
Implantação local de modelos grandes QwQ-32B: um guia fácil para PCs

O campo da modelagem de inteligência artificial (IA) está sempre cheio de surpresas, e cada avanço tecnológico pode causar nervosismo no setor. Recentemente, a equipe QwQ da Alibaba lançou seu mais recente modelo de inferência, o QwQ-32B, nas primeiras horas da manhã, o que mais uma vez atraiu muita atenção.

De acordo com o comunicado oficialO QwQ-32B é um modelo de inferência com uma escala de parâmetros de apenas 32 bilhõesE, ainda assim, eles afirmam ser capazes de rivalizar com DeepSeek-R1 e outros modelos de ponta e líderes do setor. O anúncio foi uma bomba que incendiou instantaneamente a comunidade de tecnologia, com links para o blog oficial, biblioteca de modelos Hugging Face, downloads de modelos, demonstrações on-line e um site para que os usuários possam saber mais sobre o produto e experimentá-lo.
Embora as informações da versão sejam breves e concisas, a força técnica por trás dela está longe de ser simples. A frase "32 bilhões de parâmetros comparáveis ao DeepSeek-R1" é bastante impressionante, sabendo que, em geral, quanto maior o número de parâmetros em um modelo, maior tende a ser o desempenho, mas isso também significa maior demanda por recursos de computação. QwQ-32B Conseguir um desempenho semelhante ao do megamodelo com um pequeno número de parâmetros é, sem dúvida, um grande avanço, que naturalmente despertou grande interesse entre os entusiastas e profissionais de tecnologia.
Para demonstrar o desempenho do QwQ-32B de forma mais intuitiva, um gráfico de teste de benchmark oficial foi tornado público simultaneamente. O benchmarking é um meio importante de avaliar os recursos de um modelo de IA, que mede o desempenho do modelo em diferentes tarefas, testando-o em uma série de conjuntos de dados predefinidos e padronizados, fornecendo assim aos usuários uma referência objetiva de desempenho.

A partir desse gráfico de benchmarking, podemos capturar rapidamente os seguintes pontos-chave de informação:
- Velocidade de propagação fenomenal: As informações de lançamento do modelo достига́ть foram lidas por mais de 1,69 milhão de pessoas em apenas 12 horas, o que reflete totalmente a demanda urgente do mercado por modelos de IA de alto desempenho e a alta expectativa do QwQ-32B.
- Excelente desempenho: Com apenas 32 bilhões de parâmetros, o QwQ-32B é capaz de competir com a versão de parâmetros completos do DeepSeek-R1, que tem uma contagem de parâmetros de 671 bilhões, no teste de benchmark, mostrando uma incrível relação de eficiência energética. Esse fenômeno de um modelo pequeno superando um modelo grande definitivamente rompe a percepção tradicional da relação entre o desempenho do modelo e o tamanho do parâmetro.
- Supera o desempenho dos modelos de destilação de sua classe: O QwQ-32B supera significativamente o desempenho da versão de destilação 32B do DeepSeek-R1. A destilação é uma técnica de compactação de modelos que visa imitar o comportamento de um modelo maior por meio do treinamento de um modelo menor, reduzindo assim o custo computacional e mantendo o desempenho. O fato de o QwQ-32B superar o modelo de destilação 32B demonstra ainda mais a sofisticação de sua arquitetura e metodologia de treinamento.
- Liderança de desempenho multidimensional: O QwQ-32B supera o modelo de código fechado da OpenAI, o1-mini, em várias dimensões de benchmarking, o que mostra que o QwQ-32B é capaz de competir com os principais modelos de código fechado em termos de recursos de uso geral.
De particular interesse é o fato de que o QwQ-32B, com apenas 32 bilhões de parâmetros, é capaz de superar modelos gigantes com mais de 20 vezes o número de parâmetros, representando outro salto na tecnologia de IA. Ainda mais interessante, os usuários agora podem executar facilmente a versão quantificada do QwQ-32B localmente com uma placa de vídeo de consumo da classe RTX3090 ou RTX4090. A implementação local não apenas reduz a barreira ao uso, mas também abre mais possibilidades para a segurança de dados e aplicativos personalizados. Os usuários com desempenho inferior da placa de vídeo podem tentar começar a usar a solução de implementação em nuvem recomendada:Implementando o modelo de código aberto DeepSeek-R1 on-line com potência de GPU gratuitaou inscreva-se diretamente para usar a API gratuita.Alibaba (vulcão) fornece 1 milhão de tokens por dia (por 180 dias), e o Akash A API é gratuita para uso direto, sem registro.
O DeepSeek não é mais um pônei de um truque só, então como a OpenAI se mantém no topo?
Com o QwQ-32B mostrando uma competitividade tão forte, os produtos existentes da OpenAI, tanto a versão Pro de US$ 200 quanto a versão Plus de US$ 20, enfrentam um sério desafio em termos de preço/desempenho. O QwQ-32B deu ao mercado algo em que pensar, especialmente à luz das flutuações de desempenho que os modelos da OpenAI às vezes apresentam, que foram criticadas pelos usuários como "emburrecimento". No entanto, a OpenAI ainda tem uma história profunda e um extenso ecossistema no campo da IA, e ainda pode ter uma vantagem no ajuste fino de modelos e na otimização de aplicativos em áreas específicas. No entanto, o lançamento do QwQ-32B, sem dúvida, rompe o padrão original do mercado, forçando todos os participantes a reexaminar suas próprias vantagens técnicas e estratégias de mercado.
Para avaliar melhor os recursos reais do QwQ-32B, é necessário instalá-lo localmente e testá-lo em detalhes, especialmente para examinar seu desempenho de raciocínio e nível de "QI" em um ambiente operacional local.
Felizmente, graças ao Ollama Com o advento de ferramentas como o Ollama, a implantação e a execução de grandes modelos de linguagem localmente em computadores pessoais se tornaram muito simples. O Ollama, uma estrutura leve e de código aberto para execução de modelos, simplifica muito o processo de implantação e gerenciamento de grandes modelos locais.
A Ollama é conhecida por sua eficiência e facilidade de uso. Logo após o lançamento do QwQ-32B, a Ollama anunciou rapidamente o suporte para o modelo, diminuindo ainda mais a barreira para que os usuários experimentem a mais recente tecnologia de IA e facilitando a todos o acesso ao poder do QwQ-32B.
1. instalação e operação da Ollama
Primeiro, visite o site oficial da Ollama em ollama.com e clique no botão Download para baixar o pacote de instalação apropriado para o seu sistema operacional.
A Ollama oferece suporte total para todos os principais sistemas operacionais, incluindo macOS (Intel e Apple Silicon), Windows e Linux, garantindo que o modelo QwQ-32B possa ser facilmente usado em todas as plataformas.
Quando o download for concluído, clique duas vezes no instalador e siga o assistente para concluir o processo de instalação. Após a instalação bem-sucedida, você verá um ícone de alpaca fofa na bandeja da barra de tarefas do Windows ou na barra de menus do macOS, indicando que o Ollama foi iniciado com êxito e está sendo executado em segundo plano, pronto para atendê-lo.
2. download do modelo QwQ-32B
Leia mais:O Unsloth resolve o problema de inferência duplicada na versão quantificada do QwQ-32B
Depois de instalar e executar o Ollama com êxito, você poderá começar a fazer o download do modelo QwQ-32B.

Abra o cliente Ollama no diretório Modelos Na página Modelos, você verá que o modelo QwQ-32B subiu rapidamente para o topo da lista de modelos populares, o que comprova sua popularidade. Localize a entrada do modelo "qwq" e clique nela para ir para a página de detalhes do modelo. Na página de detalhes, copie os comandos destacados na borda vermelha.
Abra um terminal local (macOS/Linux) ou um prompt de comando (Windows).
Em um terminal ou prompt de comando, cole e execute o seguinte comando:ollama run qwq
ollama run qwq
O Ollama iniciará automaticamente o download dos arquivos do modelo QwQ-32B da nuvem e iniciará o ambiente de tempo de execução do modelo automaticamente quando o download for concluído.
Vale a pena mencionar queO processo de download do modelo não parece exigir configuração de rede adicional por parte do usuário. Esse é, sem dúvida, um recurso muito útil para os usuários domésticos. Afinal, um arquivo modelo com quase 20 GB reduzirá muito a experiência do usuário se a velocidade de download for muito lenta ou exigir um ambiente de rede especial.
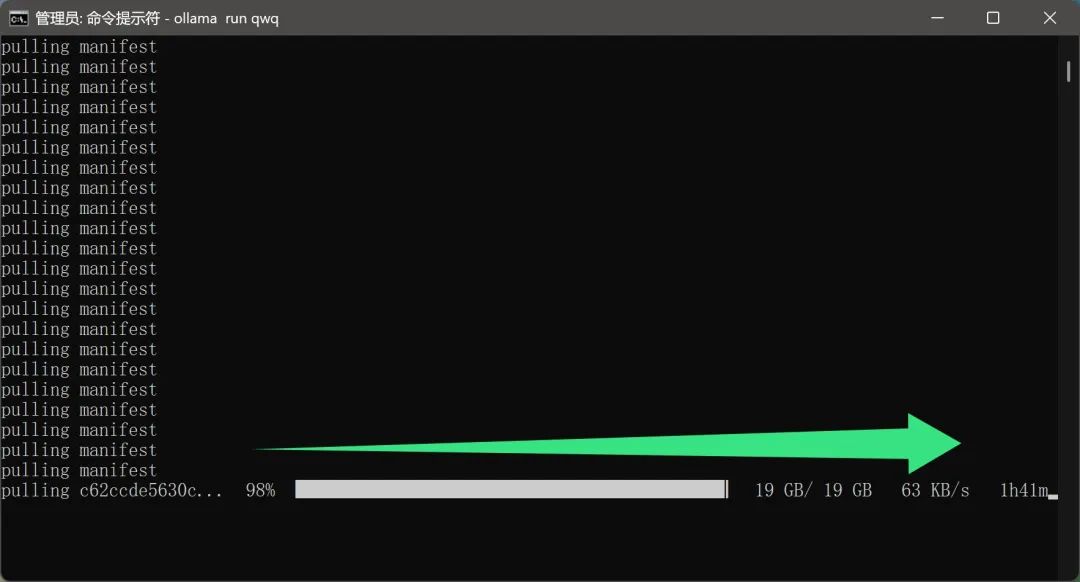
No entanto, como o modelo QwQ-32B é muito popular no momento e há muitos usuários fazendo o download, a velocidade real do download pode ser afetada até certo ponto, resultando em um tempo de download mais longo, o que exige que os usuários sejam pacientes.
Após algum tempo de espera, o modelo foi finalmente baixado. Executei o modelo QwQ-32B em um computador equipado com uma placa de vídeo RTX3060 para desktop com 12 GB de memória de vídeo para testá-lo e fiquei agradavelmente surpreso: além de o modelo ter sido carregado com sucesso, ele também foi capaz de fornecer respostas suaves com base nas entradas do usuário e, o mais importante, não houve problemas de estouro de memória de vídeo durante todo o processo. Isso significa que mesmo as placas de vídeo mais comuns podem atender aos requisitos do modelo quantitativo QwQ-32B.

Em termos de desempenho real de inferência, a capacidade do QwQ-32B já superou alguns modelos OpenAI que os usuários chamam de "IQ underline". Isso também confirma a superioridade do QwQ-32B em termos de desempenho.
Por meio do Gerenciador de Tarefas do Windows, podemos monitorar o uso de recursos do modelo em tempo real. Os resultados mostram que a CPU, a memória e a memória gráfica estão todas sob alta carga durante o processo de inferência do modelo, o que também reflete os altos requisitos de recursos de hardware para a execução de modelos grandes localmente.
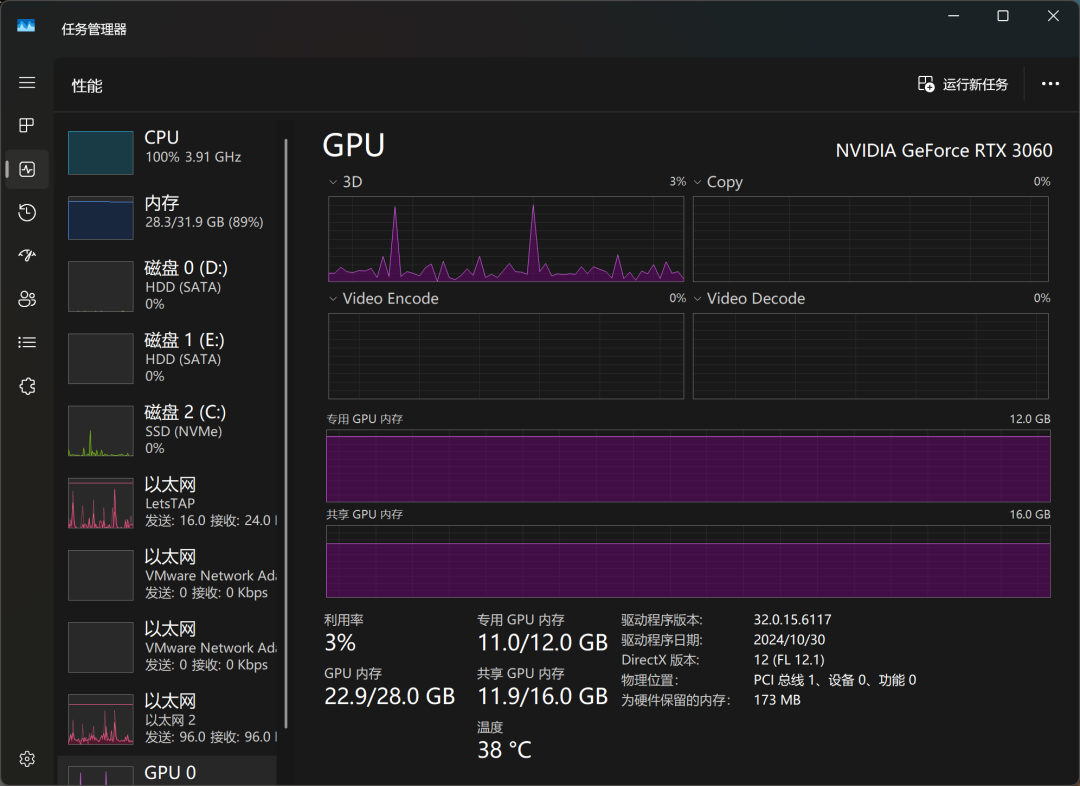
Na placa de vídeo RTX3060, o QwQ-32B responde em um ritmo de "da, da, da, da...", o que pode satisfazer as necessidades básicas de uso, mas ainda há espaço para melhorias em termos de capacidade de resposta e suavidade. Se estiver procurando uma experiência de execução de modelo local mais extrema, talvez seja necessário um nível mais alto de configuração de hardware.
Para melhorar ainda mais a velocidade de execução do modelo, baixei e executei o modelo QwQ-32B novamente em um dispositivo equipado com uma placa de vídeo RTX3090 topo de linha. Os resultados experimentais mostram que, após a substituição da placa de vídeo de última geração, a velocidade de execução do modelo foi significativamente aprimorada, e não é exagero descrevê-la como "tão rápida quanto voar". Isso também reafirma a importância da configuração do hardware para a experiência de execução do modelo local de grande porte.
3. integração do QwQ-32B aos clientes
Embora conversar com o modelo diretamente da interface de linha de comando seja uma maneira simples e direta, para quem precisa usá-lo com frequência ou busca uma melhor experiência de interação, usar um cliente gráfico é, sem dúvida, uma opção mais conveniente. Há muitos softwares excelentes de cliente de modelo de IA no mercado, e já apresentamos muitos deles, como o ChatWise. O principal motivo para escolher o ChatWise é o design simples e intuitivo da interface, a lógica de operação clara e fácil de entender e a capacidade de proporcionar uma boa experiência aos usuários.
A seguir, são descritas as etapas para configurar um modelo QwQ-32B para o cliente ChatWise.
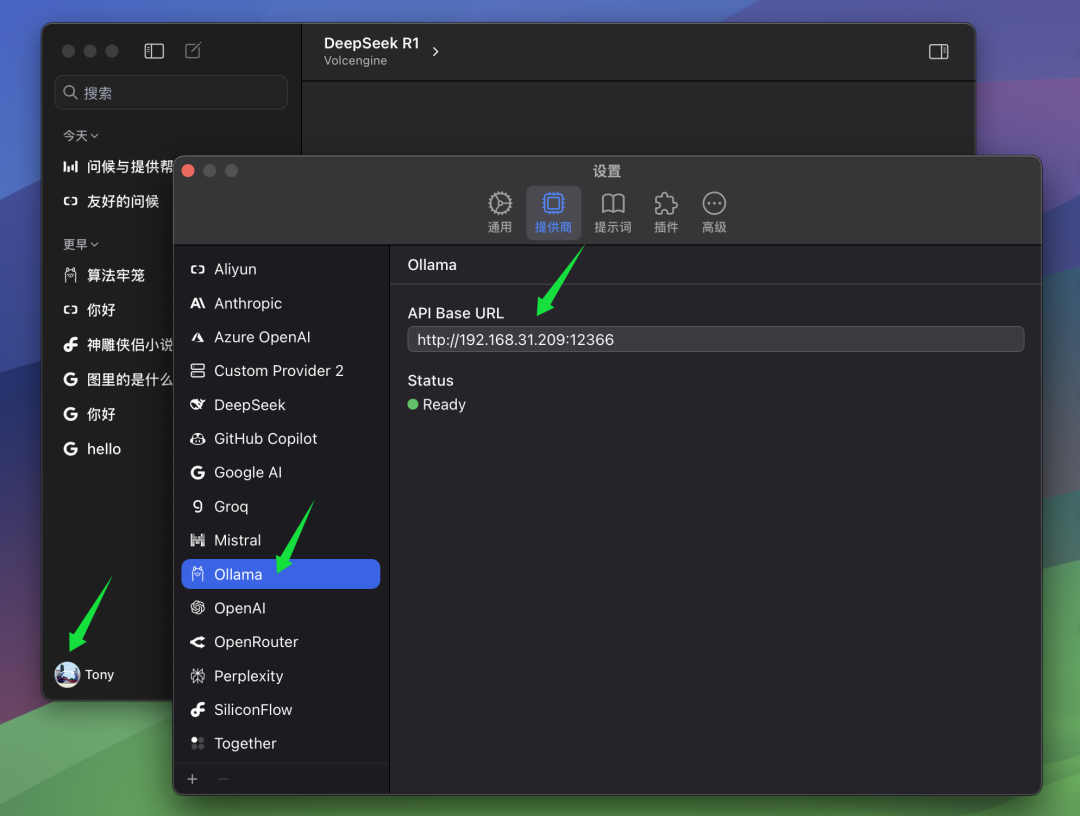
Se o seu cliente ChatWise e o serviço Ollama estiverem em execução no mesmo computador, você poderá abrir o cliente ChatWise e usar o modelo QwQ-32B diretamente, sem nenhuma configuração adicional. Esse é o caso da maioria dos usuários, ou seja, tanto o serviço Ollama quanto o aplicativo cliente estão instalados no mesmo dispositivo.
No entanto, se você, como o autor, tiver instalado o serviço Ollama em outro computador (por exemplo, um servidor) e o cliente ChatWise estiver em execução no seu computador local, será necessário modificar manualmente o BaseURL para que os clientes possam se conectar ao serviço Ollama remoto. Na seção BaseURL Nas configurações, você precisa preencher o endereço IP do computador que executa o serviço Ollama e o número da porta que você configurou no servidor Ollama. A porta padrão do Ollama é 13434, portanto, se você não a tiver configurado especificamente, poderá usar a porta padrão.
cumprir BaseURL Depois de configurado, você pode selecionar o modelo que deseja usar no cliente do ChatWise.
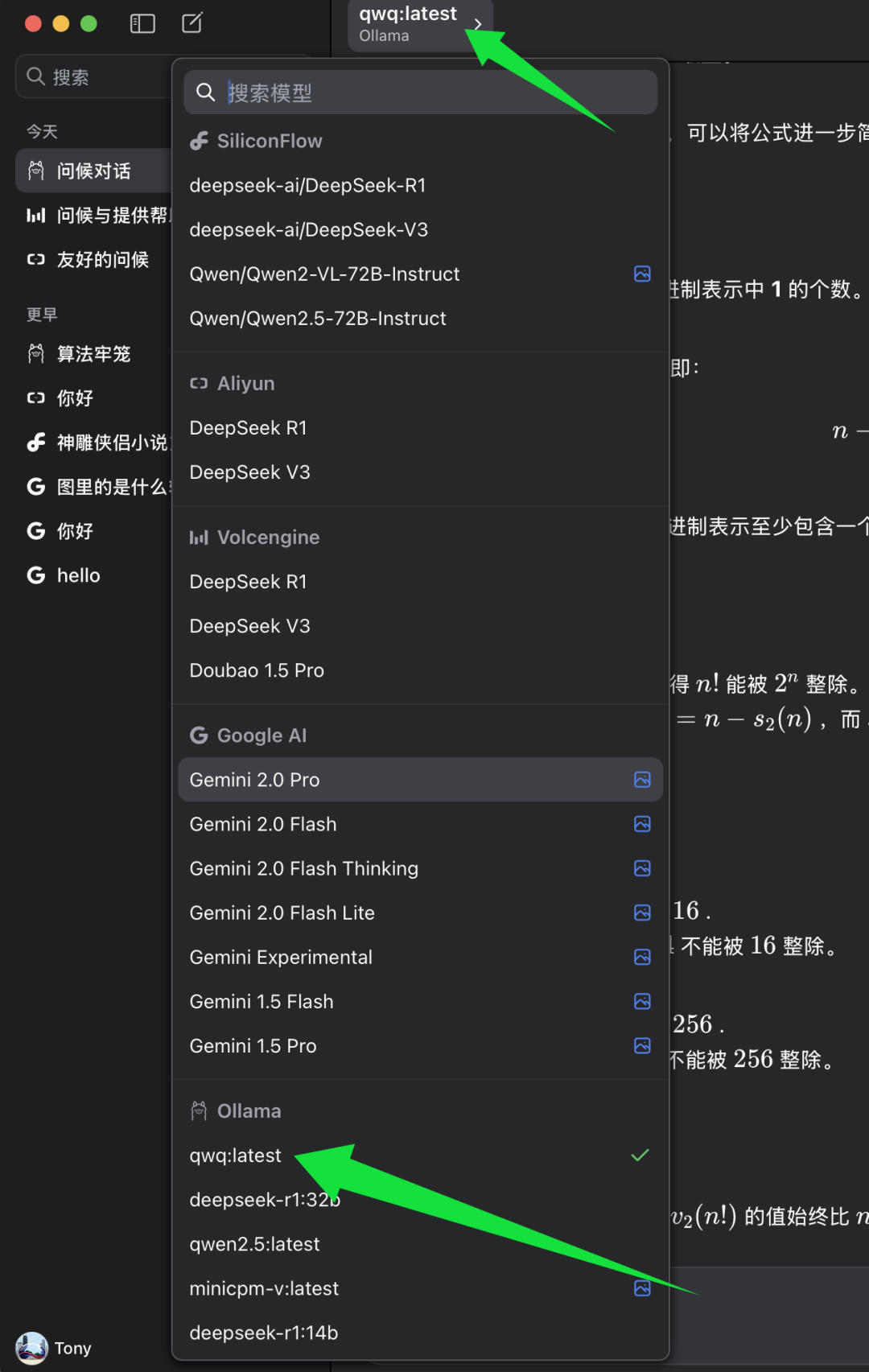
Na lista de seleção de modelos do ChatWise, localize a categoria de modelo Ollama e, abaixo dela, selecione qwq:mais recente. qwq:mais recente Representa a versão mais recente do modelo QwQ-32B, geralmente também a versão quantised de 4 bits. Selecione qwq:mais recente Depois disso, você pode começar a experimentar o poder do modelo QwQ-32B no cliente ChatWise.
4. teste de nível de inteligência do modelo QwQ-32B
Para avaliar o nível de inteligência do modelo QwQ-32B de forma mais objetiva, usamos um conjunto de perguntas clássicas desenvolvidas anteriormente para testar o problema de "inteligência reduzida" do modelo OpenAI. Esse conjunto consiste em quatro perguntas cuidadosamente selecionadas que se mostraram empiricamente úteis se o ChatGPT (especialmente para os modelos GPT-3 ou GPT-4), muitas vezes é difícil responder corretamente a essas perguntas se houver um feedback do usuário de "inteligência reduzida". Portanto, esse conjunto de perguntas pode ser usado, até certo ponto, como referência para testar o nível de inteligência dos modelos maiores.
Em seguida, testaremos o modelo QwQ-32B executado localmente, um a um, para ver se ele consegue responder com êxito a todas as perguntas.
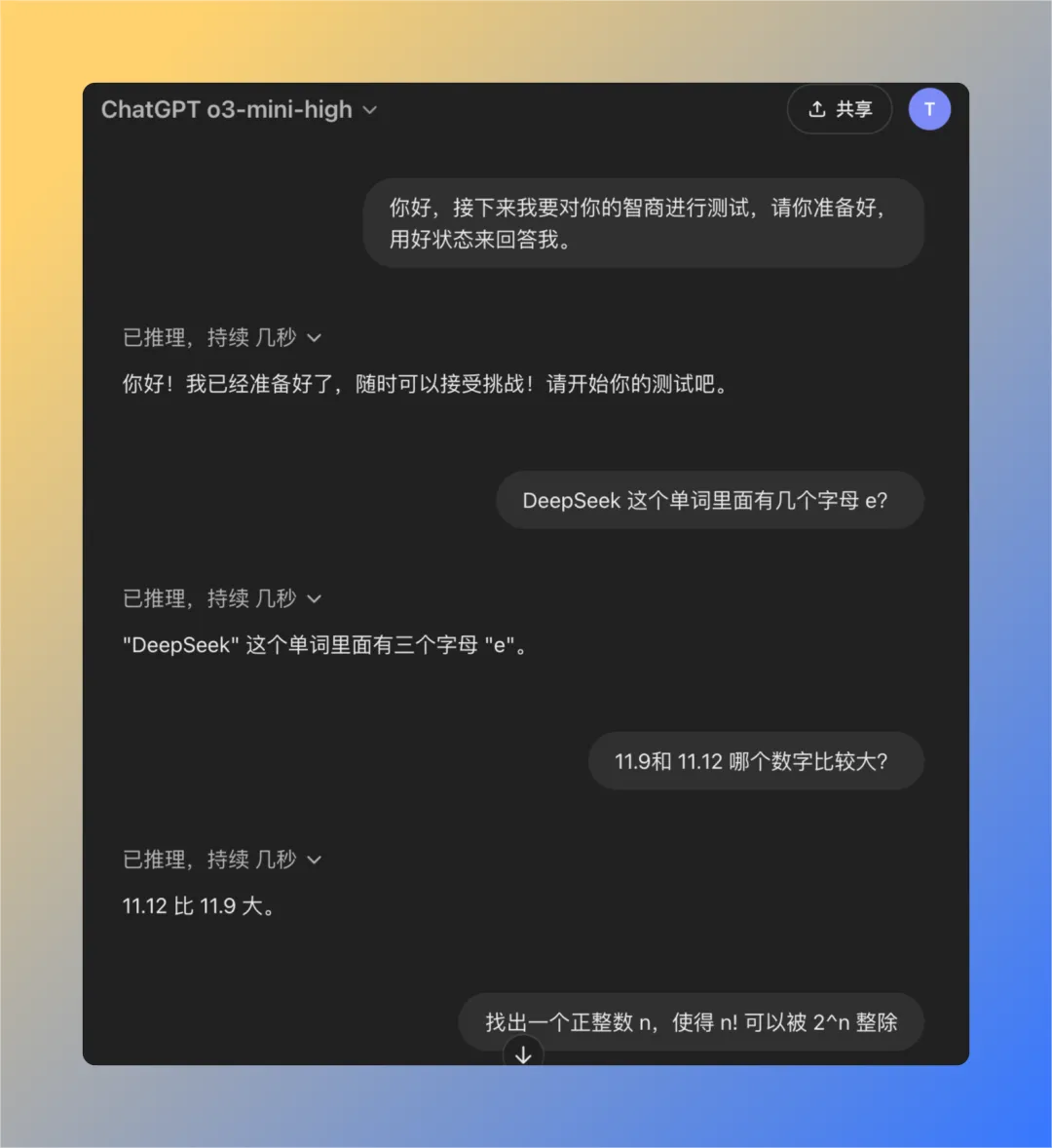
Pergunta 1: Quantas letras da letra e existem na palavra deepseek?
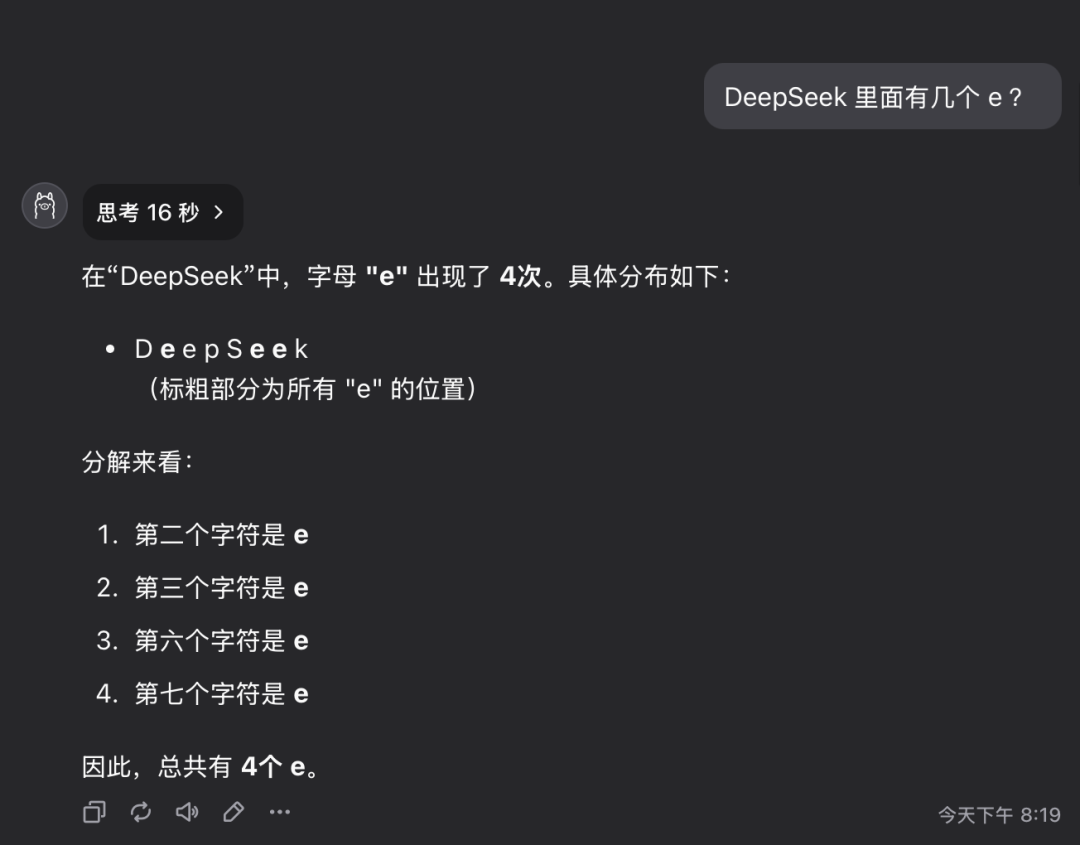
O modelo QwQ-32B deu a resposta correta em 16 segundos: 3. A resposta está correta..
Essa pergunta pode parecer simples, mas, na verdade, ela examina a capacidade do modelo de entender e extrair informações detalhadas com precisão. Surpreendentemente, ainda há um número significativo de modelos grandes que não conseguem responder com precisão a essas perguntas.
Pergunta 2: Qual valor é maior, 11,9 ou 11,12?

O modelo QwQ-32B deu a resposta correta em 47 segundos: 11,12 é maior. A resposta está correta..
Novamente, esse é um problema aparentemente básico, mas clássico. Muitos modelos grandes são confusos ou julgam mal comparações numéricas simples, refletindo possíveis deficiências no raciocínio lógico subjacente do modelo.
Problema 3: Encontre um número inteiro positivo n tal que o fatorial de n (n!) seja divisível pela enésima potência de 2 (2^n).

O modelo QwQ-32B fornece a resposta correta em 121 segundos: não existe esse número inteiro positivo n. A resposta está correta..
O objetivo dessa pergunta não é encontrar uma resposta numérica específica, mas examinar se o modelo tem a capacidade de pensar de forma abstrata e raciocinar logicamente, entender a natureza do problema e, por fim, chegar à conclusão de que "não existe". QwQ-32B foi capaz de responder corretamente a essa pergunta, demonstrando alguma habilidade de raciocínio lógico.
Pergunta 4: Raciocínio lógico clássico - Quebra-cabeça da cor do chapéu
"Há 5 pessoas em uma fila e cada uma delas está usando um chapéu na cabeça, que pode ser vermelho ou azul. Cada pessoa só consegue ver a cor do chapéu da pessoa que está à sua frente na fila, mas não a cor do chapéu em sua própria cabeça. O facilitador diz ao grupo com antecedência: "Dessas 5 pessoas, há pelo menos um chapéu vermelho". Agora, começando com a pessoa no final da fileira e avançando sucessivamente, cada pessoa é questionada: "Você sabe qual é a cor do seu chapéu?" Cada pessoa só pode responder "sim" ou "não". Supondo que a 5ª pessoa responda "não" e a 4ª pessoa responda "sim", qual é a distribuição de todas as cores possíveis de chapéu?"
Em comparação com as três primeiras perguntas, essa pergunta de raciocínio lógico era significativamente mais difícil e exigia mais análise lógica e habilidades de raciocínio do modelo.
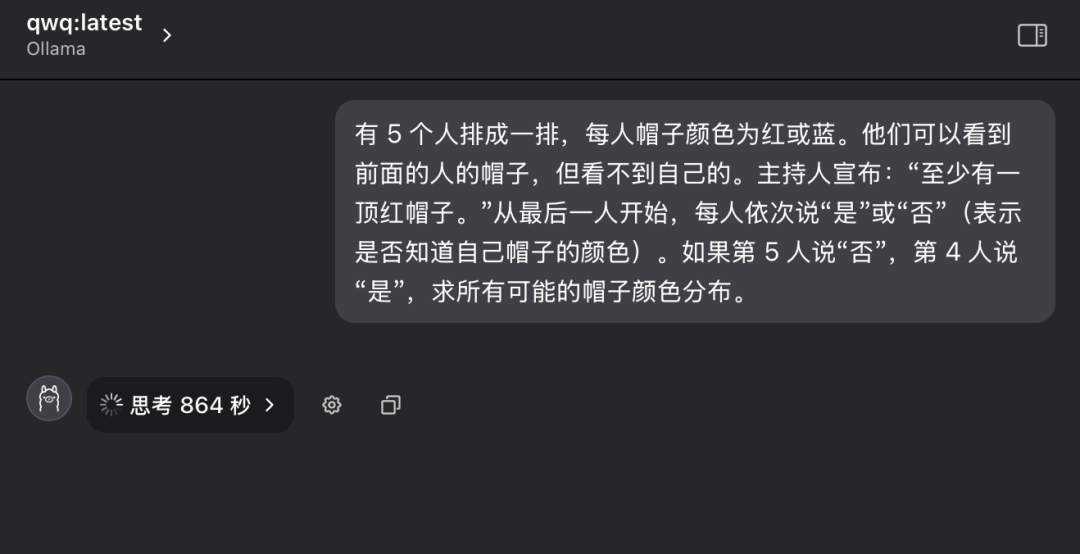
Durante o primeiro questionamento, o modelo QwQ-32B entrou em um estado de pensamento prolongado, com as palavras "Thinking..." (Pensando...) piscando na tela, como se o "cérebro" estivesse funcionando em alta velocidade, o que fez com que as pessoas se preocupassem se o hardware poderia suportar uma carga computacional tão intensa. Isso até faz com que as pessoas se preocupem se o hardware pode suportar uma carga computacional tão intensa. Considerando o tempo e a condição de execução do hardware, após mais de dez minutos de espera, interrompi manualmente o processo de raciocínio do modelo.
Em seguida, o autor reabriu uma nova sessão de diálogo e fez as mesmas perguntas ao modelo QwQ-32B novamente.

Dessa vez, o modelo QwQ-32B finalmente deu uma resposta totalmente correta após 196 segundos e explicou o raciocínio em detalhes. A resposta está correta..
Observando o registro do processo de raciocínio do modelo, podemos sentir que, apesar do tamanho relativamente pequeno dos parâmetros do QwQ-32B, ele ainda mostra um processo de raciocínio e análise muito "difícil" quando confrontado com um problema de raciocínio lógico complexo. O modelo executa muitos cálculos lógicos e deduções de probabilidade em segundo plano antes de finalmente chegar à conclusão correta.
Após a série acima de testes de QI rigorosos e detalhados, podemos concluir preliminarmente que a versão quantificada do modelo QwQ-32B de 4 bits demonstrou um desempenho geral impressionante, especialmente em raciocínio lógico e questionários, e superou outros modelos de sua classe. É razoável acreditar que o desempenho da versão não quantificada do QwQ-32B será ainda melhor. Relatório de avaliação de desempenho do modelo 32B Full Blood Edition O QwQ-32B fornece dados e análises de desempenho mais abrangentes. Portanto, podemos basicamente julgar que a promoção de desempenho feita pela equipe do Alibaba QwQ no lançamento do modelo QwQ-32B não é exagerada, e o QwQ-32B é, de fato, um excelente novo modelo de inferência, que alcança a força de competir com o modelo DeepSeek-R1 de 671 bilhões de parâmetros com uma escala de parâmetros de 32 bilhões de parâmetros.
O rápido crescimento dos grandes modelos domésticos de código aberto demonstra plenamente a vigorosa inovação e o enorme potencial de desenvolvimento da China no campo da tecnologia de IA.
O que é ainda melhor é que a versão QwQ-32B 32B do modelo requer apenas uma placa gráfica com 24 GB de RAM para executá-lo sem problemas e em velocidades impressionantes. Embora há alguns anos a execução de um modelo de grande escala de alto desempenho como esse exigisse milhões de dólares em equipamentos especializados, agora, graças aos avanços tecnológicos como o QwQ-32B e o Ollama, os usuários podem implantá-lo e experimentá-lo localmente em um PC de US$ 10.000. O lançamento do modelo QwQ-32B sinaliza que os modelos de IA de alto desempenho estão se tornando cada vez mais populares, e a era da "IA para todos" está se acelerando, e a tecnologia de IA de alto desempenho terá uma perspectiva de aplicação mais ampla em dispositivos terminais pessoais e em vários setores.
Agora é o melhor momento para agir, explorar e utilizar totalmente o poder do QwQ-32B! Vamos abraçar juntos o futuro brilhante da tecnologia de IA!
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...