
Kimi lança o MoBA: um avanço que permite o contexto infinito!

O Mixture of Experts e o Sparse attention possibilitam contextos praticamente ilimitados. Isso permite que o agente de IA RAG devore bases de código e documentos inteiros sem limitações contextuais.
📌 O desafio da atenção em contextos longos
Os transformadores ainda enfrentam uma carga computacional pesada quando as sequências se tornam muito grandes. O modelo de atenção padrão considera cada token A comparação com todos os outros tokens resulta em um aumento quadrático no custo computacional. Essa sobrecarga se torna um problema ao ler bases de código inteiras, documentos com vários capítulos ou grandes quantidades de texto jurídico.
📌 MoBA
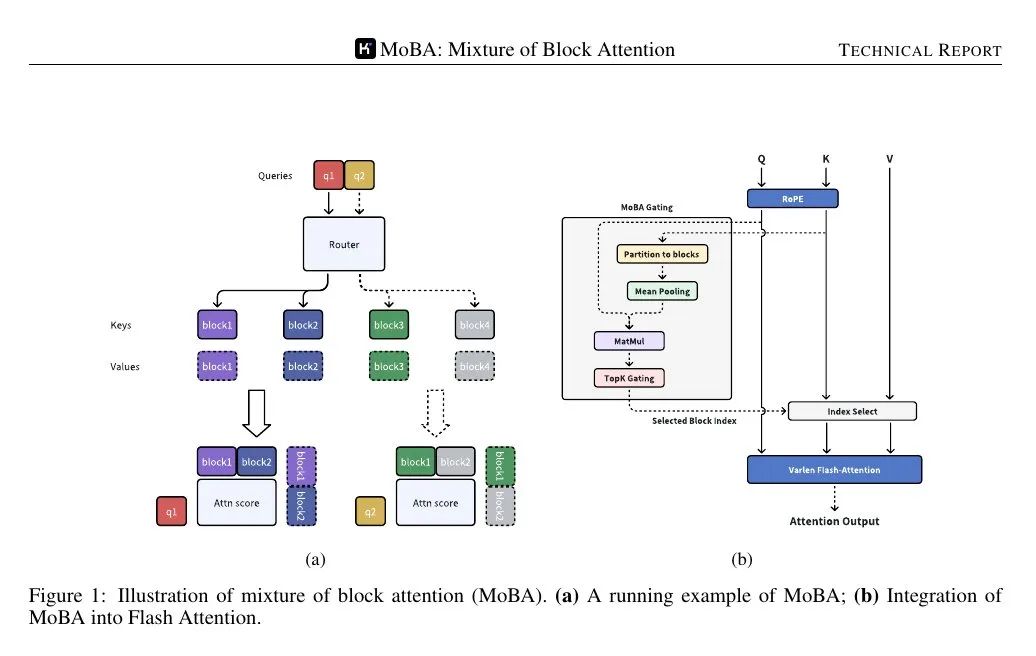
O MoBA (Mixture of Block Attention) aplica o conceito de Mixture of Experts ao mecanismo de atenção. O modelo divide a sequência de entrada em vários blocos e, em seguida, uma função de controle treinável calcula a pontuação de correlação entre cada token de consulta e cada bloco. Somente os blocos de maior pontuação são usados no cálculo da atenção, evitando assim prestar atenção a cada token na sequência completa.
Os blocos são definidos pela divisão da sequência em intervalos iguais. Cada token de consulta examina a representação agregada das chaves em cada bloco (por exemplo, usando pooling médio) e, em seguida, classifica sua importância, selecionando alguns blocos para o cálculo detalhado da atenção. O bloco que contém a consulta é sempre selecionado. O mascaramento causal garante que os tokens não vejam informações futuras, mantendo uma ordem de geração da esquerda para a direita.
📌 Alternância perfeita entre atenção plena e esparsa
O MoBA substitui o mecanismo de atenção padrão, mas não altera o número de parâmetros. Ele é semelhante ao mecanismo padrão de Transformador As interfaces são compatíveis, de modo que a atenção plena e esparsa pode ser alternada entre diferentes camadas ou fases de treinamento. Algumas camadas podem reservar a atenção plena para tarefas específicas (por exemplo, ajuste fino supervisionado), enquanto a maioria das camadas usa o MoBA para reduzir o custo computacional.
📌 Isso se aplica a pilhas maiores do Transformer, substituindo as chamadas de atenção padrão. O mecanismo de bloqueio garante que cada consulta se concentre apenas em um pequeno número de blocos. A causalidade é tratada filtrando blocos futuros e aplicando uma máscara local dentro do bloco atual da consulta.
📌 A figura abaixo mostra que a consulta é encaminhada para apenas alguns blocos "especializados" de chaves/valores, e não para toda a sequência. O mecanismo de controle atribui cada consulta ao bloco mais relevante, reduzindo assim a complexidade do cálculo da atenção de quadrática para subquadrática.
📌 O mecanismo de controle calcula uma pontuação de correlação entre cada consulta e a representação coesa de cada bloco. Em seguida, ele seleciona os k blocos de maior pontuação para cada consulta, independentemente da distância percorrida na sequência.
Como apenas alguns blocos são processados por consulta, o cálculo ainda é subquadrático, mas o modelo ainda pode saltar para tokens distantes do bloco atual se a pontuação de gating mostrar uma alta correlação.
Implementação do PyTorch
Esse pseudocódigo divide as chaves e os valores em blocos, calcula uma representação média agrupada de cada bloco e calcula a pontuação de gating (S) multiplicando a consulta (Q) pela representação agrupada.
Em seguida, ele aplica máscaras causais para garantir que as consultas não possam se concentrar em blocos futuros, usa o operador top-k para selecionar os blocos mais relevantes para cada consulta e organiza os dados para um cálculo eficiente da atenção.
📌 FlashAttention foram aplicados ao bloco de auto-atenção (posição atual) e ao bloco selecionado pelo MoBA, respectivamente, e, por fim, os resultados foram mesclados usando o softmax on-line.
O resultado final é um mecanismo de atenção esparso que preserva a estrutura causal e captura dependências de longo alcance, evitando o custo computacional quadrático total da atenção padrão.

Esse código combina a lógica de mistura de especialistas com atenção esparsa para que cada consulta se concentre em apenas alguns blocos.
O mecanismo de controle pontua cada bloco e consulta e seleciona os k "especialistas" principais, reduzindo assim o número de comparações de chave/valor.
Isso mantém a sobrecarga computacional da atenção em um nível subquadrático, permitindo que entradas extremamente longas sejam processadas sem aumentar a carga computacional ou de memória.
Ao mesmo tempo, o mecanismo de bloqueio garante que a consulta ainda possa se concentrar em tokens distantes quando necessário, preservando assim a capacidade do Transformer de processar o contexto global.
Essa estratégia baseada em blocos e portas é exatamente como o MoBA implementa contextos quase infinitos no LLM.

Observações experimentais
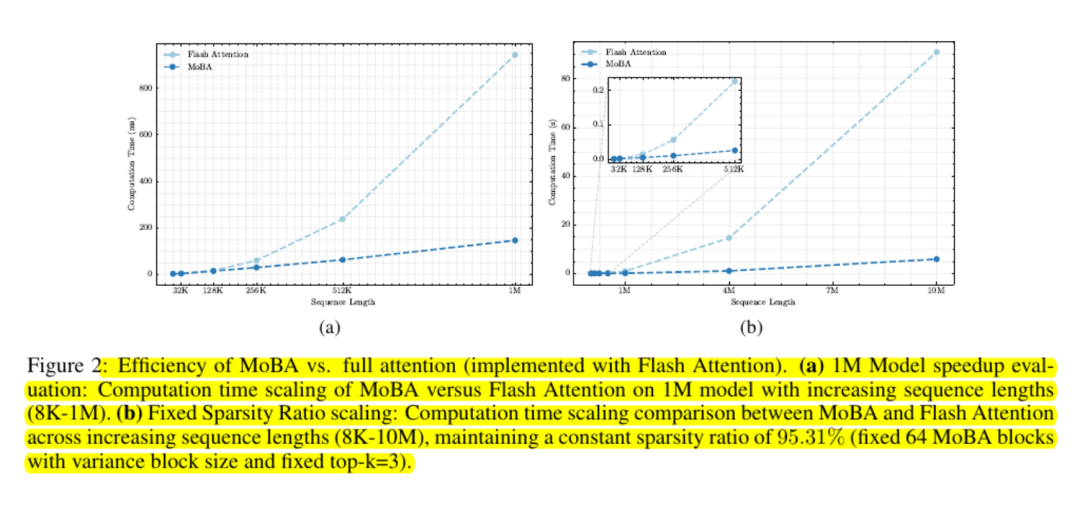
Os modelos que usam o MoBA são quase comparáveis à atenção plena em termos de perda de modelagem de linguagem e desempenho de tarefas posteriores. Os resultados são consistentes mesmo com comprimentos de contexto de centenas de milhares ou milhões de tokens. Os experimentos avaliados com "tokens de cauda" confirmam que importantes dependências de longa distância ainda são capturadas quando a consulta identifica partes relevantes.
Os testes de escalabilidade mostram que sua curva de custo é subquadrática. Os pesquisadores relatam aumentos de velocidade de até seis vezes em um milhão de tokens e ganhos maiores fora desse intervalo.
O MoBA mantém a facilidade de uso da memória, evitando o uso de matrizes de atenção total e utilizando kernels de GPU padrão para computação baseada em blocos.
Observações finais
O MoBA reduz a sobrecarga de atenção por meio de uma ideia simples: permitir que a consulta saiba quais blocos são importantes e ignorar todos os outros.
Ele preserva a interface de atenção padrão baseada em softmax e evita a imposição de um modelo local rígido. Muitos modelos de linguagem grandes podem integrar esse mecanismo de forma plug-and-play.
Isso torna o MoBA muito atraente para cargas de trabalho que precisam lidar com contextos extremamente longos, como a varredura de toda uma base de código ou o resumo de documentos enormes, sem precisar fazer grandes alterações nos pesos de pré-treinamento ou consumir muita sobrecarga de retreinamento.

© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...