Amphion MaskGCT: modelo de clonagem de texto para fala com amostragem zero (pacote de implantação local com um clique)

Introdução geral
O MaskGCT (Masked Generative Codec Transformer) é um modelo de conversão de texto em fala (TTS) totalmente não-autoregressivo introduzido em conjunto pela Funky Maru Technology e pela Universidade Chinesa de Hong Kong. O modelo elimina a necessidade de informações explícitas de alinhamento de texto para fala e adota uma abordagem de geração de duas fases, primeiro prevendo a codificação semântica a partir do texto e, em seguida, gerando a codificação acústica a partir da codificação semântica. O MaskGCT tem bom desempenho na tarefa de TTS de amostra zero, fornecendo saída de fala de alta qualidade, semelhante e fácil de entender.
Produto Beta Público: Funmaru Chiyo, ferramenta de tradução multilíngue de clonagem de voz e vídeo
Tese: https://arxiv.org/abs/2409.00750
-1")
Demonstração on-line: https://huggingface.co/spaces/amphion/maskgct
Lista de funções
- Conversão de texto em fala (TTS)Texto de entrada: converte o texto de entrada em saída de fala.
- codificação semânticaCodificação semântica: converte a fala em codificação semântica para processamento subsequente.
- código acústicoCodificação semântica: converta a codificação semântica em codificação acústica e reconstrua a forma de onda de áudio.
- aprendizado de amostra zeroSíntese de fala de alta qualidade sem informações de alinhamento explícitas.
- Modelo de pré-treinamentoUma ampla variedade de modelos pré-treinados está disponível para dar suporte à implantação e ao uso rápidos.
Usando a Ajuda
Processo de instalação
- projeto de clonagem::
git clone https://github.com/open-mmlab/Amphion.git - Criação de um ambiente e instalação de dependências::
bash ./models/tts/maskgct/env.sh
Processo de uso
- Download do modelo pré-treinadoOs modelos pré-treinados necessários podem ser baixados do HuggingFace:
from huggingface_hub import hf_hub_download # 下载语义编码模型 semantic_code_ckpt = hf_hub_download("amphion/MaskGCT", filename="semantic_codec/model.safetensors") # 下载声学编码模型 codec_encoder_ckpt = hf_hub_download("amphion/MaskGCT", filename="acoustic_codec/model.safetensors") codec_decoder_ckpt = hf_hub_download("amphion/MaskGCT", filename="acoustic_codec/model_1.safetensors") # 下载TTS模型 t2s_model_ckpt = hf_hub_download("amphion/MaskGCT", filename="t2s_model/model.safetensors") - Gerar discursoUse o código a seguir para gerar fala a partir de texto:
# 导入必要的库 from amphion.models.tts.maskgct import MaskGCT # 初始化模型 model = MaskGCT() # 输入文本 text = "你好,欢迎使用MaskGCT模型。" # 生成语音 audio = model.text_to_speech(text) # 保存生成的语音 with open("output.wav", "wb") as f: f.write(audio) - treinamento de modelosSe você precisar treinar seu próprio modelo, poderá consultar os scripts de treinamento e os arquivos de configuração do projeto para a preparação de dados e o treinamento do modelo.
advertência
- Configuração do ambienteVerifique se todas as bibliotecas dependentes necessárias estão instaladas e se as variáveis de ambiente estão configuradas corretamente.
- Preparação de dadosTreinamento com dados de fala de alta qualidade para uma melhor síntese de fala.
- Otimização de modelosAjuste os parâmetros do modelo e as estratégias de treinamento para obter o desempenho ideal de acordo com cenários de aplicativos específicos.
Tutorial de implantação local (com instalador local de um clique)
Há alguns dias, outro modelo de IA de conversão de texto em fala não autorregressivo, o MaskGCT, abriu seu código-fonte. Assim como o modelo F5-TTS, que também é não autorregressivo, o modelo MaskGCT é treinado no conjunto de dados Emilia de 100.000 horas e é proficiente na síntese entre idiomas de seis idiomas, a saber, chinês, inglês, japonês, coreano, francês e alemão. O conjunto de dados Emilia é um dos maiores e mais diversificados conjuntos de dados de fala multilíngue de alta qualidade do mundo.
Desta vez, compartilharemos como implantar o projeto MaskGCT localmente para que sua placa de vídeo volte a funcionar.
Instalação de dependências básicas
Antes de mais nada, certifique-se de que o Python 3.11 esteja instalado localmente, e você pode fazer o download do pacote no site oficial do Python.
python.org
Clonagem subsequente de projetos oficiais.
git clone https://github.com/open-mmlab/Amphion.git
São fornecidos scripts oficiais de shell de instalação baseados em Linux:
pip install setuptools ruamel.yaml tqdm
pip install tensorboard tensorboardX torch==2.0.1
pip install transformers===4.41.1
pip install -U encodec
pip install black==24.1.1
pip install oss2
sudo apt-get install espeak-ng
pip install phonemizer
pip install g2p_en
pip install accelerate==0.31.0
pip install funasr zhconv zhon modelscope
# pip install git+https://github.com/lhotse-speech/lhotse
pip install timm
pip install jieba cn2an
pip install unidecode
pip install -U cos-python-sdk-v5
pip install pypinyin
pip install jiwer
pip install omegaconf
pip install pyworld
pip install py3langid==0.2.2 LangSegment
pip install onnxruntime
pip install pyopenjtalk
pip install pykakasi
pip install -U openai-whisper
Aqui o autor converte o arquivo de dependência requirements.txt para Windows:
setuptools
ruamel.yaml
tqdm
transformers===4.41.1
encodec
black==24.1.1
oss2
phonemizer
g2p_en
accelerate==0.31.0
funasr
zhconv
zhon
modelscope
timm
jieba
cn2an
unidecode
cos-python-sdk-v5
pypinyin
jiwer
omegaconf
pyworld
py3langid==0.2.2
LangSegment
onnxruntime
pyopenjtalk
pykakasi
openai-whisper
json5
Executar comando:
pip3 install -r requirements.txt
Basta instalar as dependências.
Instale o onnxruntime-gpu.
pip3 install onnxruntime-gpu
Instalação do conjunto de três peças da tocha.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Configuração do Windows espeak-ng
Como o projeto MaskGCT depende do software espeak para seu back-end, ele precisa ser configurado localmente. O eSpeak é um sintetizador de texto para fala (TTS) compacto e de código aberto que suporta vários idiomas e sotaques. Ele usa uma abordagem de "síntese de pico de ressonância" que permite que vários idiomas sejam fornecidos em um espaço reduzido. A fala é clara e pode ser usada em altas velocidades, mas não é tão natural e suave quanto a de sintetizadores maiores baseados em gravações de fala humana, e o MaskGCT se baseia na síntese do espeak com raciocínio secundário.
Primeiro, execute o comando para instalar o espeak:
winget install espeak
Se não for possível instalá-lo, você também pode fazer o download do instalador e instalá-lo manualmente:
https://sourceforge.net/projects/espeak/files/espeak/espeak-1.48/setup_espeak-1.48.04.exe/download
Em seguida, faça o download do instalador do espeak-ng:
https://github.com/espeak-ng/espeak-ng/releases
Faça o download e clique duas vezes para instalar.
Em seguida, copie C:\Program Files\eSpeak NG\libespeak-ng.dll para o diretório C:\Program Files (x86)\eSpeak\command_line.
Em seguida, renomeie libespeak-ng.dll para espeak-ng.dll
Por fim, basta configurar o diretório C:\Program Files (x86)\eSpeak\command_line para a variável de ambiente.
Raciocínio local do MaskGCT
Com tudo isso configurado, escreva o script de inferência local_test.py:
from models.tts.maskgct.maskgct_utils import *
from huggingface_hub import hf_hub_download
import safetensors
import soundfile as sf
import os
import argparse
os.environ['HF_HOME'] = os.path.join(os.path.dirname(__file__), 'hf_download')
print(os.path.join(os.path.dirname(__file__), 'hf_download'))
parser = argparse.ArgumentParser(description="GPT-SoVITS api")
parser.add_argument("-p", "--prompt_text", type=str, default="说得好像您带我以来我考好过几次一样")
parser.add_argument("-a", "--audio", type=str, default="./说得好像您带我以来我考好过几次一样.wav")
parser.add_argument("-t", "--text", type=str, default="你好")
parser.add_argument("-l", "--language", type=str, default="zh")
parser.add_argument("-lt", "--target_language", type=str, default="zh")
args = parser.parse_args()
if __name__ == "__main__":
# download semantic codec ckpt
semantic_code_ckpt = hf_hub_download("amphion/MaskGCT", filename="semantic_codec/model.safetensors")
# download acoustic codec ckpt
codec_encoder_ckpt = hf_hub_download("amphion/MaskGCT", filename="acoustic_codec/model.safetensors")
codec_decoder_ckpt = hf_hub_download("amphion/MaskGCT", filename="acoustic_codec/model_1.safetensors")
# download t2s model ckpt
t2s_model_ckpt = hf_hub_download("amphion/MaskGCT", filename="t2s_model/model.safetensors")
# download s2a model ckpt
s2a_1layer_ckpt = hf_hub_download("amphion/MaskGCT", filename="s2a_model/s2a_model_1layer/model.safetensors")
s2a_full_ckpt = hf_hub_download("amphion/MaskGCT", filename="s2a_model/s2a_model_full/model.safetensors")
# build model
device = torch.device("cuda")
cfg_path = "./models/tts/maskgct/config/maskgct.json"
cfg = load_config(cfg_path)
# 1. build semantic model (w2v-bert-2.0)
semantic_model, semantic_mean, semantic_std = build_semantic_model(device)
# 2. build semantic codec
semantic_codec = build_semantic_codec(cfg.model.semantic_codec, device)
# 3. build acoustic codec
codec_encoder, codec_decoder = build_acoustic_codec(cfg.model.acoustic_codec, device)
# 4. build t2s model
t2s_model = build_t2s_model(cfg.model.t2s_model, device)
# 5. build s2a model
s2a_model_1layer = build_s2a_model(cfg.model.s2a_model.s2a_1layer, device)
s2a_model_full = build_s2a_model(cfg.model.s2a_model.s2a_full, device)
# load semantic codec
safetensors.torch.load_model(semantic_codec, semantic_code_ckpt)
# load acoustic codec
safetensors.torch.load_model(codec_encoder, codec_encoder_ckpt)
safetensors.torch.load_model(codec_decoder, codec_decoder_ckpt)
# load t2s model
safetensors.torch.load_model(t2s_model, t2s_model_ckpt)
# load s2a model
safetensors.torch.load_model(s2a_model_1layer, s2a_1layer_ckpt)
safetensors.torch.load_model(s2a_model_full, s2a_full_ckpt)
# inference
prompt_wav_path = args.audio
save_path = "output.wav"
prompt_text = args.prompt_text
target_text = args.text
# Specify the target duration (in seconds). If target_len = None, we use a simple rule to predict the target duration.
target_len = None
maskgct_inference_pipeline = MaskGCT_Inference_Pipeline(
semantic_model,
semantic_codec,
codec_encoder,
codec_decoder,
t2s_model,
s2a_model_1layer,
s2a_model_full,
semantic_mean,
semantic_std,
device,
)
recovered_audio = maskgct_inference_pipeline.maskgct_inference(
prompt_wav_path, prompt_text, target_text,args.language,args.target_language, target_len=target_len
)
sf.write(save_path, recovered_audio, 24000)
A primeira inferência fará o download de 10 Gs de modelos no diretório hf_download.
O processo de raciocínio ocupa 11 G de memória de vídeo:
-1")
Se você tiver menos de 11 G de memória de vídeo, certifique-se de ativar a política de fallback da memória do sistema no painel de controle da Nvidia para aumentar a memória de vídeo por meio da memória do sistema:
-2")
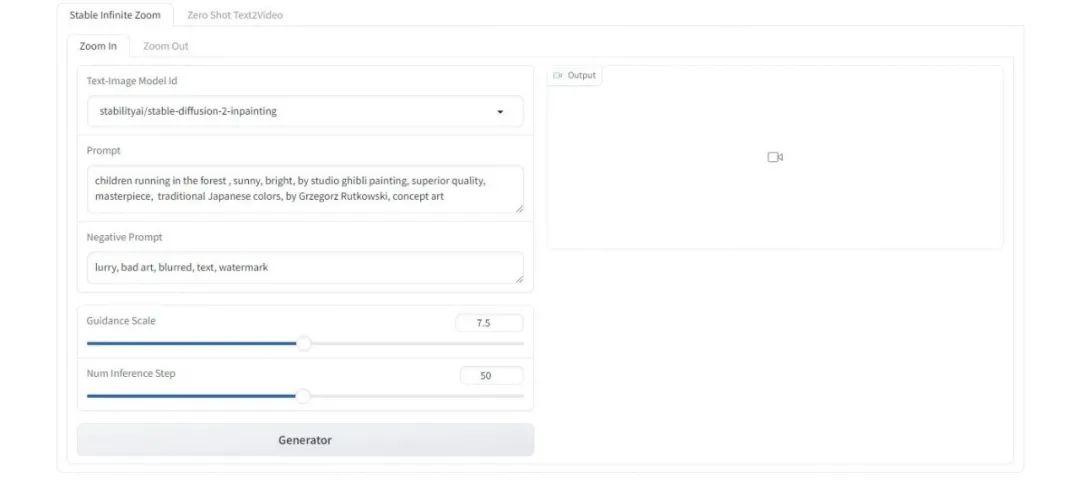
Se desejar, você também pode escrever uma interface webui simples com base no gradio, app.py:.
import os
import gc
import re
import gradio as gr
import numpy as np
import subprocess
os.environ['HF_HOME'] = os.path.join(os.path.dirname(__file__), 'hf_download')
# 设置HF_ENDPOINT环境变量
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
reference_wavs = ["请选择参考音频或者自己上传"]
for name in os.listdir("./参考音频/"):
reference_wavs.append(name)
def change_choices():
reference_wavs = ["请选择参考音频或者自己上传"]
for name in os.listdir("./参考音频/"):
reference_wavs.append(name)
return {"choices":reference_wavs, "__type__": "update"}
def change_wav(audio_path):
text = audio_path.replace(".wav","").replace(".mp3","").replace(".WAV","")
# text = replace_speaker(text)
return f"./参考音频/{audio_path}",text
def do_cloth(gen_text_input,ref_audio_input,model_choice_text,model_choice_re,ref_text_input):
cmd = fr'.\py311_cu118\python.exe local_test.py -t "{gen_text_input}" -p "{ref_text_input}" -a "{ref_audio_input}" -l {model_choice_re} -lt {model_choice_text} '
print(cmd)
res = subprocess.Popen(cmd)
res.wait()
return "output.wav"
with gr.Blocks() as app_demo:
gr.Markdown(
"""
项目地址:https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
整合包制作:刘悦的技术博客 https://space.bilibili.com/3031494
"""
)
gen_text_input = gr.Textbox(label="生成文本", lines=4)
model_choice_text = gr.Radio(
choices=["zh", "en"], label="生成文本语种", value="zh",interactive=True)
wavs_dropdown = gr.Dropdown(label="参考音频列表",choices=reference_wavs,value="选择参考音频或者自己上传",interactive=True)
refresh_button = gr.Button("刷新参考音频")
refresh_button.click(fn=change_choices, inputs=[], outputs=[wavs_dropdown])
ref_audio_input = gr.Audio(label="Reference Audio", type="filepath")
ref_text_input = gr.Textbox(
label="Reference Text",
info="Leave blank to automatically transcribe the reference audio. If you enter text it will override automatic transcription.",
lines=2,
)
model_choice_re = gr.Radio(
choices=["zh", "en"], label="参考音频语种", value="zh",interactive=True
)
wavs_dropdown.change(change_wav,[wavs_dropdown],[ref_audio_input,ref_text_input])
generate_btn = gr.Button("Synthesize", variant="primary")
audio_output = gr.Audio(label="Synthesized Audio")
generate_btn.click(do_cloth,[gen_text_input,ref_audio_input,model_choice_text,model_choice_re,ref_text_input],[audio_output])
def main():
global app_demo
print(f"Starting app...")
app_demo.launch(inbrowser=True)
if __name__ == "__main__":
main()
E, é claro, não se esqueça de instalar a dependência do gradio:
pip3 install -U gradio
O efeito de execução é parecido com o seguinte:
-3")
observações finais
A vantagem do modelo MaskGCT é que o nível de tom e ritmo é excelente, comparável à voz real; a desvantagem também é muito óbvia, o custo de operação é alto, a otimização do nível de engenharia é insuficiente. A página inicial do projeto MaskGCT tem sua versão comercial do modelo de entrada, de acordo com essa inferência, o funcionário não deve ter muita força na versão de código aberto e, por fim, o pacote de integração de uma chave é apresentado com todas as pessoas para aproveitar o mesmo.
Kit de implantação de um clique do MaskGCT
https://pan.quark.cn/s/e74726b84c78
Cortesia de Ten Horsemen: https://pan.quark.cn/s/1a8428b6ff73 Código do extrato: kind
https://drive.google.com/drive/folders/11JHi5FnusZA34Q6zS3b3Xj5MiLpYKsLu
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...