta os recursos extraídos no SLAHead para obter um reconhecimento de estrutura mais preciso. Além do aprimoramento da estrutura do modelo, a estratégia de treinamento também foi aprimorada. Com base no conjunto de dados de volume completo autoconstruído do Flying Paddle e no conjunto de dados ajustados de alta qualidade, os pesos de reconhecimento de estrutura da mesa com fio e da mesa sem fio são obtidos, respectivamente, por uma nova estratégia de pré-treinamento de três estágios.
Para avaliar a capacidade de reconhecimento de formas do SLANeXt, a equipe de P&D realizou vários testes com base em diversos tipos de conjuntos de dados. Os resultados dos experimentos são os seguintes:
Com base em um conjunto interno de revisão de reconhecimento de formulários de alto nível:

Baseado em dados reais de negócios dos parceiros:

Os resultados experimentais mostram que o SLANeXt tem uma melhoria significativa de desempenho em relação ao SLANet_plus.
Aplicativos algorítmicos
Ao usar o PP-TableMagic, você não só pode aproveitar os excelentes recursos de previsão de tabelas HTML para trabalhar diretamente com tabelas, mas também pode aproveitar ao máximo sua estrutura para permitir o ajuste fino do modelo personalizado.
Ao fazer o ajuste fino de outros modelos de reconhecimento de formulários de ponta a ponta para casos ruins, geralmente é difícil criar grandes conjuntos de treinamento quando apenas esse tipo de dados pode ser coletado, o que leva a um fenômeno de "um contra o outro", em que o desempenho do modelo diminui em vez de aumentar.

Além disso, o ajuste fino do modelo de reconhecimento de tabelas de ponta a ponta exige a anotação simultânea da estrutura da tabela e das posições das células dos dados de treinamento, o que consome muito tempo e trabalho na maioria dos cenários de aplicação.
Com a arquitetura de rede multimodelo do PP-TableMagic, quando há necessidade de melhorar o desempenho de um determinado tipo de tabela, apenas o modelo ou modelos mais críticos precisam ser ajustados, minimizando assim o impacto sobre o desempenho de reconhecimento de outros tipos de tabelas.

Portanto, quando o PP-TableMagic é ajustado em cenários reais, não apenas o desempenho de reconhecimento de cada tipo de tabela tem pouca influência um sobre o outro, mas também a anotação de dados só precisa ser rotulada com a categoria correspondente, o que economiza muita mão de obra.
Para os desenvolvedores com grande capacidade de codificação, a arquitetura do PP-TableMagic pode ser ajustada diretamente no nível da ramificação. Conforme mostrado na figura abaixo, quando um determinado tipo de dados de tabela é considerado muito importante, uma ramificação separada pode ser configurada para processamento, o que pode melhorar muito a capacidade geral de reconhecimento de tabelas.

O PP-TableMagic tem excelente desempenho e suporta alta personalização e alto grau de liberdade de ajuste fino do modelo direcionado para obter o melhor desempenho de reconhecimento de mesa em uma variedade de cenários de aplicativos, e é a primeira solução de código aberto para reconhecimento de mesa que pode obter alta personalização em todos os cenários.
Primeiros passos
montagem
Instale o PaddlePaddle:
# CPU 版本
python -m pip install paddlepaddle==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# GPU 版本,需显卡驱动程序版本 ≥450.80.02(Linux)或 ≥452.39(Windows)
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# GPU 版本,需显卡驱动程序版本 ≥545.23.06(Linux)或 ≥545.84(Windows)
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
Instale o pacote PaddleX Wheel:
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0rc0-py3-none-any.whl
Experiência rápida
O PP-TableMagic pode ser chamado diretamente.
O PaddleX fornece uma API Python fácil de usar para experimentar previsões de modelos com apenas algumas linhas de código.
Faça o download das imagens de teste:
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition_v2.jpg
O PaddleX suporta a chamada do PP-TableMagic a partir da linha de comando ou por meio de scripts Python (representados no PaddleX pela linha de produtos table_recognition_v2).
Método de linha de comando:
paddlex --pipeline table_recognition_v2
--use_doc_orientation_classify=False
--use_doc_unwarping=False
--input table_recognition.jpg
--save_path ./output
--device gpu:0
Método de script Python:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition_v2")
output = pipeline.predict(
input="table_recognition.jpg",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_xlsx("./output/")
res.save_to_html("./output/")
res.save_to_json("./output/")
Após o uso, os resultados do reconhecimento serão salvos no caminho especificado.
desenvolvimento secundário
Se você estiver satisfeito com o efeito do PP-TableMagic, poderá realizar diretamente o raciocínio de alto desempenho, a implantação de serviços ou a implantação do lado final na linha de produção. Se o cenário da tabela for particularmente vertical e ainda houver espaço para otimização, você também poderá usar o PaddleX para realizar o desenvolvimento secundário direcionado de um ou vários modelos no PP-TableMagic com base nos dados do seu próprio cenário, de modo a aproveitar ao máximo as vantagens de ajuste fino personalizado do PP-TableMagic. Com base no conveniente recurso de desenvolvimento secundário do PaddleX, a verificação de dados, o treinamento de modelos e a inferência de avaliação podem ser concluídos com o uso de comandos unificados, sem a necessidade de entender os princípios subjacentes da aprendizagem profunda, preparar os dados da cena de acordo com os requisitos e simplesmente executar os comandos para concluir a iteração do modelo. Aqui mostramos o processo de desenvolvimento secundário do modelo de detecção de células de mesa sem fio RT-DETR-L_wireless_table_cell_det:
python main.py -c paddlex/configs/modules/table_cells_detection/RT-DETR-L_wireless_table_cell_det.yaml
-o Global.mode=train
-o Global.dataset_dir=./path_to_your_datasets
Todos os outros modelos suportam desenvolvimento secundário, consulte os detalhes:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/pipeline_usage/tutorials/ocr_pipelines/table_recognition_v2.md#4-%E4%BA%8C%E6%AC%A1%E5%BC%80%E5%8F%91
Implementação orientada a serviços
Da mesma forma, o PaddleX fornece um recurso de implantação com serviços para o PP-TableMagic, encapsulando os recursos de raciocínio do reconhecimento de tabelas como serviços e permitindo que os clientes acessem esses serviços por meio de solicitações na Web para obter resultados de raciocínio de tabelas.
A PaddleX oferece dois tipos de implantação de serviços: implantação de serviços básicos e implantação de serviços de alta estabilidade. A Basic Serviced Deployment é uma solução de implantação de serviços simples e fácil de usar, com baixos custos de desenvolvimento, que permite aos usuários implantar e depurar resultados rapidamente. A implantação com serviços de alta estabilidade é baseada no NVIDIA Triton Inference Server, que oferece maior estabilidade e permite maior desempenho.
Para obter mais informações sobre o PP-TableMagic, consulte a documentação oficial da linha de produção do PaddleX:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/pipeline_usage/tutorials/ocr_pipelines/table_recognition_v2.md
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...