
Por quanto tempo um modelo grande consegue entender um vídeo? Smart Spectrum GLM-4V-Plus: 2 horas


Com base nas duas gerações anteriores de modelos de vídeo (CogVLM2-Video e GLM-4V-PLUS), otimizamos ainda mais as técnicas de compreensão de vídeo com o lançamento da versão beta do GLM-4V-Plus-0111. Essa versão introduz técnicas como a resolução variável nativa, que melhora a capacidade do modelo de se adaptar a diferentes comprimentos e resoluções de vídeo.
- Compreensão mais detalhada de vídeos curtos: para conteúdo com vídeos de curta duração, o modelo oferece suporte a vídeos nativos de alta resolução para garantir a captura precisa de informações detalhadas.
- Melhor compreensão de vídeos longos: diante de vídeos de até 2 horas de duração, o modelo pode se ajustar automaticamente a uma resolução menor, equilibrando de forma eficaz a captura de informações temporais e espaciais para obter uma compreensão aprofundada de vídeos longos.
Com essa atualização, a versão beta do GLM-4V-Plus-0111 não apenas mantém as vantagens das duas gerações anteriores de modelos em termos de Q&A temporal, mas também alcança melhorias significativas na duração do vídeo e na adaptabilidade da resolução.
I. Comparação de desempenho
No artigo recém-lançado Smart Spectrum Realtime, 4V, Air New Model Released, Synchronised with New API, detalhamos os resultados da análise do modelo GLM-4V-Plus-0111 (beta) no domínio da compreensão de imagens. O modelo atingiu o nível sota em várias listas de avaliação pública.
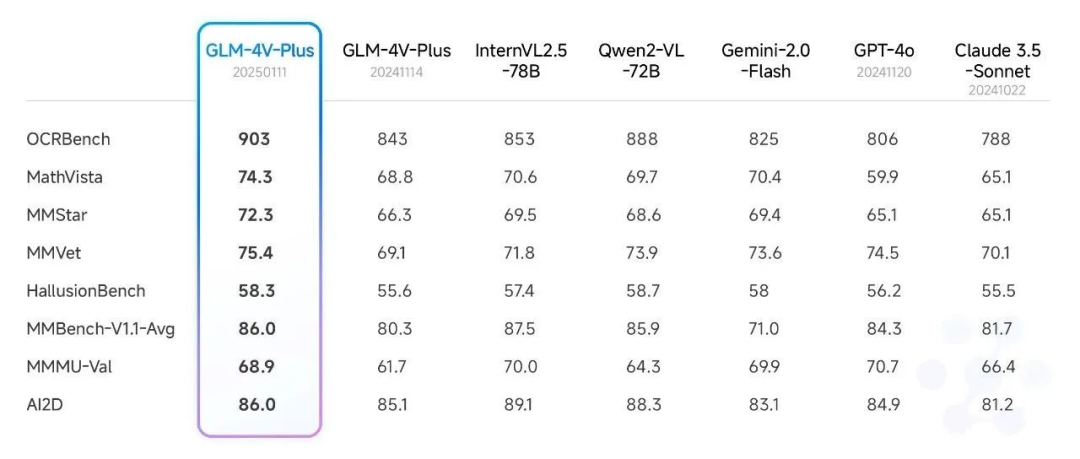
Além disso, também realizamos um teste abrangente em relação a um conjunto de análises de compreensão de vídeo autorizado e também alcançamos um nível relativamente alto. Em particular, o modelo beta GLM-4V-Plus-0111 supera significativamente os modelos comparáveis de compreensão de vídeo em termos de compreensão de ações refinadas em vídeo e compreensão de vídeos longos.
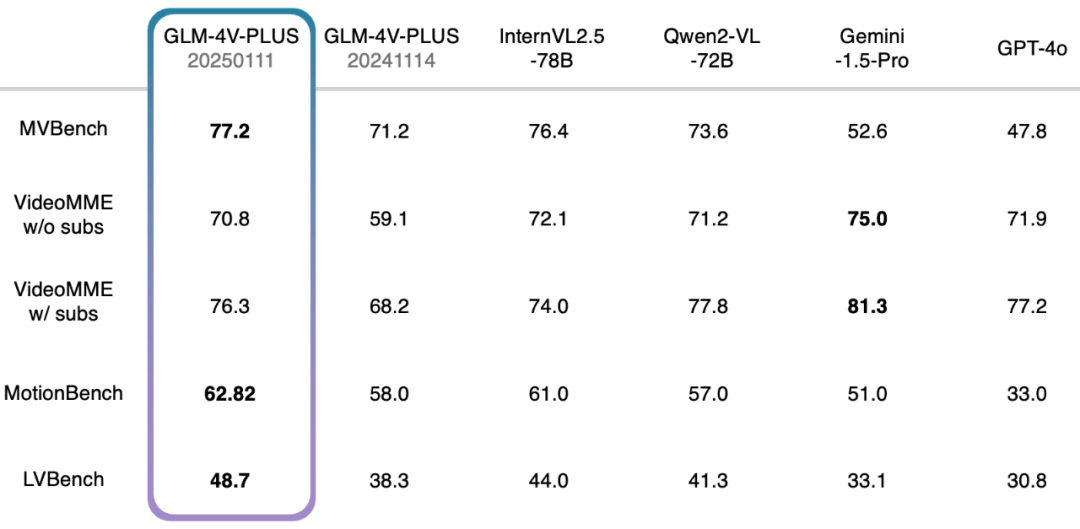
- MVBench: esse conjunto de análise consiste em 20 tarefas complexas de vídeo criadas para avaliar de forma abrangente os recursos combinados de macromodelos multimodais na compreensão de vídeos.
- VideoMME sem legendas: como referência de avaliação multimodal, o VideoMME é usado para avaliar os recursos de análise de vídeo de grandes modelos de linguagem. Nesse caso, a versão sem legendas indica uma entrada multimodal sem legendas, com foco na análise do próprio vídeo.
- VideoMME w/ subs: semelhante à versão w/o subs, mas com a adição de legendas como entradas multimodais para fornecer uma avaliação mais abrangente do desempenho geral do modelo ao lidar com dados multimodais.
- MotionBench: com foco na compreensão refinada do movimento, o MotionBench é um conjunto de dados de referência abrangente que contém diversos dados de vídeo e anotações humanas de alta qualidade para avaliar os recursos dos modelos de compreensão de vídeo para análise de movimento.
- LVBench: com o objetivo de avaliar a capacidade do modelo de entender vídeos longos, o LVBench desafia o desempenho de modelos multimodais ao lidar com tarefas de vídeos longos e verifica a estabilidade e a precisão dos modelos na análise de séries temporais longas.
II. Aplicação do cenário
No ano passado, as áreas de aplicação dos modelos de compreensão de vídeo se expandiram, oferecendo diversos recursos, como geração de descrição de vídeo, segmentação de eventos, classificação, rotulagem e análise de eventos para novas mídias, publicidade, revisão de segurança, fabricação industrial e outros setores. Nosso recém-lançado modelo de compreensão de vídeo beta GLM-4V-Plus-0111 herda e fortalece essas funções básicas e aprimora ainda mais os recursos de processamento e análise de dados de vídeo.
Capacidade de descrição de vídeo mais precisa: com base em entradas de resolução nativa e otimização contínua do phantom do volante de dados, o novo modelo reduz significativamente a taxa de phantom na geração de descrição de vídeo e obtém uma descrição mais abrangente do conteúdo de vídeo, fornecendo aos usuários informações de vídeo mais precisas e ricas.


Processamento eficiente de dados de vídeo: o novo modelo não só tem a capacidade de fornecer descrições detalhadas de vídeos, mas também pode concluir com eficiência as tarefas de classificação, geração de títulos e rotulagem de vídeos. Os usuários podem melhorar ainda mais a eficiência do processamento personalizando os prompts ou criando processos automatizados de dados de vídeo para o gerenciamento inteligente.

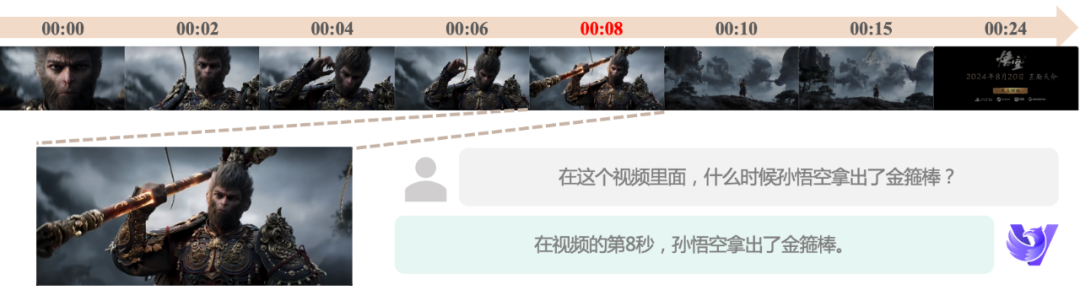
Consciência precisa do tempo: em resposta à natureza dimensional do tempo dos dados de vídeo, nosso modelo tem se dedicado a aprimorar os recursos de questionamento de tempo desde sua primeira geração. Agora, o novo modelo pode localizar com mais precisão os pontos de tempo de eventos específicos, permitir a segmentação semântica e a edição automatizada de vídeos, além de oferecer suporte avançado para edição e análise de vídeos.
Capacidade de compreensão de movimentos finos: o novo modelo oferece suporte a entradas com taxa de quadros mais alta, que podem capturar pequenas alterações de movimento e obter uma compreensão de movimentos mais refinada, mesmo quando a taxa de quadros do vídeo é baixa, fornecendo uma garantia sólida para cenários de aplicativos que exigem uma análise de movimentos precisa.


Compreensão de vídeo ultralonga: por meio da inovadora tecnologia de resolução variável, o novo modelo supera as limitações do tempo de processamento de vídeo e suporta até 2 horas de compreensão de vídeo, o que amplia significativamente os cenários de aplicação comercial do modelo de compreensão de vídeo:

Capacidade de videochamada em tempo real: com base em um modelo avançado de compreensão de vídeo, desenvolvemos um modelo de videochamada em tempo real, o GLM-Realtime, com capacidade de compreensão de vídeo e perguntas e respostas em tempo real e memória de chamada de até 2 minutos. O modelo já está on-linePlataforma aberta de IA Smart SpectrumO GLM-Realtime não apenas ajuda os clientes a criar inteligências de chamadas de vídeo, mas também se combina com o hardware em rede existente para criar facilmente produtos inovadores, como casas inteligentes, brinquedos com IA, óculos com IA e muito mais.
Atualmente, os usuários comuns também podem ter a experiência de fazer chamadas de vídeo com IA no aplicativo Smart Spectrum Clear Speech.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...