Leitura rápida do artigo
Este artigo oferece uma visão abrangente e aprofundada do passado e do presente da Lei de Escalonamento de Modelos de Linguagem Grandes (LLMs) e a direção futura da pesquisa em IA. Com uma lógica clara e muitos exemplos, o autor Cameron R. Wolfe leva os leitores dos conceitos básicos à pesquisa de ponta, apresentando uma visão ampla do campo da IA. A seguir, apresentamos um resumo e um comentário sobre o conteúdo principal do artigo e os pontos de vista do autor:
1. origens e desenvolvimento da lei de escala: de GPT a Chinchilla
- Os autores começam afirmando que a lei da escala é o principal impulsionador do desenvolvimento de grandes modelos de linguagem. Ao introduzir o conceito básico da Lei da Potência, os autores explicam como a perda de teste de um modelo de linguagem grande diminui à medida que os parâmetros do modelo, o tamanho do conjunto de dados e o esforço computacional aumentam.
- Os autores dão uma olhada na evolução da família de modelos GPT e demonstram de forma vívida a aplicação das leis de escala na prática. Desde os primeiros GPT e GPT-2, passando pelo marcante GPT-3, até o misterioso GPT-4, a OpenAI sempre aderiu à estratégia de "fazer milagres com grandes esforços" e constantemente atualizou o limite superior dos recursos dos modelos de linguagem grandes. O artigo descreve detalhadamente as principais inovações, as configurações experimentais e o desempenho de cada modelo, e destaca que o surgimento do GPT-3 marca a transição de um modelo especializado para um modelo básico de uso geral do modelo de linguagem grande e abre uma nova era de pesquisa em IA.
- Os autores não defendem cegamente que "maior é melhor", mas analisam racionalmente a lei do tamanho "computacionalmente ideal" proposta pelo modelo Chinchilla. A pesquisa da DeepMind mostrou que os modelos anteriores eram geralmente "subtreinados", ou seja, o tamanho do conjunto de dados era muito pequeno em relação ao tamanho do modelo, e o sucesso do modelo de Chinchilla demonstrou que aumentar o tamanho do conjunto de dados adequadamente pode ser mais eficaz do que aumentar o tamanho do modelo para o mesmo orçamento computacional. Essa descoberta teve um impacto profundo no treinamento de modelos de linguagem grandes subsequentes.
Comentário: Os autores fornecem uma introdução aprofundada à Lei da Escala, com explicações teóricas e exemplos de apoio, para que até mesmo leitores não especializados possam entender suas ideias centrais. Ao analisar a evolução da série de modelos GPT, os autores vinculam a lei abstrata da escala ao desenvolvimento de modelos concretos, o que melhora a legibilidade e a persuasão do artigo. A análise do modelo Chinchilla demonstra o espírito discursivo do autor, que não está defendendo cegamente a escala, mas orientando os leitores a pensar sobre como fazer uso mais eficiente dos recursos de computação.
2. o "fim" da lei do tamanho: perguntas e reflexões
- A segunda parte do artigo enfoca o recente questionamento da lei de escala na IA. Os autores citam várias reportagens da mídia que sugerem que o setor está começando a se perguntar se a lei da escala atingiu seu teto à medida que a taxa de melhoria do modelo diminui. Ao mesmo tempo, os autores citam pessoas do setor, como Dario Amodei e Sam Altman, que argumentam o contrário, sugerindo que a escala ainda é uma força importante que impulsiona o progresso da IA.
- Os autores observam que a "desaceleração" na lei de escala era, até certo ponto, esperada. A própria lei da escala prevê que, à medida que a escala aumenta, a dificuldade de melhorar o desempenho aumenta exponencialmente. Além disso, os autores enfatizam a importância de definir "desempenho". Uma diminuição na perda de testes não equivale necessariamente a um aumento nos recursos do Modelo do Big Language, e as expectativas do setor em relação ao Modelo do Big Language variam muito.
- Os "gargalos de dados" são um dos problemas nos quais os autores se concentram. O modelo Chinchilla e os estudos subsequentes enfatizaram a importância do tamanho dos dados, mas a disponibilidade limitada de dados de alta qualidade na Internet pode funcionar como um gargalo para o desenvolvimento futuro de modelos de grandes idiomas.
Comentário: Essa seção demonstra o pensamento crítico do autor e sua visão aguçada do setor. Em vez de evitar a controvérsia, os autores apresentam objetivamente os pontos de vista de várias partes e analisam os possíveis motivos da "desaceleração em escala" do ponto de vista técnico. A ênfase do autor nos "gargalos de dados" é particularmente importante, não apenas como um desafio real para o desenvolvimento de grandes modelos de linguagem, mas também como uma direção para pesquisas futuras.
3. o futuro da pesquisa em IA: além do pré-treinamento
- A parte final do artigo analisa as direções futuras da pesquisa em IA, com foco em modelos de linguagem grandes, sistema/agente e modelos de inferência.
- Os autores argumentam que, mesmo que o crescimento do tamanho dos modelos pré-treinados atinja um gargalo, ainda podemos melhorar os recursos de IA criando sistemas complexos de modelos de linguagem grandes. O artigo descreve as duas principais estratégias de decomposição e vinculação de tarefas e usa resumos de livros como um exemplo de como tarefas complexas podem ser divididas em subtarefas com as quais os modelos de linguagem de grande porte são excelentes.
- Os autores também discutem as perspectivas de aplicação de modelos de Big Language no desenvolvimento de produtos, destacando que a criação de produtos de modelos de Big Language realmente úteis é uma direção importante para a pesquisa atual em IA. Em particular, o artigo destaca o conceito de Agente, que amplia os cenários de aplicação de modelos de linguagem de grande porte, dando-lhes a capacidade de usar ferramentas. No entanto, os autores também apontam os desafios de robustez da criação de sistemas complexos de modelagem de linguagem de grande porte e apresentam direções de pesquisa para melhorar a confiabilidade do sistema por meio de algoritmos de meta-geração aprimorados.
- Em termos de modelos de inferência, os autores apresentam os modelos o1 e o3 da OpenAI, que obtiveram resultados impressionantes em tarefas de inferência complexas. O o3, em particular, superou os níveis humanos em vários benchmarks desafiadores e até mesmo quebrou as previsões de Terence Tao para alguns problemas. Os autores destacam que o sucesso dos modelos o1 e o3 mostra que, além de aumentar a escala do pré-treinamento, a inferência de modelos pode ser significativamente aprimorada com o aumento das entradas computacionais no momento da inferência, um novo paradigma de escala.
Comentário: Esta seção é muito voltada para o futuro, e a introdução dos autores aos sistemas/agentes de modelagem de Big Language e aos modelos de inferência abre novos horizontes para os leitores. A ênfase dos autores na criação de produtos de Big Language Model é de grande importância prática, não apenas para a pesquisa acadêmica, mas também para a aplicação da tecnologia de IA na prática. A introdução dos modelos o1 e o3 é encorajadora, pois mostra o grande potencial da IA para tarefas de raciocínio complexas e indica novas direções para futuras pesquisas de IA.
Faça um resumo e reflita:
O artigo de Cameron R. Wolfe é um excelente trabalho que combina amplitude e profundidade, não apenas fornecendo uma visão geral sistemática do desenvolvimento da Lei de Escala para Modelos de Linguagem de Grande Porte, mas também uma perspectiva perspicaz sobre o futuro da pesquisa em IA. O ponto de vista do autor é objetivo e racional, afirmando a importante função da lei de escala, mas também apontando suas limitações e desafios. A lógica do artigo é clara e bem argumentada, de modo que mesmo os leitores que não estão familiarizados com o campo da IA podem se beneficiar dele.
Destaques notáveis:
- Uma explicação detalhada: O autor tem um talento especial para explicar conceitos complexos em uma linguagem fácil de entender, como a introdução de leis de potência, leis de escala e decomposição de tarefas.
- Com o apoio de exemplos ricos: O artigo lista um grande número de modelos e resultados experimentais, como a série GPT, Chinchilla, Gopher, o1, o3, etc., para tornar as teorias abstratas tangíveis e relacionáveis.
- Uma análise abrangente da literatura: O artigo cita um grande número de referências que abrangem trabalhos clássicos e resultados de pesquisas recentes no campo da modelagem de linguagem ampla, fornecendo aos leitores recursos para um estudo aprofundado.
- Pensamento de mente aberta: Os autores não dão uma resposta final sobre o futuro da lei da escala, mas levam o leitor a pensar de forma independente, como, por exemplo, "O que faremos em seguida?" Essa pergunta inspirará mais pesquisadores a explorar as fronteiras da IA.
Este é um artigo que merece ser lido com atenção por todos aqueles que acompanham o desenvolvimento da IA. Ele não apenas resume o passado, mas também esclarece o futuro. O valor do artigo não está apenas em seu conteúdo em si, mas também em seu espírito de estimular o pensamento e liderar a inovação. Acredito que, nas futuras pesquisas de IA, veremos mais avanços como o o3, e as ideias em escala continuarão a impulsionar o progresso da tecnologia de IA em novas formas.
Título:Leis de escala para modelos de idiomas grandes: do GPT-3 ao o3.
Texto original:https://cameronrwolfe.substack.com/p/llm-scaling-laws
Saiba mais sobre o estado atual da modelagem de grandes linguagens em escala e o futuro da pesquisa de IA...

(Fontes [1, 7, 10, 21])
Avanços mais recentes na pesquisa de IA -Em particular, o Modelo de Linguagem Grande (LLM)- Tudo isso é impulsionado pela escala. Se treinarmos modelos maiores com mais dados, obteremos melhores resultados. Essa relação pode ser definida com mais rigor pela lei da escala, que é uma equação que descreve como a perda de teste de um modelo de linguagem grande diminui à medida que aumentamos alguma quantidade relevante (por exemplo, a quantidade de computação de treinamento). A lei do tamanho nos ajuda a prever os resultados de execuções de treinamento maiores e mais caras, o que nos dá a confiança necessária para continuar investindo em escalonamento.
"Se você tiver um grande conjunto de dados e treinar uma rede neural muito grande, o sucesso é garantido!" - Ilya Sutskever
Durante anos, a lei da escala tem sido uma estrela-guia previsível para a pesquisa de IA. De fato, o sucesso dos primeiros laboratórios de fronteira, como o OpenAI, foi até atribuído à sua adesão à lei da escala. No entanto, a persistência da escala foi recentemente questionada por1 relatos de que os principais laboratórios de pesquisa estão trabalhando para criar a próxima geração de modelos melhores de grandes linguagens. Essas afirmações podem nos deixar céticos:Haverá um gargalo em escala? Em caso afirmativo, há outras maneiras de avançar?
Esta visão geral responderá a essas perguntas desde o início, começando com uma explicação detalhada das Leis de Escala do Modelo de Linguagem Grande e das pesquisas relacionadas. O conceito da Lei da Escala é simples, mas há todo tipo de equívoco público em relação à escala - aA ciência por trás desse estudo é, na verdade, muito específicaA Lei da Escala. Usando essa compreensão detalhada da escala, discutiremos as últimas tendências na pesquisa de modelagem de Big Language e os fatores que fizeram com que a lei da escala "parasse". Por fim, usaremos essas informações para fornecer uma visão mais clara do futuro da pesquisa em IA, concentrando-nos em algumas ideias principaisIncluindo escala--Essas ideias podem continuar a impulsionar o progresso.
Conceitos básicos de dimensionamento para modelos de linguagem grandes
Para entender o estado de escala de modelos de linguagem grandes, primeiro precisamos estabelecer um entendimento geral das leis de escala. Vamos construir esse entendimento do zero, começando com o conceito de leis de potência. Em seguida, exploraremos como as leis de potência foram aplicadas no estudo de modelos de linguagem grandes para derivar as leis de escala que usamos atualmente.
O que é uma lei de potência?
As leis de potência são um conceito fundamental no dimensionamento de modelos de linguagem grandes. Em resumo, uma lei de potência simplesmente descreve a relação entre duas quantidades. No caso de um modelo de linguagem grande, a primeira quantidade é a perda de teste do modelo de linguagem grande-ou outras métricas de desempenho relevantes (por exemplo, precisão da tarefa downstream [7])- A outra é que estamos tentando dimensionar determinadas configurações, como o número de parâmetros do modelo. Por exemplo, ao investigar as propriedades de escala de um modelo de linguagem grande, podemos ver a seguinte declaração.
"Se houver dados de treinamento suficientes, o dimensionamento da perda de validação deverá ser uma função de lei de potência suave aproximada do tamanho do modelo." - Fonte [4]
Essa afirmação nos diz que há uma relação mensurável entre a perda de teste do modelo e o número total de parâmetros do modelo. Uma alteração em uma dessas quantidades resultará em uma alteração invariável na escala relativa da outra. Em outras palavras, sabemos por essa relação que o aumento do número total de parâmetros do modelo - oSupondo que outras condições sejam atendidas (por exemplo, disponibilidade de dados de treinamento suficientes)--resultará em uma redução nas perdas de teste por um fator previsível.
Fórmula de lei de potência. A lei de potência básica é expressa pela seguinte equação.

As duas quantidades estudadas aqui são x responder cantando ymas (não) a responder cantando p é uma constante que descreve a relação entre essas quantidades. Se traçarmos essa função de lei de potência2 , obteremos a figura abaixo. Fornecemos gráficos nas escalas normal e logarítmica porque a maioria dos artigos que estudam o dimensionamento de modelos de linguagem grandes usa escalas logarítmicas.

Gráfico da lei de potência fundamental entre x e y
No entanto, os diagramas fornecidos para dimensionar o Big Language Model não se parecem com os diagramas mostrados acima - oGeralmente estão de cabeça para baixo.Veja o exemplo abaixo.

(Fonte [1])

A equação para a lei de potência inversa é quase a mesma que a equação para a lei de potência padrão, mas estamos interessados na p Use expoentes negativos. Se o expoente de uma lei de potência for negativo, o gráfico ficará de cabeça para baixo; veja o exemplo abaixo.

Gráfico da lei de potência inversa entre x e y
Quando plotada usando uma escala logarítmica, essa lei de potência inversa produz a relação linear que caracteriza as leis de tamanho da maioria dos modelos de linguagem grandes. Quase todos os artigos abordados nesta visão geral geram esses gráficos para investigar como o dimensionamento de uma variedade de fatores diferentes (por exemplo, tamanho, computação, dados etc.) afeta o desempenho de um modelo de linguagem grande. Agora, vamos dar uma olhada mais prática nas leis de potência, entendendo um dos primeiros artigos a estudá-las no contexto do dimensionamento de modelos de linguagem grandes [1].
Leis de escala para modelagem neurolinguística [1]
Nos primórdios da modelagem de idiomas, não entendíamos o impacto da escala no desempenho. A modelagem de linguagem era uma área de pesquisa promissora, mas a geração atual de modelos na época (por exemplo, o GPT original) tinha potência limitada. Ainda não havíamos descoberto o poder dos modelos maiores, e o caminho para criar modelos de linguagem melhores não estava claro.A forma do modelo (ou seja, o número de camadas e o tamanho) é importante? Tornar o modelo maior ajuda a melhorar o desempenho? Quantos dados são necessários para treinar esses modelos maiores?
"À medida que o tamanho do modelo, o tamanho do conjunto de dados e a quantidade de computação usada para o treinamento aumentam, a perda é dimensionada como uma lei de potência, com algumas dessas tendências abrangendo mais de sete ordens de magnitude." - Fonte [1]
Em [1], os autores procuraram analisar vários fatores por meio deOs exemplos incluem o tamanho do modelo, a forma do modelo, o tamanho do conjunto de dados, o cálculo do treinamento e o tamanho do lote- no desempenho do modelo para responder a essas perguntas. Com essa análise, aprendemos que o desempenho do modelo de linguagem grande melhora suavemente à medida que aumentamos o número de
- Número de parâmetros do modelo.
- O tamanho do conjunto de dados.
- A quantidade de computação usada para treinamento.
Mais especificamente.Quando o desempenho não é prejudicado pelos outros dois fatores, observa-se uma relação de lei de potência entre cada fator e a perda de teste do modelo de linguagem grande.
Configuração experimental.Para ajustar suas leis de potência, os autores pré-treinaram grandes modelos de linguagem em um subconjunto do corpus WebText2, com um tamanho de até 1,5 bilhão de parâmetros e contendo de 22 a 23 bilhões de tokens. Todos os modelos usam 1.024 Token de comprimento de contexto fixo e perda padrão de previsão do próximo token (entropia cruzada) para treinamento. A mesma perda é medida em um conjunto de teste reservado e usada como nossa principal métrica de desempenho.Essa configuração corresponde às configurações de pré-treinamento padrão para a maioria dos modelos de linguagem grandes..

(Fonte [1])
Modelos de linguagem grande Leis de potência de escala.Desempenho do modelo de linguagem grande treinado em [1] -Em termos de suas perdas em testes no WebText2- O sistema de cálculo de dados da Microsoft - provou melhorar constantemente com mais parâmetros, dados e computação3 . Essas tendências abrangem oito ordens de grandeza em computação, seis ordens de grandeza em tamanho de modelo e duas ordens de grandeza em tamanho de conjunto de dados. As relações exatas da lei de potência e as equações ajustadas a cada relação são fornecidas na figura acima. Cada uma das equações aqui é muito semelhante às equações de lei de potência inversa que vimos anteriormente. Entretanto, definimos a = 1 e acrescente uma constante de multiplicação adicional de 4 dentro dos colchetes.
Os autores em [1] apontam um pequeno detalhe necessário para ajustar corretamente essas leis de potência. Ao calcular o número total de parâmetros do modelo, não incluímos as incorporações de posição ou de token, o que produz tendências de escala mais claras; veja abaixo.

(Fonte [1])
Essas leis de potência só se aplicam quando o treinamento não é prejudicado por outros fatores. Portanto, todos os três componentes - oTamanho do modelo, dados e cálculos-todos devem ser expandidos ao mesmo tempo para obter o desempenho ideal. Se expandirmos qualquer um desses componentes isoladamente, chegaremos a um ponto de retorno decrescente.
O que a lei de potência nos diz?Embora os gráficos de lei de potência fornecidos em [1] pareçam promissores, devemos observar que esses gráficos foram gerados usando a escala logarítmica. Se gerarmos gráficos normais (ou seja, sem escala logarítmica), obteremos a figura a seguir, na qual vemos que a forma da lei de potência se assemelha a um decaimento exponencial.

Gráficos de lei de potência sem escalas logarítmicas
Considerando grande parte do discurso on-line sobre escalonamento e AGI, essa descoberta parece contraintuitiva. Em muitos casos, a intuição que recebemos parece ser a de que a qualidade de grandes modelos de linguagem aumenta exponencialmente com o crescimento logarítmico da computação, mas esse não é o caso. De fato, oO aprimoramento da qualidade de grandes modelos de linguagem torna-se cada vez mais difícil à medida que a escala aumenta.

(Fonte [1])
Outras descobertas úteis.Além da lei de potência observada em [1], vimos que outros fatores considerados, como a forma do modelo ou as configurações arquitetônicas, têm pouco impacto sobre o desempenho do modelo; veja acima. De longe, a escala é o fator que mais contribui para a criação de modelos melhores para linguagens grandes - oMais dados, computação e parâmetros de modelo levam a um aumento suave no desempenho do modelo de linguagem grande.
"Modelos maiores têm eficiências de amostragem significativamente mais altas, de modo que o treinamento computacionalmente eficiente ideal envolve o treinamento de modelos muito grandes em quantidades relativamente modestas de dados e a interrupção significativamente antes da convergência." - Fonte [1]
É interessante notar que as análises empíricas em [1] mostram que modelos de linguagem grandes e maiores tendem a ter maior eficiência de amostragem, o que significa que eles usam menos dados para atingir o mesmo nível de perda de teste em comparação com modelos menores. Por esse motivo, oO pré-treinamento de um modelo de linguagem grande até a convergência é (indiscutivelmente) abaixo do ideal.. Em vez disso, podemos treinar modelos maiores com menos dados e interromper o processo de treinamento antes da convergência. Essa abordagem é ideal em termos do volume de computação de treinamento usado, mas não leva em conta os custos de inferência. Na verdade, geralmente treinamos modelos menores com mais dados porque os modelos menores são mais baratos de hospedar.
Os autores também analisaram extensivamente a relação entre o tamanho do modelo e a quantidade de dados usados para o pré-treinamento e descobriram que o tamanho do conjunto de dados não precisa aumentar tão rapidamente quanto o tamanho do modelo.O aumento no tamanho do modelo em cerca de 8 vezes requer um aumento no volume de dados de treinamento em cerca de 5 vezes para evitar o ajuste excessivo.

(Fonte [1])
"Esses resultados mostram que o desempenho da modelagem de linguagem melhora de forma suave e previsível quando dimensionamos adequadamente o tamanho do modelo, os dados e a computação. Esperamos que modelos de linguagem maiores tenham um desempenho melhor do que os modelos atuais e tenham maior eficiência de amostragem." - Fonte [1]
Aplicação prática da lei do tamanho
O fato de o pré-treinamento em larga escala ser tão benéfico nos coloca diante de um pequeno dilema. Os melhores resultados podem ser obtidos com o treinamento de modelos grandes em grandes quantidades de dados. No entanto, essas execuções de treinamento são muito caras eIsso significa que eles também assumem muitos riscosE se gastarmos US$ 10 milhões para treinar um modelo que não atenda às nossas expectativas? E se gastarmos US$ 10 milhões para treinar um modelo que não atenda às nossas expectativas? Dado o custo do pré-treinamento, não podemos realizar nenhum ajuste específico do modelo e precisamos garantir que os modelos que treinamos tenham um bom desempenho. Precisamos desenvolver uma estratégia para ajustar esses modelos e prever seu desempenho sem gastar muito dinheiro.

(Fonte [11])
- Treine vários modelos menores usando várias configurações de treinamento.
- Ajuste a lei de escala ao desempenho de modelos menores.
- Inferindo o desempenho de modelos maiores usando a lei do tamanho.
É claro que essa abordagem tem suas limitações. A previsão do desempenho de modelos maiores a partir de modelos menores é difícil e pode ser imprecisa. Os modelos podem se comportar de forma diferente dependendo do tamanho. No entanto, vários métodos foram propostos para tornar isso mais viável, e as leis de tamanho agora são comumente usadas para essa finalidade. A capacidade de usar leis de escala para prever o desempenho de modelos maiores nos dá mais confiança (e paz de espírito) como pesquisadores. Além disso, a lei do tamanho oferece uma maneira simples de justificar um investimento em pesquisa de IA.
Aumento de escala e era de pré-treinamento
"É isso que está impulsionando todos os avanços que estamos vendo hoje - mega redes neurais treinadas em enormes conjuntos de dados." - Ilya Sutskever
A descoberta da Lei da Escala catalisou muitos avanços recentes no estudo de modelos de linguagem de grande porte. Para obter melhores resultados, precisamos simplesmente treinar modelos em conjuntos de dados maiores (e melhores!) conjuntos de dados para treinar modelos cada vez maiores. Essa estratégia foi usada para criar vários modelos na família GPT, bem como a maioria dos modelos conhecidos de equipes fora da OpenAI. Aqui, daremos uma olhada mais profunda no progresso dessa pesquisa de dimensionamento - oRecentemente descrita por Ilya Sutskever como "a era do pré-treinamento". 5.
Série GPT: GPT [2], GPT-2 [3], GPT-3 [4] e GPT-4 [5].
Modelos de linguagem grande A aplicação mais conhecida e visível das leis de escala é a criação da família de modelos GPT da OpenAI. Vamos nos concentrar principalmente nos primeiros modelos abertos da série - oAté a GPT-3-Porque:
- Os detalhes desses modelos estão sendo compartilhados de forma mais aberta.
- Modelos posteriores se beneficiaram dos avanços na pesquisa pós-treinamento, além de expandir o processo de pré-treinamento.
Também apresentaremos alguns resultados de escala conhecidos, como os modelos do GPT-4.

(Fonte [2])
- O pré-treinamento autossupervisionado em texto plano é muito eficaz.
- É importante usar trechos longos e contínuos de texto para o pré-treinamento.
- Quando pré-treinados dessa forma, os modelos individuais podem ser ajustados para resolver uma variedade de tarefas diferentes com precisão de última geração6 .
Em geral, o GPT não é um modelo particularmente digno de nota, mas estabeleceu algumas bases importantes para trabalhos posteriores (ou seja, o Transformer somente para decodificador e o pré-treinamento autossupervisionado) que exploraram modelos semelhantes em uma escala maior.

(Fonte [3])
- Esses modelos são pré-treinados no WebText, que i) é muito maior que o BooksCorpus, e o ii) Criado com a coleta de dados da Internet.
- Esses modelos não são ajustados para tarefas de downstream. Em vez disso, resolvemos a tarefa realizando inferência de amostra zero7 usando modelos pré-treinados.
Os modelos GPT-2 não atingem o desempenho de última geração na maioria dos benchmarks8 , mas seu desempenho melhora consistentemente com o aumento do tamanho do modelo - oA expansão do número de parâmetros do modelo gera benefícios clarosVeja abaixo.

(Fonte [3])
"Os modelos de linguagem com capacidade suficiente começarão a aprender a inferir e executar tarefas demonstradas em sequências de linguagem natural para melhor prevê-las, independentemente de seu método de aquisição." - Fonte [3]
GPT-3 [4] foi um momento decisivo na pesquisa de IA que demonstrou claramente os benefícios do pré-treinamento em larga escala de um modelo de linguagem grande. Com mais de 175 bilhões de parâmetros, esse modelo é mais de 100 vezes maior do que o maior modelo GPT-2; veja abaixo.

(Fonte [4])

(Fonte [4])

(Fonte [4])

(Fonte [4])

(Fonte [4])
Após a GPT-3. O desempenho impressionante do GPT-3 despertou um grande interesse no estudo de modelos de idiomas grandes, concentrando-se principalmente no pré-treinamento em grande escala.InstructGPT [8], ChatGPT e GPT-4 [5]--O uso de uma combinação de pré-treinamento em larga escala e de novas técnicas de pós-treinamento (ou seja, ajuste fino supervisionado e aprendizado por reforço a partir de feedback humano) melhorou consideravelmente a qualidade de modelos de linguagem de grande porte. Esses modelos são tão impressionantes que até provocaram um aumento no interesse público pela pesquisa em IA.
"O GPT-4 é um modelo baseado em Transformer pré-treinado para prever o próximo Token em um documento. O processo de alinhamento pós-treinamento melhora a métrica de fatorialidade e a aderência ao comportamento desejado." - Fonte [5]
Nesse momento, a OpenAI começou a divulgar menos detalhes sobre suas pesquisas. Em vez disso, os novos modelos só eram liberados por meio de sua API, o que impedia o público de entender como esses modelos eram criados. Felizmente, algumas informações úteis podem ser extraídas do material que a OpenAI divulga. Por exemplo, InstructGPT [8]-ChatGPT antecessores-- Há um artigo relacionado que documenta detalhadamente a estratégia pós-treinamento do modelo; veja abaixo. Como esse documento também afirma que o GPT-3 é o modelo básico do InstructGPT, é razoável inferir que o aprimoramento do desempenho do modelo é amplamente independente do processo de pré-treinamento estendido.

(Fonte [8])
- O GPT-4 é baseado no Transformer.
- O modelo é pré-treinado usando a previsão do próximo token.
- Uso de dados públicos e licenciados de terceiros.
- O modelo é ajustado usando o aprendizado por reforço a partir do feedback humano.
No entanto, a importância do dimensionamento é muito evidente nesse relatório técnico. Os autores observam que um dos principais desafios deste trabalho é desenvolver uma arquitetura de treinamento dimensionável que tenha um desempenho previsível em diferentes escalas, permitindo a extrapolação dos resultados de execuções menores e, assim, proporcionando confiança para exercícios de treinamento maiores (e muito mais caros!) com segurança. exercícios de treinamento com confiança.
"A perda final de um modelo de linguagem grande devidamente treinado ...... pode ser aproximada por uma lei de potência da quantidade de computação usada para treinar o modelo." - Fonte [5]
O pré-treinamento em massa é muito caro, portanto, geralmente temos apenas uma chance de acertar.Não há espaço para ajustes específicos do modelo. A lei do tamanho desempenha um papel fundamental nesse processo. Podemos treinar um modelo usando de 1.000 a 10.000 vezes menos cálculos e usar os resultados dessas execuções de treinamento para ajustar as leis de potência. Essas leis de potência podem então ser usadas para prever o desempenho de modelos maiores. Em particular, vimos em [8] que o desempenho do GPT-4 foi previsto usando leis de potência que medem a relação entre computação e perda de teste; veja abaixo.

GPT-4 Fórmula de lei de escala para treinamento (Fonte [5])

(Fonte [5])

(Fonte [5])
Chinchila. Treinamento de modelos de linguagem grandes e computacionalmente ideais [5]

(Fonte [9])

(Fonte [10])

(Fonte [10])
"A quantidade de dados de treinamento que se espera que seja necessária excede em muito a quantidade de dados usados atualmente para treinar modelos grandes." - Fonte [6]
Chinchila.A análise fornecida em [6] destaca a importância do tamanho dos dados.Modelos grandes precisam ser treinados com mais dados para atingir o desempenho idealPara verificar essa descoberta, os autores treinaram um modelo de linguagem grande com 70 bilhões de parâmetros chamado Chinchilla. Para verificar essa descoberta, os autores treinaram um modelo de linguagem grande de 70 bilhões de parâmetros chamado Chinchilla. Em comparação com os modelos anteriores, o Chinchilla é menor, mas tem um conjunto de dados de pré-treinamento maior - o1,4 trilhão de tokens de treinamento no totalO Chinchilla usa os mesmos dados e a mesma estratégia de avaliação do Gopher [10]. Embora quatro vezes menor que o Gopher, o Chinchilla supera consistentemente os modelos maiores; veja abaixo.

(Fonte [6])
O "fim" da lei de escala
A lei da escala tornou-se recentemente um tópico importante (e controverso) na pesquisa de IA. Como vimos nesta visão geral, a escala impulsionou grande parte do aprimoramento da IA durante a era pré-treinamento. No entanto, à medida que o ritmo de lançamentos e aprimoramentos de modelos diminui na segunda metade de 202411 , estamos começando a ver um questionamento generalizado do dimensionamento de modelos, o que parece indicar que a pesquisa de IA - aEm particular, a lei de escala-Pode estar batendo em uma parede.
- A OpenAI está mudando sua estratégia de produto por causa de gargalos no dimensionamento de sua abordagem atual, disse a Reuters.
- As informações dizem que os aprimoramentos do modelo GPT estão começando a desacelerar.
- A Bloomberg destaca as dificuldades enfrentadas por vários laboratórios de ponta na tentativa de desenvolver uma IA mais poderosa.
- O TechCrunch diz que a escala está começando a produzir retornos decrescentes.
- A revista Time publicou um artigo com nuances que destaca os vários fatores que estão causando a desaceleração da pesquisa de IA.
- Ilya Sutskever, no NeurIPS'24, disse que *"o pré-treinamento como o conhecemos acabará "*.
Ao mesmo tempo, muitos especialistas têm uma visão oposta. Por exemplo, (o CEO da Anthropic) declarou que o escalonamento *"pode ...... continuar"E Sam Altman continua pregando.a frase "não há paredes "*. Nesta seção, daremos mais cor a essa discussão fornecendo uma explicação fundamentada sobre o estado atual da escala e os vários problemas que podem existir.
Redução de escala: o que significa? Por que isso está acontecendo?
"Ambas as afirmações são provavelmente verdadeiras: em um nível técnico, o escalonamento ainda funciona. Para os usuários, a taxa de melhoria está diminuindo." - Nathan Lambert
Em seguida, ......O aumento de escala está ficando mais lento? A resposta é complexa e depende muito de nossa definição precisa de "desaceleração". Até o momento, minha resposta mais plausível a essa pergunta é que ambas as respostas estão corretas. Por esse motivo, não tentaremos responder a essa pergunta. Em vez disso, vamos nos aprofundar no que está sendo dito sobre esse tópico para que possamos construir uma compreensão mais matizada do estado atual (e futuro) do dimensionamento de modelos de linguagem grande.
O que a lei da escala nos diz?Primeiro, precisamos revisar a definição técnica da lei do tamanho. A lei do tamanho define a relação entre o cálculo de treinamento (ou tamanho do modelo/conjunto de dados) e a perda de teste de um modelo de linguagem grande de acordo com uma lei de potência. No entanto, aA natureza desse relacionamento é frequentemente mal compreendida. A ideia de obter ganhos de desempenho exponenciais com o crescimento logarítmico da computação é um mito. A lei de escala se parece mais com o decaimento exponencial, o que significa que, com o tempo, teremos que trabalhar mais para obter mais ganhos de desempenho; veja abaixo.

(Fonte [5])
"Os profissionais normalmente usam a precisão do benchmark downstream como um indicador da qualidade do modelo, em vez da perda no conjunto de avaliação de perplexidade." - Fonte [7]
Definir desempenho.Como podemos avaliar se o Big Language Model está melhorando? Do ponto de vista da lei da escala, o desempenho de um modelo de idioma grande geralmente é medido pela perda de teste do modelo durante o pré-treinamento, mas o efeito de uma perda de teste menor na capacidade de um modelo de idioma grande não está claro.As perdas menores levam a uma maior precisão nas tarefas posteriores? Perdas menores levarão a novos recursos para o Big Language Model? Há uma desconexão entre o que a lei de escala nos diz e o que realmente nos importa:
- A lei do tamanho nos diz que o aumento do tamanho do pré-treinamento reduzirá suavemente a perda de teste de modelos de linguagem grandes.
- Nossa preocupação é obter um modelo "melhor" da linguagem mais ampla.
Dependendo de quem você é e do que espera de um novo sistema de IA...e os métodos que você usou para avaliar esses novos sistemas-será muito diferente. Os usuários comuns de IA tendem a se concentrar em aplicativos de bate-papo de uso geral, enquanto os profissionais geralmente se preocupam com o desempenho de grandes modelos de linguagem em tarefas posteriores. Em contrapartida, os pesquisadores dos principais laboratórios de ponta parecem ter grandes (e muito específicas) expectativas em relação aos sistemas de IA; por exemplo, escrever teses de doutorado ou resolver problemas avançados de raciocínio matemático. Dada a ampla gama de recursos que são difíceis de avaliar, há muitas maneiras de analisar o desempenho de modelos de linguagem grandes; veja abaixo.

(Fonte [15])
Desaparecimento de dados.Para escalonar o pré-treinamento de modelos de linguagem grandes, precisamos aumentar o tamanho do modelo e do conjunto de dados. As primeiras pesquisas [1] parecem sugerir que a quantidade de dados é menos importante do que o tamanho do modelo, mas vemos em Chinchilla [6] que o tamanho do conjunto de dados é igualmente importante. Além disso, trabalhos recentes sugerem que a maioria dos pesquisadores prefere "treinar demais" seus modelos.ou pré-treiná-los em conjuntos de dados cujo tamanho exceda a otimização do Chinchilla-para economizar custos de inferência [7].
"Os estudos de aumento de escala geralmente se concentram na computação de mecanismos de treinamento ideais ...... Como os modelos maiores são mais caros para raciocinar, agora é prática comum treinar em excesso os modelos menores." - Fonte [7]
Todos esses estudos nos levam a uma conclusão simples: oA expansão do pré-treinamento de modelos de linguagem grande exigirá a criação de conjuntos de dados de pré-treinamento maioresEsse fato constitui uma das principais críticas à lei de escala de modelos de linguagem grandes. Esse fato constitui uma das principais críticas à lei do tamanho para modelos de linguagem grandes. Muitos pesquisadores argumentaram que talvez não haja dados suficientes para continuar a dimensionar o processo de pré-treinamento. Como pano de fundo, a grande maioria dos dados de pré-treinamento usados para o Big Language Model atual foi obtida por meio de rastreamento da Web; veja abaixo. Como só temos uma Internet, pode ser difícil encontrar fontes totalmente novas de dados de pré-treinamento de alta qualidade e em grande escala.

Até mesmo Ilya Sutskever apresentou recentemente esse argumento, afirmando que i) A computação está crescendo rapidamente, mas ii) Os dados não cresceram devido à dependência do rastreamento da Web. Como resultado, ele argumenta que não podemos continuar a expandir o processo de pré-treinamento para sempre. O pré-treinamento, tal como o conhecemos, chegará ao fim, e precisamos encontrar novas maneiras de fazer a pesquisa de IA progredir. Em outras palavras."Atingimos o pico de dados.".
Escala de pré-treinamento de última geração
O escalonamento acabará levando a retornos decrescentes, e os argumentos centrados nos dados contra o escalonamento contínuo são razoáveis e convincentes. No entanto, ainda há várias direções de pesquisa que poderiam aprimorar o processo de pré-treinamento.

Dados sintéticos.Para ampliar o processo de pré-treinamento em várias ordens de grandeza, talvez seja necessário contar com dados gerados sinteticamente. Apesar das preocupações de que a dependência excessiva de dados sintéticos pode levar a problemas de diversidade [14], estamos vendo modelos de linguagem grandes cada vez mais - e isso é um problema.E parece ter sido bem-sucedido em--usando dados sintéticos [12]. Além disso, o aprendizado de curso [13] e as estratégias de pré-treinamento contínuo levaram a vários aprimoramentos significativos por meio do ajuste dos dados de pré-treinamento; por exemplo, alterando a combinação de dados ou adicionando dados de instrução no final do pré-treinamento.

(Fonte [7])
DeepSeek-v3.Apesar dos debates recentes, continuamos a ver avanços semi-frequentes ao estender o processo de pré-treinamento para modelos de linguagem grandes. Por exemplo, o recente lançamento do DeepSeek-v3 [18], oUm parâmetro de 671 bilhões12 (MoE). Além de ser de código aberto, o modelo foi pré-treinado em 14,8 trilhões de textos Token e superou o desempenho do GPT-4o e do Claude-3.5-Sonnet; veja a figura abaixo para ver o desempenho do modelo e aqui para ver a licença. Para referência, o modelo LLaMA-3 foi treinado em mais de 15 trilhões de dados de texto bruto; consulte aqui para obter mais detalhes.

(Fonte [18])
- Arquitetura MoE otimizada do DeepSeek-v2.
- Uma nova estratégia de perda sem ajuda para o MoE de balanceamento de carga.
- Previsão de objetivos de treinamento com várias palavras.
- Refinamento dos recursos de raciocínio a partir de modelos de cadeia de pensamento longos (ou seja, semelhante ao o1 da OpenAI).
O modelo também foi pós-treinado, incluindo o ajuste fino supervisionado e a aprendizagem por reforço com base no feedback humano para alinhá-lo às preferências humanas.
"Treinamos o DeepSeek-V3 com 14,8 trilhões de tokens diversos e de alta qualidade. O processo de pré-treinamento foi muito estável. Não tivemos nenhum pico de perda irrecuperável nem tivemos que reverter o processo de treinamento." - Fonte [8]
No entanto, a maior chave para o desempenho impressionante do DeepSeek-v3 é a escala de pré-treinamento - oEsse é um modelo grande treinado em um conjunto de dados igualmente grandeO DeepSeek-v3 tem um processo de pré-treinamento incrivelmente estável e segue o padrão de modelo de linguagem grande a um custo muito baixo! O treinamento de um modelo tão grande é difícil por vários motivos (por exemplo, falhas de GPU e picos de perda). O DeepSeek-v3 tem um processo de pré-treinamento incrivelmente estável e é treinado a um custo razoável de acordo com o padrão Large Language Model; veja abaixo.Esses resultados sugerem que operações maiores de pré-treinamento se tornam mais gerenciáveis e eficientes com o tempo.

(Fonte [18])
- Clusters de computação maiores13.
- Mais (e melhor) hardware.
- Muita potência.
- novos algoritmos (por exemplo, para treinamento distribuído em grande escala).
O treinamento de modelos de última geração não é apenas uma questão de garantir financiamento para mais GPUs; é um feito de engenharia multidisciplinar. Um esforço tão complexo leva tempo. Para referência, o GPT-4 foi lançado em março de 2023, quase três anos após o lançamento do GPT-3 - oEm particular, 33 meses. Um cronograma semelhante (se não mais longo) pode ser razoavelmente esperado para desbloquear outro aumento de 10 a 100 vezes na escala.
"A cada ordem de magnitude de crescimento em escala, é preciso encontrar inovações diferentes." - Ege Erdil (Epoch AI)
O futuro da pesquisa de IA
Agora que temos uma compreensão mais profunda do estado do pré-treinamento em escala, vamos supor (puramente para fins desta discussão) que a pesquisa de pré-treinamento subitamente atingirá um obstáculo. Mesmo que os recursos do modelo não melhorem em nada no futuro próximo, há várias maneiras pelas quais a pesquisa de IA pode continuar a evoluir rapidamente. Já discutimos alguns desses tópicos (por exemplo, dados sintéticos). Nesta seção, vamos nos concentrar em dois temas populares atualmente:
- Sistema/agente de modelos de idiomas grandes.
- Modelos de raciocínio.
Criação de um sistema útil de modelagem de linguagem grande
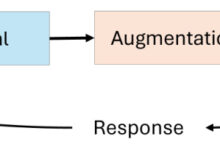
Atualmente, a maioria dos aplicativos baseados em modelos de Big Language é executada em um paradigma de modelo único. Em outras palavras, resolvemos uma tarefa passando-a para um único modelo do Big Language e usando diretamente a saída do modelo como a resposta para essa tarefa; veja abaixo.

Se quiséssemos aprimorar esse sistema (ou seja, resolver tarefas mais difíceis com maior precisão), poderíamos simplesmente melhorar os recursos do modelo subjacente, mas essa abordagem depende da criação de modelos mais avançados. Em vez disso, podemos ir além do paradigma de modelo único criando um sistema baseado em um modelo de linguagem grande que combina vários modelos de linguagem grande - oou outro componente-- Resolver tarefas complexas.

Fundamentos do sistema de modelagem de linguagem grande. O objetivo de um sistema Big Language Model é decompor tarefas complexas em partes menores que podem ser resolvidas mais facilmente pelo Big Language Model ou por outros módulos. Há duas estratégias principais que podem ser usadas para atingir esse objetivo (conforme mostrado na figura acima):
- Detalhamento das tarefasA tarefa em si é dividida em subtarefas menores que podem ser resolvidas individualmente e posteriormente agregadas14 para formar a resposta final.
- link (em um site)Solução de tarefas ou subtarefas por meio de várias chamadas sequenciais ao modelo de linguagem grande, em vez de uma única chamada.
Essas estratégias podem ser usadas individualmente ou em conjunto. Por exemplo, suponhamos que queiramos criar um sistema para resumir livros. Para fazer isso, podemos dividir a tarefa resumindo primeiro cada capítulo do livro. A partir daí, podemos:
- Resumir a tarefa dividindo-a ainda mais em pedaços menores de texto (ou seja, semelhante à decomposição recursiva/hierárquica).
- Vincule várias chamadas de LM; por exemplo, faça com que uma LM extraia todos os fatos ou informações importantes de um capítulo e faça com que outra LM gere um resumo do capítulo com base nesses fatos importantes.
Em seguida, podemos agregar esses resultados fazendo com que o Big Language Model resuma os resumos dos capítulos conectados para formar um resumo de todo o romance. O fato de que a maioria das tarefas complexas pode ser decomposta em partes simples que são fáceis de resolver torna esses sistemas de modelagem de linguagem grande muito poderosos. À medida que realizamos uma decomposição e uma vinculação mais extensas, esses sistemas podem se tornar muito complexos, o que os torna uma área interessante (e influente) da pesquisa aplicada de IA.
Criação de produtos com base no Big Language Model.Apesar do sucesso e da popularidade do Modelo de Big Language, o número de casos de uso reais (e amplamente adotados) do Modelo de Big Language ainda é muito pequeno. Atualmente, os maiores casos de uso do Modelo de Big Language são a geração de código e o bate-papo, ambos aplicativos relativamente óbvios do Modelo de Big Language15 ; veja abaixo.

Considerando que há muitas áreas de aplicação para modelagem de linguagem grande.A simples criação de produtos mais genuinamente úteis com base em grandes modelos de linguagem é uma área importante da pesquisa de IA aplicada. Já temos modelos muito avançados à nossa disposição, mas usá-los para criar produtos que valham a pena é um problema totalmente diferente. Para resolver esse problema, é necessário aprender a criar sistemas de modelagem de linguagem grandes, confiáveis e avançados.

(Fonte [19])
robustezé um dos maiores obstáculos para a criação de sistemas de agentes/modelos de linguagem grandes e mais avançados. Suponhamos que temos um sistema de Modelo de Grande Linguagem que faz dez chamadas diferentes para o Modelo de Grande Linguagem. Além disso, vamos supor que cada chamada ao Big Language Model tenha uma probabilidade de sucesso de 95% e que todas as chamadas precisem ser bem-sucedidas para gerar o resultado final correto. Embora os componentes individuais do sistema sejam razoavelmente precisos, oNo entanto, a taxa de sucesso de todo o sistema é de apenas 60%!

(Fonte [20])

(Fonte [20])
Modelos de raciocínio e novos paradigmas de dimensionamento
Uma crítica comum aos primeiros modelos de linguagem grandes era que eles simplesmente memorizavam dados e tinham pouco poder de raciocínio. No entanto, a alegação de que os modelos de linguagem grandes são incapazes de raciocinar foi amplamente desmentida nos últimos anos. Sabemos, por meio de pesquisas recentes, que esses modelos podem sempre ter tido uma capacidade inerente de raciocínio, mas tivemos que usar as dicas ou os métodos de treinamento corretos para obter essa capacidade.
Dicas de cadeia de pensamento (CoT) [22] foi uma das primeiras técnicas a demonstrar os recursos de inferência de um modelo de linguagem grande. O método é simples e baseado em dicas. Simplesmente pedimos ao Big Language Model que forneça uma explicação de sua resposta antes de gerar a resposta real; consulte aqui para obter mais detalhes. O poder de raciocínio do Big Language Model melhora significativamente quando ele gera uma justificativa que descreve o processo passo a passo usado para chegar a uma resposta. Além disso, essas explicações são legíveis por humanos e podem tornar o resultado do modelo mais interpretável!

(Fonte [22])
- Modelos de linguagem de classe grande - Modelos de avaliação de juízes geralmente fornecem a base para a pontuação antes de gerar os resultados finais da avaliação [23, 24].
- Estratégias supervisionadas de ajuste fino e de ajuste de instruções foram propostas para ensinar modelos de linguagem grandes menores/abertos a escrever cadeias de pensamento melhores [25, 26].
- Os modelos de linguagem grandes são frequentemente solicitados a refletir, comentar ou validar seus próprios resultados e, em seguida, modificar seus resultados com base nessas informações [12, 27].
O raciocínio complexo é um tópico de pesquisa ativo e está evoluindo rapidamente. Novos algoritmos de treinamento que ensinam grandes modelos de linguagem a incorporar a verificação (em nível de etapa) [28, 29] em seu processo de raciocínio mostraram resultados promissores, e provavelmente continuaremos a ver melhorias à medida que novas e melhores estratégias de treinamento forem disponibilizadas.
Modelo de inferência o1 da OpenAI [A o1 usa estratégias de raciocínio que se baseiam fortemente em cadeias de pensamento. Semelhante à maneira como os humanos pensam antes de responder a uma pergunta, a o1 leva algum tempo para "pensar" antes de fornecer uma resposta. De fato, o "pensamento" que a o1 gera é simplesmente uma longa cadeia de pensamentos que o modelo usa para pensar sobre o problema, dividi-lo em etapas mais simples, experimentar várias abordagens para resolver o problema e até mesmo corrigir seus próprios erros.16 A o1 também é uma "cadeia de pensamentos" usada pelo modelo para pensar sobre o problema.
"O OpenAI o1 [é] um novo modelo de linguagem em larga escala treinado para realizar raciocínios complexos usando o aprendizado por reforço. o1 pensa antes de responder - ele pode gerar uma longa cadeia interna de pensamento antes de responder ao usuário." - Fonte [21]
Os detalhes da estratégia exata de treinamento da o1 não foram compartilhados publicamente. No entanto, sabemos que a o1 aprende a raciocinar usando um algoritmo de "aprendizagem por reforço em larga escala" que "faz uso muito eficiente dos dados" e se concentra em melhorar a capacidade do modelo de gerar cadeias de pensamento úteis. Com base nos comentários públicos dos pesquisadores da OpenAI e nas declarações recentes sobre o o1, parece que o modelo foi treinado usando o aprendizado por reforço puro, o que contradiz sugestões anteriores de que o o1 pode ter usado alguma forma de pesquisa de árvore em seu raciocínio.

Comparação entre GPT-4o e o1 em tarefas de inferência pesada (Fonte [21])
- Top 89% em Competitive Programming Problems no Codeforces.
- Colocação entre os 500 melhores alunos dos Estados Unidos nas rodadas de qualificação da American Mathematical Olympiad (AIME).
- Supera a precisão de estudantes de doutorado humanos em questões de física, biologia e química de nível de graduação (GPQA).

(Fonte [22])
"Descobrimos que o desempenho de o1 continua a melhorar com mais aprendizado de reforço (computado durante o treinamento) e mais tempo de raciocínio (computado durante o teste)." - Fonte [22]
Da mesma forma, vemos no gráfico acima que o desempenho de o1 melhora suavemente à medida que investimos mais computação no treinamento por meio do aprendizado por reforço. Essa é exatamente a abordagem seguida para criar o modelo de inferência o3. O modelo foi avaliado pela OpenAI no final de 2024 e pouquíssimos detalhes sobre o o3 foram compartilhados publicamente. No entanto, como o modelo foi lançado tão rapidamente após o o1 (ou seja, três meses depois), é provável que o o3 seja uma versão "ampliada" do o1, com mais computação investida no aprendizado por reforço.

No momento em que este artigo foi escrito, o modelo o3 ainda não havia sido lançado, mas os resultados obtidos com a extensão do o1 são impressionantes (e, em alguns casos, chocantes). As realizações mais notáveis do o3 estão listadas abaixo:
- obteve 87,5% no benchmark ARC-AGI, em comparação com a precisão de 5% do GPT-4o. O o3 foi o primeiro modelo a exceder o desempenho em nível humano de 85% no ARC-AGI. O benchmark foi descrito como a "Estrela do Norte" da AGI e está invicto há mais de cinco anos17 .
- Uma precisão de 71,7% no SWE-Bench Verified e uma pontuação Elo de 2727 no Codeforces colocam o o3 entre os 200 melhores programadores humanos competitivos do mundo.
- com uma precisão de 25,2% no benchmark FrontierMath da EpochAI.Melhoria da precisão do estado da arte em relação ao 2.0% anteriorO benchmark foi descrito por Terence Tao como "extremamente difícil" e provavelmente insolúvel por sistemas de IA "por pelo menos alguns anos". O benchmark foi descrito por Terence Tao como "extremamente difícil" e provavelmente insolúvel por sistemas de IA "por pelo menos alguns anos".
Também foi apresentada uma versão lite do o3, chamada o3-mini, que apresenta um desempenho muito bom e oferece melhorias significativas na eficiência computacional.

(Fonte [21] e Aqui estão)
- Tempo de treinamento (aprendizado intensivo) Cálculo.
- Calcule quando estiver raciocinando.
O dimensionamento de modelos no estilo o1 é diferente da lei tradicional de tamanho. Em vez de aumentar o processo de pré-treinamento, aumentamos a quantidade de computação aplicada ao pós-treinamento e à inferência.É um paradigma totalmente novo de dimensionamentoAté o momento, os resultados obtidos com a extensão do modelo de inferência foram muito bons. Essa descoberta sugere que existem claramente outros caminhos para a expansão além do pré-treinamento. Com o surgimento dos modelos de inferência, descobrimos a próxima montanha a ser escalada. Embora ela possa se apresentar de diferentes formas, aA escala continuará a impulsionar os avanços na pesquisa de IA.
observações finais
Agora temos uma visão mais clara das leis de escala, seu impacto em modelos de linguagem grandes e a direção futura da pesquisa em IA. Como aprendemos, há muitos fatores que contribuem para as recentes críticas às leis de escala:
- A decadência natural da lei de escala.
- As expectativas de competência em modelagem de idiomas de grande porte variaram consideravelmente.
- Atrasos em trabalhos de engenharia interdisciplinares e de grande escala.
Essas são perguntas legítimas queMas nenhum deles indica que o dimensionamento ainda não está funcionando como esperado. O investimento em pré-treinamento em larga escala continuará (e deverá continuar), mas as melhorias se tornarão cada vez mais difíceis com o tempo. Como resultado, outras direções de desenvolvimento (por exemplo, agentes e inferência) se tornarão mais importantes. No entanto, a ideia básica de escalonamento continuará a desempenhar um papel importante à medida que investirmos nessas novas áreas de pesquisa. O fato de continuarmos ou não a escalonar não é o problema.A verdadeira questão é o que vamos expandir em seguida.
bibliografia
[1] Kaplan, Jared, et al. "Leis de escala para modelos de linguagem neural". arXiv preprint arXiv:2001.08361 (2020).
[2] Radford, Alec. "Improving language understanding by generative pre-training." (2018).
[3] Radford, Alec, et al. "Language models are unsupervised multitask learners." Blog da OpenAI 1.8 (2019): 9.
[4] Brown, Tom, et al. "Language models are few-shot learners." Avanços nos sistemas de processamento de informações neurais 33 (2020): 1877-1901.
[5] Achiam, Josh, et al. "Relatório técnico do Gpt-4". arXiv preprint arXiv:2303.08774 (2023).
[6] Hoffmann, Jordan, et al. "Training compute-optimal large language models". arXiv preprint arXiv:2203.15556 (2022).
[7] Gadre, Samir Yitzhak, et al. "Language models scale reliably with over-training and on downstream tasks." arXiv preprint arXiv:2403.08540 (2024).
[8] Ouyang, Long, et al. "Training language models to follow instructions with human feedback". Avanços nos sistemas de processamento de informações neurais 35 (2022): 27730-27744.
[9] Smith, Shaden, et al. "Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model." arXiv preprint arXiv:2201.11990 (2022).
[10] Rae, Jack W., et al. "Scaling language models: methods, analysis & insights from training gopher." arXiv preprint arXiv:2112.11446 (2021).
[11] Bhagia, Akshita, et al. "Establishing Task Scaling Laws via Compute-Efficient Model Ladders". arXiv preprint arXiv:2412.04403 (2024).
[12] Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback". arXiv preprint arXiv:2212.08073 (2022).
[13] Blakeney. Cody.Ganhos de desempenho com a amostragem de domínios no final do treinamento". arXiv preprint arXiv:2406.03476 (2024).
[14] Chen, Hao, et al. "On the Diversity of Synthetic Data and its Impact on Training Large Language Models" (Sobre a diversidade de dados sintéticos e seu impacto no treinamento de modelos de idiomas grandes). arXiv preprint arXiv:2410.15226 (2024).
[15] Guo, Zishan, et al. "Evaluating large language models: A comprehensive survey". arXiv preprint arXiv:2310.19736 (2023).
[16] Xu, Zifei, et al. "Scaling laws for post-training quantized large language models." arXiv preprint arXiv:2410.12119 (2024).
[17] Xiong, Yizhe, et al. "Temporal scaling law for large language models." arXiv preprint arXiv:2404.17785 (2024).
[18] DeepSeek-AI et al. "Relatório técnico do DeepSeek-v3". https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf (2024).
[19] Schick, Timo, et al. "Toolformer: language models can teach themselves to use tools." arXiv preprint arXiv:2302.04761 (2023).
[20] Welleck, Sean, et al. "From decoding to meta-generation: reference-time algorithms for large language models." arXiv preprint arXiv:2406.16838 (2024).
[21] OpenAI et al. "Aprendendo a raciocinar com LLMs". https://openai.com/index/learning-to-reason-with-llms/ (2024).
[22] Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Avanços nos sistemas de processamento de informações neurais 35 (2022): 24824-24837.
[23] Liu, Yang, et al. "G-eval: avaliação de Nlg usando gpt-4 com melhor alinhamento humano". arXiv preprint arXiv:2303.16634 (2023).
[24] Kim, Seungone, et al. "Prometheus: Inducing fine-grained evaluation capability in language models". Décima segunda Conferência Internacional sobre Representações de Aprendizagem . 2023.
[25] Ho, Namgyu, Laura Schmid e Se-Young Yun: "Large language models are reasoning teachers". arXiv preprint arXiv:2212.10071 (2022).
[26] Kim, Seungone, et al. "The cot collection: improving zero-shot and few-shot learning of language models via chain-of-thought fine-tuning." arXiv preprint arXiv:2305.14045 (2023).
[27] Weng, Yixuan, et al. "Large language models are better reasoners with self-verification." arXiv preprint arXiv:2212.09561 (2022).
[28] Lightman, Hunter, et al. "Let's verify step by step" (Vamos verificar passo a passo). arXiv preprint arXiv:2305.20050 (2023).
[29] Zhang, Lunjun, et al. "Generative verifiers: reward modelling as next-token prediction." arXiv preprint arXiv:2408.15240 (2024).
1 Os dois principais relatórios são do The Information e da Reuters.
2 Geramos o desenho usando as seguintes configurações:a = 1(matemática) gênerop = 0.5paz 0 < x < 1.
3 Os cálculos são definidos em [1] como 6NBSque N é o número de parâmetros do modelo queB é o tamanho do lote usado durante o treinamento.S é o número total de etapas de treinamento.
4 Essa constante de multiplicação extra não altera o comportamento da lei de potência. Para entender por que isso acontece, precisamos entender a definição de invariância de escala. Como as leis de potência são invariantes em escala, as características básicas de uma lei de potência são as mesmas, mesmo que aumentemos ou diminuamos a escala por algum fator. O comportamento observado é o mesmo em qualquer escala!
5 Essa descrição é do prêmio Test of Time Award que Ilya recebeu por esse artigo na NeurIPS'24.
6 Embora isso possa parecer óbvio agora, devemos ter em mente que, na época, a maioria das tarefas de PLN (por exemplo, resumo e perguntas e respostas) tinha domínios de pesquisa dedicados a elas! Cada uma dessas tarefas tinha arquiteturas associadas específicas à tarefa, especializadas para executá-la, e o GPT era um modelo genérico único que podia superar a maioria dessas arquiteturas em várias tarefas diferentes.
7 Isso significa que simplesmente descrevemos cada tarefa nos prompts do modelo de linguagem grande e usamos o mesmo modelo para resolver as diferentes tarefas - oSomente os prompts mudam entre as tarefas.
8 Isso é esperado, pois esses modelos usam inferência de amostra zero e não são ajustados em nenhuma tarefa downstream.
9 Por recursos "emergentes", queremos dizer habilidades que só estão disponíveis para modelos de linguagem grandes quando eles atingem um determinado tamanho (por exemplo, um modelo suficientemente grande).
10 Aqui, definimos "computacionalmente ideal" como a configuração de treinamento que produz o melhor desempenho (em termos de perda de teste) a um custo computacional de treinamento fixo.
11 Por exemplo, o Anthropic continua atrasando seu lançamento. Claude 3.5 Opus, o Google só lançou uma versão em flash do Gemini-2, e a OpenAI só lançou o GPT-4o em 2024 (até o lançamento do o1 e do o3 em dezembro), que, sem dúvida, não é muito mais capaz do que o GPT-4.
12 Apenas 37 bilhões de parâmetros estão ativos durante a inferência de um único token.
13 Por exemplo, a xAI construiu recentemente um novo data center em Memphis com 100.000 GPUs NVIDIA, e a liderança da Anthropic está aumentando seus gastos com computação em 100 vezes nos próximos anos.
14 A etapa de agregação pode ser implementada de várias maneiras. Por exemplo, podemos agregar as respostas manualmente (por exemplo, por meio de uma conexão), usando um modelo de linguagem grande ou qualquer outra coisa!
15 Isso não se deve ao fato de essas tarefas serem simples. A geração de código e o bate-papo são difíceis de resolver, mas são (indiscutivelmente) aplicações bastante óbvias do Big Language Model.
16A OpenAI optou por ocultar essas longas cadeias de pensamento dos usuários da o1. O argumento por trás dessa escolha é que esses fundamentos fornecem insights sobre os processos de pensamento do modelo que podem ser usados para depurar ou monitorar o modelo. No entanto, os modelos devem ter permissão para expressar seus pensamentos puros sem nenhum dos filtros de segurança necessários para a saída do modelo voltado para o usuário.
17 Atualmente, o ARC-AGI permanece tecnicamente invicto porque o3 excede os requisitos computacionais para benchmarking. No entanto, o modelo ainda alcança uma precisão de 75,7% usando configurações computacionais mais baixas.