PDF gratuito de Fundamentals of Large Models da Universidade de Zhejiang - com link para download

O livro Fundamentals of Large Models oferece uma análise aprofundada das principais tecnologias e dos caminhos práticos dos modelos de linguagem de grande porte (LLMs). Partindo da teoria básica da modelagem de linguagem, ele explica sistematicamente os princípios do design de modelos com base em arquiteturas estatísticas, de redes neurais recorrentes (RNN) e de transformadores, concentrando-se nas três principais arquiteturas de modelos de linguagem de grande porte (somente codificador, codificador-decodificador, somente decodificador) e em modelos representativos (por exemplo, BERT, T5, série GPT). O livro explica as principais tecnologias, como engenharia de prompts, ajuste fino eficiente de parâmetros, edição de modelos e geração de aprimoramento de recuperação. Combinado com estudos de caso ricos, o livro demonstra práticas de aplicação em diferentes cenários, fornecendo aos leitores um aprendizado abrangente e aprofundado e orientação prática, ajudando os leitores a dominar a aplicação e a otimização de tecnologias de modelagem de linguagem grande.

Noções básicas de modelagem de linguagem
- Modelagem de idiomas com base em métodos estatísticosAnálise detalhada dos modelos de n-gramas e das estatísticas por trás deles, incluindo suposições de Markov e estimativa de grande verossimilhança.
- Modelagem de linguagem baseada em RNNDescrição: Uma explicação detalhada dos recursos estruturais das Redes Neurais Recorrentes (RNN), problemas comuns de desaparecimento e explosão de gradiente no treinamento e aplicações práticas na modelagem de idiomas.
- Modelagem de linguagem baseada em transformadoresAnálise abrangente dos principais componentes da arquitetura do Transformer, como o mecanismo de autoatenção, redes neurais feed-forward (FFNs), normalização de camadas e conectividade residual, e sua aplicação eficiente na modelagem de idiomas.
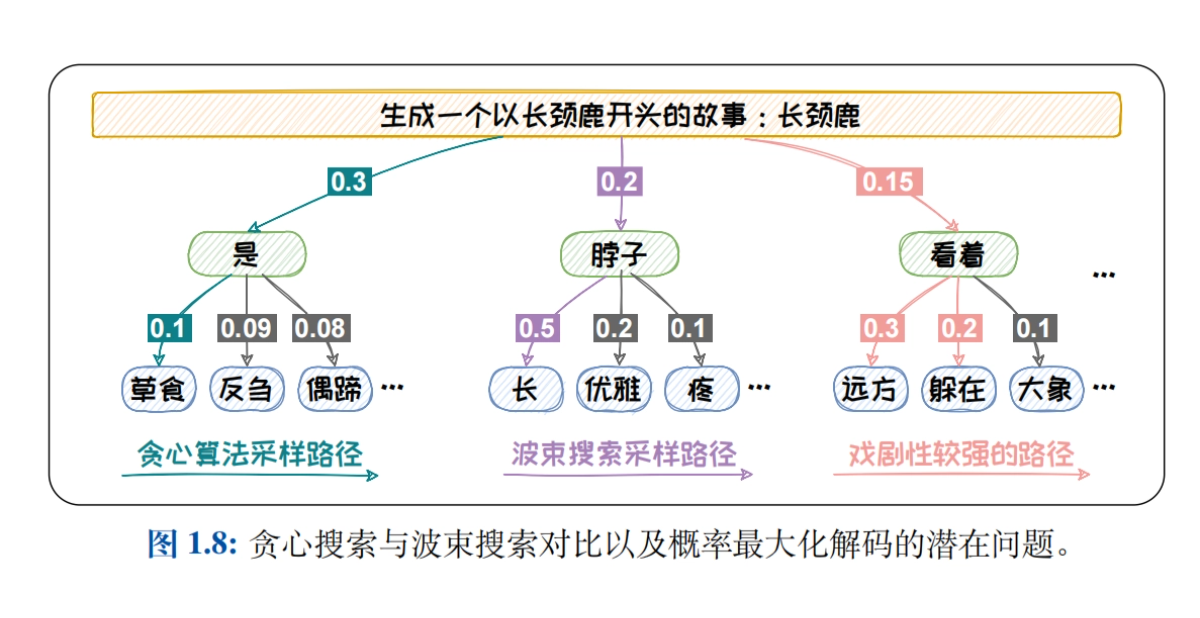
- Métodos de amostragem para modelagem de linguagemEstratégias de decodificação, como Greedy Search, Beam Search, Top-K Sampling, Top-P Sampling e Temperature mechanism, são sistematicamente apresentadas para explorar o impacto das diferentes estratégias na qualidade do texto gerado.
- Revisão dos modelos de linguagemDescrição detalhada das rubricas intrínsecas (por exemplo, perplexidade) e extrínsecas (por exemplo, BLEU, ROUGE, BERTScore, G-EVAL) são apresentadas para analisar os pontos fortes e as limitações de cada rubrica na avaliação do desempenho dos modelos de linguagem.
Arquitetura do modelo de Big Language
- Big Data + Big Models → Nova InteligênciaA seguir, apresentamos uma análise aprofundada do impacto do tamanho do modelo e do tamanho dos dados sobre a capacidade do modelo, uma explicação detalhada das Leis de Dimensionamento (como a Lei de Kaplan-McCandlish e a Lei de Chinchilla) e uma discussão sobre como melhorar o desempenho do modelo otimizando o tamanho do modelo e dos dados.
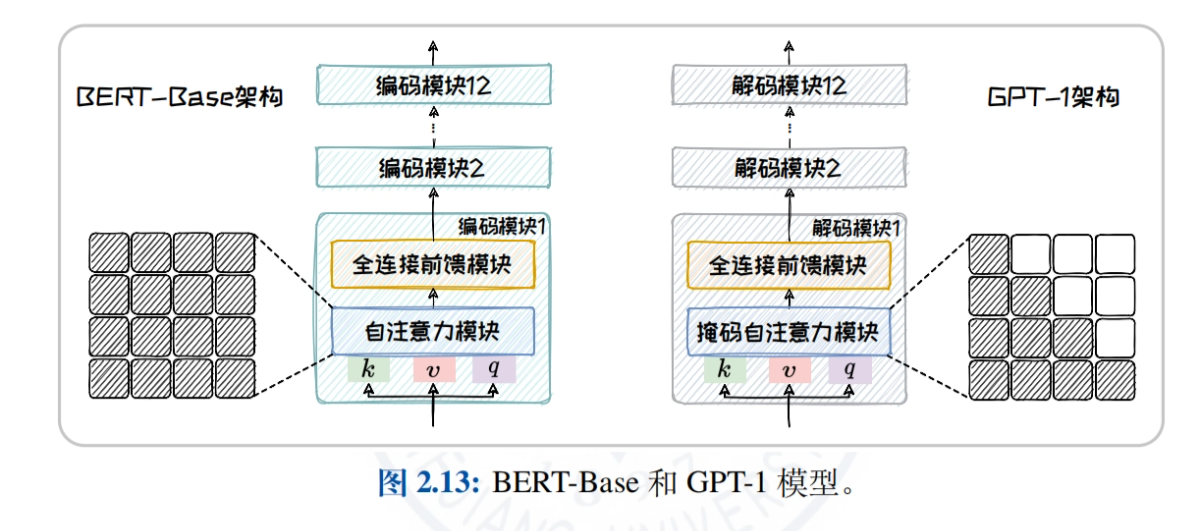
- Visão geral da arquitetura do modelo do Big LanguageComparação e análise dos mecanismos de atenção e das tarefas aplicáveis de três arquiteturas convencionais, somente codificador, codificador-decodificador e somente decodificador, para ajudar os leitores a entender os recursos e as vantagens de diferentes arquiteturas.
- Arquitetura somente de codificadorBERT: Tomando o BERT como exemplo, explicamos em profundidade a estrutura do modelo, as tarefas de pré-treinamento (por exemplo, MLM, NSP) e os modelos derivados (por exemplo, RoBERTa, ALBERT, ELECTRA) para explorar a aplicação do modelo em tarefas de compreensão de linguagem natural.
- Arquitetura do codificador-decodificadorOs modelos T5 e BART são usados como exemplos para apresentar a estrutura unificada de geração de texto e diversas tarefas de pré-treinamento, e para analisar o desempenho dos modelos em tarefas como tradução automática e resumo de texto.
- Arquitetura somente de decodificadorDescrição: O histórico de desenvolvimento e as características da família GPT (de GPT-1 a GPT-4) e da família LLaMA (LLaMA1/2/3) são descritos em detalhes, explorando as vantagens dos modelos para tarefas de geração de texto em domínio aberto.
- arquitetura sem transformadorIntrodução de modelos de espaço de estado (SSMs), como RWKV, Mamba e o paradigma Training While Testing (TTT), explorando o potencial de arquiteturas não convencionais a serem aplicadas em cenários específicos.
Engenharia imediata
- Introdução ao Prompt ProjectDefinição de Prompt e Engenharia de Prompt, explicação detalhada do processo de desambiguação e vetorização (Tokenização, Incorporação) e exploração de como gerar texto de alta qualidade por meio de um modelo de bootstrap de Prompt bem projetado.
- Aprendizagem no contexto (ICL)Introdução aos conceitos de aprendizado de amostra zero, amostra única e poucas amostras, explorando estratégias de seleção de exemplos (por exemplo, similaridade e diversidade) e analisando como o aprendizado contextual pode ser usado para melhorar a adaptabilidade dos modelos à tarefa.
- Cadeia de pensamento (CoT)CoT: Explique os três modos de CoT: passo a passo (por exemplo, CoT, Zero-Shot CoT, Auto-CoT), pensar (por exemplo, ToT, GoT) e brainstorm (por exemplo, Self-Consistency) e explore como aprimorar o raciocínio de modelos por meio da cadeia de pensamento.
- Dicas de promptsEle apresenta técnicas como a padronização da redação do Prompt, o resumo racional das perguntas, o uso de CoTs no momento certo e o bom uso de pistas psicológicas (por exemplo, interpretação de papéis, substituição de situações) para ajudar os leitores a aprimorar a elaboração do Prompt.
- Aplicativos relacionadosIntrodução de aplicativos como Big Model-based Intelligentsia (Agents), Síntese de dados, Text-to-SQL, GPTS, etc., e exploração de casos de uso prático da Prompt Engineering em diferentes domínios.
Ajuste fino eficiente dos parâmetros
- Introdução ao ajuste fino eficiente dos parâmetrosIntrodução: A introdução das duas abordagens dominantes para a adaptação de tarefas downstream - aprendizado de contexto e ajuste fino de instruções - leva à técnica de ajuste fino eficiente de parâmetros (PEFT), detalhando as vantagens significativas em termos de redução de custos e eficiência.
- Métodos de anexação de parâmetrosDescrição detalhada dos métodos de ajuste fino eficiente, anexando novos módulos menores e treináveis à estrutura do modelo, incluindo a implementação e as vantagens de entradas de suplemento (por exemplo, ajuste de prompt), modelos de suplemento (por exemplo, ajuste de prefixo e ajuste de adaptador) e saídas de suplemento (por exemplo, ajuste de proxy).
- Método de seleção de parâmetrosIntrodução de métodos para o ajuste fino de apenas uma parte dos parâmetros do modelo, divididos em métodos baseados em regras (por exemplo, BitFit) e métodos baseados em aprendizado (por exemplo, Child-tuning), explorando como reduzir a carga computacional e melhorar o desempenho do modelo por meio da atualização seletiva dos parâmetros.
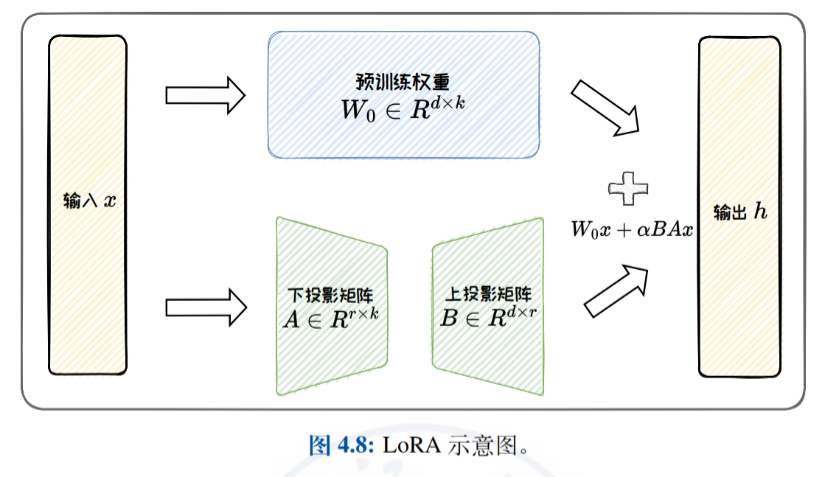
- Métodos de adaptação de baixa classificaçãoIntrodução detalhada ao ajuste fino eficiente por meio da aproximação da matriz de atualização de peso original por uma matriz de baixa classificação, com foco no LoRA e suas variantes (por exemplo, ReLoRA, AdaLoRA e DoRA), e uma discussão sobre a eficiência paramétrica do LoRA e os recursos de generalização de tarefas.
- Prática e aplicaçãoIntrodução: apresenta o uso da estrutura HF-PEFT e das técnicas relacionadas, demonstra casos de uso das técnicas PEFT na consulta e análise de dados tabulares e comprova a eficácia da PEFT no aprimoramento do desempenho de grandes tarefas específicas de modelos.
Edição de modelos
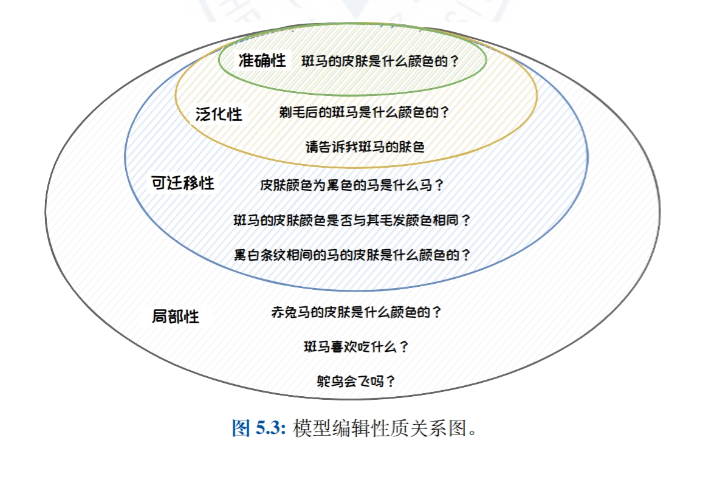
- Introdução à edição de modelosIntrodução à ideia, à definição e à natureza da edição de modelos, detalhando a importância da edição de modelos na correção de erros de viés, toxicidade e conhecimento em grandes modelos de linguagem.
- Abordagem clássica para edição de modelosClassificação dos métodos de edição de modelos em métodos de expansão externa (por exemplo, armazenamento de conhecimento e métodos de parâmetros adicionais) e métodos de modificação interna (por exemplo, meta-aprendizagem e métodos de edição posicional), apresentando trabalhos representativos de cada tipo de método.
- Método de parâmetro adicional: T-PatcherMétodo T-Patcher: O método T-Patcher é descrito em detalhes, o que permite o controle preciso da saída do modelo por meio da anexação de parâmetros específicos ao modelo e é adequado para cenários que exigem correção rápida e precisa de pontos de conhecimento específicos no modelo.
- Método de edição de local: ROMAIntrodução detalhada ao método ROME, que obtém um controle preciso dos resultados do modelo localizando e modificando camadas ou neurônios específicos dentro do modelo, e é adequado para cenários que exigem uma modificação profunda da estrutura de conhecimento interna do modelo.
- Aplicativos de edição de modelosIntrodução: Apresenta as aplicações práticas da edição de modelos na atualização precisa de modelos, protegendo o direito de ser esquecido e aumentando a segurança do modelo, e demonstra o potencial de aplicação da tecnologia de edição de modelos em diferentes cenários.
Geração aprimorada de pesquisa
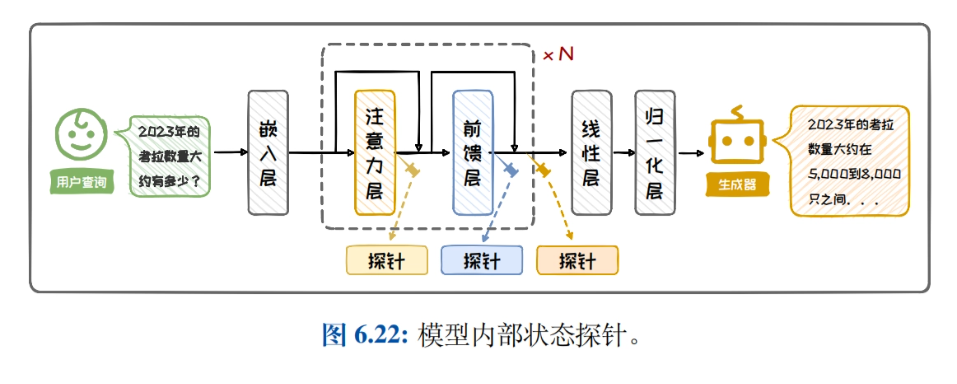
- Perfil de geração de aprimoramento de recuperaçãoIntrodução: apresenta o histórico e a composição da geração aprimorada por recuperação, detalhando a importância e os cenários de aplicação do aprimoramento do desempenho do modelo por meio da combinação de recuperação e geração em tarefas de processamento de linguagem natural.
- Recuperação da arquitetura de geração aprimoradaIntrodução: apresenta a classificação da arquitetura RAG, a arquitetura de aprimoramento de caixa preta e a arquitetura de aprimoramento de caixa branca, compara e analisa as características e os cenários aplicáveis de diferentes arquiteturas e ajuda os leitores a escolher a arquitetura adequada.
- recuperação de conhecimentoIntrodução detalhada à construção de bases de conhecimento, aprimoramento de consultas, pesquisadores e aprimoramento da eficiência da recuperação, explorando como melhorar a eficácia da recuperação e otimizar o processo de recuperação de conhecimento por meio do rearranjo dos resultados da recuperação.
- Aprimoramento da geraçãoIntrodução: apresenta quando aprimorar, onde aprimorar, vários aprimoramentos e métodos de redução de custos, discute estratégias para aplicar o aprimoramento generativo a diferentes tarefas e aprimora a qualidade e a eficiência do texto gerado.
- Prática e aplicaçãoIntrodução: Apresenta as etapas para criar um sistema RAG simples, mostra exemplos de RAG em aplicativos típicos e ajuda os leitores a entender e aplicar técnicas de geração aprimorada de recuperação para melhorar o desempenho de seus modelos em tarefas do mundo real.
Endereço para download de material de recursos
O relatório Fundamentals of Large Modelling está disponível para download em: https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (Código de acesso: 8894)
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas


Nenhum comentário...