01.contextos
No desenvolvimento do aplicativo RAG, a primeira etapa é dividir o documento em partes, e a divisão eficiente do documento em partes pode melhorar efetivamente a precisão do conteúdo de recuperação subsequente. Como dividir em pedaços de forma eficiente é um tópico de discussão importante. Existem métodos como a divisão em pedaços de tamanho fixo, a divisão em pedaços de tamanho aleatório, a reamostragem de janela deslizante, a divisão em pedaços recursiva, com base no conteúdo da divisão em pedaços semântica e outros métodos. O Late Chunking proposto por Jina AI lida com o problema de chunking de outra perspectiva, vamos dar uma olhada nele.
02.O que é Late Chunking?
A fragmentação tradicional pode perder as dependências contextuais de longa distância nos documentos ao processar documentos longos, o que é uma grande armadilha para a recuperação e a compreensão de informações. Ou seja, quando as principais informações estão dispersas em vários blocos de texto, o fragmento de texto fragmentado fora de contexto provavelmente perderá seu significado original, resultando em uma recuperação subsequente mais fraca.
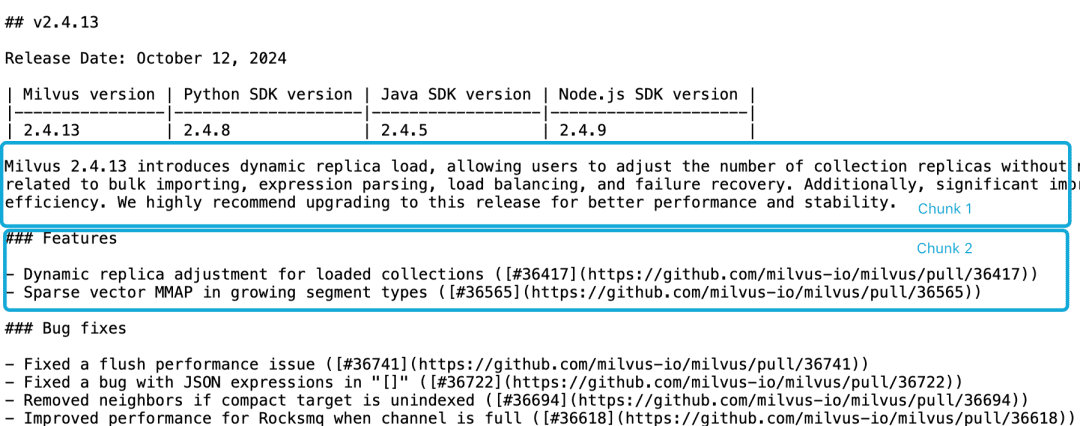
Tomemos como exemplo a nota da versão 2.4.13 do Milvus, se ela estiver dividida em dois blocos de documentos, como segue, e se quisermos consultar oO que há de novo no Milvus 2.4.13?Nesse ponto, é difícil para o modelo de incorporação vincular corretamente essas referências às entidades, o que resulta em uma incorporação de baixa qualidade.
O LLM tem dificuldade em resolver esse problema de correlação devido ao fato de a descrição funcional não estar no mesmo bloco que as informações da versão e à falta de um documento contextual maior. Embora existam várias heurísticas que tentam aliviar esse problema, como reamostragem de janela deslizante, sobreposição de comprimentos de janela de contexto e varreduras de vários documentos, no entanto, como todas as heurísticas, esses métodos são imprevisíveis; eles podem funcionar em alguns casos, mas não há garantias teóricas.
O chunking tradicional usa uma estratégia de pré-chunking, ou seja, primeiro o chunking e depois o modelo de incorporação. O texto é primeiro cortado com base em parâmetros como frase, parágrafo ou comprimento máximo predefinido. Em seguida, o modelo de incorporação processa esses pedaços um a um, por meio de métodos como pooling médio, o token Late Chunking é o processo de primeiro passar pelo modelo de incorporação e depois dividi-lo em pedaços (esse é o significado de late). Late Chunking, por outro lado, é passar pelo modelo Embedding antes de fazer o chunking (é aí que entra o significado de late, primeiro a vetorização e depois o chunking), primeiro pegamos o modelo Embedding transformador A camada é aplicada a todo o texto, gerando uma sequência de representações vetoriais para cada token que contém informações contextuais detalhadas. Em seguida, essas sequências de vetores de tokens são agrupadas uniformemente para obter o bloco final de incorporação que considera todo o contexto do texto.
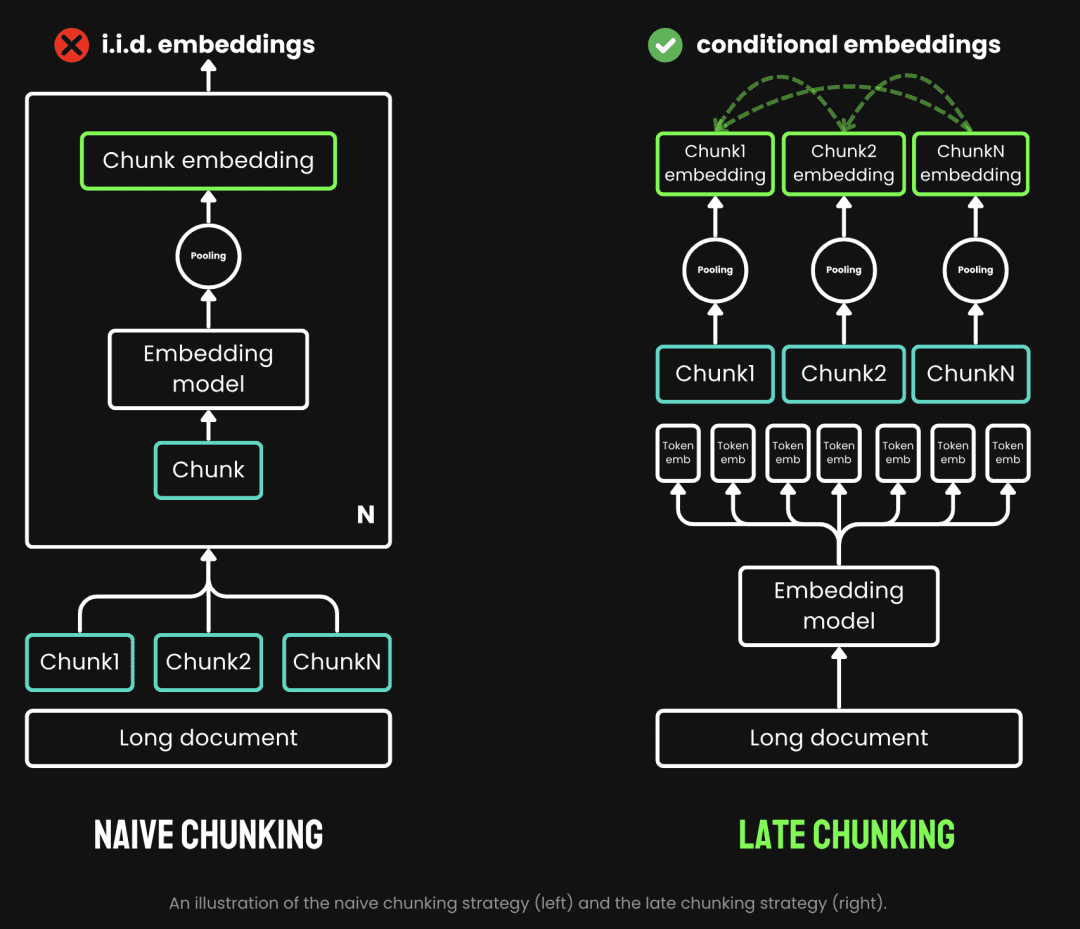
(Fonte da imagem: https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
O Late Chunking gera a incorporação de blocos em que cada bloco codifica mais informações contextuais, melhorando assim a qualidade e a precisão da codificação. Podemos oferecer suporte a modelos de Embedding de contexto longo, oferecendo suporte a contextos longos, como jina-embeddings-v2-base-ptEle pode processar até 8192 tokens de texto (equivalente a 10 páginas de papel A4), o que basicamente atende aos requisitos contextuais da maioria dos textos longos.
Em resumo, podemos ver as vantagens do Late Chunking em aplicativos RAG:
- Maior precisão: ao preservar as informações contextuais, o Late Chunking retorna conteúdo mais relevante para as consultas do que o simples chunking.
- Chamadas eficientes ao LLM: o Late Chunking reduz a quantidade de texto passada ao LLM porque retorna menos pedaços e mais relevantes.
03.Testando o Late Chunking
3.1 Implementação básica do Late Chunking
A função sentence_chunker do documento original para a fragmentação de parágrafos retorna o conteúdo da fragmentação e as informações de marcação da fragmentação span_annotations (ou seja, o início e o fim da marcação da fragmentação)
def sentence_chunker(document, batch_size=10000).
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
para i, enviado em enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
A função document_to_token_embeddings passa o modelo jinaai/jina-embeddings-v2-base-pt bem como o tokenizador, que retorna o Embedding de todo o documento.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096).
tokenised_document = tokenizer(document, return_tensors="pt")
tokens = tokenised_document.tokens()
outputs = []
for i in range(0, len(tokens), batch_size):
start = i
end = min(i + batch_size, len(tokens))
batch_inputs = {k: v[:, start:end] for k, v in tokenised_document.items()}
com torch.no_grad().
model_output = model(**batch_inputs)
outputs.append(model_output.last_hidden_state)
model_output = torch.cat(outputs, dim=1)
return model_output
A função late_chunking fragmenta o Embedding de todo o documento, bem como as informações de marcação span_annotations dos blocos originais.
def late_chunking(token_embeddings, span_annotation, max_length=None).
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation): if (
se (
max_length is not None
): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None): if (
anotações = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start = 1: pooled_embeddings.apps = [] for start, end in annotations.
pooled_embeddings.append(
embeddings[start:end].sum(dim=0) / (end - start)
)
agrupamentos_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputs
Se um modelo for usadojinaai/jina-embeddings-v2-base-ptExecutar Late Chunking
tokeniser = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# Primeiro, divida o texto em pedaços como de costume para obter os pontos de início e fim dos pedaços.
chunks, span_annotations = sentence_chunker(document)
# Em seguida, incorpore o documento completo.
token_embeddings = document_to_token_embeddings(model, tokeniser, document)
# Em seguida, execute o chunking tardio
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2 Comparação com os métodos tradicionais de incorporação
Vamos usar a nota de versão 2.4.13 do milvus como exemplo.
O Milvus 2.4.13 apresenta o carregamento dinâmico de réplicas, permitindo que os usuários ajustem o número de réplicas da coleção sem precisar liberar e recarregar a coleção.
Essa versão também soluciona vários bugs críticos relacionados à importação em massa, análise de expressões, balanceamento de carga e recuperação de falhas.
Além disso, foram feitos aprimoramentos significativos no uso de recursos MMAP e no desempenho de importação, aumentando a eficiência geral do sistema.
É altamente recomendável fazer upgrade para essa versão para obter melhor desempenho e estabilidade.
A incorporação tradicional, ou seja, chunking seguido de incorporação, e a incorporação com abordagem Late Chunking, ou seja, incorporação seguida de chunking, são realizadas respectivamente. Em seguida, o milvus 2.4.13 Compare os resultados com essas duas abordagens de incorporação, respectivamente
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):: print(f'similarity_late(x))
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
A partir dos resultados, as palavras milvus 2.4.13 A semelhança dos resultados do Late Chunking com documentos fragmentados é maior do que a do Embedding tradicional, porque o Late Chunking primeiro executa o Embedding para toda a passagem do texto, de modo que toda a passagem do texto seja milvus 2.4.13 o que, por sua vez, melhora significativamente a similaridade nas comparações de texto subsequentes.
similarity_late_chunking("milvus 2.4.13", "O Milvus 2.4.13 apresenta o carregamento dinâmico de réplicas, permitindo que os usuários ajustem o número de réplicas da coleção réplicas da coleção sem a necessidade de liberar e recarregar a coleção.")
atraso: 0,8785206
similarity_traditional("milvus 2.4.13", "O Milvus 2.4.13 introduz a carga de réplica dinâmica, permitindo que os usuários ajustem o número de réplicas da coleção sem precisar liberar e recarregar a coleção.") late_chunking: 0.8785206 sem a necessidade de liberar e recarregar a coleção.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "Essa versão também soluciona vários bugs críticos relacionados à importação em massa, análise de expressões, balanceamento de carga e recuperação de falhas. balanceamento de carga e recuperação de falhas.")
late_chunking: 0,84828955
similarity_traditional("milvus 2.4.13", "Esta versão também aborda vários bugs críticos relacionados à importação em massa, análise de expressões, balanceamento de carga e recuperação de falhas.") late_chunking: 0.84828955 balanceamento de carga e recuperação de falhas.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Além disso, foram feitas melhorias significativas no uso de recursos MMAP e no desempenho de importação, aumentando a eficiência geral do sistema."). melhorando a eficiência geral do sistema.")
late_chunking: 0,84942204
similarity_traditional("milvus 2.4.13", "Além disso, foram feitas melhorias significativas no uso de recursos MMAP e no desempenho de importação, aumentando a eficiência geral do sistema.") late_chunking: 0.84942204 aprimorando a eficiência geral do sistema.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "É altamente recomendável atualizar para esta versão para obter melhor desempenho e estabilidade.")
late_chunking: 0,85431844
similarity_traditional("milvus 2.4.13", "É altamente recomendável atualizar para esta versão para obter melhor desempenho e estabilidade.")
traditional_chunking: 0.71859795
3.3 Teste de chunking tardio no Milvus
Importação de dados de chunking tardio para o Milvus
dados_de_lote=[]
for i in range(len(chunks)):
data = {
"content" (conteúdo): chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection, data=batch_data, batch_data, batch_data.append(data)
data=batch_data, )
)
Teste de consulta
Definimos o método de consulta de similaridade de cosseno, bem como o uso do método de consulta nativo Milvus para Late Chunking, respectivamente.
def late_chunking_query_by_milvus(query, top_k = 3).
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
nome_da_coleção=coleção,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3).
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
A partir dos resultados, os dois métodos retornam o mesmo conteúdo, o que indica que os resultados da consulta sobre Late Chunking em Milvus são precisos.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn##### Featuresnn- Ajuste dinâmico de réplica para coleções carregadas ([#36417](https://github.com/milvus-io/milvus/pull/ 36417))n- MMAP de vetor esparso em tipos de segmentos crescentes ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn##### Featuresnn- Ajuste dinâmico de réplica para coleções carregadas ([#36417](https://github.com/milvus-io/milvus/pull/ 36417))n- MMAP de vetor esparso em tipos de segmentos crescentes ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.resumos
Apresentamos os antecedentes, os conceitos básicos e a implementação subjacente do Late Chunking conforme ele surgiu e, em seguida, descobrimos que o Late Chunking funciona bem ao testá-lo no Mivlus. De modo geral, a combinação de precisão, eficiência e facilidade de implementação torna o Late Chunking uma abordagem eficaz para aplicativos RAG.
Referência.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
Código de amostra:
Link: https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 Código de extração: 1234 O código é executado na máquina aws g4dn.xlarge