
Tutorial de instalação e uso do Ollama

Houve muitas edições anteriores sobre Ollama As informações nos tutoriais de instalação e implantação são bastante dispersas, portanto, desta vez, reunimos um tutorial completo em uma única etapa sobre como usar o Ollama em um computador local. Os tutoriais são voltados para iniciantes, a fim de evitar pisar em falso, e recomenda-se que aqueles que forem capazes de fazê-lo leiam a documentação oficial do Ollama. Em seguida, fornecerei um guia passo a passo para instalar e usar o Ollama.

Por que escolher Ollama para instalação local de modelos grandes
Muitos novatos não entendem, como eu, que existem outras ferramentas on-line de melhor desempenho para a implementação de modelos grandes, como:Inventário de estruturas LLM semelhantes ao Ollama: várias opções para modelos grandes implantados localmente Por que você recomenda instalar o Ollama no final?
Em primeiro lugar, é claro, é fácil de instalar em computadores pessoais, mas um dos pontos mais importantes é que o desempenho do modelo para implantação autônoma é melhor otimizado para os parâmetros, e a instalação não está sujeita a erros. Por exemplo, a mesma configuração de instalação no computador QwQ-32B Use o Ollama para facilitar o uso, mude para "mais potente". llama.cpp Ele pode estar travado, e até mesmo a resposta de saída não está correta. Há muitos motivos por trás disso e não consigo explicá-los claramente, portanto, não o farei. Saiba apenas que o Ollama contém o llama.cpp na parte inferior e, devido à melhor otimização, ele é executado de forma mais estável do que o llama.cpp.
Que tipo de arquivos de modelos grandes o Ollama pode executar?
O Ollama suporta arquivos de modelo nos dois formatos a seguir com diferentes mecanismos de inferência:
- Formato GGUF: através de
llama.cppRaciocínio. - formato dos safetensores: através de
vllmRaciocínio.
Isso significa que:
- Se for usado um modelo no formato GGUF, o Ollama chamará a função
llama.cppRealizar inferência eficiente de CPU/GPU. - Se for usado um modelo no formato safetensors, o Ollama usará o
vllmAlém das GPUs, as GPUs são frequentemente usadas para inferência de alto desempenho.
É claro que você não precisa se preocupar, basta saber que a maioria dos arquivos que você instala está no formato GGUF. Por que você enfatiza o GGUF?
Suporte GGUF Quantitativo (por exemplo, Q4, Q6_K)A capacidade deMantém um bom desempenho de inferência com gráficos e memória muito pequenosEmbora os sensores de segurança sejam geralmente modelos FP16/FP32 completos, eles são muito maiores e ocupam mais recursos. Você pode saber mais aqui:O que é quantificação de modelo: explicação dos tipos de dados FP32, FP16, INT8 e INT4.
Requisitos mínimos de configuração da Ollama
Sistema operacional: Linux: Ubuntu 18.04 ou posterior, macOS: macOS 11 Big Sur ou posterior
RAM: 8 GB para modelos 3B em execução, 16 GB para modelos 7B em execução, 32 GB para modelos 13B em execução
Espaço em disco: 12 GB para a instalação do Ollama e do modelo básico, espaço adicional necessário para armazenar os dados do modelo, dependendo do modelo que você estiver usando. Recomenda-se reservar 6 GB de espaço na unidade C.
CPU: Recomenda-se o uso de qualquer CPU moderna com pelo menos 4 núcleos e, para a execução do modelo 13B, recomenda-se o uso de uma CPU com pelo menos 8 núcleos.
GPU (opcional): Você não precisa de uma GPU para executar o Ollama, mas ela pode melhorar o desempenho, especialmente ao executar modelos maiores. Se você tiver uma GPU, poderá usá-la para acelerar o treinamento de modelos personalizados.
Instalar Ollama
Acesse: https://ollama.com/download
Basta escolher de acordo com o ambiente do computador e a instalação é muito simples. A única coisa a se prestar atenção aqui é que o ambiente de rede pode fazer com que a instalação não seja feita corretamente.
Instalação do macOS: https://ollama.com/download/Ollama-darwin.zip
Instalação do Windows: https://ollama.com/download/OllamaSetup.exe
Instalação do Linux:curl -fsSL https://ollama.com/install.sh | sh
Imagem do Docker: (aprenda por conta própria no site oficial)
CPU ou GPU Nvidia:docker pull ollama/ollama
GPUs AMD:docker pull ollama/ollama:rocm

Após a conclusão da instalação, você verá o ícone do Ollama no canto inferior direito da área de trabalho. Se houver um alerta verde no ícone, isso significa que você precisa fazer a atualização.

Configuração da Ollama
O Ollama é muito fácil de instalar, mas a maioria das configurações precisa modificar as "variáveis de ambiente", o que é muito desagradável para os novatos. Listei todas as variáveis para aqueles que precisam consultar (não precisam se lembrar):
| parâmetros | Etiquetagem e configuração |
|---|---|
| OLLAMA_MODELS | Indica o diretório em que os arquivos de modelo estão armazenados; o diretório padrão éDiretório do usuário atualassumir (escritório) C:\Users%username%.ollama\modelsSistema Windows Não é recomendável colocá-lo na unidade COs discos podem ser colocados em outros discos (por exemplo E:\ollama\models) |
| OLLAMA_HOST | é o endereço de rede no qual o serviço ollama escuta, e o padrão é127.0.0.1 Se você quiser permitir que outros computadores acessem o Ollama (por exemplo, outros computadores em uma LAN), a opçãoConfigurações recomendadasestar bem 0.0.0.0 |
| OLLAMA_PORT | Indica a porta padrão na qual o serviço ollama escuta, cujo padrão é11434 Se houver um conflito de portas, você poderá modificar as configurações para outras portas (por exemplo8080etc.) |
| OLLAMA_ORIGENS | Indica a origem da solicitação do cliente HTTP, usando uma lista separada por vírgulas de meias colunas. Se o uso local não for restrito, ele pode ser definido como um asterisco * |
| OLLAMA_KEEP_ALIVE | Indica o tempo de sobrevivência do modelo grande depois que ele é carregado na memória; o padrão é5mSão 5 minutos. (por exemplo, um número simples 300 significa 300 segundos, 0 significa que o modelo é desinstalado assim que a resposta à solicitação é processada, e qualquer número negativo significa que ele foi mantido ativo) Recomenda-se definir o 24h O modelo permanece na memória por 24 horas, aumentando a velocidade de acesso. |
| OLLAMA_NUM_PARALLEL | Indica o número de solicitações simultâneas processadas; o padrão é1 (ou seja, processamento serial único e simultâneo de solicitações) As recomendações são ajustadas às necessidades reais |
| OLLAMA_MAX_QUEUE | Indica o comprimento da fila de solicitações; o valor padrão é512 Recomenda-se ajustar às necessidades reais; as solicitações que excederem o tamanho da fila serão descartadas |
| OLLAMA_DEBUG | indica a saída do registro de depuração, que pode ser definido na fase de desenvolvimento do aplicativo para1 (ou seja, produz informações detalhadas de registro para solução de problemas) |
| OLLAMA_MAX_LOADED_MODELS | Indica o número máximo de modelos carregados na memória ao mesmo tempo; o padrão é1 (ou seja, apenas um modelo pode estar na memória) |
1. modifique o diretório de download de arquivos de modelos grandes
Nos sistemas Windows, os arquivos de modelo baixados pelo Ollama são armazenados por padrão em um diretório específico na pasta do usuário. Especificamente, o caminho padrão geralmente éC:\Users\<用户名>\.ollama\models. Aqui.<用户名>refere-se ao nome de usuário de login atual do sistema Windows.

Por exemplo, se o nome de usuário de login do sistema foryangfanentão o caminho de armazenamento padrão do arquivo de modelo pode serC:\Users\yangfan\.ollama\models\manifests\registry.ollama.ai. Nesse diretório, os usuários podem encontrar todos os arquivos de modelo baixados pelo Ollama.
Observação: Os caminhos de instalação de sistemas mais novos geralmente são:C:\Users\<用户名>\AppData\Local\Programs\Ollama
Os downloads de modelos grandes podem facilmente ter vários gigabytes. Se o espaço na unidade C for pequeno, a primeira etapa a ser executada é modificar o diretório de download de arquivos de modelos grandes.
1. encontre o ponto de entrada para as variáveis de ambiente
A maneira mais fácil: Win+R para abrir a janela de execução, digite sysdm.cplSe quiser usar essa opção, abra as Propriedades do sistema, selecione a guia Advanced (Avançado) e clique em Environment Variables (Variáveis de ambiente).

Outros métodos:
1. Iniciar->Configurações->Sobre->Configurações avançadas do sistema->Propriedades do sistema->Variáveis de ambiente.
2. este computador -> Clique com o botão direito do mouse -> Propriedades -> Configurações avançadas do sistema -> Variáveis de ambiente.
3. Iniciar->Painel de controle->Sistema e segurança->Sistema->Configurações avançadas do sistema->Propriedades do sistema->Variáveis de ambiente.
4. caixa de pesquisa na parte inferior da área de trabalho->Input->Environmental Variables (Entrada->Variáveis de ambiente)
Ao entrar, você verá a tela a seguir:

2. modificar as variáveis de ambiente
Procure o nome da variável OLLAMA_MODELS em System Variables (Variáveis do sistema) e clique em New (Novo) se ela não estiver lá.


Se OLLAMA_MODELS já existir, selecione-o e clique duas vezes com o botão esquerdo do mouse ou selecione-o e clique em "Edit" (Editar).

O valor da variável é alterado para o novo diretório; neste caso, eu o alterei da unidade C para a unidade E, que tem mais espaço em disco.

Após salvar, é recomendável iniciar o computador em uma nova inicialização e usá-lo novamente para obter um resultado mais seguro.
2. modifique o endereço de acesso e a porta padrão
No navegador, digite o URL: http://127.0.0.1:11434/ , você verá a seguinte mensagem, indicando que ele está sendo executado; há alguns riscos de segurança aqui que precisam ser modificados, ainda nas variáveis de ambiente.

1. modificar OLLAMA_HOST
Se não houver, adicione um novo, se for 0.0.0.0 para permitir o acesso à extranet, altere-o para 127.0.0.1

2. modificar o OLLAMA_PORT
Se você não a tiver, adicione-a e altere 11434 para qualquer porta, como:11331(O intervalo de modificação da porta é de 1 a 65535), comece em 1000 para evitar conflito de portas. Observe o uso do inglês ":".

Lembre-se de reiniciar seu computador para obter a leitura recomendada sobre a segurança do Ollama:O DeepSeek incendeia o Ollama. Sua implantação local está segura? Cuidado com a aritmética "roubada"!
Instalação de modelos grandes
Ir para o URL: https://ollama.com/search

Selecionar modelo, selecionar tamanho do modelo, copiar comando

Acesso a ferramentas de linha de comando

Cole o comando para instalá-lo automaticamente

O download está sendo feito aqui, portanto, se estiver lento, considere a possibilidade de mudar para um ambiente de Internet mais feliz!

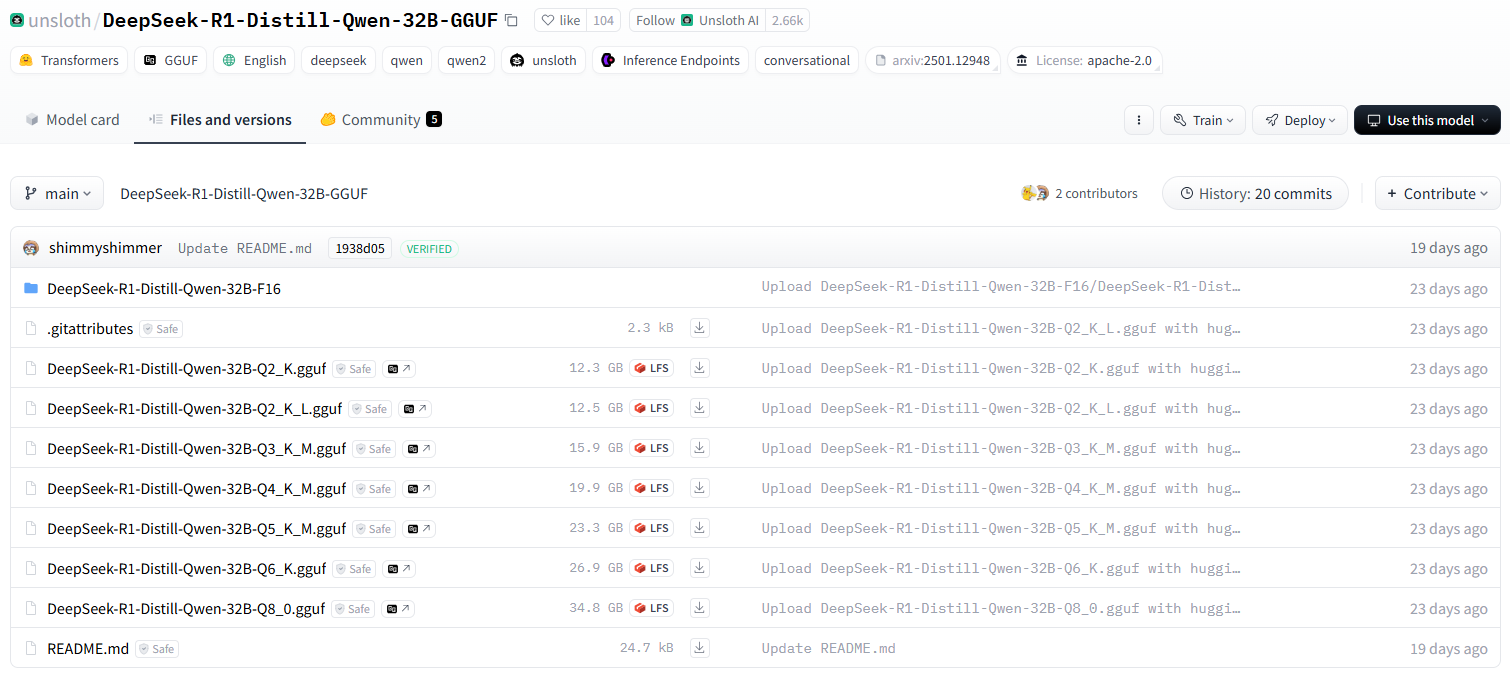
Se quiser fazer o download de modelos grandes que o Ollama não oferece, você certamente poderá fazê-lo. A grande maioria deles são arquivos GGUF no huggingface, e eu peguei uma versão especial quantificada do DeepSeek-R1 O 32B é usado como exemplo para demonstração da instalação.
1. instalando o formato de comando base do modelo de controle de versão quantitativo huggingface
Lembre-se do seguinte formato de comando de instalação
ollama run hf.co/{username}:{reponame}
2. seleção da versão quantitativa
Lista de todas as versões quantitativas: https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main
Esta instalação usa: Q5_K_M
3. comando de instalação de emenda

{username}=unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF
{reponame}=Q5_K_M
Splice para obter o comando de instalação completo:ollama run hf.co/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q5_K_M
4 - Realize a instalação no Ollama
Execute o comando de instalação

Você pode enfrentar falhas de rede (boa sorte com isso), repita o comando de instalação mais algumas vezes...
Ainda não está funcionando? Tente o seguinte comando.hf.co/Altere a seção parahttps://hf-mirror.com/(alternar para o endereço de espelho doméstico), o patchwork final do comando de instalação completo é o seguinte:
ollama run https://hf-mirror.com/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q5_K_M
Um tutorial completo para essa seção está disponível:Implementação privada sem GPUs locais DeepSeek-R1 32B
Comandos básicos do Ollama
| comando | descrições |
|---|---|
ollama serve | Lançamento do Ollama |
ollama create | Criação de modelos a partir do Modelfile |
ollama show | Exibição de informações do modelo |
ollama run | modelo operacional |
ollama stop | Interromper um modelo em execução |
ollama pull | Extração de modelos do registro |
ollama push | Empurrando modelos para o registro |
ollama list | Listar todos os modelos |
ollama ps | Lista de modelos em execução |
ollama cp | Modelos de replicação |
ollama rm | Excluir modelo |
ollama help | Exibir informações de ajuda para qualquer comando |
| simbolizar | descrições |
|---|---|
-h, --help | Mostrar informações de ajuda para o Ollama |
-v, --version | Exibição de informações de versão |
Ao inserir comandos em várias linhas, você pode usar a opção """ Executar um avanço de linha.

fazer uso de """ Avanço de linha final.

Para encerrar o serviço de inferência de modelo do Ollama, você pode usar o comando /bye.

Uso do Ollama em uma ferramenta de diálogo de IA nativa
A maioria das principais ferramentas de diálogo de IA nativas já está adaptada ao Ollama por padrão e não exige nenhuma configuração. Por exemplo Assistência à página OpenwebUI.
No entanto, algumas ferramentas locais de diálogo de IA exigem que você mesmo insira o endereço da API.http://127.0.0.1:11434/(observe se a porta foi modificada)

Algumas ferramentas de diálogo de IA baseadas na Web certamente oferecem suporte à configuração, por exemplo PróximoChat :

Se quiser que o Ollama em execução no seu computador local seja totalmente exposto para uso externo, aprenda a usar o cpolar ou o ngrok por conta própria, o que está além do escopo do uso para iniciantes.
O artigo parece ser muito longo; de fato, dentro dos quatro pontos de conhecimento muito simples, aprenda o uso futuro de Ollama basicamente sem obstáculos, vamos revisar novamente:
1. configuração de variáveis de ambiente
2. duas maneiras de instalar um modelo grande
3. lembre-se dos comandos básicos de execução e exclusão de modelos
4. uso em diferentes clientes
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...