Como todos sabemos, quando precisamos permitir que um modelo de linguagem grande execute uma tarefa, precisamos inserir um Prompt para orientar sua execução, que é descrita usando linguagem natural. Para tarefas simples, a linguagem natural pode descrevê-las claramente, como: "Por favor, traduza o seguinte para o chinês simplificado:", "Por favor, gere um resumo do seguinte:" e assim por diante.
Entretanto, quando nos deparamos com algumas tarefas complexas, como exigir que o modelo gere um formato JSON específico, ou quando a tarefa tem várias ramificações, cada ramificação precisa executar várias subtarefas e as subtarefas estão inter-relacionadas entre si, as descrições em linguagem natural não são suficientes.
tópico de discussão
Aqui estão duas perguntas instigantes para você experimentar antes de continuar lendo:
- Há várias sentenças longas, cada uma das quais precisa ser dividida em sentenças mais curtas de no máximo 80 caracteres e, em seguida, ser gerada em um formato JSON que descreva claramente a correspondência entre as sentenças longas e curtas.
Por exemplo:
[
{
"long": "Esta é uma frase longa que precisa ser dividida em frases mais curtas.", "short": [ [ {
"short": [
"Esta é uma frase longa", "que precisa ser dividida", "short": [
"This is a long sentence that needs to be split", "short": [ "This is a long sentence", "that needs to be split", "into shorter sentences.
"Esta é uma frase longa", "que precisa ser dividida", "em frases mais curtas".
Esta é uma frase longa que precisa ser dividida em frases mais curtas].
}, { "short".
}, {
"long": "Outra frase longa que deve ser dividida em frases mais curtas.", "short": [ "que precisa ser dividida", "em frases mais curtas." ] }, {
"short": [
"Another long sentence", "that should be split", "short": [
"that should be split", "short": [ "Outra frase longa", "that should be split", "short".
"em frases mais curtas".
]
}
]
- Um texto original legendado com apenas informações de diálogo, do qual agora você precisa extrair capítulos, falantes e, em seguida, listar o diálogo por capítulo e parágrafo. No caso de vários falantes, cada diálogo precisa ser precedido pelo falante, não se o mesmo falante estiver falando consecutivamente. (Na verdade, esse é um GPT que eu mesmo uso para organizar roteiros de vídeo Agrupamento de scripts de vídeo GPT)
Exemplo de entrada:
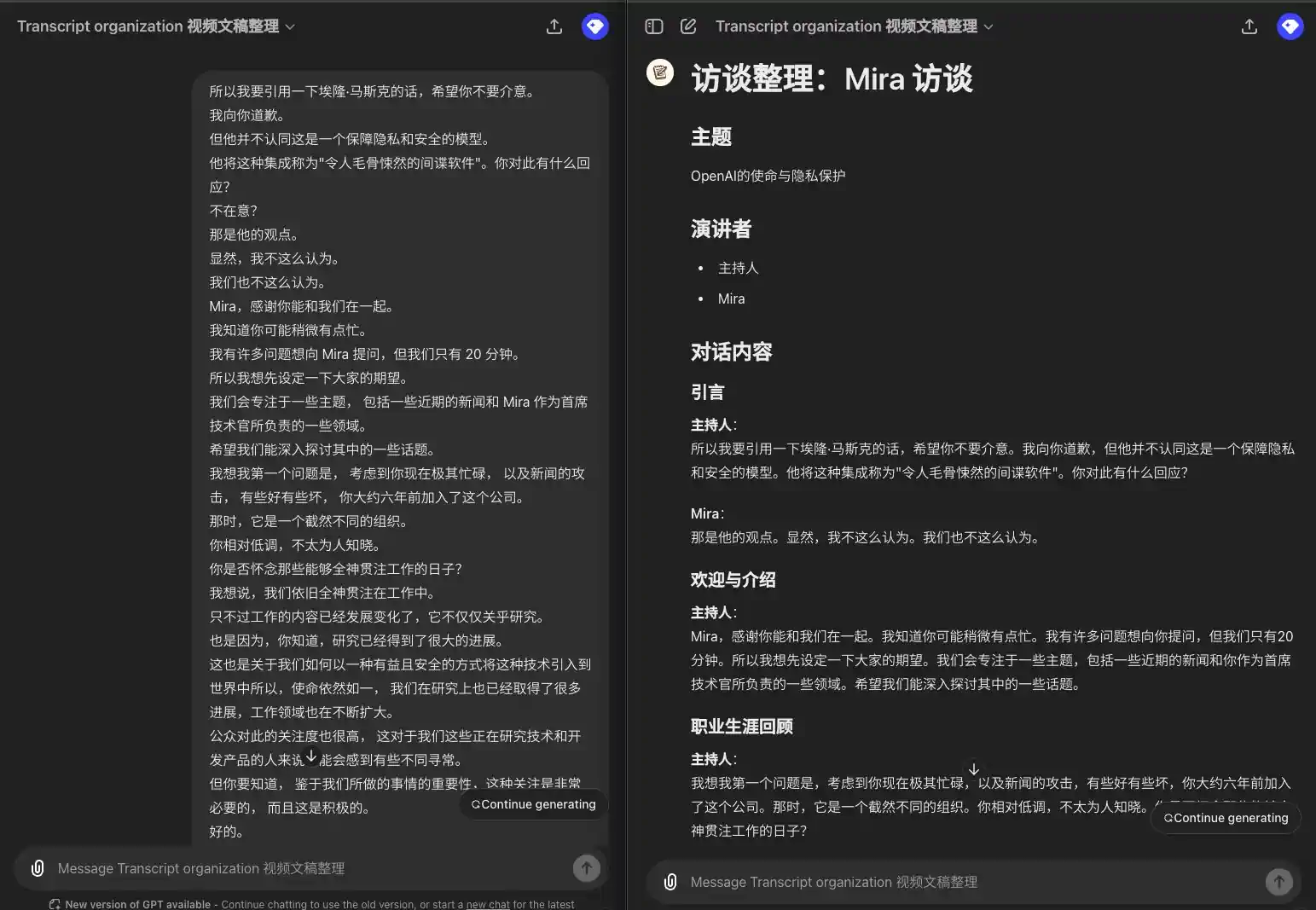
Portanto, vou citar Elon Musk, e espero que você não se importe. Peço desculpas. Mas ele não concorda que esse seja um modelo de privacidade e segurança. Ele chamou a integração de "spyware assustador". Qual é a sua resposta a isso? Não me importo? Essa é a opinião dele. Obviamente, eu não acho isso. Nós também não. Mira, obrigado por estar conosco. Sei que deve estar um pouco ocupada. Tenho muitas perguntas para a Mira, mas só temos 20 minutos. Portanto, gostaria de definir suas expectativas primeiro. Vamos nos concentrar em vários tópicos, incluindo algumas notícias recentes e algumas das áreas de responsabilidade da Mira como CTO. Espero que possamos nos aprofundar em alguns desses tópicos. Acho que minha primeira pergunta é: considerando que você está extremamente ocupado no momento e os ataques nas notícias, alguns bons, outros ruins, você entrou na empresa há cerca de seis anos. Naquela época, a organização era muito diferente. Você tinha um perfil relativamente discreto e não era muito conhecido. Sente falta dos dias em que podia se concentrar em seu trabalho? Eu diria que ainda estamos totalmente engajados em nosso trabalho. Só que o trabalho evoluiu e não se trata apenas de pesquisa. Também se trata de pesquisa que já percorreu um longo caminho. Também se trata de como podemos trazer essa tecnologia para o mundo de uma forma benéfica e segura, portanto, a missão continua a mesma, e fizemos muito progresso na pesquisa, e o campo de trabalho está se expandindo. Há muito interesse público nisso, o que pode parecer um pouco incomum para aqueles de nós que trabalham com tecnologia e desenvolvem produtos. Mas, dada a importância do que estamos fazendo, essa atenção é muito necessária e positiva.
Saída de amostra:
### Introdução **Moderador**: Vou citar Elon Musk, espero que você não se importe. Peço desculpas, mas ele não concorda que esse seja um modelo de privacidade e segurança. Ele chamou essa integração de "spyware assustador". Qual é a sua resposta a isso? **Mira: Essa é a opinião dele. Obviamente, eu não acho isso. Nós também não achamos. ### Boas-vindas e apresentações **Anfitrião Mira, obrigado por estar conosco. Sei que você deve estar um pouco ocupada. Tenho muitas perguntas para você, mas só temos 20 minutos. Portanto, gostaria de definir suas expectativas primeiro. Vamos nos concentrar em vários tópicos, incluindo algumas notícias recentes e algumas das áreas pelas quais você é responsável como CTO. Espero que possamos nos aprofundar em alguns desses tópicos. ### Revisão da carreira **Anfitrião: Acho que minha primeira pergunta é: dado o fato de que você está extremamente ocupado no momento e os ataques nas notícias, alguns bons e outros ruins, você entrou nesta empresa há cerca de seis anos. Naquela época, era uma organização muito diferente. Você era relativamente discreto e não muito conhecido. Você sente falta dos dias em que podia dar atenção total ao seu trabalho? **Mira**: Eu diria que ainda estamos totalmente engajados em nosso trabalho. Só que o trabalho evoluiu e não se trata apenas de pesquisa. Isso também se deve ao fato de a pesquisa ter progredido muito. Também se trata de como podemos trazer essa tecnologia para o mundo de uma forma benéfica e segura. Portanto, a missão continua a mesma, mas também fizemos muito progresso na pesquisa e as áreas de trabalho estão se expandindo. Há também muito interesse público nisso, o que pode parecer um pouco incomum para aqueles que estão trabalhando na tecnologia e desenvolvendo o produto. Mas é preciso entender que, dada a importância do que estamos fazendo, essa atenção é muito necessária e positiva.
A essência do Prompt
Talvez você tenha lido muitos artigos on-line sobre como escrever técnicas de Prompt e memorizado muitos modelos de Prompt, mas qual é a essência do Prompt? Por que precisamos do Prompt?
O Prompt é essencialmente uma instrução de controle para o LLM, descrita em linguagem natural, que permite que o LLM entenda nossos requisitos e transforme as entradas em nossas saídas desejadas, conforme necessário.
Por exemplo, a técnica de poucos disparos comumente usada é permitir que o LLM entenda nossos requisitos por meio de exemplos e, em seguida, consulte os exemplos para produzir os resultados desejados. Por exemplo, a CoT (Chain of Thought, cadeia de raciocínio) consiste em decompor artificialmente a tarefa e limitar o processo de execução, de modo que o LLM possa seguir o processo e as etapas especificadas por nós, sem ser muito difuso ou pular as etapas principais e, assim, obter melhores resultados.
É como quando vamos à escola, quando o professor está falando sobre teoremas matemáticos, ele precisa nos dar exemplos para que possamos entender o significado dos teoremas por meio dos exemplos; quando estamos fazendo experimentos, precisamos saber as etapas dos experimentos e, mesmo que não entendamos os princípios dos experimentos, mas possamos executá-los de acordo com as etapas, ainda assim obteremos mais ou menos os mesmos resultados.
Por que, às vezes, os resultados do Prompt não são tão bons?
Isso ocorre porque o LLM não consegue entender com precisão nossos requisitos, que são limitados, por um lado, pela capacidade do LLM de entender e seguir instruções e, por outro, pela clareza e precisão da descrição do Prompt.
Como controlar com precisão a saída do LLM e definir sua lógica de execução com a ajuda de pseudocódigo
Como o Prompt é essencialmente uma instrução de controle para o LLM, podemos escrever o Prompt sem nos limitarmos às descrições tradicionais de linguagem natural, mas também podemos usar pseudocódigo para controlar com precisão a saída do LLM e definir sua lógica de execução.
O que é pseudocódigo?
O pseudocódigo é um método de descrição formal para descrever algoritmos, que é um tipo de método de descrição entre a linguagem natural e a linguagem de programação para descrever etapas e processos de algoritmos. Em vários livros e artigos sobre algoritmos, vemos com frequência a descrição de pseudocódigo, mesmo que você não precise conhecer uma linguagem, mas também por meio do pseudocódigo para entender a execução do fluxo do algoritmo.
Então, até que ponto o LLM entende bem o pseudocódigo? Na verdade, a compreensão de pseudocódigo do LLM é bastante forte. O LLM foi treinado com muitos códigos de qualidade e consegue entender facilmente o significado do pseudocódigo.
Como escrever um Prompt de pseudocódigo?
O pseudocódigo é muito familiar para os programadores e, para quem não é programador, é possível escrever pseudocódigo simples apenas lembrando-se de algumas regras básicas. Alguns exemplos:
- Variáveis, que são usadas para armazenar dados, por exemplo, para representar entradas ou resultados intermediários com alguns símbolos específicos
- Tipo, usado para definir o tipo de dados, como cadeias de caracteres, números, matrizes, etc.
- função que define a lógica de execução de uma subtarefa
- Fluxo de controle, usado para controlar o processo de execução do programa, como loops, julgamentos condicionais, etc.
- instrução if-else, se a condição A for satisfeita, execute a tarefa A; caso contrário, execute a tarefa B.
- Um loop for que executa uma tarefa para cada elemento da matriz.
- No loop while, quando a condição A for satisfeita, a tarefa B será executada continuamente.
Agora vamos escrever o Prompt em pseudocódigo, usando as duas perguntas de reflexão anteriores como exemplo.
Pseudocódigo para gerar um formato JSON específico
O formato JSON desejado pode ser claramente descrito com a ajuda de um pseudocódigo semelhante à definição de tipo do TypeScript:
Divida as frases em segmentos curtos, com no máximo uma linha (menos de 80 caracteres, cerca de 10 palavras em inglês) cada. Mantenha o significado de cada segmento, por exemplo, separe as pontuações, "e", "que", "onde", "o que", "quando", "quem", "qual" ou "ou" etc., se possível, mas mantenha essas pontuações ou palavras para a divisão. Não adicione ou remova nenhuma palavra ou sinal de pontuação. A entrada é uma matriz de strings. A saída deve ser uma matriz json válida de objetos, cada objeto contendo uma frase e seus segmentos. Array
Organização de scripts de legendas com pseudocódigo
A tarefa de agrupar textos legendados é relativamente complexa. Se você imaginar escrever um programa para realizar essa tarefa, pode haver muitas etapas, como extrair capítulos, depois extrair falantes e, por fim, agrupar diálogos de acordo com capítulos e falantes. Com a ajuda do pseudocódigo, podemos decompor essa tarefa em várias subtarefas, para as quais nem é necessário escrever um código específico, mas apenas descrever claramente a lógica de execução das subtarefas. Em seguida, execute essas subtarefas passo a passo e, por fim, integre a saída do resultado.
Podemos usar algumas variáveis para armazenar, como assuntoealto-falantesecapítuloseparágrafos etc.
Na saída, também podemos usar loops For para iterar pelos capítulos e parágrafos e instruções If-else para determinar se precisamos emitir o nome do orador.
Sua tarefa é reorganizar as transcrições de vídeo para facilitar a leitura e reconhecer os falantes em diálogos com várias pessoas. Aqui estão os pseudocódigos de como fazer isso Aqui estão os pseudocódigos de como fazer isso
def extract_subject(transcript): # Localiza o assunto na transcrição e o retorna como uma string.
# Encontre o assunto na transcrição e retorne-o como uma string.
def extract_chapters(transcript): # Localiza os capítulos na transcrição e os retorna como uma lista de strings.
# Encontre os capítulos na transcrição e retorne-os como uma lista de strings. def extract_chapters(transcript).
def extract_speakers(transcript): # Encontre os falantes na transcrição e retorne-os como uma lista de cadeias de caracteres.
# Encontre os locutores na transcrição e retorne-os como uma lista de strings. def extract_speakers(transcript).
def find_paragraphs_and_speakers_in_chapter(chapter): # Localiza os parágrafos e os retorna como uma lista de strings. def extract_speakers(transcript).
# Localiza os parágrafos e os locutores em um capítulo e os retorna como uma lista de tuplas. def find_paragraphs_and_speakers_in_chapter(chapter).
# Cada tupla contém o orador e seus parágrafos. # Encontre os parágrafos e oradores em um capítulo e retorne-os como uma lista de tuplas.
def format_transcript(transcript): # Extraia o assunto, o texto da tupla e o texto da tupla.
# Extraia o assunto, os palestrantes, os capítulos e imprima-os
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
capítulos = extract_chapters(transcrição)
print("Capítulos:", capítulos)
# formatar a transcrição
formatted_transcript = f "# {subject}\n\n"
for chapter in chapters.
formatted_transcript += f "## {chapter}\n\n" for chapter in chapters.
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers.
# se houver vários oradores, imprima o nome do orador antes de cada parágrafo
if speakers.size() > 1.
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs: formatted_transcript += f"{speaker}:
formatted_transcript += f" {parágrafo}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Vamos ver como isso funciona:
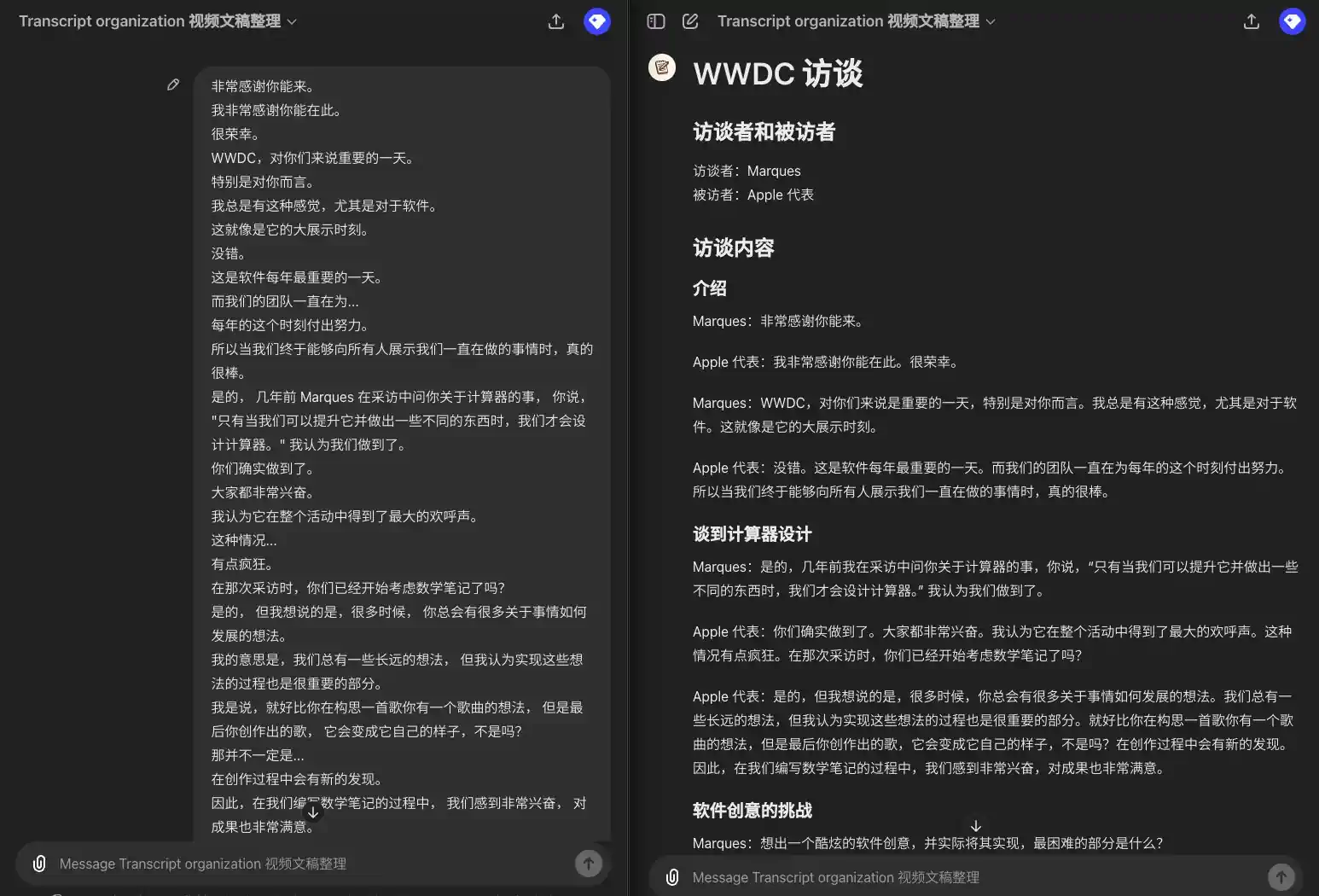
Coletando transcrições de entrevistas da WWDC
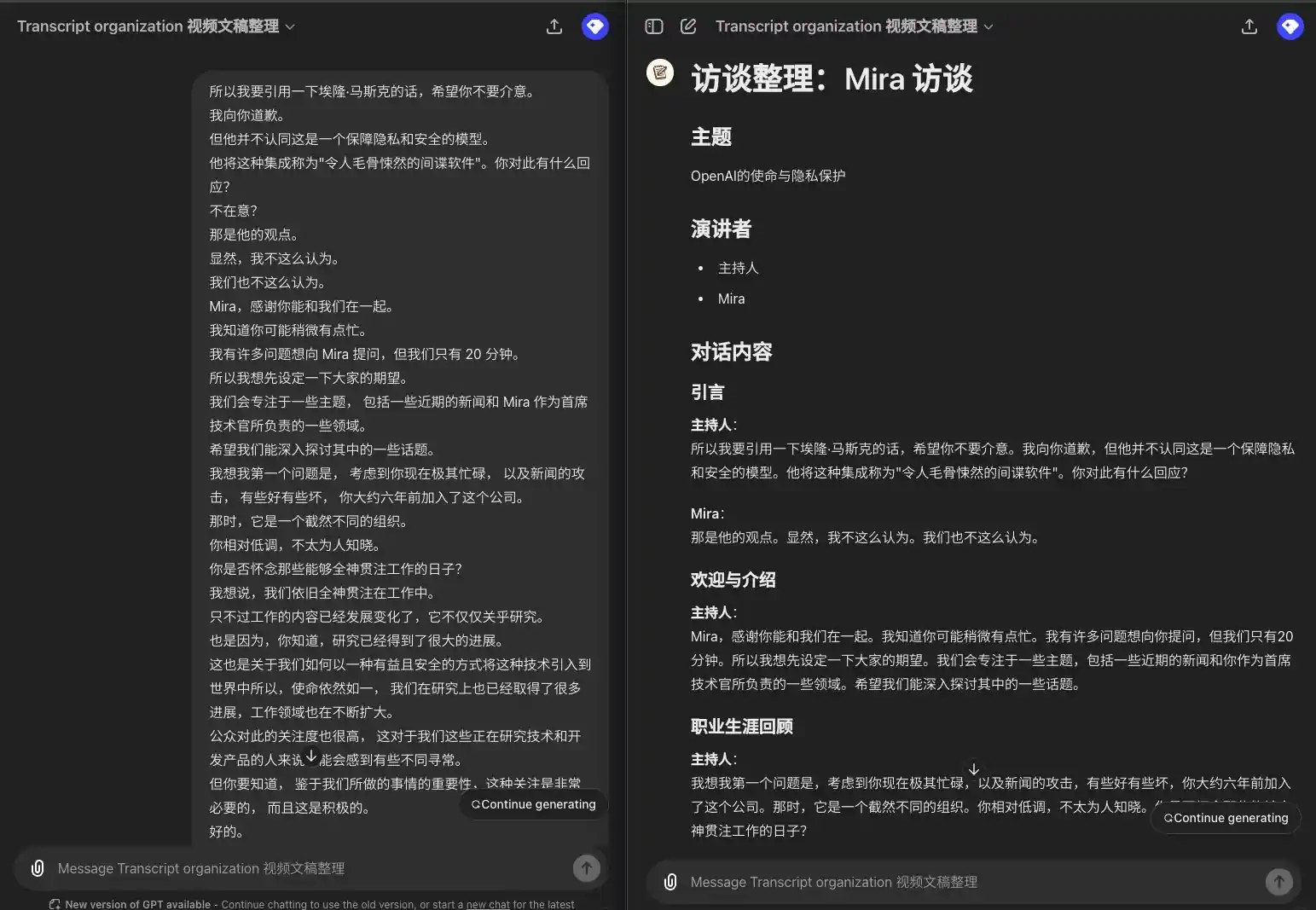
Vários palestrantes, palestrantes de shows
1 Alto-falante, nenhum alto-falante mostrado
Você também pode usar apenas o GPT que gerei com esse prompt:Organização de transcrição GPT
Faça o ChatGPT desenhar várias imagens de uma vez com o código pseudo
Também aprendi recentemente um uso muito interessante do termo com um internauta taiwanês, Sensei Yoon Sang-chi.Faça o ChatGPT desenhar várias imagens de uma vez com pseudocódigo.
Agora, se você quiser fazer ChatGPT Se quiser gerar mais de uma imagem por vez, você pode usar o pseudocódigo para decompor a tarefa de gerar várias imagens em várias subtarefas e, em seguida, executar várias subtarefas por vez e, finalmente, integrar a saída do resultado.
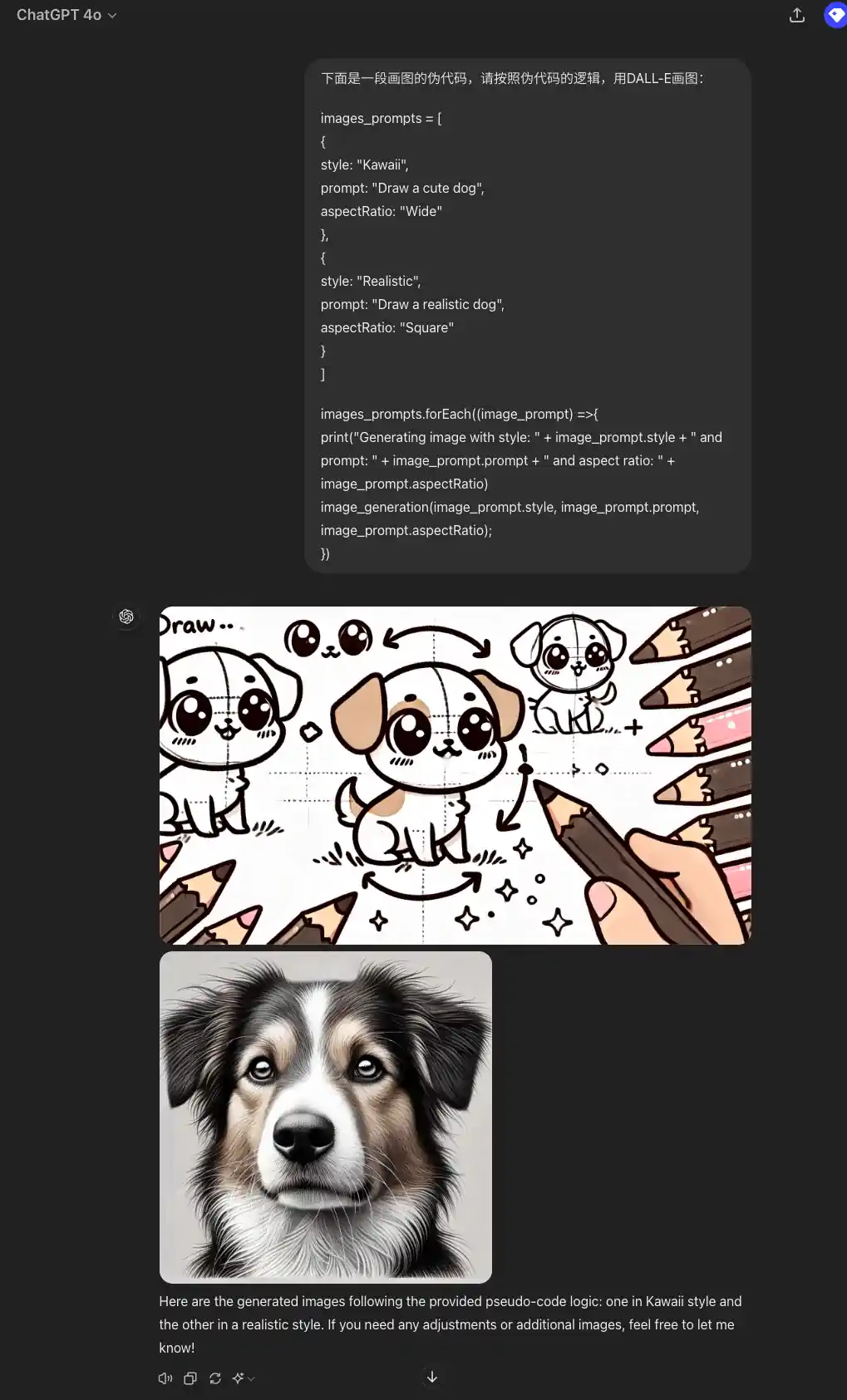
Aqui está um pseudocódigo para desenhar um diagrama. Siga a lógica do pseudocódigo e desenhe o diagrama com o DALL-E:
images_prompts = [
{
estilo: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic", prompt: "Draw a realistic dog", aspectRatio: "Wide" }, {
prompt: "Draw a realistic dog" (Desenhe um cachorro realista), aspectRatio: "Square
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) => {
print("Gerando imagem com estilo: " + image_prompt.style + " e prompt: " + image_prompt.prompt + " e proporção: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})
resumos
Por meio do exemplo acima, podemos ver que, com a ajuda do pseudocódigo, podemos controlar com mais precisão o resultado de saída do LLM e definir sua lógica de execução, em vez de nos limitarmos apenas à descrição da linguagem natural. Quando nos deparamos com algumas tarefas complexas ou tarefas com várias ramificações, cada ramificação precisa executar várias subtarefas e as subtarefas estão relacionadas umas às outras, o uso de pseudocódigo para descrever o Prompt será mais claro e preciso.
Quando escrevemos um Prompt, lembramos que um Prompt é essencialmente uma instrução de controle para o LLM, descrita em linguagem natural, que permite que o LLM entenda o que queremos e, em seguida, transforme as entradas nas saídas que esperamos, conforme necessário. Quanto à forma de descrição do Prompt, ela pode ser flexível em várias formas, como few-shot, CoT, pseudocódigo etc.
Mais exemplos:
Gerar meta prompts de "pseudocódigo" para controle preciso da formatação da saída