Introdução geral
O VideoChat é um projeto humano digital de interação por voz em tempo real baseado em tecnologia de código aberto, compatível com esquemas de voz de ponta a ponta (GLM-4-Voice - THG) e esquemas em cascata (ASR-LLM-TTS-THG). O projeto permite que os usuários personalizem a imagem e o timbre do ser humano digital e suporta clonagem de timbre e sincronização labial, saída de streaming de vídeo e latência do primeiro pacote de até 3 segundos. Os usuários podem experimentar sua funcionalidade por meio de demonstrações on-line ou implantá-lo e usá-lo localmente por meio de documentação técnica detalhada.
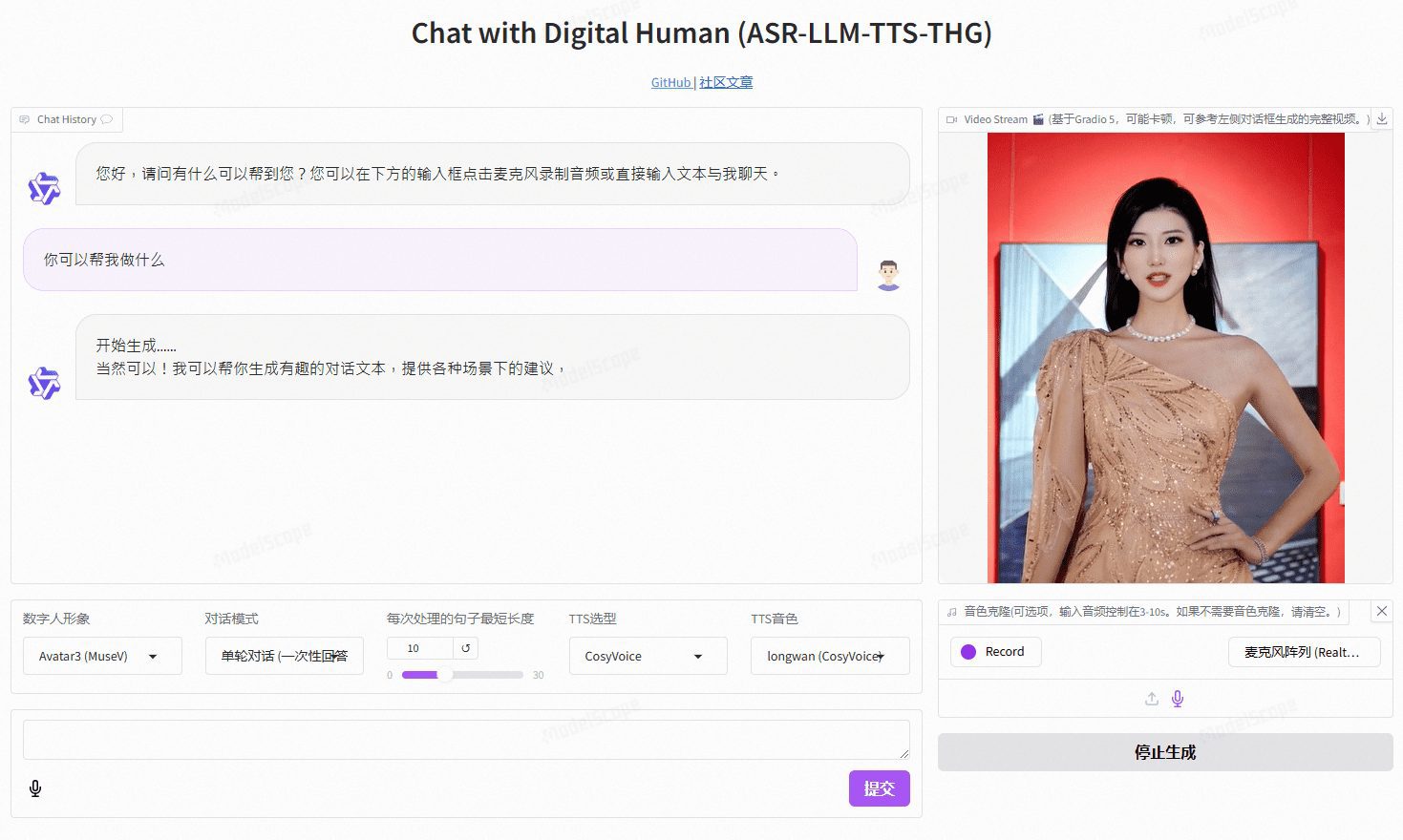
Endereço de demonstração: https://www.modelscope.cn/studios/AI-ModelScope/video_chat
Lista de funções
- Interação de voz em tempo real: suporte para soluções de voz de ponta a ponta e soluções em cascata
- Imagem e tom personalizados: os usuários podem personalizar a aparência e o som da pessoa digital de acordo com suas necessidades
- Clonagem de voz: suporta a clonagem da voz do usuário para proporcionar uma experiência de voz personalizada
- Baixa latência: a latência do primeiro pacote é tão baixa quanto 3 segundos para garantir uma experiência de interação tranquila
- Projeto de código aberto: com base na tecnologia de código aberto, os usuários podem modificar e ampliar livremente a função
Usando a Ajuda
Processo de instalação
- Configuração do ambiente
- Sistema operacional: Ubuntu 22.04
- Versão do Python: 3.10
- Versão CUDA: 12.2
- Versão do Torch: 2.1.2
- projeto de clonagem
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - Criação de um ambiente virtual e instalação de dependências
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - Faça o download do arquivo de pesos
- Recomendamos o uso do CreateSpace para fazer o download, configuramos o git lfs para rastrear os arquivos de peso
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - Início dos serviços
python app.py
Processo de uso
- Configuração da API-KEY::
- Se o desempenho da máquina local for limitado, você poderá usar a API Qwen e a API CosyVoice fornecidas pela grande plataforma de serviços de modelo da Aliyun, a Hundred Refine, no
app.pyConfigure a API-KEY na seção
- Se o desempenho da máquina local for limitado, você poderá usar a API Qwen e a API CosyVoice fornecidas pela grande plataforma de serviços de modelo da Aliyun, a Hundred Refine, no
- inferência local::
- Se você não usar a API-KEY, poderá usá-la no
src/llm.pyresponder cantandosrc/tts.pyConfigure o método de inferência local para remover o código de chamada de API desnecessário.
- Se você não usar a API-KEY, poderá usá-la no
- Início dos serviços::
- estar em movimento
python app.pyInicie o serviço.
- estar em movimento
- Personalização da persona digital::
- existir
/data/video/Catálogo para adicionar um vídeo gravado da imagem humana digital. - modificações
/src/thg.pyna avatar_list da classe Muse_Talk, adicionando o nome da imagem e bbox_shift. - existir
app.pyDepois de adicionar o nome da persona digital ao avatar_name no Gradio, reinicie o serviço e aguarde a conclusão da inicialização.
- existir
Procedimento de operação detalhado
- Imagem e tom personalizados: em
/data/video/para adicionar o vídeo gravado da imagem humana digital ao diretóriosrc/thg.pymodificaçãoConversa sobre museusclasselista_de_avataresadicione o nome da imagem ebbox_shiftParâmetros. - clonagem de fala: em
app.pyConfiguração médiaCosyVoice APIou usandoBorda_TTSExecutar raciocínio local. - Soluções de voz de ponta a ponta: Uso
GLM-4-Vozpara fornecer geração e reconhecimento de fala eficientes.
- Visite o endereço do serviço implantado localmente e acesse a interface do Gradio.
- Selecione ou carregue um vídeo personalizado de persona digital.
- Configure a função de clone de voz para carregar a amostra de voz de um usuário.
- Inicie a interação de voz em tempo real e experimente os recursos de diálogo de baixa latência.