
Como os grandes modelos ficam mais "inteligentes"? A Universidade de Stanford revela a chave para o autoaperfeiçoamento: quatro comportamentos cognitivos

O campo da Inteligência Artificial fez um progresso impressionante nos últimos anos, especialmente na área de Modelagem de Linguagem Grande (LLM). Muitos modelos, como o Qwen, demonstraram uma incrível capacidade de autoverificação de respostas e correção de erros. Entretanto, nem todos os modelos têm a mesma capacidade de autoaperfeiçoamento. Com os mesmos recursos computacionais adicionais e o mesmo tempo de "raciocínio", alguns modelos conseguem aproveitar ao máximo esses recursos e melhorar drasticamente seu desempenho, enquanto outros têm pouco sucesso. Esse fenômeno levanta a questão: quais fatores são responsáveis por essa discrepância?
Assim como os seres humanos passam mais tempo pensando profundamente quando confrontados com problemas difíceis, alguns modelos avançados de grandes linguagens começam a exibir um comportamento de raciocínio semelhante quando treinados para o autoaperfeiçoamento por meio do aprendizado por reforço. Entretanto, há diferenças significativas no autoaperfeiçoamento entre modelos treinados com o mesmo aprendizado por reforço. Por exemplo, o Qwen-2.5-3B supera de longe o Llama-3.2-3B no jogo Countdown. Embora ambos os modelos sejam relativamente fracos no estágio inicial, no final do treinamento de aprendizagem por reforço, o Qwen atinge uma precisão de cerca de 60%, enquanto o Llama tem apenas cerca de 30%. Qual é o mecanismo oculto por trás dessa diferença significativa?
Um estudo recente de Stanford aprofundou os mecanismos por trás da capacidade de autoaperfeiçoamento de modelos grandes, revelando que os principais modelos de linguagem no sistema subjacente de comportamento cognitivo A importância da IA. Esta pesquisa oferece novas perspectivas sobre a compreensão e o aprimoramento dos recursos de autoaperfeiçoamento dos sistemas de IA.
O estudo foi amplamente discutido após sua divulgação. O CEO da Synth Labs, por exemplo, acredita que a descoberta é empolgante porque promete ser integrada a qualquer modelo para melhorar seu desempenho.

Quatro comportamentos cognitivos principais
Para investigar os motivos das diferenças no autoaperfeiçoamento, os pesquisadores se concentraram em dois modelos básicos, Qwen-2.5-3B e Llama-3.2-3B. Ao treiná-los com o aprendizado por reforço no jogo Countdown, os pesquisadores observaram diferenças significativas: a capacidade de resolução de problemas do Qwen melhorou significativamente, enquanto o Llama-3 apresentou um aprimoramento relativamente limitado durante o mesmo processo de treinamento. Então, quais propriedades do modelo são responsáveis por essa diferença?

Para examinar sistematicamente essa questão, a equipe de pesquisa desenvolveu uma estrutura para analisar os comportamentos cognitivos que são essenciais para a solução de problemas. A estrutura descreve quatro comportamentos cognitivos principais:
- VerificaçãoVerificação sistemática de erros.
- Retrocesso:: Abandonar abordagens fracassadas e tentar novos caminhos.
- Definição de sub-metas:: Divide problemas complexos em etapas gerenciáveis.
- Pensamento reversoDerivação reversa do resultado desejado para a entrada inicial.
Esses padrões de comportamento são muito semelhantes à maneira como os solucionadores de problemas especializados abordam tarefas complexas. Por exemplo, os matemáticos realizam provas verificando cuidadosamente cada etapa da derivação; voltando atrás para verificar as etapas anteriores quando são encontradas contradições; e dividindo teoremas complexos em lemas mais simples para provas passo a passo.

Análises preliminares indicam que o modelo Qwen apresenta naturalmente esses comportamentos de inferência, especialmente nas áreas de validação e retrocesso, ao passo que o modelo Llama-3 não apresenta esses comportamentos de forma evidente. Com base nessas observações, os pesquisadores formularam a hipótese central: Determinados comportamentos de raciocínio na estratégia inicial são essenciais para que o modelo faça uso efetivo do maior tempo de teste. Em outras palavras, se um modelo de IA quiser se tornar "mais inteligente" quando tiver mais tempo para "pensar", ele deverá primeiro ter algumas habilidades básicas de raciocínio, como o hábito de verificar se há erros e verificar os resultados. Se o modelo não tiver essas habilidades básicas de raciocínio desde o início, ele não conseguirá melhorar efetivamente seu desempenho, mesmo que receba mais tempo de raciocínio e recursos computacionais. Isso é muito semelhante ao processo de aprendizado humano: se os alunos não tiverem habilidades básicas de autoverificação e correção de erros, é improvável que a simples realização de exames mais longos melhore significativamente seu desempenho.
Validação experimental: a importância do comportamento cognitivo
Para testar a hipótese acima, os pesquisadores realizaram uma série de experimentos de intervenção inteligentes.
Primeiramente, eles tentaram fazer um bootstrap do modelo Llama-3 usando trajetórias de inferência sintéticas contendo comportamentos cognitivos específicos (especialmente retrospecção). Os resultados mostram que o modelo Llama-3, assim orientado, apresenta melhorias significativas na aprendizagem por reforço, com ganhos de desempenho comparáveis aos do Qwen-2.5-3B.
Em segundo lugar, mesmo que as trajetórias de raciocínio usadas para o bootstrapping contivessem respostas incorretas, o modelo Llama-3 ainda era capaz de progredir, desde que essas trajetórias exibissem padrões de raciocínio corretos. Essa descoberta sugere que o O principal fator que realmente impulsiona o autoaperfeiçoamento do modelo é a presença do comportamento de raciocínio, não a correção da resposta em si.
Por fim, os pesquisadores filtraram o conjunto de dados OpenWebMath para enfatizar esses comportamentos de raciocínio e usaram esses dados para pré-treinar o modelo Llama-3. Os resultados experimentais mostram que essa adaptação direcionada dos dados de pré-treinamento é eficaz para induzir os comportamentos de inferência necessários para que o modelo faça uso eficiente dos recursos computacionais. A trajetória de melhoria do desempenho do modelo Llama-3 pré-treinado e ajustado é surpreendentemente consistente com a do modelo Qwen-2.5-3B.
Os resultados desses experimentos revelam uma forte ligação entre o comportamento de raciocínio inicial de um modelo e sua capacidade de se aprimorar. Essa ligação ajuda a explicar por que alguns modelos de linguagem são capazes de utilizar eficientemente recursos computacionais adicionais, enquanto outros ficam estagnados. Uma compreensão mais profunda dessa dinâmica é essencial para o desenvolvimento de sistemas de IA que possam melhorar significativamente a solução de problemas.
Jogo de contagem regressiva com seleção de modelos
O estudo começa com uma observação surpreendente: modelos de linguagem de tamanho semelhante, de diferentes famílias de modelos, apresentam melhorias de desempenho muito diferentes quando treinados com aprendizado por reforço. Para explorar esse fenômeno em profundidade, os pesquisadores escolheram o jogo Countdown como seu principal banco de testes.
Countdown é um quebra-cabeça de matemática no qual o jogador precisa combinar um determinado conjunto de números para chegar a um número-alvo usando as quatro operações básicas de adição, subtração, multiplicação e divisão. Por exemplo, dados os números 25, 30, 3, 4 e o número-alvo 32, o jogador precisa obter o número exato 32 por meio de uma série de operações, por exemplo, (30 - 25 + 3) × 4 = 32.
O jogo Countdown foi escolhido para este estudo porque examina os recursos de raciocínio matemático, planejamento e estratégia de busca do modelo, ao mesmo tempo em que oferece um espaço de busca relativamente restrito que permite ao pesquisador realizar análises aprofundadas. Em comparação com domínios mais complexos, o jogo Countdown reduz a dificuldade de análise e, ao mesmo tempo, examina com eficácia o raciocínio complexo. Além disso, o sucesso do Countdown depende mais das habilidades de resolução de problemas do que de outras tarefas matemáticas, em vez de conhecimento matemático puro.
Os pesquisadores escolheram dois modelos básicos, Qwen-2.5-3B e Llama-3.2-3B, para comparar as diferenças de aprendizagem entre as diferentes famílias de modelos. Os experimentos de aprendizagem por reforço são baseados na biblioteca VERL e implementados usando o TinyZero. Eles usaram o algoritmo PPO (Proximal Policy Optimization) para treinar o modelo em 250 etapas, amostrando 4 trajetórias por pista. O motivo da escolha do algoritmo PPO é que, em comparação com o algoritmo GRPO e outros algoritmos de aprendizado por reforço, como o REINFORCE, o PPO apresenta melhor estabilidade em várias configurações de hiperparâmetro, embora a diferença geral de desempenho entre os algoritmos não seja significativa. (Nota do editor: Suspeita-se que o original "GRPO" seja um erro de escrita e deva ser lido como PPO.)
Os resultados experimentais revelam trajetórias de aprendizado muito diferentes para os dois modelos. Embora ambos tenham desempenho semelhante no início da tarefa, com pontuações baixas, o Qwen-2.5-3B mostra um "salto qualitativo" por volta da 30ª etapa do treinamento, conforme evidenciado pelas respostas significativamente mais longas geradas pelo modelo e um aumento significativo na precisão. No final do treinamento, o Qwen-2.5-3B atinge uma precisão de cerca de 601 TP3T, que é muito maior do que os 301 TP3T do Llama-3.2-3B.
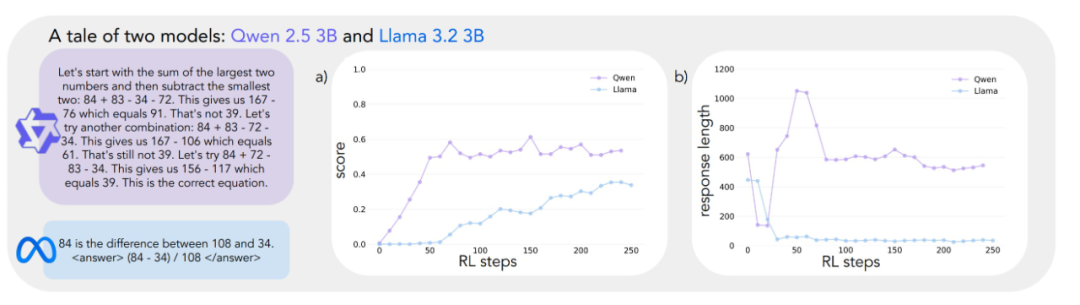
Nos últimos estágios do treinamento, os pesquisadores observaram uma mudança interessante no comportamento do Qwen-2.5-3B: o modelo passou gradualmente do uso de declarações de validação explícitas (por exemplo, "8*35 é 280, muito alto") para a verificação implícita da solução. O modelo irá последовательно (em russo, traduzido como "последовательно land" ou "sequencialmente") experimentar diferentes soluções até encontrar a correta e não mais avaliar seu próprio trabalho usando palavras. O contraste é impressionante. Esse contraste leva a uma questão central: quais são os recursos subjacentes que permitem que um modelo alcance o autoaperfeiçoamento com sucesso com base no raciocínio? Para responder a essa pergunta, é necessária uma estrutura sistemática para analisar o comportamento cognitivo.
Estrutura da análise cognitivo-comportamental
Para obter uma compreensão mais profunda das trajetórias de aprendizagem muito diferentes dos dois modelos, os pesquisadores desenvolveram uma estrutura para identificar e analisar os principais comportamentos cognitivos nos resultados do modelo. A estrutura se concentra em quatro comportamentos básicos:
- RetrocessoModificação explícita do método quando um erro é detectado (por exemplo, "Este método não funciona porque ..."). .").
- VerificaçãoVerificação sistemática de resultados intermediários (por exemplo, "Vamos validar esse resultado com ... para verificar esse resultado").
- Definição de sub-metas...: Divida problemas complexos em etapas gerenciáveis (por exemplo, "Para resolver esse problema, primeiro precisamos ..."). .
- Pensamento reversoEm problemas de raciocínio direcionado a metas, comece com um resultado desejado e trabalhe de trás para frente para encontrar um caminho para a solução (por exemplo, "Para atingir a meta de 75, precisamos de um número que seja ... divisível por ..."). .").
Esses comportamentos foram escolhidos porque representam uma estratégia de solução de problemas muito diferente dos padrões de raciocínio linear e monotônico comuns nos modelos de linguagem. Esses comportamentos cognitivos permitem trajetórias de raciocínio mais dinâmicas e semelhantes a pesquisas, em que as soluções podem evoluir de forma não linear. Embora esse conjunto de comportamentos não seja exaustivo, os pesquisadores os escolheram porque são fáceis de identificar e se ajustam naturalmente às estratégias humanas de solução de problemas nos jogos Countdown e em tarefas mais amplas de raciocínio matemático, como a construção de provas matemáticas.
Cada comportamento cognitivo pode ser entendido por meio de sua função no raciocínio do token Por exemplo, o retrocesso é representado pela negação explícita e pela substituição de sequências de tokens de etapas anteriores. Por exemplo, o retrocesso é representado como uma sequência de tokens que negam e substituem explicitamente as etapas anteriores; a validação é representada pela geração de tokens que comparam os resultados com os critérios de solução; o retrocesso é representado por tokens que constroem de forma incremental um caminho de solução para o estado inicial a partir da meta; e a definição de submetas é representada pela sugestão explícita de etapas intermediárias a serem alcançadas ao longo do caminho para a meta final. Os pesquisadores desenvolveram um pipeline de classificação usando o modelo GPT-4o-mini que identifica de forma confiável esses padrões na saída do modelo.
O impacto do comportamento inicial no autoaperfeiçoamento
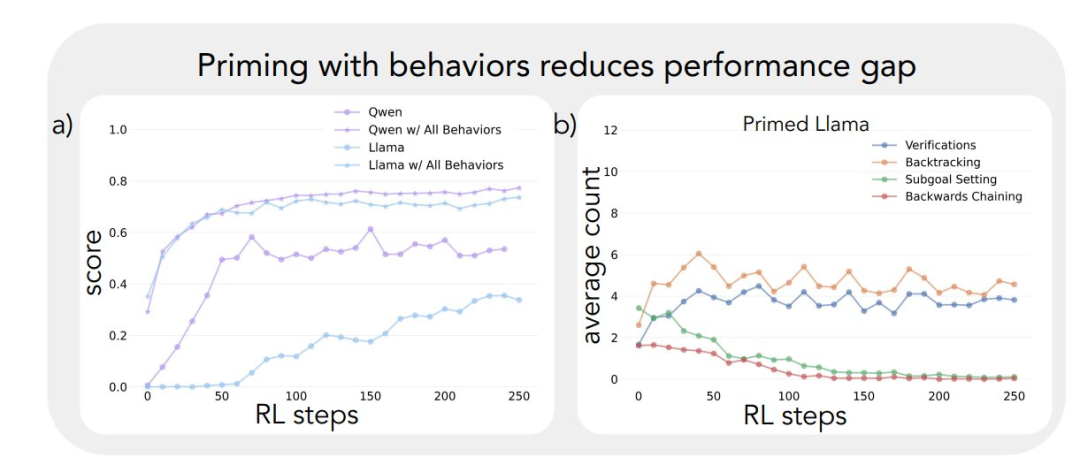
A aplicação da estrutura analítica acima aos experimentos iniciais produziu um insight importante: A melhoria significativa no desempenho do modelo Qwen-2.5-3B ocorre paralelamente ao surgimento de comportamentos cognitivos, especialmente os comportamentos de verificação e retrocesso. Em contrapartida, o modelo Llama-3.2-3B apresentou poucos sinais desses comportamentos durante o treinamento.
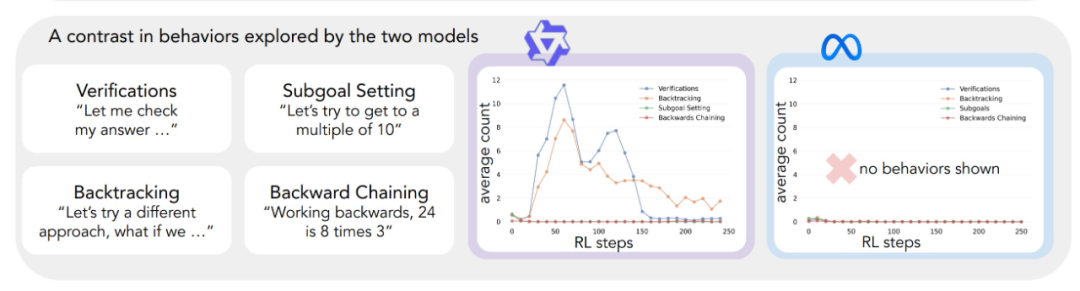
Para entender melhor essa diferença, os pesquisadores analisaram os padrões de raciocínio de linha de base dos três modelos: Qwen-2.5-3B, Llama-3.2-3B e Llama-3.1-70B. Os resultados das análises mostraram que o modelo Qwen-2.5-3B produziu proporções mais altas de todos os comportamentos cognitivos do que as duas variantes do modelo Llama, Llama-3.2-3B e Llama-3.1-70B. O modelo 2.5-3B produziu uma proporção maior de todos os comportamentos cognitivos. Embora o modelo maior Llama-3.1-70B tenha ativado esses comportamentos com mais frequência do que o modelo Llama-3.2-3B, esse aumento foi desigual, especialmente para comportamentos retrospectivos, que permaneceram limitados mesmo no modelo maior.

Essas observações revelam duas percepções importantes:
- A presença de determinados comportamentos cognitivos na estratégia inicial pode ser um pré-requisito necessário para que o modelo faça uso efetivo da computação do tempo de teste aumentado, estendendo a sequência de inferência.
- Aumentar o tamanho do modelo pode melhorar a frequência de ativação contextual desses comportamentos cognitivos até certo ponto.
Esse modelo é fundamental porque a aprendizagem por reforço só pode ampliar comportamentos que já estão presentes em trajetórias bem-sucedidas. Isso significa que a disponibilidade inicial desses comportamentos cognitivos é um pré-requisito para o aprendizado eficaz no modelo.
Intervenção no comportamento inicial: orientando a aprendizagem de modelos
Tendo estabelecido a importância dos comportamentos cognitivos no modelo básico, a próxima pergunta é: esses comportamentos podem ser induzidos artificialmente no modelo por meio de intervenções direcionadas? Os pesquisadores levantaram a hipótese de que, ao criar variantes do modelo básico que exibem seletivamente comportamentos cognitivos específicos antes do treinamento de aprendizagem por reforço, seria possível obter uma compreensão mais profunda de quais padrões comportamentais são essenciais para uma aprendizagem eficaz.
Para testar essa hipótese, eles primeiro criaram sete conjuntos de dados iniciais diferentes usando o jogo Countdown. Cinco desses conjuntos de dados enfatizavam diferentes combinações de comportamentos: todas as combinações de estratégias, apenas retrocesso, retrocesso e validação, retrocesso e definição de subobjetivos, e retrocesso e pensamento para trás. Eles usaram o modelo Claude-3.5-Sonnet para gerar esses conjuntos de dados devido à capacidade do Claude-3.5-Sonnet de gerar trajetórias de inferência com características comportamentais especificadas com precisão.
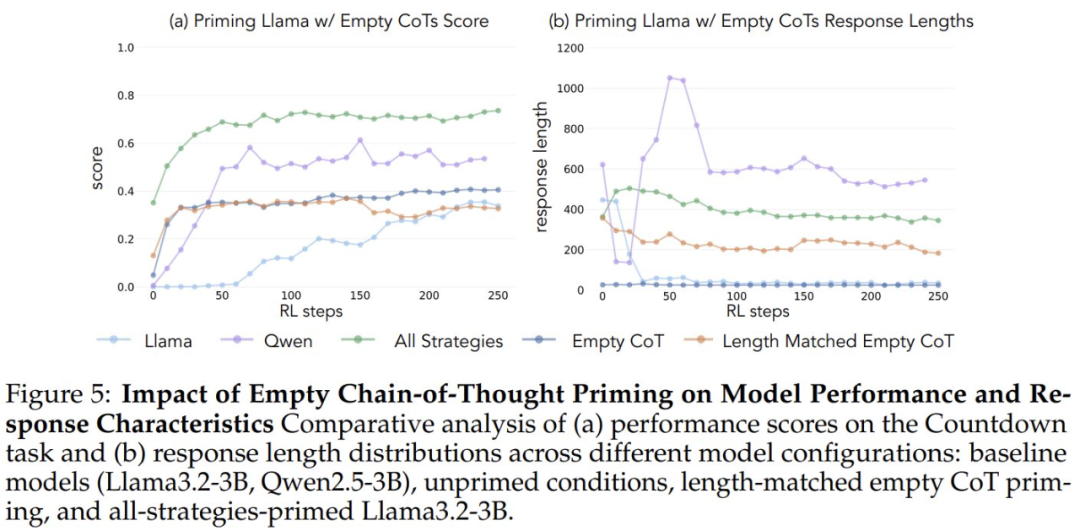
Para verificar se os ganhos de desempenho se deviam a comportamentos cognitivos específicos e não simplesmente a um aumento no tempo de computação, os pesquisadores também introduziram duas condições de controle: uma Cadeia de Pensamento vazia e uma condição de controle que preenchia a cadeia de tokens de espaço reservado e combinava o comprimento dos pontos de dados com o conjunto de dados "todas as combinações de estratégias". ". Esses conjuntos de dados de controle ajudaram os pesquisadores a verificar se as melhorias de desempenho observadas eram de fato devidas a comportamentos cognitivos específicos, e não apenas a um aumento no tempo de computação.
Além disso, os pesquisadores criaram uma variante do conjunto de dados "Full Strategy Combination", que contém apenas soluções incorretas, mas mantém os padrões de raciocínio necessários. O objetivo dessa variante é distinguir a diferença entre a importância do comportamento cognitivo e a precisão das soluções.
Os resultados experimentais mostram que os modelos Llama-3 e Qwen-2.5-3B apresentam melhorias significativas de desempenho por meio do treinamento de aprendizagem por reforço quando inicializados com um conjunto de dados que contém comportamento retrospectivo. A análise comportamental mostra ainda que O aprendizado por reforço amplifica seletivamente os comportamentos que se mostraram empiricamente úteis, enquanto inibe outros comportamentos. Por exemplo, na condição de Combinação de Estratégia Completa, o modelo retém e aprimora os comportamentos retrospectivos e de validação, ao mesmo tempo em que reduz a frequência dos comportamentos de retrocesso e de definição de submetas. No entanto, quando emparelhado apenas com comportamentos retrospectivos, os comportamentos suprimidos (por exemplo, retrocesso e definição de submetas) persistem durante todo o treinamento.
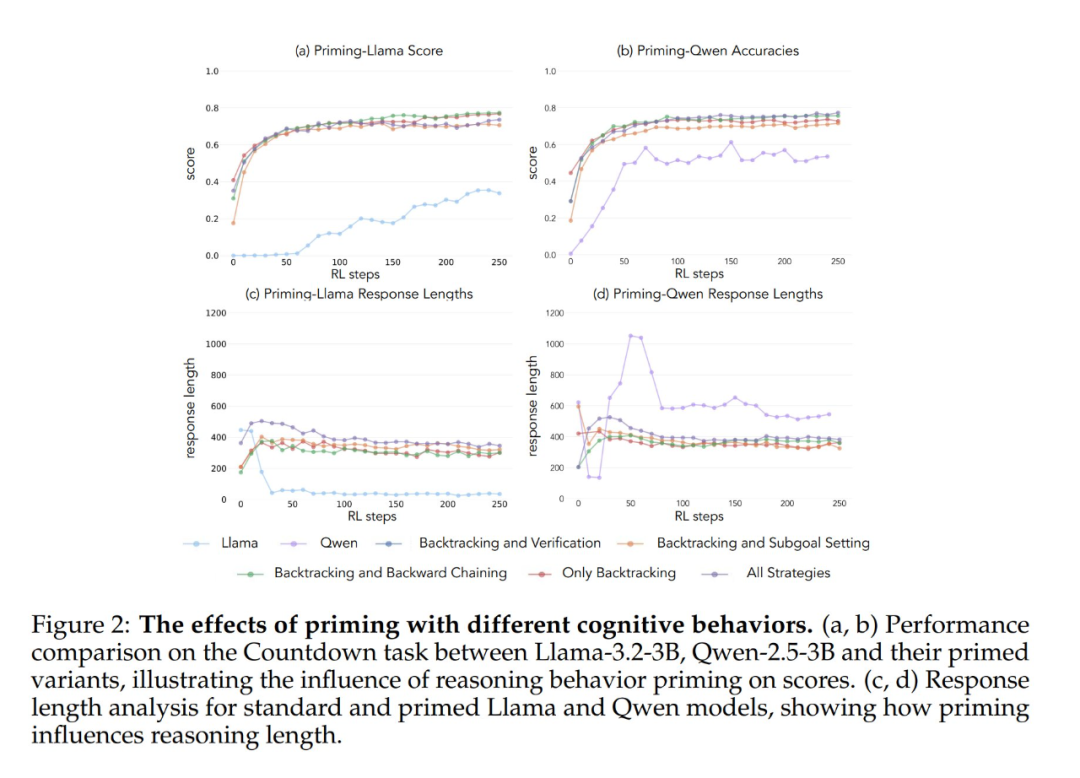
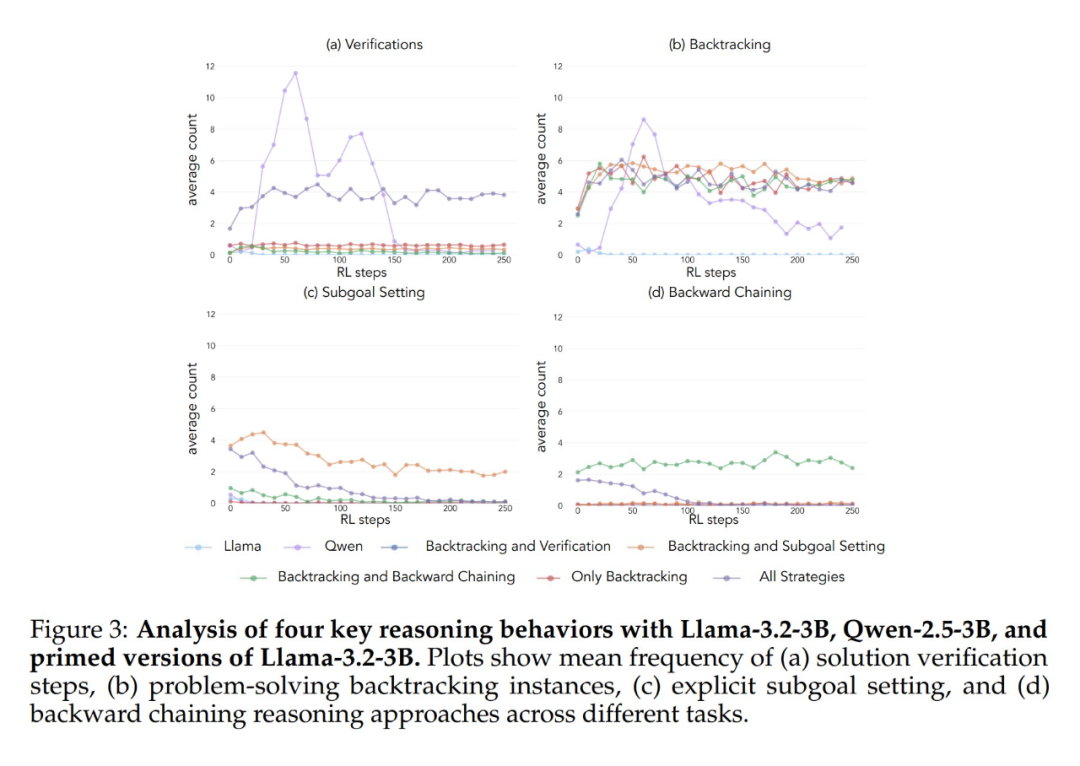
Quando iniciados usando uma cadeia de pensamento vazia como condição de controle, ambos os modelos tiveram desempenho comparável ao do modelo básico Llama-3 (precisão de aproximadamente 30%-35%). Isso sugere que a simples atribuição de tokens adicionais sem incluir comportamentos cognitivos não é um uso eficiente da computação do tempo de teste. Ainda mais surpreendente é o fato de que o treinamento com cadeias de pensamento vazias teve um efeito prejudicial, pois o modelo Qwen-2.5-3B parou de explorar novos padrões de comportamento. Essa é mais uma evidência de que Esses comportamentos cognitivos são essenciais para que o modelo faça uso eficiente dos recursos computacionais estendidos por meio de sequências de inferência mais longas.
O que é ainda mais surpreendente é que os modelos inicializados com soluções incorretas, mas com comportamento cognitivo correto, alcançaram quase o mesmo nível de desempenho que os modelos treinados em conjuntos de dados com soluções corretas. Esse resultado sugere fortemente que A presença de comportamentos cognitivos (em vez da aquisição de respostas corretas) é um fator essencial para o sucesso do autoaperfeiçoamento por meio da aprendizagem por reforço. Assim, os padrões de raciocínio de modelos relativamente fracos podem orientar efetivamente o processo de aprendizado para criar modelos mais fortes. Isso prova mais uma vez que A presença do comportamento cognitivo é mais importante do que a exatidão do resultado.

Seleção comportamental em dados de pré-treinamento
Os resultados desses experimentos sugerem que determinados comportamentos cognitivos são essenciais para o autoaperfeiçoamento do modelo. No entanto, os métodos usados para induzir comportamentos específicos nos modelos iniciais do estudo anterior eram específicos do domínio e se baseavam em jogos de contagem regressiva. Isso pode afetar negativamente a capacidade de generalização da inferência final. Portanto, é possível aumentar a frequência de comportamentos de inferência benéficos modificando a distribuição dos dados de pré-treinamento do modelo para obter um recurso de autoaperfeiçoamento mais geral?
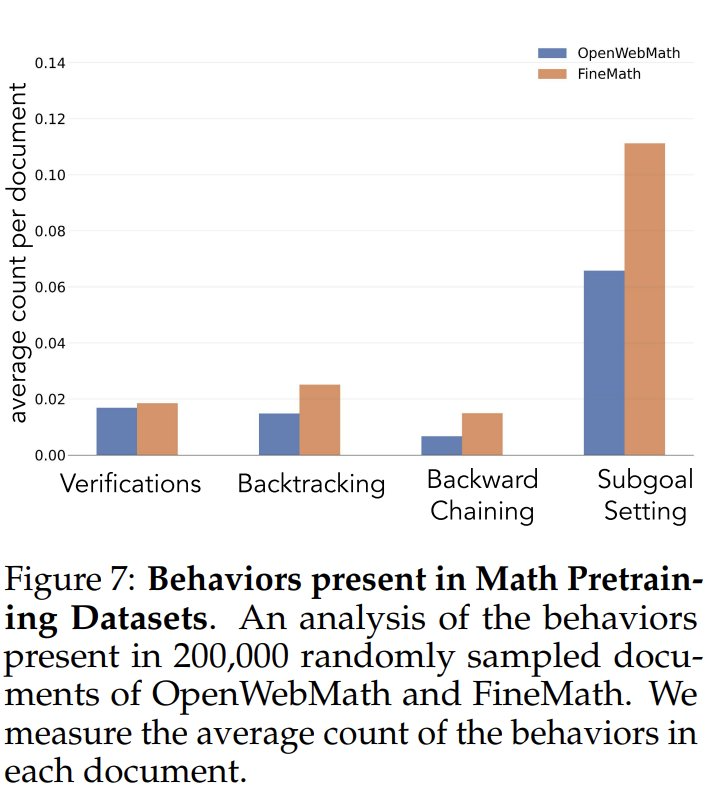
Para investigar a frequência dos comportamentos cognitivos nos dados de pré-treinamento, os pesquisadores analisaram primeiro as frequências naturais dos comportamentos cognitivos nos dados de pré-treinamento. Eles se concentraram nos conjuntos de dados OpenWebMath e FineMath, que foram criados especificamente para o raciocínio matemático. Usando o modelo Qwen-2.5-32B como classificador, os pesquisadores analisaram 200.000 documentos selecionados aleatoriamente desses dois conjuntos de dados para verificar a presença do comportamento cognitivo desejado. Os resultados mostraram que, mesmo nesses corpora com foco matemático, a frequência de comportamentos cognitivos, como retrocesso e validação, permaneceu baixa. Isso sugere que os processos de pré-treinamento padrão têm exposição limitada a esses padrões comportamentais importantes.
Para testar se o aumento artificial da exposição a comportamentos cognitivos aumenta o potencial de autoaperfeiçoamento do modelo, os pesquisadores desenvolveram um conjunto de dados de pré-treinamento contínuo e direcionado a partir do conjunto de dados OpenWebMath. Primeiro, eles usaram o modelo Qwen-2.5-32B como classificador para analisar documentos matemáticos do corpus de pré-treinamento a fim de identificar a presença do comportamento de raciocínio alvo. Com base nisso, eles criaram dois conjuntos de dados de comparação: um rico em comportamentos cognitivos e um conjunto de dados de controle com muito pouco conteúdo cognitivo. Em seguida, eles usaram o modelo Qwen-2.5-32B para reescrever cada documento em ambos os conjuntos de dados em um formato estruturado de perguntas e respostas, preservando a presença ou ausência natural de comportamentos cognitivos nos documentos de origem. Os conjuntos de dados de pré-treinamento resultantes continham, cada um, um total de 8,3 milhões de tokens. Essa abordagem permitiu que os pesquisadores isolassem efetivamente os efeitos do comportamento de raciocínio enquanto controlavam o formato e a quantidade de conteúdo matemático durante o pré-treinamento.
Depois de pré-treinar o modelo Llama-3.2-3B nesses conjuntos de dados e aplicar o aprendizado por reforço, os pesquisadores observaram:
- Os modelos pré-treinados com enriquecimento comportamental acabam atingindo um nível de desempenho comparável ao do modelo Qwen-2.5-3B, com melhoria relativamente limitada no desempenho do modelo de controle.
- A análise comportamental dos modelos pós-treinamento mostrou que a variante do modelo pré-treinado enriquecida comportamentalmente manteve alta ativação do comportamento de inferência durante todo o processo de treinamento, enquanto o modelo de controle exibiu padrões comportamentais semelhantes aos do modelo básico Llama-3.
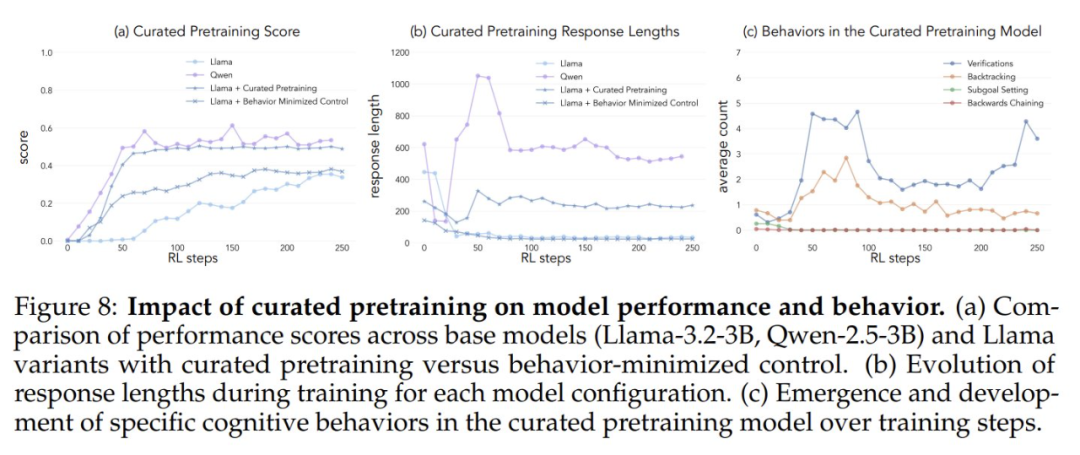
Os resultados desses experimentos sugerem fortemente que A modificação direcionada dos dados de pré-treinamento pode gerar com sucesso os principais comportamentos cognitivos necessários para o autoaperfeiçoamento eficaz por meio do aprendizado por reforço. Este estudo fornece novas ideias e métodos para compreender e aprimorar os recursos de autoaperfeiçoamento de grandes modelos de linguagem. Para obter mais detalhes, consulte o artigo original.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...