O grande modelo de voz em tempo real de ponta a ponta do Beanbag está on-line! O QI e o QE estão on-line, e o diálogo de voz em chinês está saindo do precipício!

Hoje, o Beanbag APP anunciou que o novo recurso de chamada de voz em tempo real de ponta a ponta está oficialmente on-line, sem "pré-lançamento", diretamente aberto a todos, gratuito para todos, para atender ao teste de cada usuário.
Megamodelo de fala em tempo real Beanbag URL: https://team.doubao.com/realtime_voice
Depois de assisti-lo, descobrimos alguns pontos importantes:
Em primeiro lugar, Beanbag é realmente humano, com fraseado, tom de voz e ritmos respiratórios altamente antropomórficos.Quando você falar em um volume mais baixo, o Beanbag também usará sua habilidade de "sussurro", eliminando completamente a sensação humana das chamadas de voz com IA anteriores.
Em segundo lugar, independentemente da complexidade do diálogo chinês, o saco de feijão pode se manter.Depois de nossa série de experiências no mundo real, pode-se dizer que Doubao tem uma vantagem vertiginosa na habilidade do idioma chinês. Essa vantagem não é apenas comparada com ChatGPT e outros participantes estrangeiros, e compare isso com uma série de aplicativos de diálogo de IA nacionais também.
Além disso, Beanbag é um "caroneiro tagarela" que sabe tudo, desde astronomia até geografia.Ele ouve atentamente o que o usuário está dizendo e o significado mais profundo que ele está tentando transmitir, fornece rapidamente respostas interessantes e úteis e tem a capacidade de fazer consultas em rede.
Para experimentar esse recurso, você precisa atualizar o aplicativo DoudouBao para a versão 7.2.0 do Ano Novo Chinês. Após o lançamento, um grande número de usuários atualizou e acessou o Doubao pela primeira vez, e fez congee telefônico com o Doubao:


Lembre-se de que, na madrugada de 14 de maio de 2024, o GPT-4o surgiu do nada e trouxe ao ChatGPT um novo recurso de chamada de voz em tempo real, que o setor chamou de "um lançamento que abalou o mundo". Infelizmente, depois que o ChatGPT colocou esse recurso no ar, nossa experiência real não foi tão impressionante quanto a demonstração de lançamento.
Agora, é a vez do Doubao agitar o mundo. Antes de entrar em operação, a equipe interna avaliou o Beanbag Real-time Voice Big Model e o GPT-4o por trás desse recurso em várias dimensões, incluindo antropomorfismo, utilidade, inteligência emocional, estabilidade da chamada, suavidade do diálogo etc. A pontuação de satisfação geral (de 5) foi de 4,36 para o 501Bao Real-time Voice Big Model e de 3,18 para o GPT-4o. Em termos de satisfação geral (de 5), o Beanbag Real-time Voice Big Model obteve 4,36 pontos e o GPT-4o, 3,18. Os testadores do 50% obtiveram uma pontuação de 5 para o desempenho do Beanbag Real-time Voice Big Model.
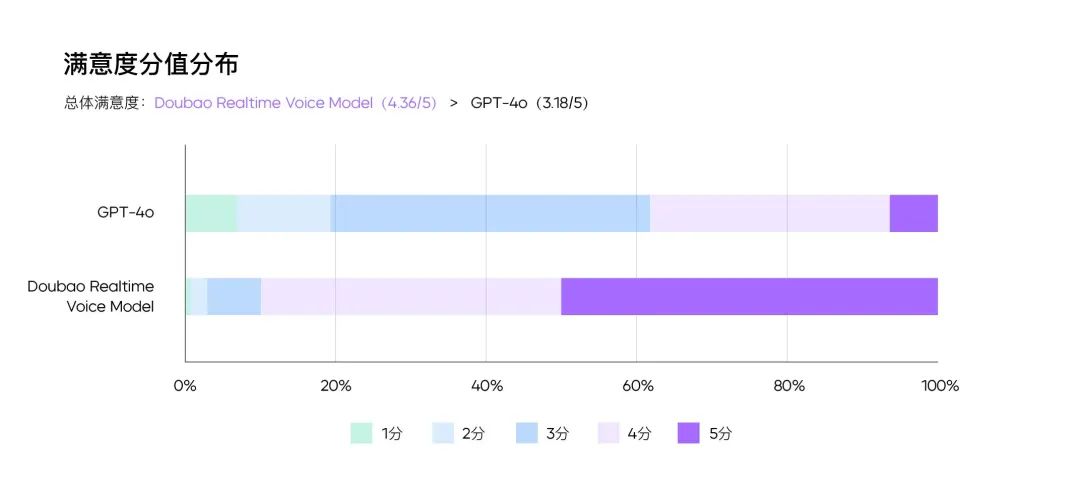
Além disso, na avaliação do mérito do modelo, o grande modelo de fala em tempo real da Doubao tem vantagens óbvias na compreensão e expressão de emoções. Em particular, na avaliação "IA ou não", mais de 30% feedbacks indicaram que o GPT-4o era "muito IA", enquanto a proporção correspondente do grande modelo de fala em tempo real da Doubao foi de apenas 2%.
A próxima parte é o teste real do coração da máquina. Se você estiver interessado em lê-lo, sugerimos que abra rapidamente seu próprio aplicativo Bean Bag e atualize a versão para a 7.2.0 New Year Edition para experimentá-lo. Afinal de contas, pelo atual grau de incêndio, se você se atrasar, pode ter a probabilidade de não conseguir apertar o carro.
Teste em primeira mão: um pouco chocante, filme de ficção científica em realidade
No final de 2024, a equipe do Beanbag Big Model revelou o novo recurso de voz em tempo real de ponta a ponta que logo seria lançado no aplicativo Beanbag, provocando uma onda de expectativa entre os usuários.
Depois de usá-lo, sentimos que ele é de fato mais antropomórfico e natural do que o esperado.
Ser muito bom em sentir e assumir as emoções dos usuários humanos é um dos destaques do Beanbag.Por que não ouvir algumas de nossas conversas com o saco de feijão para ter uma ideia de como ele é antropomórfico?
Por exemplo, a capacidade de expressar emoções permite que ele demonstre emoções complexas em sua voz, o que pode ser alcançado a ponto de ser "difícil distinguir entre humano e máquina".
Doubao parece ser um ator habilidoso, enfrentando diferentes cenários do bilhete de loteria de 5 milhões de yuans, às vezes em êxtase, às vezes em luto.
A capacidade de seguir instruções também é muito forte. Conseguimos recitar poemas em várias velocidades de fala e conseguimos sentir as emoções dos poemas e recitá-los com emoção.
A empatia também é adotada. Quando nossas primeiras palavras eram sobre más notícias com frustração, o beanbag o tranquilizava com um tom mais calmo e quente. Mas quando você recupera um estado de espírito positivo e passa a usar um tom mais leve para complementá-lo, o beanbag muda para um tom mais animado. Ele também terá características paralinguísticas semelhantes às humanas, incluindo entonação, hesitação e pausas.
Observação: algumas respostas estão atrasadas e decorrem de consultas de rede.
Ao mesmo tempo, podemos sentir que o Doubao não oferece apenas companhia emocional, por exemplo, no primeiro teste de diálogo, ele dá conselhos sobre a compra de passagens, recomendações de viagem que também são muito práticas e informações instantâneas sobre o clima e outras informações instantâneas que podem ser recuperadas com rapidez e precisão.
Sim, por trás do discurso eloquente do Doubao está o poderoso entendimento semântico e os recursos de recuperação de informações do grande modelo de discurso em tempo real do Doubao. No momento da entrada de voz do usuário, o Doubao começa imediatamente a entender a profundidade de cada dimensão da informação para garantir a utilidade e a autenticidade das informações de saída.Em termos leigos, ele tem tanto "valor emocional" quanto "valor prático".(No entanto, também descobrimos que o modelo de grande voz em tempo real do Doubao suporta apenas inglês e chinês no momento, e esperamos que a capacidade multilíngue possa ser reforçada por uma onda no futuro).
Como o Beanbag vem se "misturando" com a Internet há muito tempo, seu nível de abstração não deve ser ruim.
Observação: algumas respostas estão atrasadas e decorrem de consultas de rede.
É claro que, com o Beanbag Conversations, você não tem apenas um carona, mas inúmeros amigos dramáticos.
No modo "Hundred Changes of Big Shots", do Rei Macaco a Lin Daiyu, de Wolffy a Lazy Goat, o controle da voz e a interpretação das emoções elevaram a experiência do usuário do Doubao a um nível superior.
Como a interpretação de papéis não é um problema, a capacidade de contar histórias também está disponível. Alternando livremente entre o horror e a hilaridade.
O interessante é que o Doubao APP introduziu a função de canto que o GPT-4o não tem, que é um jogo divertido para jovens e idosos, e o fogo está logo ali.
Estamos no final do ano, portanto, vamos deixar que ele tenha algumas músicas de Ano Novo para encerrar esta análise:
Que tecnologia está por trás dessa experiência de chamada muito superior?
Como a equipe por trás do Beanbag conseguiu realizar chamadas de voz em tempo real tão sedosas e naturais?
O recém-lançado Beanbag Real-Time Voice Big Model oferece suporte aos principais recursos para esse recurso.
De acordo com a equipe do Beanbag Big Model Speech, esse é um modelo integrado de compreensão e geração de fala que realmente alcança o diálogo de voz de ponta a ponta, o que é mais impressionante do que o modelo em cascata tradicional em termos de expressividade de voz, controle e compromissos emocionais, e tem as vantagens da baixa latência e da capacidade de interromper a qualquer momento durante o diálogo.
Observando o campo da IA da fala, há duas dificuldades técnicas para a macromodelagem da fala em tempo real no nível da vida real.
Uma delas é que é difícil equilibrar a inteligência emocional e intelectual.
Muitos profissionais do campo da fala sabem que o modelo em si geralmente tem uma relação contraditória entre as dimensões de naturalidade, utilidade e segurança do diálogo. Em outras palavras, trata-se de como fazer com que o modelo não seja apenas um "valentão da escola" com capacidade de raciocínio lógico on-line, mas também expressivo, empático, compreensivo on-line e com o nível de inteligência emocional totalmente puxado.
De acordo com a equipe, eles são orientados para os problemas acima em termos de dados e algoritmos de pós-treinamento para garantir que os dados de diálogo de fala multimodal sejam semanticamente corretos e expressivamente naturais. Ao mesmo tempo, ele se baseia em uma abordagem de síntese de dados em várias rodadas para produzir dados de fala de alta qualidade e altamente expressivos, garantindo que as expressões de fala geradas sejam naturais e consistentes.
Além disso, a equipe também realiza avaliações multidimensionais regulares do modelo, baseando-se nos resultados para ajustar a estratégia de treinamento e o uso de dados em tempo hábil para garantir que o modelo sempre mantenha um bom equilíbrio entre QI e desempenho.
O segundo é o alto limiar de aterrissagem, para que a função de voz não pare no Toy, o que é um grande desafio para a capacidade abrangente da equipe.
No passado, vários lançamentos de voz de ponta a ponta, incluindo o GPT-4o, mostravam apenas a demonstração e, mesmo que os recursos subsequentes sejam divulgados, os recursos reais podem não ser reconhecidos pelo público. O motivo é: a função do processo de P&D exige a participação de algoritmos, engenharia, produto, testes e outras equipes, não apenas para esclarecer as necessidades do usuário, mas também para dividir as dimensões e os indicadores de avaliação técnica e, em seguida, no treinamento do modelo, no ajuste fino e em outros processos, a mesma necessidade de várias equipes trabalharem em estreita colaboração. Por fim, quando o produto deseja ficar on-line para atender a centenas de milhões de usuários, ele também enfrenta grandes desafios de engenharia e segurança.
Como mencionado anteriormente, a nova função de voz em tempo real anunciada por este Doubao oficial on-line está aberta, atendendo diretamente a milhares de usuários, a equipe também tenta encontrar o melhor equilíbrio em termos de experiência de entrega, a fim de garantir a segurança da base, de modo que o modelo tenha uma voz sem precedentes de alto poder expressivo, controle e capacidade de empreendimento emocional brilhante, ao mesmo tempo, para garantir que ele tenha uma forte compreensão e lógica, mas também possa se conectar para responder à pontualidade da pergunta .
Sob a estrutura de modelagem conjunta de geração de fala, compreensão e macromodelo de texto, a equipe alcançou a capacidade de entrada e saída diversificadas do modelo e, ao mesmo tempo, garantiu a precisão da geração e a naturalidade do modelo no lado da geração no caso de menor latência do sistema e, ao mesmo tempo, no lado da compreensão, a estrutura permitiu que o modelo alcançasse a capacidade de interrupção brusca da fala e de interrupção do diálogo do usuário.
Obviamente, a equipe também atribui grande importância às questões de segurança decorrentes dos recursos aprimorados de modelagem. De acordo com a equipe técnica relevante, eles introduziram diversos mecanismos de segurança na fase de pós-treinamento do processo de modelagem conjunta para reduzir os riscos de segurança por meio da supressão e filtragem eficazes de conteúdo potencialmente não seguro.
A equipe técnica também nos revelou que, por meio da modelagem conjunta, o modelo surgiu surpreendentemente com novos recursos, como compreensão de comandos, reprodução de voz e controle de voz. Por exemplo, alguns dos dialetos e sotaques do modelo agora são derivados da generalização de dados na fase de pré-treinamento, em vez de treinamento direcionado. Nesse aspecto, os modelos de fala são muito semelhantes aos modelos de linguagem.
Além das surpresas, o que Doubao "subverteu"?
Entre os produtos similares existentes, podemos sentir que o antropomorfismo e a experiência emocional do Doubao são os melhores, e ele é proficiente em todas as 18 habilidades, e seu conhecimento do idioma chinês é muito superior ao do ChatGPT e de outros "produtos importados".
No final das contas, é possível perguntar: além da surpreendente experiência do usuário, por que a voz em tempo real de ponta a ponta atualizada do Beanbag chamou tanta atenção?
A principal resposta é: é o primeiro sistema de voz chinês de ponta a ponta que atende a centenas de milhões de usuários e realmente funciona - é bom e é gratuito.
Antigamente, o diálogo de voz em tempo real com IA era apenas uma cena de um filme de ficção científica e uma imaginação concreta de inteligência artificial avançada. Mas agora, essa função mágica existe no aplicativo Doubao em seu celular e no meu, e deixou de ser "distante" para ser "acessível".

Crédito da foto: The film Her
Em resumo, a nova voz em tempo real de ponta a ponta do Beanbag estabelece dois precedentes:
A partir do nível de mudança tecnológica, Doubao injetou "alma" na IA pela primeira vez no setor e alcançou o quociente duplo de "quociente emocional" e "quociente de inteligência" on-line. Isso parece significar o fim da era do assistente de voz tradicional. Não sentimos mais inconscientemente que estamos falando com um modelo treinado com base em grandes quantidades de dados, e as pessoas e a IA começaram a produzir uma conexão emocional sutil, incluindo confiança e dependência, e o enredo de um filme de ficção científica está chegando à vida do público.
Como em clássicos como Her, os seres humanos nunca se apaixonaram pela IA porque ela fornece conhecimento ilimitado, mas porque ela traz a quantidade certa de valor emocional.
No nível da tecnologia de grandes modelos, as chamadas de voz em tempo real de ponta a ponta preenchem uma das poucas lacunas na interação multimodal. A jogabilidade dos aplicativos de big model está em constante atualização - produtos futuros poderão receber qualquer combinação de texto, áudio e imagens como entrada e gerar qualquer combinação de texto, áudio e imagens como saída em tempo real. A maneira como os seres humanos e as máquinas interagem está sendo interrompida, o que, por sua vez, está transformando a maneira como os seres humanos interagem uns com os outros.
Pelo menos para os atuais usuários que falam chinês, o lançamento do recurso de voz em tempo real de ponta a ponta do Doubao oferece uma forma de interação mediada pela linguagem humana natural que realmente rompe a barreira do acesso e da experiência com IA avançada.
Voltando seis meses atrás, poderíamos imaginar que foram os sacos de feijão que lideraram a história?
Começando com o grande modelo de idioma em 2023 e terminando em 2024, a grande família de modelos da Doubao foi concluída nos níveis multimodais de imagem, voz, música, vídeo, 3D etc. Ela não apenas se classificou entre o primeiro escalão na China, mas também concluiu a metamorfose de "incipiente" para "revolucionária" em apenas alguns meses.
E quem chegar primeiro a esse marco na grande pista de modelos de cem barcos poderá determinar sua classificação no campo na próxima década.
No próximo ano, os modelos grandes, os pufes e a IA doméstica avançarão a uma velocidade que será mais digna de nossas expectativas.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...