Recentemente, descobri uma atraente estrutura de base de conhecimento de IA doméstica de código aberto: KAG (Knowledge Augmented Generation).
KAG Lançado em conjunto pelo Ant Group, pela Universidade de Zhejiang e por muitas outras organizações, ele se concentra na criação de bases de conhecimento em campos verticais. Os dados do artigo mostram que o KAG atinge o campo do governo eletrônico Taxa de precisão impressionante do 91.6%O sistema de perguntas e respostas da Microsoft, Inc., também se destaca em cenários como Q&A de assistência médica eletrônica.
Este artigo o levará a uma análise detalhada de KAG princípio, cenários de aplicação, comparação RAG O artigo também fornece tutoriais de instalação local e demonstrações para que você tenha uma experiência imersiva com a estrutura KAG de código aberto do Ant. Se estiver planejando usar IA para criar sua própria base de conhecimento, este artigo é imperdível!
O que é KAG? Conceitos básicos para uma nova geração de estruturas de bases de conhecimento
O KAG (Knowledge Augmented Generation) é uma estrutura de raciocínio de perguntas e respostas baseada no mecanismo OpenSPG e em modelos de linguagem grandes (LLMs). Seus principais conceitos sãoCombinando as vantagens duplas do gráfico de conhecimento e da recuperação de vetores, ele visa oferecer aos usuários um suporte mais rigoroso à decisão e serviços de recuperação de informações mais precisos.
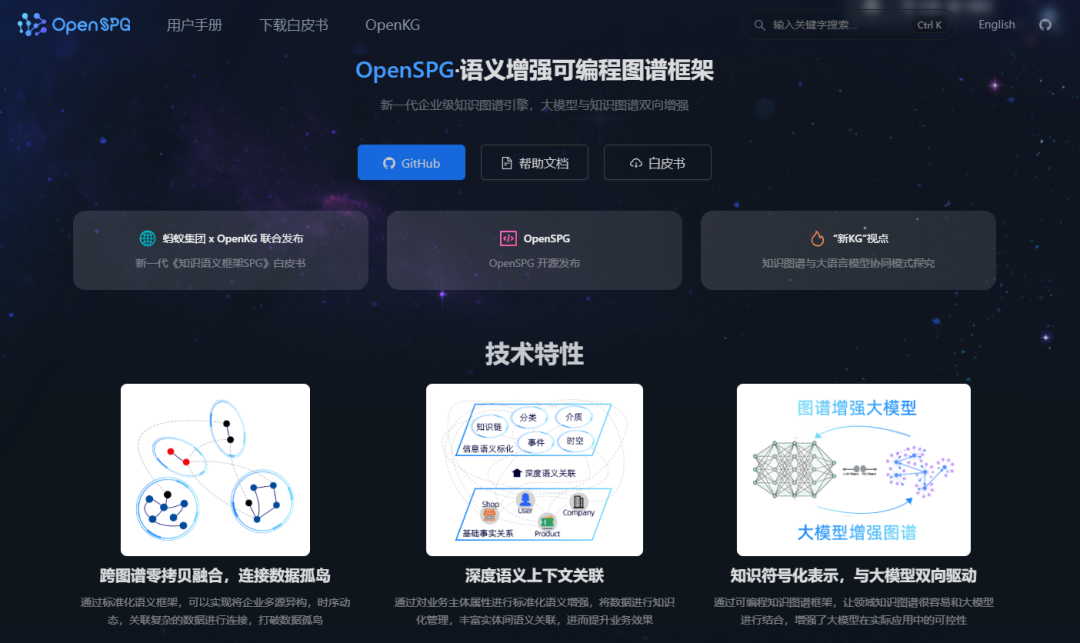
O KAG realiza a fusão profunda e o aprimoramento do LLM e do Knowledge Graph por meio das quatro tecnologias principais a seguir:
- Conhecimento de representação favorável ao LLMOtimização da estrutura dos gráficos de conhecimento para facilitar a compreensão e a exploração por modelos de linguagem de grande porte.
- Indexação cruzada entre gráficos de conhecimento e fragmentos de texto originaisEstabelecer links bidirecionais entre entidades e relacionamentos no gráfico de conhecimento e os fragmentos de texto originais para melhorar a eficiência e a precisão da recuperação.
- Mecanismo de raciocínio híbrido guiado por forma lógicaCombine o poder de raciocínio lógico do Knowledge Graph com o poder de compreensão semântica do LLM para obter testes de raciocínio mais complexos.
- Alinhamento de conhecimento com raciocínio semânticoConhecimento: garanta que o conhecimento no gráfico de conhecimento esteja alinhado com o espaço semântico do modelo de linguagem para aumentar a eficácia da utilização do conhecimento.
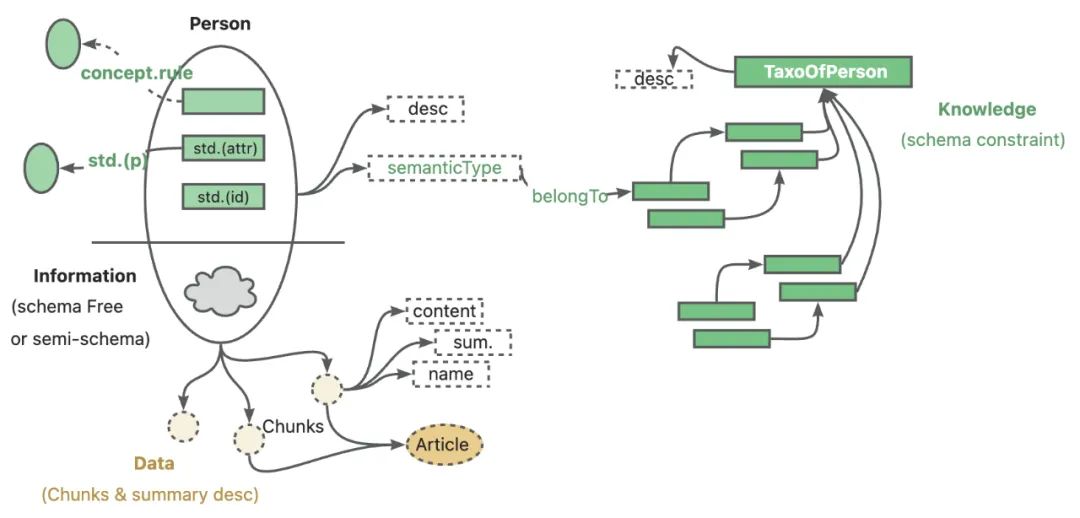
Em suma, o KAG combina de forma inovadora as vantagens do Knowledge Graph e do Vector Retrieval para criar uma estrutura avançada de base de conhecimento. Ele pode não apenas utilizar o recurso de raciocínio lógico do LLM, mas também combiná-lo com o gráfico de conhecimento para um raciocínio mais profundo, a fim de concluir tarefas complexas de recuperação de informações. Mais importante ainda, quando as informações do gráfico de conhecimento são insuficientes, o KAG também pode usar de forma inteligente a tecnologia de recuperação de vetores para complementar fragmentos de texto relevantes e garantir a abrangência e a precisão das respostas.
Visão geral da arquitetura geral do KAG
A estrutura do KAG consiste em dois módulos principais: construção de conhecimento (kg-builder) e solução de problemas (kg-solver).
- kg-builder O módulo se concentra na construção eficiente do conhecimento, otimizando a representação do conhecimento para LLM e oferecendo suporte à modelagem flexível do conhecimento e à indexação bidirecional.
- solucionador de kg O módulo é então responsável pela solução eficiente de problemas, que é obtida por um mecanismo de raciocínio híbrido que integra vários recursos, como recuperação, raciocínio gráfico, raciocínio linguístico e computação numérica para resolver problemas complexos.
- O terceiro módulo, kag-model, será de código aberto para aprimorar ainda mais a estrutura do KAG.
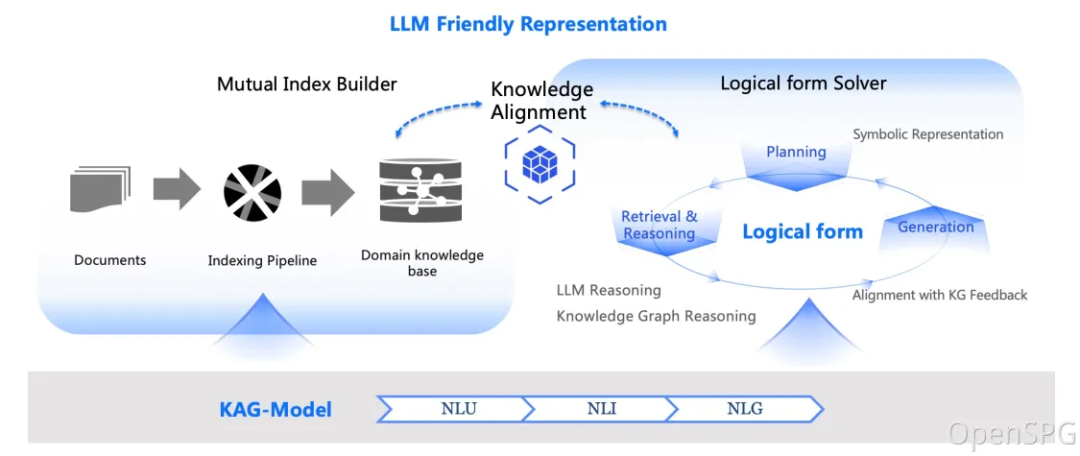
KAG vs. RAG tradicional: diferenças e vantagens explicadas
O RAG (Retrieval-Augmented Generation) tem sido amplamente usado como uma tecnologia de base de conhecimento comum. Então, quais são as diferenças e as vantagens do KAG em relação ao RAG? Nós os comparamos e analisamos por meio das seguintes dimensões:
1. representação do conhecimento:
- RAG. Ele se baseia principalmente na similaridade de vetores para a recuperação, e a representação do conhecimento é relativamente simples, o que dificulta o tratamento de problemas complexos que exigem raciocínio multihop.
- KAG. Adotar uma representação de conhecimento que seja mais amigável ao LLM, compatível com o conhecimento sem esquema e com restrição de esquema, que ofereça suporte à estrutura inter-indexada de conhecimento estruturado em gráficos e conhecimento textual, além de uma representação de conhecimento mais rica e estruturada.
2 Habilidades de raciocínio:
- RAG. Insensibilidade às relações lógicas do conhecimento e falta de habilidades de raciocínio lógico para lidar com problemas em áreas especializadas que exigem raciocínio complexo.
- KAG. Apresenta um mecanismo de raciocínio híbrido guiado por símbolos lógicos, com raciocínio lógico avançado e recursos de teste de fatos em vários pontos para lidar com problemas profissionais mais complexos.
3. desempenho:
- RAG. Apresenta baixo desempenho em tarefas de múltiplos saltos e tarefas de passagem cruzada, gerando textos relativamente fracos em termos de coerência e lógica.
- KAG. Ele tem um bom desempenho em tarefas com vários saltos e passagens cruzadas, melhorando significativamente a precisão do raciocínio e a cobertura de informações, além de gerar respostas mais precisas e abrangentes.
4. cenários aplicáveis:
- RAG. Ele é mais adequado para tarefas gerais de geração e recuperação de texto, mas o desempenho será limitado em áreas especializadas, como direito, medicina e ciências, em que é necessário um raciocínio complexo.
- KAG. Particularmente adequado para aplicativos que exigem raciocínio complexo e questionários factuais de vários locais Área de especializaçãoA empresa é capaz de fornecer serviços de conhecimento mais profissionais e precisos, como assuntos financeiros, médicos, jurídicos e governamentais.
Em suma, ao combinar Knowledge Graph e Vector Retrieval e otimizar profundamente os recursos de representação do conhecimento e raciocínio, o KAG mostra o potencial de superar a tecnologia RAG tradicional ao lidar com problemas complexos e questionar o conhecimento específico do domínio.
Implantação local de tutoriais em "nível de feed": instalação do KAG, uso, efeito da demonstração
As análises teóricas precisam ser testadas na prática! A seguir, mostrarei como instalar, implantar e usar o KAG localmente de forma manual, com uma demonstração simples dos resultados.
Recursos relacionados ao KAG:
- Endereço do Github.https://github.com/OpenSPG/KAG
- Site oficial.https://spg.openkg.cn/
Recomendações de configuração de hardware:
- CPU ≥ 8 núcleos
- Memória RAM ≥ 32 GB
- Disco rígido ≥ 100 GB
A configuração oficial recomendada é alta, mas, de acordo com meu teste real, ele pode ser executado basicamente sem problemas em um PC com Windows e 16 GB de RAM. Portanto, este tutorial demonstrará a instalação e o uso do KAG em um ambiente Windows.
Etapa 1: Instalar o Docker Desktop
A instalação e a implantação do KAG dependem de um ambiente Docker, portanto, certifique-se de ter o Docker Desktop instalado em seu computador.
Etapa 2: Criar o arquivo docker-compose.yml
- Crie uma pasta chamada KAG no diretório raiz da unidade D (ou outro disco).
- Dentro da pasta KAG, crie um novo arquivo chamado docker-compose.yml.
- Copie e cole o seguinte código YAML no arquivo docker-compose.yml e salve-o.
versão: "3.7"
serviços.
server.
restart: sempre
imagem: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latest
nome_do_contêiner: release-openspg-server
portas.
- "8887:8887"
depends_on.
- mysql
- neo4j
- minio
Volumes #.
# - /etc/localtime:/etc/localtime:ro
ambiente: /etc/localtime:/etc/localtime:ro
TZ: Ásia/Shanghai
LANG: C.UTF-8
comando: [
"java",
"-Dfile.encoding=UTF-8",
"-Xms2048m",
"-Xmx8192m",
"-jar".
"arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",
'---server.repository.impl.jdbc.host=mysql',
'---server.repository.impl.jdbc.password=openspg',
'---builder.model.execute.num=5',
'--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j', '--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?
'--cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j'
]
mysql.
restart: always
imagem: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latest
nome do contêiner: release-openspg-mysql
volumes: mysql_data:release-openspg-mysql:latest
- mysql_data:/var/lib/mysql
ambiente: mysql_data:/var/lib/mysql
TZ: Ásia/Shanghai
LANG: C.UTF-8
MYSQL_ROOT_PASSWORD. openspg
MYSQL_DATABASE: openspg
portas.
- "3306:3306"
comando: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci'
]
neo4j.
reiniciar: sempre
imagem: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latest
nome do contêiner: release-openspg-neo4j
ports.
- "7474:7474"
- "7687:7687"
ambiente.
- TZ=Ásia/Shanghai
- NEO4J_AUTH=neo4j/neo4j@openspg
- NEO4J_PLUGINS=["apoc"]
- NEO4J_server_memory_heap_initial__size=1G
- NEO4J_server_memory_heap_max__size=4G
- NEO4J_server_memory_pagecache_size=1G
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=*
- NEO4J_dbms_security_procedures_allowlist=*
NEO4J_dbms_security_procedures_unrestricted
- neo4j_logs:/logs
- neo4j_data:/data
minio.
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latest
nome do contêiner: release-openspg-minio
comando: server --console-address ":9001" /data
reiniciar: sempre
ambiente: MINIO_ACCESS_KNOWLEDGE
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio@openspg
TZ: Ásia/Shanghai
TZ: Ásia/Shanghai
- 9000:9000
- 9001:9001
volumes: minio_data:/data
- minio_data:/data
volumes: minio_data:/data
mysql_data.
neo4j_logs.
minio_data: minio_data:/data volumes: mysql_data.
minio_data.
Etapa 3: iniciar o serviço KAG
- Abra um prompt de comando e alterne para o diretório da pasta KAG (digite cmd no campo de endereço da pasta KAG e dê enter).
- Digite docker-compose up -d na linha de comando e dê enter para iniciar a instalação e a implantação automatizadas do KAG.
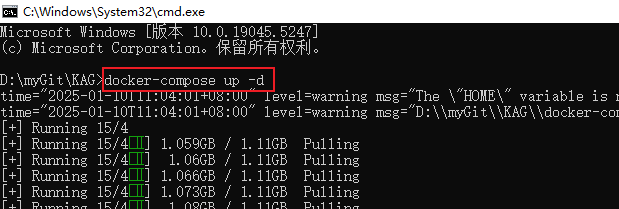
- Aguarde algum tempo; quando você vir que os serviços mysql, neo4j, openspg-server e minio são exibidos com o status Criado ou Iniciado, isso significa que o serviço KAG foi iniciado com êxito.
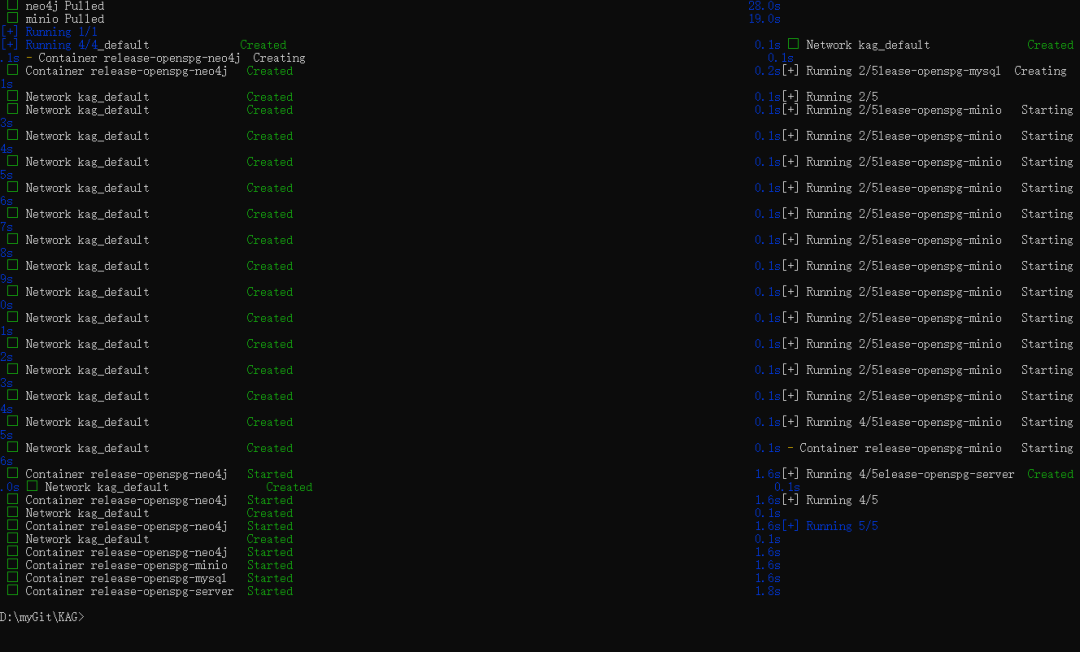
Etapa 4: Visite a página de administração de back-end do KAG
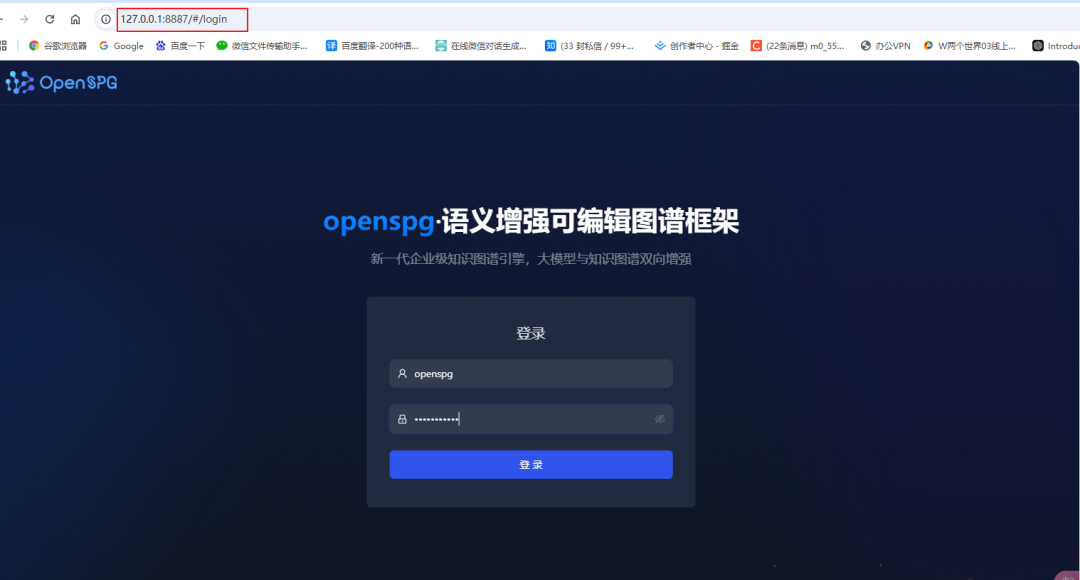
- Abra o navegador e digite o endereço 127.0.0.1:8887 para acessar a página de operação em segundo plano do KAG.
- Faça login no sistema usando o nome de usuário padrão openspg e a senha padrão openspg@kag.
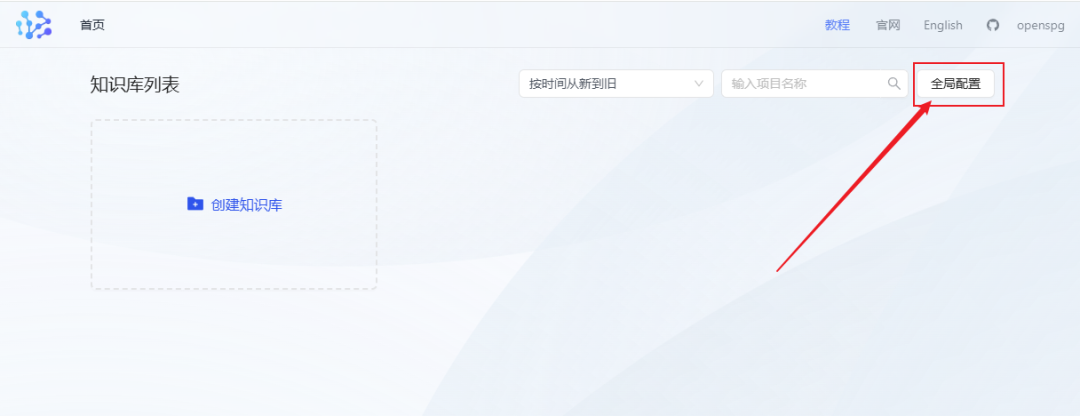
Etapa 5: Configurar o sistema KAG
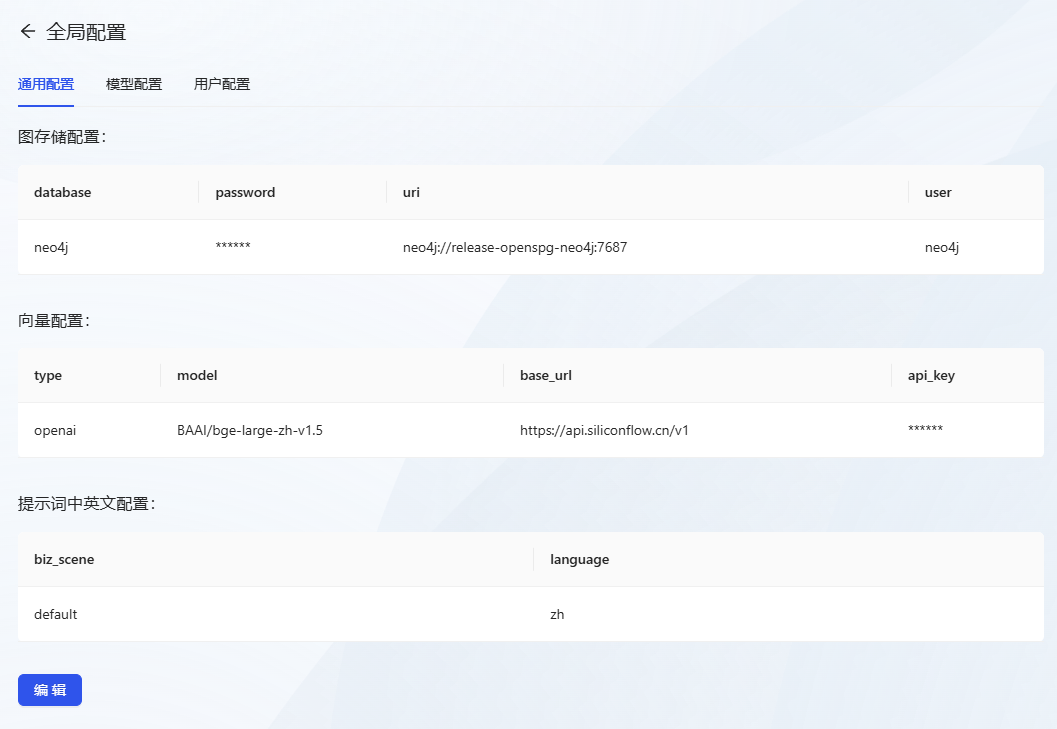
- Depois de fazer login, primeiro clique no menu Global Configuration (Configuração global).
- Configuração comumConfiguração: Execute a seguinte configuração
- Figura Configuração de armazenamento
- banco de dados:neo4j
- senha: neo4j@openspg
- uri:neo4j://release-openspg-neo4j:7687
- usuário:neo4j
- Dicas em inglês e chinês
- biz_scene: padrão
- Idioma: zh
- configuração de vetores (computação) (usando a API de modelagem vetorial gratuita)
- tipo: openai
- modelo: BAAI/bge-large-zh-v1.5
- base_url:https://api.siliconflow.cn/v1
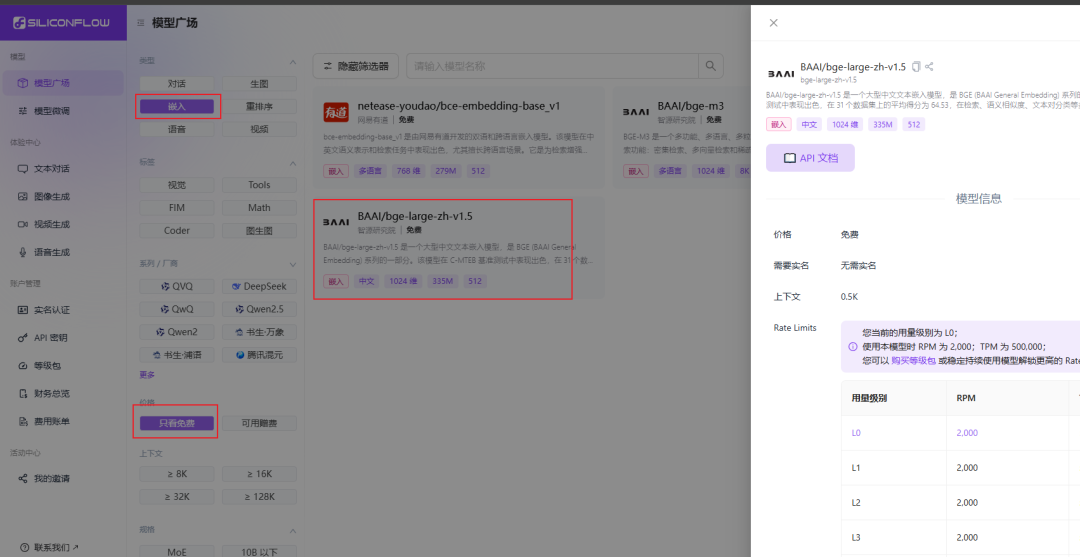
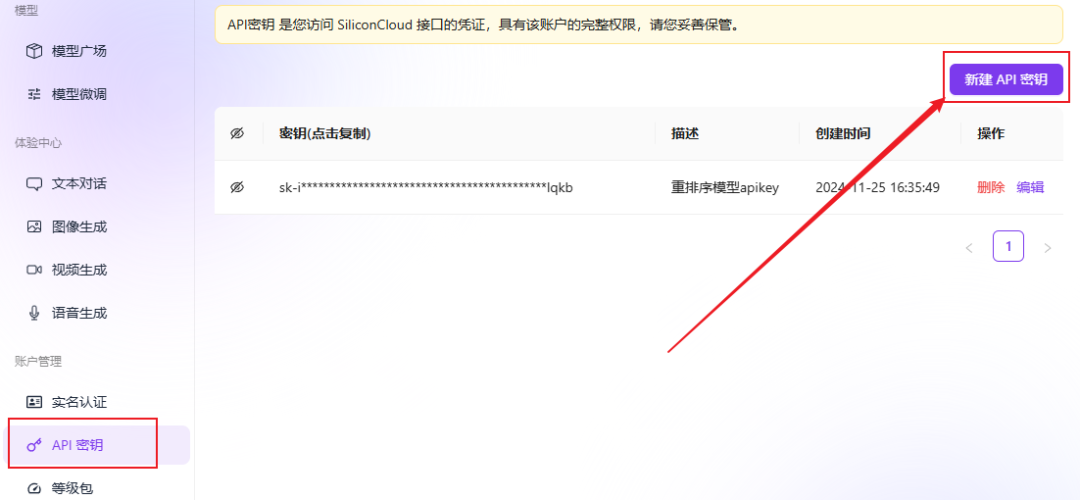
- api_key: vá para Fluxo baseado em silício para obter uma chave de API gratuita.
- Fluxo baseado em silício Depois de se registrar e fazer login na plataforma, você pode encontrar o modelo de vetor gratuito e criar uma chave de API seguindo as diretrizes da imagem abaixo.
- Configuração do modelo: Clique Adicionar modelo maas (compatível com a interface openai)Configure o modelo de idioma grande que você deseja usar.
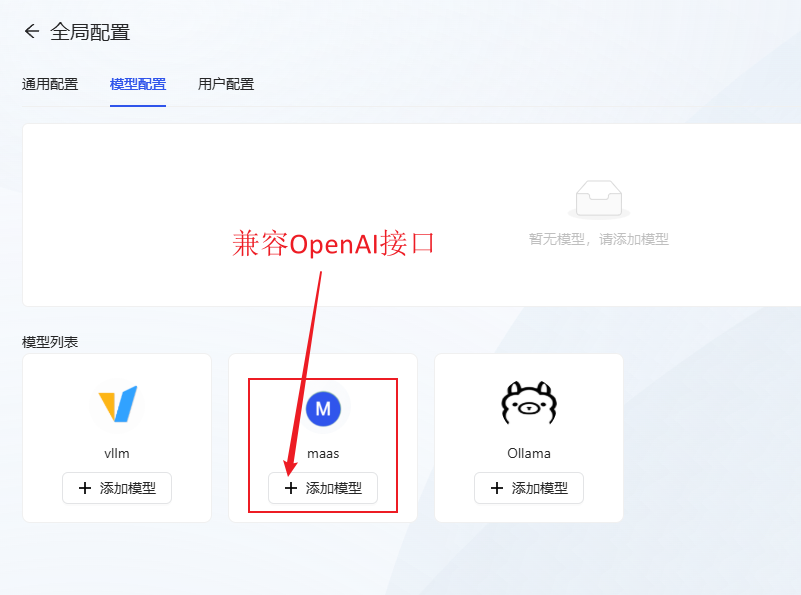
- Tome o gpt-4o como exemplo, preencha as informações do modelo e clique em OK para salvar.
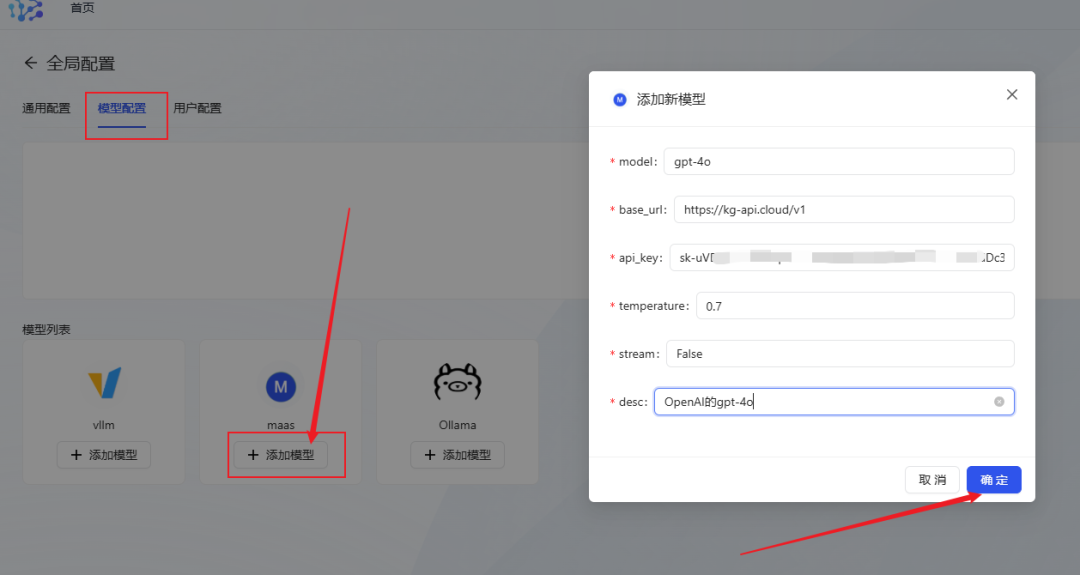
- Modelo de recomendação de estação de retransmissão APISe você tiver uma variedade de necessidades de chamadas de API de modelos grandes, considere usar o serviço de trânsito de API, que é compatível com a interface OpenAI, suporta a alternância com um clique entre modelos grandes nacionais e estrangeiros e fornece MJ, SD e Suno e outras interfaces de desenho e criação de música. O preço também é mais favorável.
Etapa 6: Criar uma base de conhecimento e importar documentos
- Retorne à página inicial e clique em Create Knowledge Base (Criar base de conhecimento).

- Nomeie a base de conhecimento e clique em Salvar.
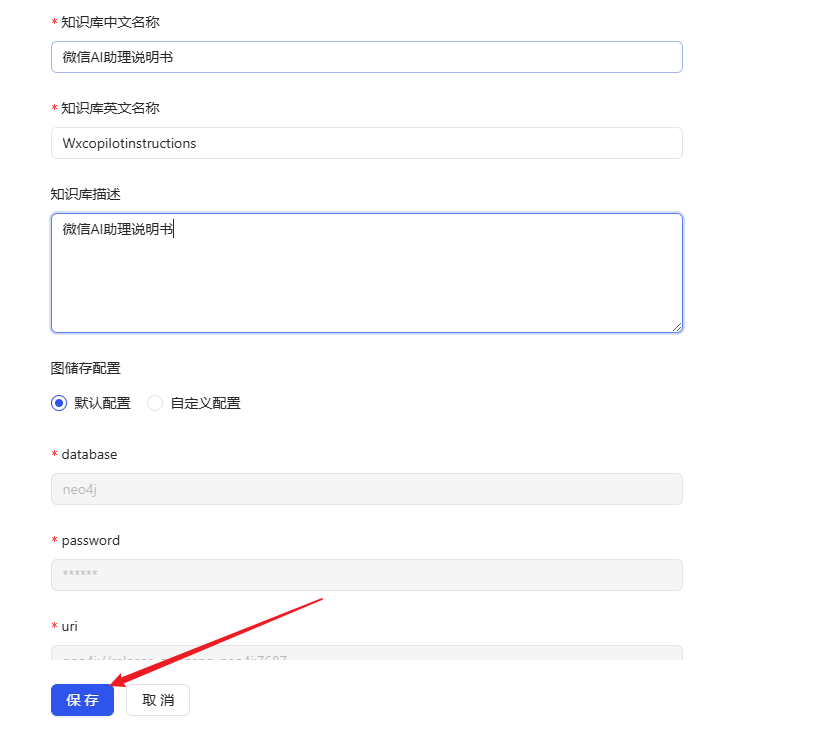
- Após a criação bem-sucedida, localize a base de conhecimento recém-criada na página inicial e clique em Knowledge Base Build.
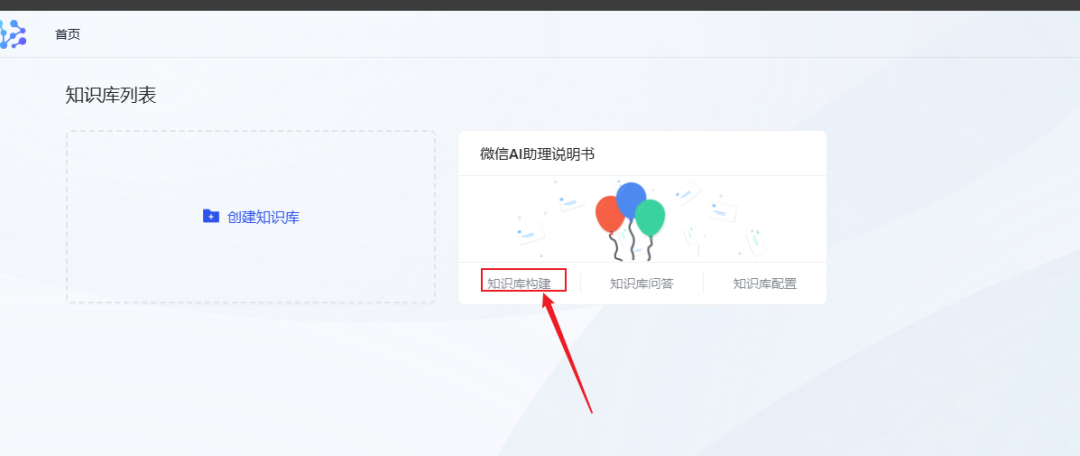
- Clique em Create Task para iniciar a importação de documentos.
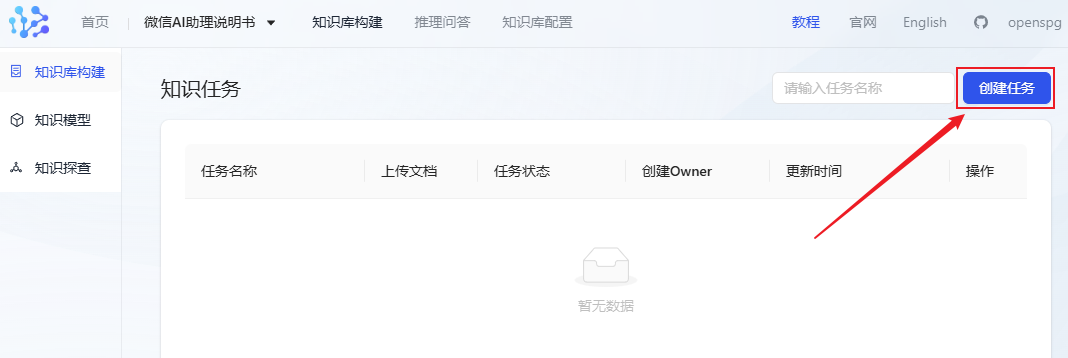
- Carregue os documentos da sua base de conhecimento (atualmente, o KAG só suporta o carregamento de um documento por vez; se você tiver vários documentos, precisará carregá-los em lotes). Aqui eu carreguei documentos relacionados ao meu produto mais recente, o WeChat AI Assistant.
- Chamada para compartilhamento de ferramentas de mesclagem de arquivosSe você tiver uma boa ferramenta gratuita de fusão de arquivos, compartilhe-a na seção de comentários para facilitar o processamento em lote de documentos.
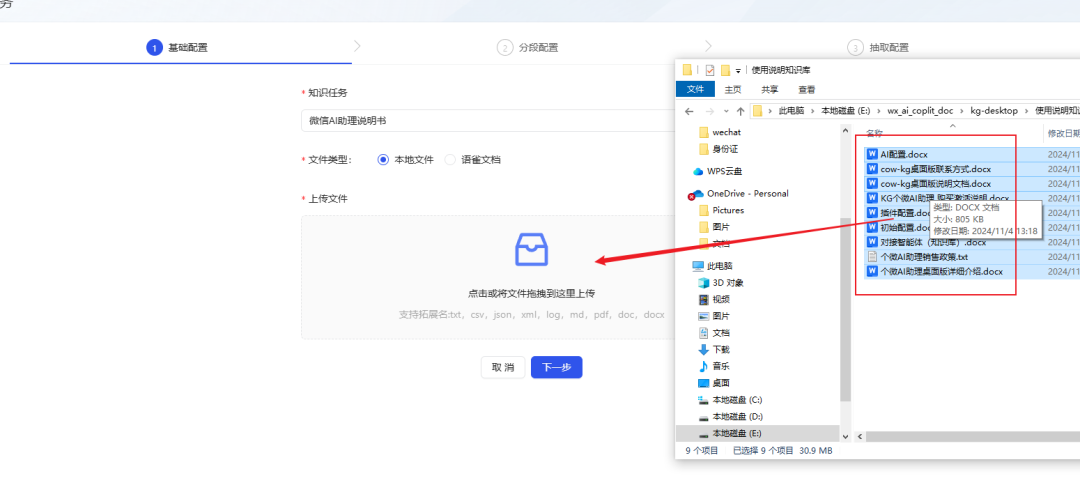
- Na próxima etapa da configuração, é recomendável marcar a caixa para cortar parágrafos de acordo com a semântica do documento, a fim de preservar a coerência contextual dos parágrafos.
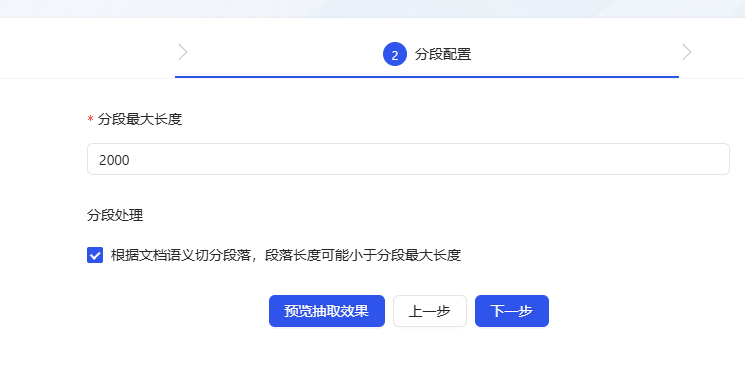
- modelo de extração opção padrão (a configuração padrão está correta). pista Ela pode ser personalizada conforme necessário. Aqui, eu simplesmente a defini como "Q&A Split" (o entendimento nem sempre é preciso, fique à vontade para me corrigir).
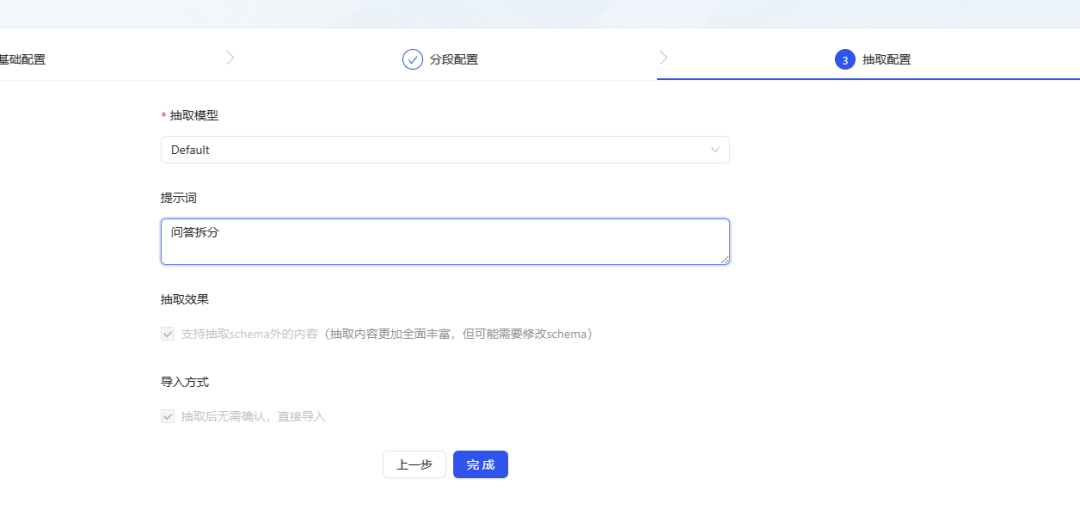
- Clique em Finish (Concluir) e o KAG começará a extrair e analisar os documentos, um processo que pode levar algum tempo.
- O processo de análise de documentos é dividido em 6 etapas, conforme mostrado na figura a seguir:
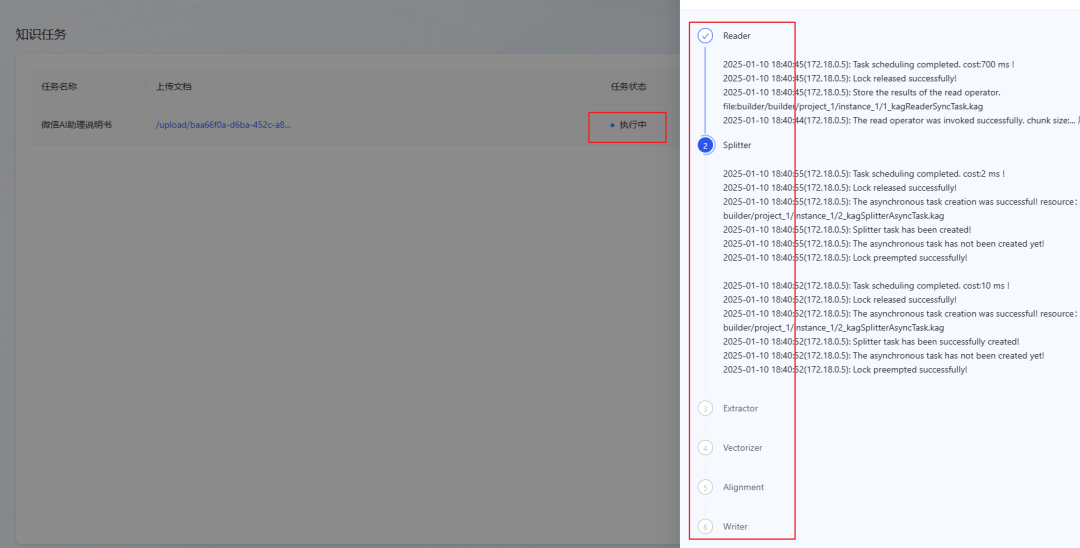
- Aguarde até que o status da tarefa mude para Concluído, indicando que o documento foi importado com sucesso para a Base de Conhecimento. (Se o status não tiver sido atualizado por um longo período, tente atualizar a página).
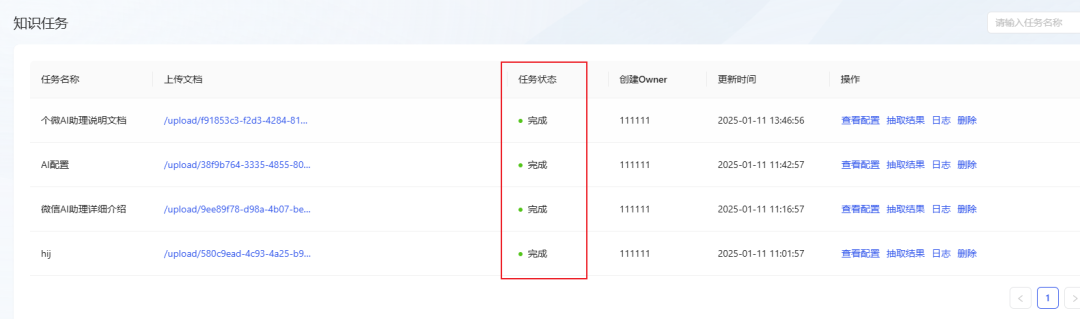
Etapa 7: Demonstração
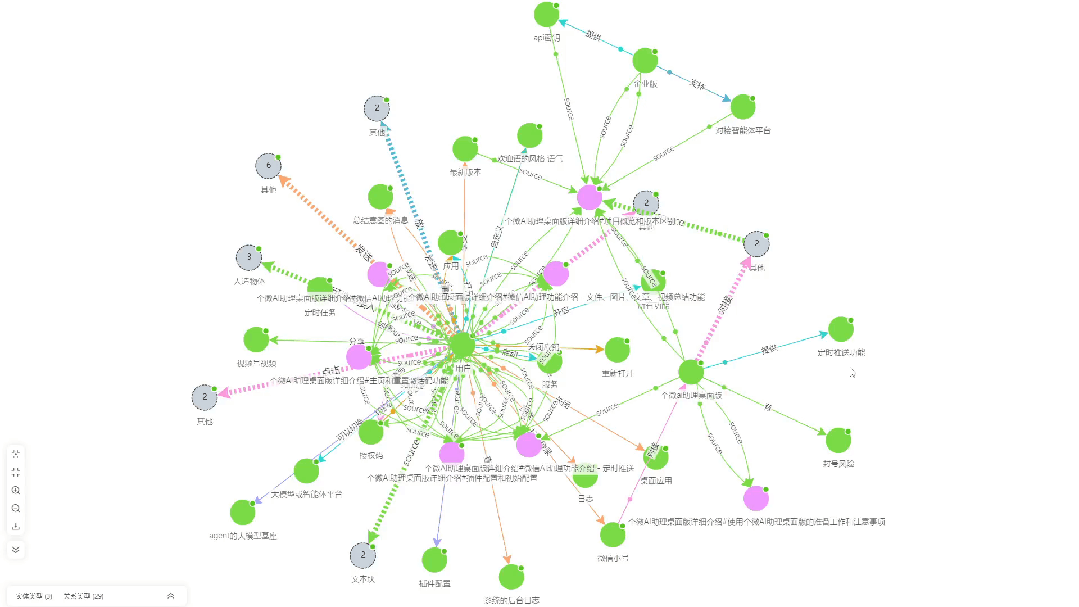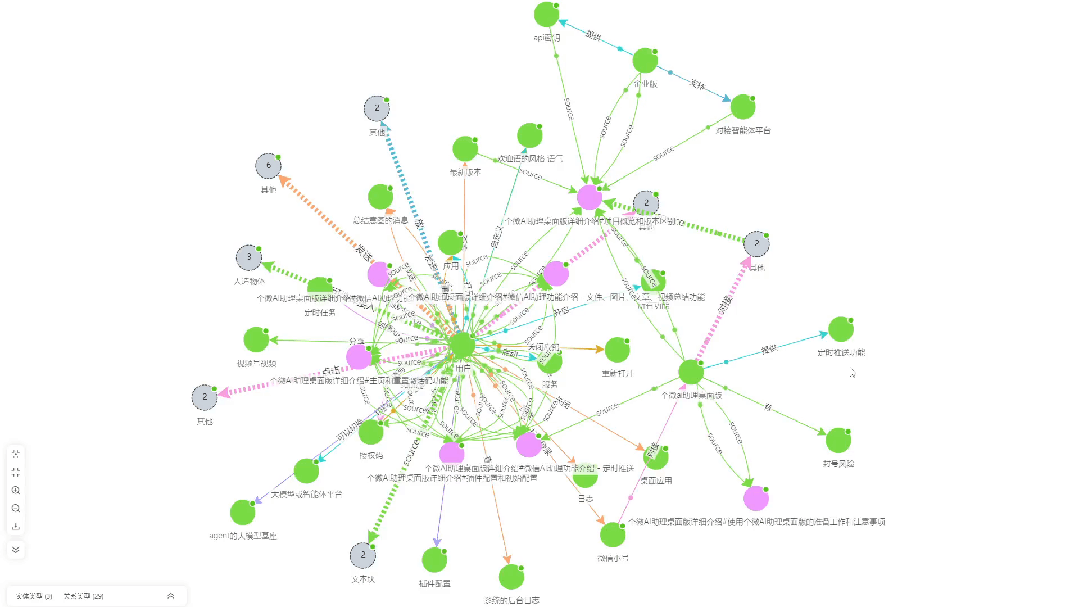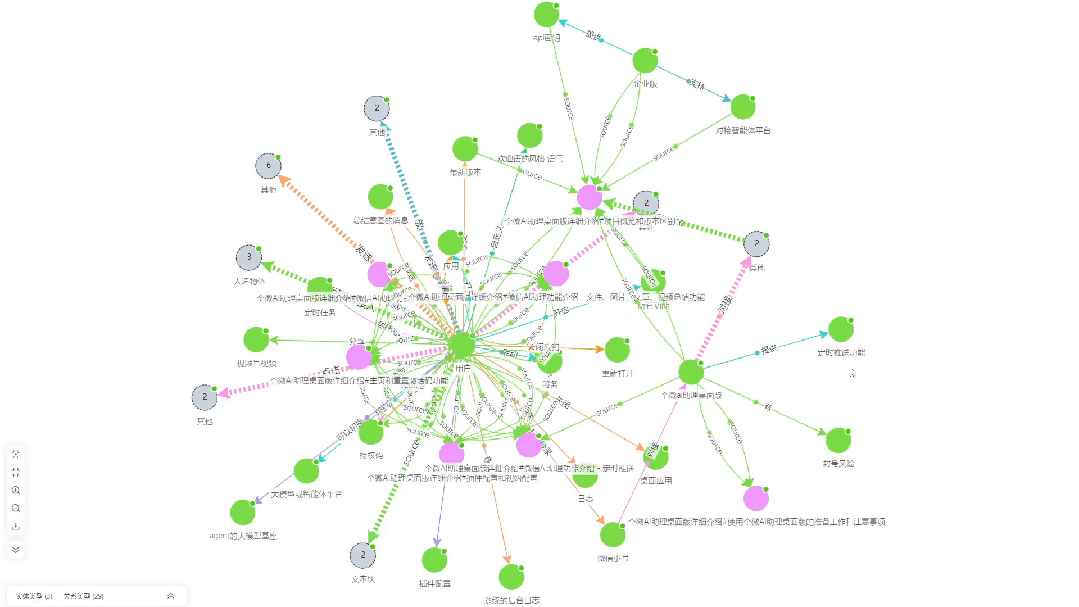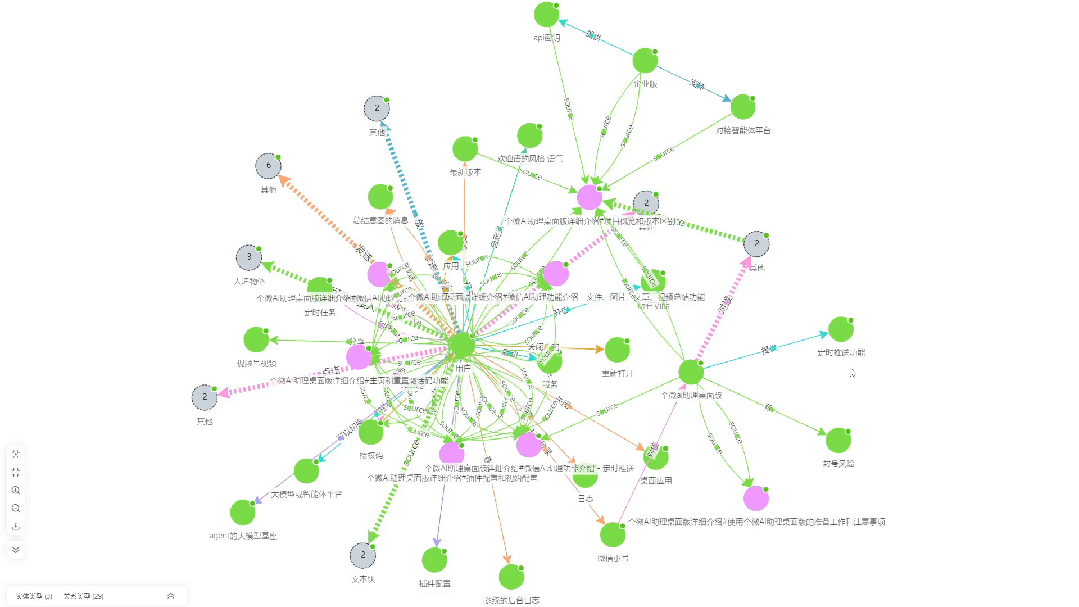
- Diagrama de correlação de extração de conhecimentoEsta é uma visualização das associações de conhecimento extraídas do documento pelo KAG.
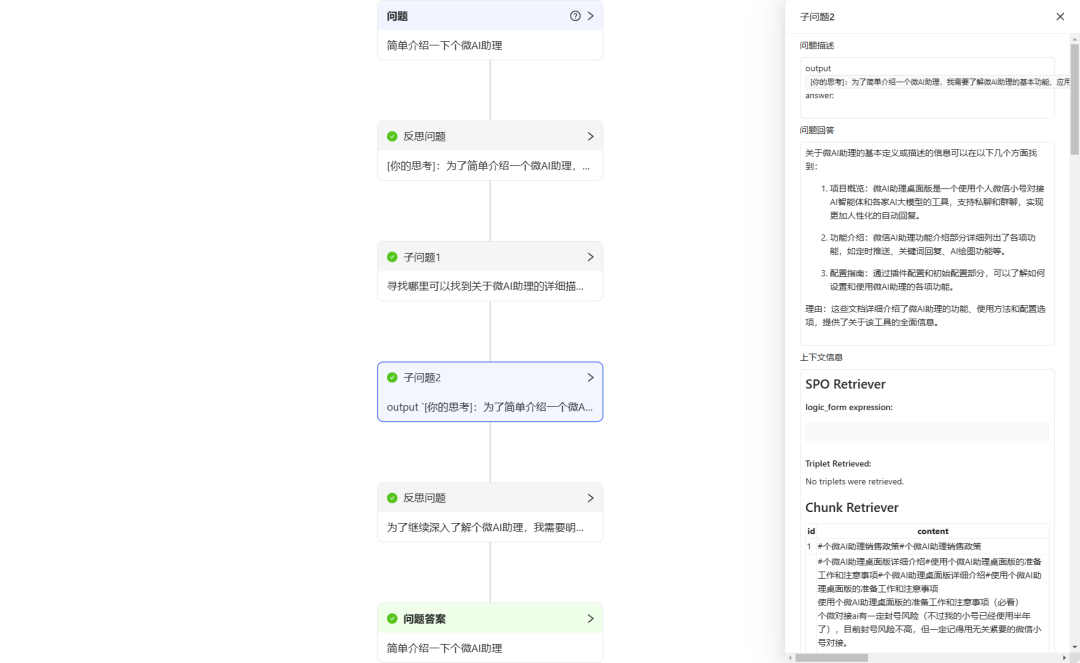
- Teste de eficácia de perguntas e respostas::
- Pergunta 1: "Apresente brevemente o Personal Micro AI Assistant."
O KAG executa um processo de pensamento e raciocínio antes de recuperar e dar a resposta. É possível observar que as respostas dadas pelo KAG são relativamente precisas e abrangentes. Entretanto, o tempo de resposta é lento, cerca de 40 segundos (portanto, o KAG pode não ser adequado para cenários simples de perguntas e respostas).

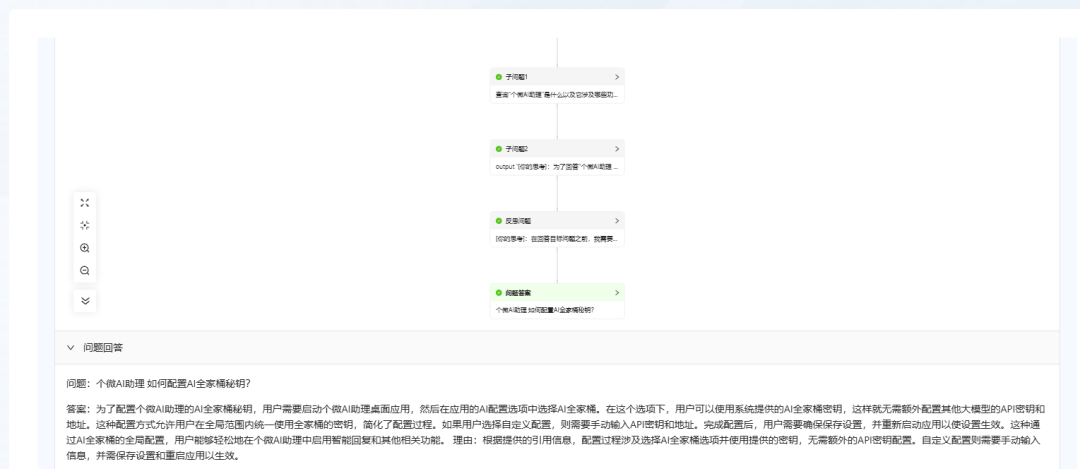
- Pergunta 2: "Como configurar a chave secreta do AI Family Bucket para o Personal Micro AI Assistant?"
O KAG também pode fornecer uma resposta, mas isso ainda leva mais tempo.
Resumo e perspectivas
Com a experiência acima, podemos ver que a estrutura da base de conhecimento KAG de código aberto ainda está em fase de desenvolvimento rápido, alguns recursos e a experiência do usuário ainda precisam ser aprimorados (como o ajuste dos parâmetros da base de conhecimento, a edição da base de conhecimento e a modificação da função não são perfeitos, o uso de alguns bugs também pode ser encontrado). No entanto, de acordo com os registros de atualização do Github, a equipe do KAG está realizando ativamente a iteração do código e a otimização funcional.
A direção técnica do KAG, que funde Knowledge Graph e Vector Retrieval, é muito promissora. Assim como a tecnologia RAG requer dados de base de conhecimento de alta qualidade, aumento de modelos e ajuste de parâmetros para obter resultados ideais, o desenvolvimento do KAG também requer aprimoramento e otimização contínuos.
Conforme mencionado no início do artigo, o KAG é mais adequado para áreas especializadas, como saúde, finanças, direito, governo etc., que exigem raciocínio complexo, em vez de cenários simples de perguntas e respostas do dia a dia (em que a capacidade de resposta é uma deficiência).
No momento, o KAG ainda não abriu a API, e espera-se que, após a abertura da API no futuro, ela possa ser integrada ao aplicativo Agent e, por meio do mecanismo de identificação de problemas, problemas simples e complexos possam ser desviados para aproveitar as vantagens do KAG no processamento de problemas complexos.
Em suma, este artigo tem como objetivo dar a você uma amostra da tecnologia de ponta que é o KAG. Embora o KAG ainda não seja perfeito, ele demonstrou grande potencial como uma estrutura de base de conhecimento de código aberto. Acreditamos que, com os esforços conjuntos da comunidade e a iteração contínua da tecnologia, o KAG trará mais possibilidades para o campo das bases de conhecimento de IA.