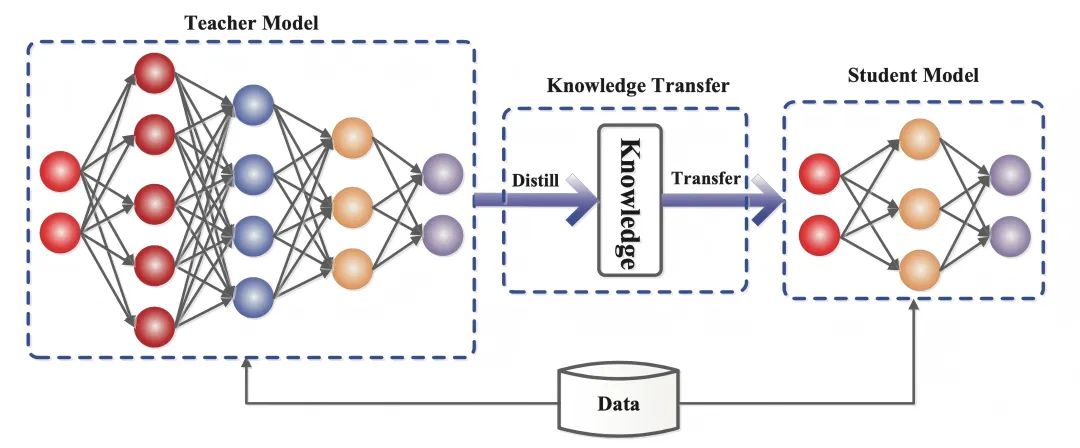
A destilação de conhecimento é uma técnica de aprendizado de máquina que visa transferir o aprendizado de um modelo grande pré-treinado (ou seja, um "modelo de professor") para um "modelo de aluno" menor. As técnicas de destilação podem nos ajudar a desenvolver modelos generativos mais leves para uso em áreas como diálogo inteligente e criação de conteúdo.
mais próximo (de locais) Destilação Essa palavra é vista com muita frequência.
A equipe do DeepSeek, que fez um grande alarde há dois dias, lançou o DeepSeek-R1cujo modelo grande com 670B parâmetros foi migrado com sucesso para um modelo leve com 7B parâmetros por meio de técnicas de aprendizagem por reforço e destilação.
O modelo destilado supera os modelos tradicionais do mesmo tamanho e até mesmo se aproxima do modelo pequeno mais importante da OpenAI, o OpenAI-o1-mini.
No campo da inteligência artificial, grandes modelos de linguagem (por exemplo, GPT-4, DeepSeek-R1 ) demonstrou excelentes recursos de raciocínio e geração com centenas de bilhões de parâmetros. No entanto, seus enormes requisitos computacionais e os altos custos de implantação limitam muito sua aplicação em cenários como dispositivos móveis e computação de ponta.
Como compactar o tamanho do modelo sem perder o desempenho?Destilação de conhecimento(Destilação de conhecimento) é uma técnica fundamental para resolver esse problema.
1. o que é destilação de conhecimento
A destilação de conhecimento é uma técnica de aprendizado de máquina que visa transferir o aprendizado de um modelo grande pré-treinado (ou seja, um "modelo de professor") para um "modelo de aluno" menor.
Na aprendizagem profunda, ele é usado como uma forma de compressão de modelos e transferência de conhecimento, especialmente para redes neurais profundas de grande escala.
A essência da destilação do conhecimento émigração de conhecimentoque imita a distribuição de resultados do modelo do professor, de modo que o modelo do aluno herda sua capacidade de generalização e lógica de raciocínio.
- Modelo de professor(Modelo do professor): geralmente um modelo complexo com um grande número de parâmetros e treinamento suficiente (por exemplo, DeepSeek-R1), cuja saída contém não apenas os resultados da previsão, mas também implicitamente as informações de similaridade entre as categorias.
- Modelos de alunos(Modelo do aluno: um modelo pequeno e compacto, com menos parâmetros, que permite a transferência de competências por meio da correspondência com as metas flexíveis do modelo do professor.
Diferentemente da aprendizagem profunda tradicional, em que o objetivo é treinar uma rede neural artificial para fazer previsões que se assemelhem mais aos resultados de amostra fornecidos no conjunto de dados de treinamento, a destilação do conhecimento exige que o modelo do aluno não apenas se ajuste à resposta correta (um objetivo difícil), mas também aprenda a "lógica do pensamento" do modelo do professor. -Ou seja, o resultado dodistribuição de probabilidade(alvo fácil).
Por exemplo, na tarefa de classificação de imagens, o modelo do professor não apenas indicará "esta imagem é um gato" (confiança 90%), mas também dará possibilidades como "parece uma raposa" (5%), "outros animais " (5%) e outras possibilidades.
Ao capturar as correlações (por exemplo, gatos e raposas têm orelhas pontudas e características de pelo semelhantes), o modelo do aluno acabará aprendendo a ser mais flexível em sua capacidade de discriminar, em vez de memorizar mecanicamente as respostas padrão.
2. conhecimento de como funciona a destilação
No artigo de 2015 Distilling the Knowledge in a Neural Network (Destilando o conhecimento em uma rede neural), que propõe a divisão do treinamento em dois estágios com finalidades diferentes, os autores fazem uma analogia: enquanto a forma larval de muitos insetos é otimizada para extrair energia e nutrientes do ambiente, a forma adulta é completamente diferente, otimizada para deslocamento e reprodução, enquanto a aprendizagem profunda tradicional tradicional usa os mesmos modelos nas fases de treinamento e implantação, mesmo que eles tenham requisitos diferentes.
O entendimento de "conhecimento" nos documentos também varia:
Antes da publicação do artigo, havia uma tendência de equiparar o conhecimento no modelo de treinamento com os valores dos parâmetros aprendidos, o que dificultava ver como o mesmo conhecimento poderia ser mantido ao mudar a forma do modelo.
Uma visão mais abstrata do conhecimento é que ele é um aprendizadoMapeamento do vetor de entrada para o vetor de saída.
As técnicas de destilação de conhecimento não apenas replicam o resultado dos modelos dos professores, mas também imitam seus "processos de pensamento". Na era dos LLMs, a destilação do conhecimento permite a transferência de qualidades abstratas, como estilo, capacidade de raciocínio e alinhamento com as preferências e os valores humanos.
A realização da destilação do conhecimento pode ser dividida em três etapas principais:
2.1 Geração de alvos flexíveis: "fuzzificando" as respostas
O modelo do professor é passadoSoftmax de alta temperaturaA tecnologia transforma as respostas "preto e branco" em "dicas difusas" que contêm informações detalhadas.
À medida que a temperatura (Temperature) aumenta (por exemplo, T=20), a distribuição de probabilidade da saída do modelo fica mais suave.
Por exemplo, a sentença original "Cat (90%), Fox (5%)"
Pode se tornar "Gato (60%), Raposa (20%), Outro (20%)".
Esse ajuste força os modelos dos alunos a se concentrarem em correlações entre categorias (por exemplo, gatos e raposas têm orelhas de formato semelhante) em vez de memorizar rótulos mecanicamente.
2.2 Projeto da função objetiva: equilibrando objetivos flexíveis e rígidos
Os objetivos de aprendizado do modelo do aluno são dois:
- Imitar a lógica do pensamento do professor(soft target): aprender relacionamentos entre turmas combinando as distribuições de probabilidade de alta temperatura dos professores.
- Lembre-se da resposta correta.(Meta difícil): Garantir que não haja declínio na precisão básica.
A função de perda do modelo do aluno é uma combinação ponderada de alvos suaves e difíceis, e os pesos de ambos precisam ser ajustados dinamicamente.
Por exemplo, ao atribuir pesos de 70% a metas flexíveis e 30% a metas difíceis, é semelhante ao fato de os alunos passarem 70% estudando as soluções do professor e 30% consolidando as respostas padrão, alcançando um equilíbrio entre flexibilidade e precisão.
2.3 Regulação dinâmica dos parâmetros de temperatura, controle da "granularidade de transferência" do conhecimento.
O parâmetro de temperatura é o "botão de dificuldade" da destilação intelectual:
- Modo de alta temperatura(por exemplo, T=20): as respostas são altamente ambíguas e adequadas para transmitir associações complexas (por exemplo, distinguir entre diferentes raças de gatos).
- modo de baixa temperatura(por exemplo, T = 1): as respostas estão próximas da distribuição original e são adequadas para tarefas simples (por exemplo, reconhecimento de números).
- estratégia dinâmicaAbsorção extensiva de conhecimento, inicialmente com altas temperaturas e, posteriormente, esfriando para se concentrar nos principais recursos.
Por exemplo, as tarefas de reconhecimento de fala exigem temperaturas mais baixas para manter a precisão. Esse processo é semelhante ao de um professor que ajusta a profundidade da instrução de acordo com o nível do aluno - desde a heurística até a realização de provas.
3. importância da destilação do conhecimento
Os modelos de melhor desempenho para uma determinada tarefa tendem a ser muito grandes, lentos ou caros para a maioria dos casos de uso no mundo real, mas têm um desempenho excelente que se deve ao seu tamanho e à capacidade de pré-treinamento em grandes quantidades de dados de treinamento.
Por outro lado, modelos menores, embora mais rápidos e menos exigentes do ponto de vista computacional, são menos precisos, menos refinados e menos informados do que modelos maiores com mais parâmetros.
É aí que entra em jogo o valor da aplicação da destilação do conhecimento, por exemplo:
O modelo grande de 670B parâmetros do DeepSeek-R1 migra seus recursos para um modelo leve de 7B parâmetros por meio de uma técnica de destilação de conhecimento: o DeepSeek-R1-7B, que supera os modelos sem inferência, como o GPT-4o-0513, em todos os aspectos. DeepSeek-R1-32B e DeepSeek-R1-70B superam significativamente o o1-mini na maioria dos benchmarks.
Esses resultados demonstram o grande potencial da destilação. A destilação do conhecimento tornou-se uma importante ferramenta técnica.
No campo do processamento de linguagem natural, muitos institutos de pesquisa e empresas usam técnicas de destilação para compactar modelos de linguagem grandes em versões menores para tarefas como tradução, sistemas de diálogo e classificação de texto.
Por exemplo, modelos grandes, quando destilados, podem ser executados em dispositivos móveis para fornecer serviços de tradução em tempo real sem depender de recursos avançados de computação em nuvem.
O valor da destilação do conhecimento é ainda mais significativo na IoT e na computação de borda. Embora os modelos tradicionais de grande porte geralmente exijam um suporte avançado de cluster de GPU, os modelos pequenos são destilados para serem executados em microprocessadores ou dispositivos incorporados com consumo de energia muito menor.
Essa tecnologia não apenas reduz drasticamente os custos de implantação, mas também permite que os sistemas inteligentes sejam mais amplamente utilizados em áreas como saúde, direção autônoma e casas inteligentes.
No futuro, o potencial de aplicação da destilação de conhecimento será ainda mais amplo. Com o desenvolvimento da IA generativa, a tecnologia de destilação pode nos ajudar a desenvolver modelos generativos mais leves para o diálogo inteligente, a criação de conteúdo e outras áreas.