
Ali Bailian fornece a API QwQ-32B gratuitamente, e 1 milhão de tokens são gratuitos para usá-la todos os dias!

Recentemente, a AliCloud Hundred Refinement Platform anunciou uma nova plataforma para QwQ-32B O Big Language Model abre interfaces de API e forneceAcesso gratuito a 1 milhão de tokens por diaO modelo QwQ-32B é uma tecnologia nova e interessante que reduz significativamente as barreiras para os usuários experimentarem a tecnologia de IA de ponta. Para os usuários que desejam experimentar o desempenho avançado do modelo QwQ-32B, mas estão limitados pela capacidade de computação do hardware local, chamar o modelo de nuvem por meio da interface API é definitivamente uma opção mais atraente.
Leitura recomendada para aqueles que não conhecem o QwQ-32B:Modelo pequeno, grande potência: QwQ-32B com parâmetro 1/20 para lutar contra o DeepSeek-R1 de sangue puro
Vantagens da interface API: quebra das limitações de hardware, poder de computação avançado na ponta dos dedos
Anteriormente, lançamos Implantação local de modelos grandes QwQ-32B: um guia fácil para PCs Além disso, os usuários que desejam experimentar modelos de linguagem em grande escala, como o QwQ-32B, geralmente precisam implantar equipamentos de computação de alto desempenho localmente. O requisito de hardware de 24 GB ou até mais de memória de vídeo geralmente impede que muitos usuários tenham acesso à experiência de IA. A interface de API fornecida pela plataforma Hundred Refine da AliCloud resolve esse problema de forma inteligente.
Ao chamar os modelos QwQ por meio da interface API, os usuários podem obter várias vantagens:
- Não há limite para configuração de hardware. Não há necessidade de implementar localmente hardware de alto desempenho, reduzindo o limite de uso. Até mesmo laptops finos e leves e até mesmo smartphones podem utilizar sem problemas o poderoso poder de modelagem da nuvem. Recomenda-se que os usuários usem uma placa gráfica com 24 G de memória de vídeo ou superior para obter uma experiência de execução de modelo local mais suave.
- Compatibilidade do sistema. A interface da API é independente do sistema operacional e multiplataforma. Não importa se está usando Windows, macOS ou Linux, você pode acessá-la facilmente.
- A versão Plus, mais potente. Os usuários podem experimentar a versão aprimorada do QwQ Plus, que supera a versão completa do QwQ-32B implantada localmente. A versão Plus, ou seja, a versão aprimorada do modelo de inferência QwQ para o Tongyi Qianqi, é baseada no modelo Qwen2.5 e treinada por aprendizado por reforço. Em comparação com a versão básica, a versão Plus obteve melhorias significativas na capacidade de inferência do modelo e na avaliação das principais métricas (por exemplo, AIME 24/25, livecodebench) e algumas métricas gerais (por exemplo, IFEval, LiveBench etc.), a versão Plus obteve o melhor desempenho. DeepSeek-R1 Versão completa do nível do modelo.
- Resposta de alta velocidade. A interface API permite tempos de resposta rápidos de 40-50 tokens/segundo. Isso significa que os usuários podem ter uma experiência interativa quase em tempo real, aumentando consideravelmente a eficiência.
Vale a pena mencionar que, além do AliCloud Hundred Refine, a plataforma de mobilidade in silico também fornece uma interface API para o modelo QwQ-32B. Se os usuários estiverem interessados na plataforma de fluxo in silico, eles podem consultar o artigo anterior. Neste artigo, apresentaremos principalmente como usar a interface de API fornecida pela plataforma Aliyun Hundred Refine.
Guia de acesso à API do Aliyun Hundred Refined: três etapas simples para começar!
A Hundred Refinement Platform da AliCloud fornece aos usuários da API do modelo da série QwQ 1 milhão de usuários diários tokens O crédito gratuito. Para a maioria dos usuários, esse valor é suficiente para a experiência e os testes diários. Os usuários só precisam concluir um registro e uma configuração simples para começar.
Abaixo estão as etapas resumidas para configurar a API do Aliyun Bai Lian QwQ Plus no lado do cliente:
1. obtenha a chave da API e o nome do modelo
Primeiro, visite o site AliCloud Hundred Refinement Platform e conclua o registro ou login.
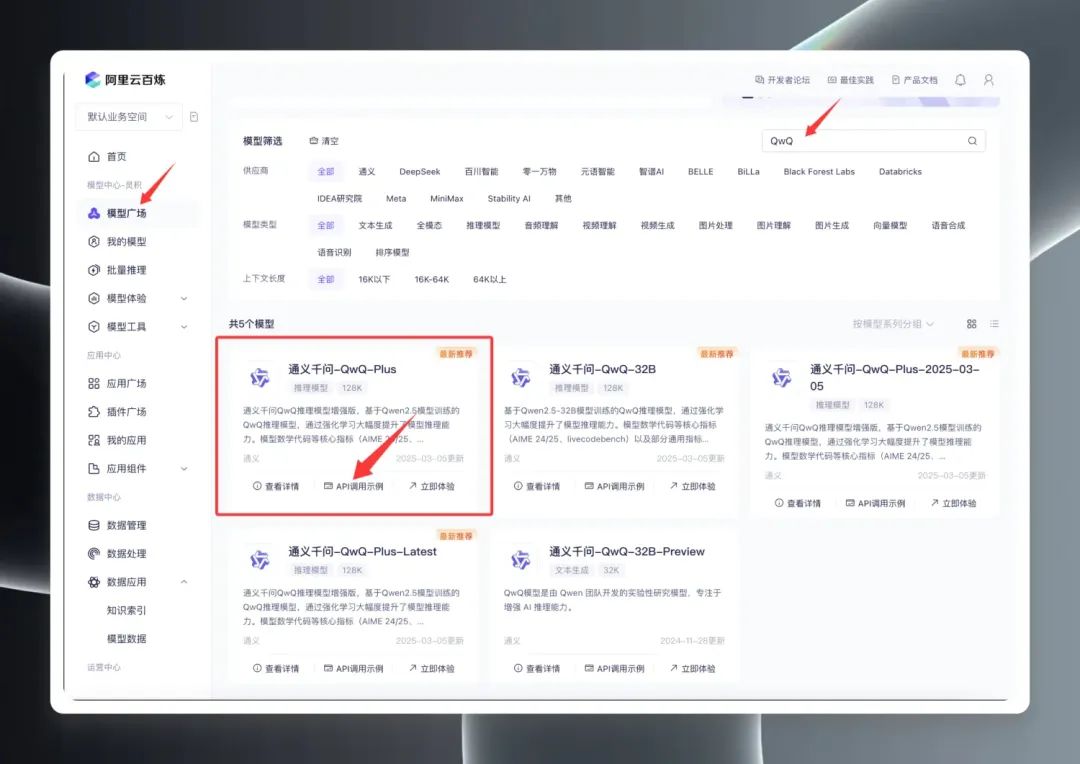
Uma vez conectado, procure por "QwQ" no Model Square para ver a linha de modelos QwQ. De fato, o Model Square exibe três versões principais: QwQ32B (versão oficial), QwQ32B-Preview (versão de visualização) e QwQ Plus (versão aprimorada, também conhecida como versão comercial).
Selecione "QwQ Plus (Enhanced)", clique em "API Call Examples" e, na nova página, localize o Nome do modelo qwq-plus.
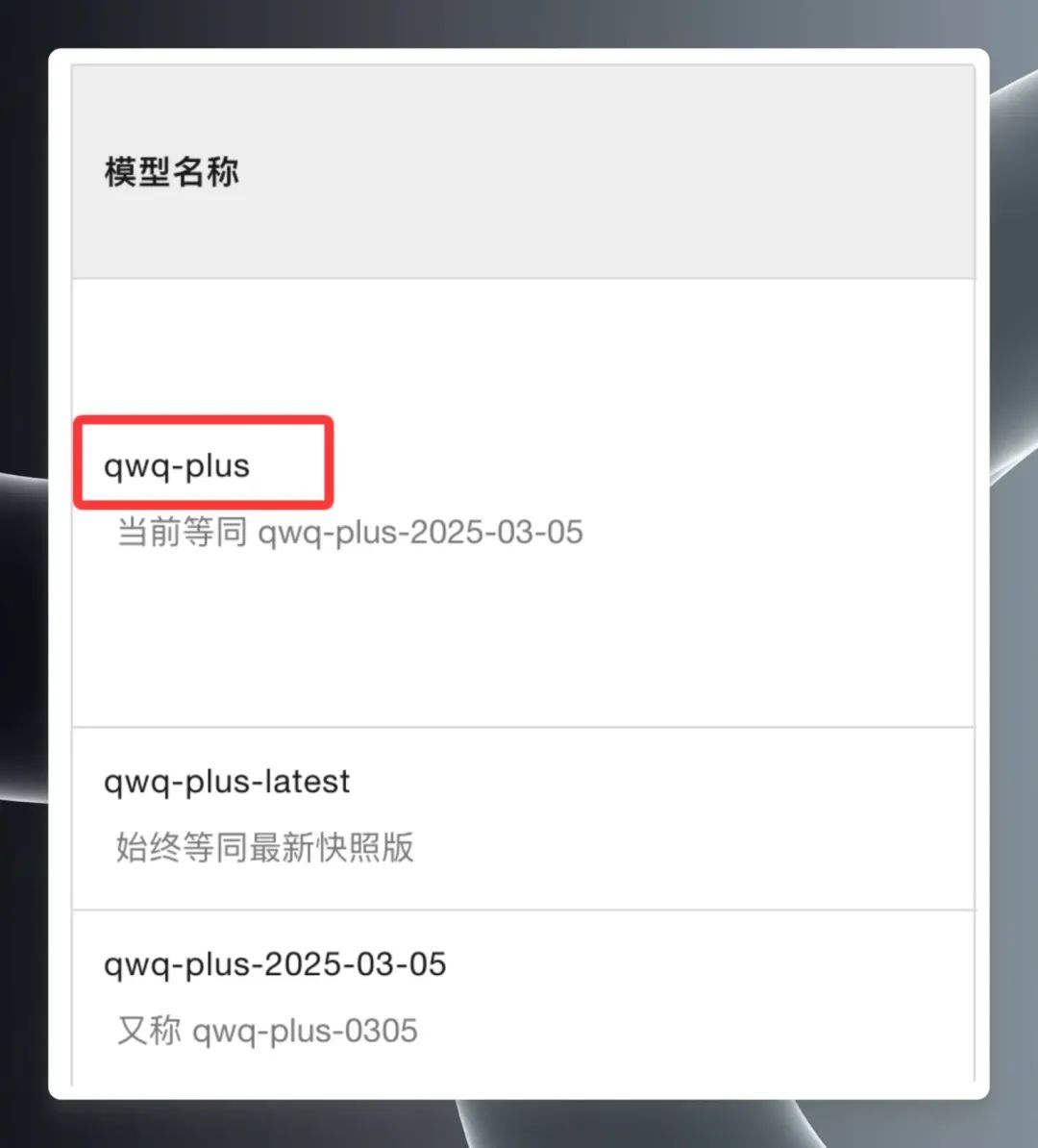
Em seguida, clique em "View My API Key" (Ver minha chave de API) no canto superior direito da página. Você precisa criar uma chave de API pela primeira vez; se já tiver criado uma, poderá visualizá-la e copiá-la diretamente. Chave da API.
2. configuração do cliente
este documento é baseado em Chatwise O cliente é usado como exemplo para fins de demonstração. Abra o software Chatwise, clique no avatar do usuário e vá para a tela "Settings" (Configurações).
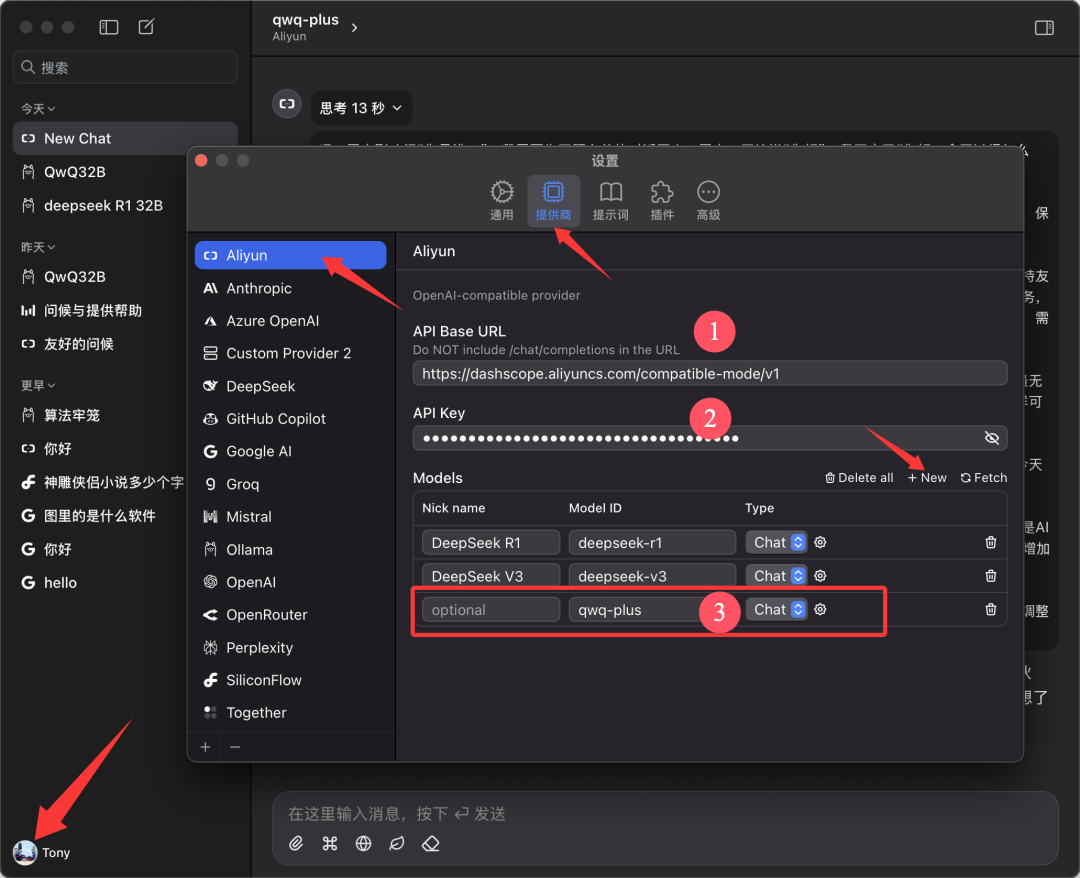
Localize "Aliyun" na lista de provedores; se não for encontrado, clique em "➕" na parte inferior para adicioná-lo.
Configure conforme mostrado na figura abaixo:
- URL da base da API.
https://bailian.aliyuncs.com(Geral) - Chave de API. Cole a API Key que você copiou na etapa anterior
- Modelos. Adicionar nome do modelo
qwq-plus(deve ser o nome)
3. iniciar a experiência
Retorne à tela principal do Chatwise e selecione o modelo "qwq-plus" no menu suspenso de seleção de modelos para iniciar sua experiência de diálogo.
Desempenho no mundo real: comparável ou melhor do que as implementações locais
Para verificar o desempenho real da API do QwQ Plus, realizamos um teste de comparação simples.
Teste de velocidade:
As medições mostram que a velocidade da interface API do QwQ Plus é excelente, com uma taxa estável de 40-50 tokens/segundo. Em comparação, a interface DeepSeek API do modelo R1, a taxa é significativamente mais lenta, com mais de 10 tokens/seg.
Teste de compatibilidade:
Os usuários também podem configurar e usar a API do QwQ Plus em um cliente como o CherryStudio, mas, durante o teste do CherryStudio, foi observado um problema em potencial: quando o modelo executa raciocínios complexos por um longo período, o CherryStudio pode consumir uma grande quantidade de recursos do sistema, e podem ocorrer reinicializações do software em alguns dispositivos configurados. No entanto, o uso do cliente Chatwise no mesmo ambiente de hardware não causou problemas semelhantes. Isso pode estar relacionado a diferenças nas estruturas de desenvolvimento dos diferentes clientes.
Comparação de competências:
Seguimos as perguntas anteriores de raciocínio lógico com a cor do chapéu e comparamos o desempenho do modelo local QwQ32 com o da API QwQ Plus.
Descrição do problema:
Há 5 pessoas em uma fila, cada uma com um chapéu vermelho ou azul. Elas podem ver os chapéus das pessoas à sua frente, mas não os seus próprios chapéus. O facilitador anuncia: "Há pelo menos um chapéu vermelho". Começando pela última pessoa, cada uma diz "sim" ou "não" (indicando se sabe ou não a cor de seu chapéu). Se a 5ª pessoa disser "não" e a 4ª pessoa disser "sim", encontre a distribuição de todas as cores possíveis de chapéu.
Desempenho local do modelo QwQ32:

O modelo local QwQ32 foi finalmente respondido com sucesso após duas tentativas, sendo que a segunda levou 196 segundos.
Desempenho da API do QwQ Plus:
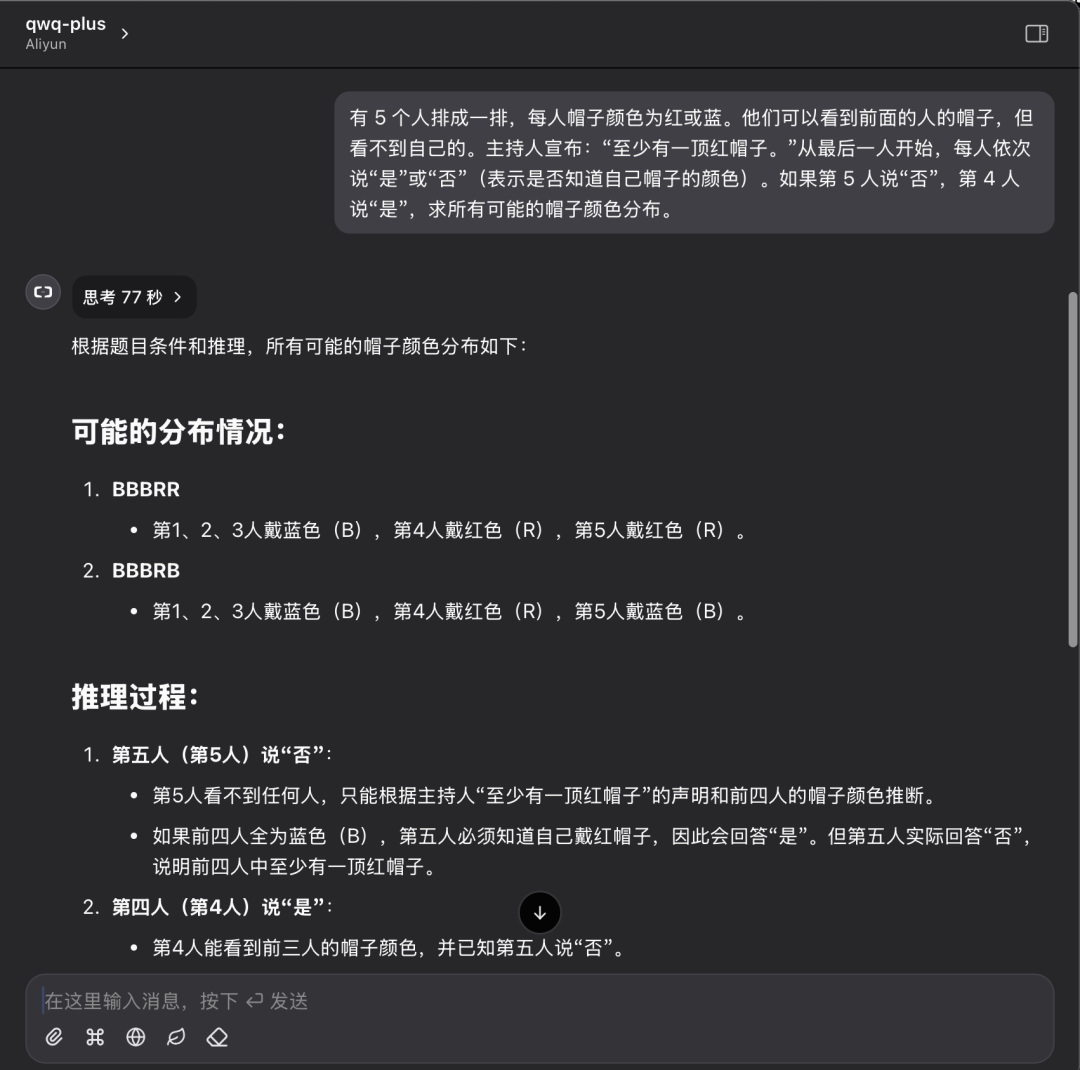
Desempenho da API do QwQ Plus na mesma pergunta: resposta correta única em 77 segundos.
Análise dos resultados dos testes:
Embora um único caso não seja suficiente para avaliar totalmente a capacidade do modelo, os resultados desse teste podem refletir visualmente a diferença entre o modelo implantado localmente e a solução de API em nuvem. Ao resolver problemas de raciocínio lógico, ambas as soluções podem dar respostas corretas, mas a API do QwQ Plus é melhor em termos de eficiência e clareza do processo de raciocínio, com tempo de raciocínio mais curto e menor consumo de tokens.
Adote a IA na nuvem para todos
A abertura gratuita da interface da API QwQ-32B na plataforma AliCloud Hundred Refine e o fornecimento de tokens gratuitos generosos é, sem dúvida, um passo importante para promover a popularidade da tecnologia de modelagem de linguagem grande. Com a interface API, os usuários podem experimentar facilmente o poder dos modelos de IA de alto desempenho na nuvem sem investir em custos de hardware caros. Seja você um desenvolvedor, pesquisador ou entusiasta de IA, agora você pode aproveitar ao máximo os recursos gratuitos fornecidos pelo Aliyun Hundred Refine para iniciar sua jornada de exploração de IA.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...