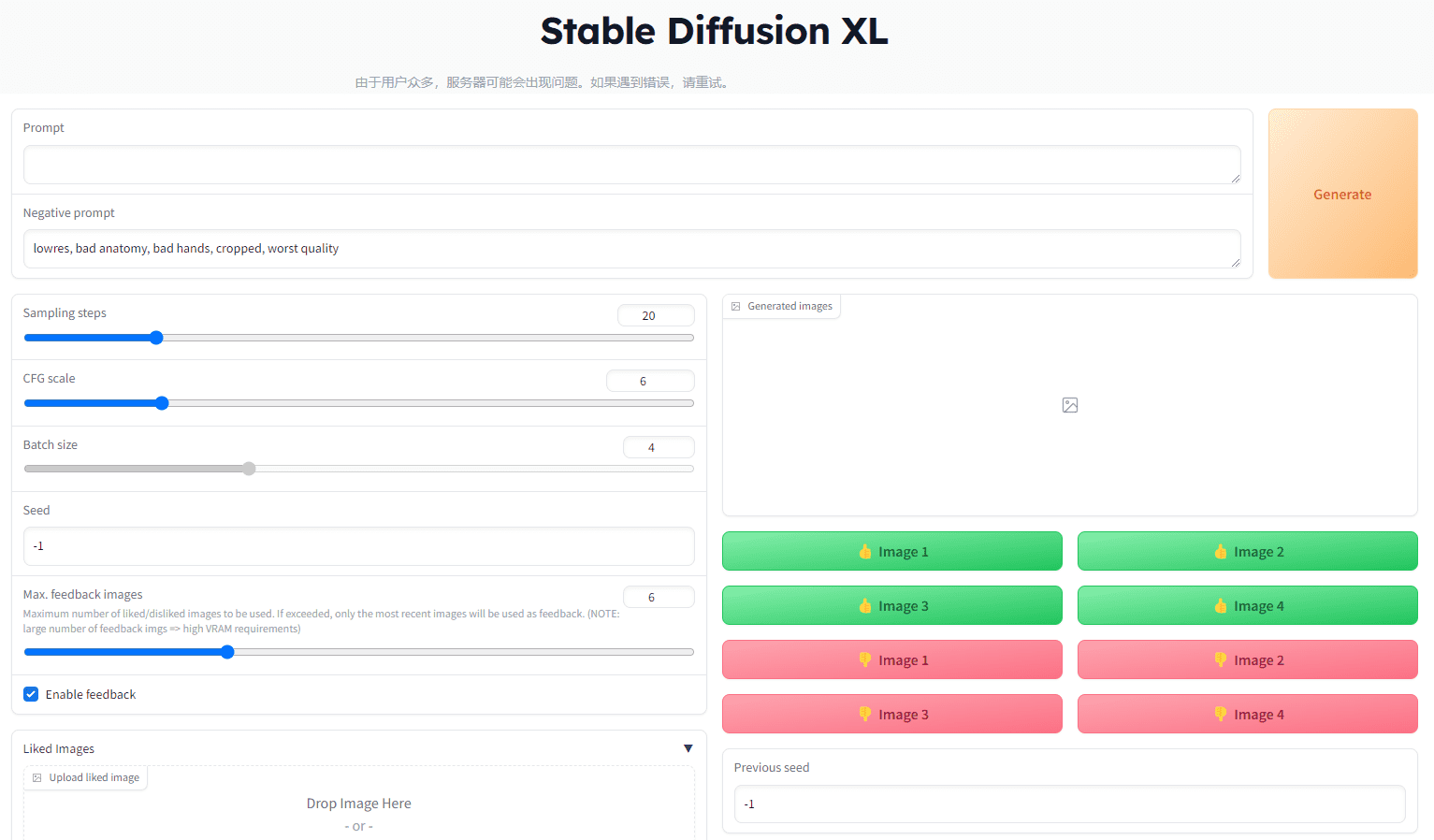
AivisSpeech: gerando software de síntese de fala japonesa emocionalmente rica

Introdução geral
O AivisSpeech é um software de síntese de fala japonesa baseado na interface de usuário do editor VOICEVOX, que integra o AivisSpeech Engine para gerar facilmente uma fala emocionalmente rica. O AivisSpeech integra o AivisSpeech Engine, o que facilita a geração de discursos emocionalmente ricos. O AivisSpeech é compatível com uma ampla gama de modelos de síntese de som, permitindo que os usuários gerem discursos japoneses de alta qualidade com operações simples. Disponível para Windows e macOS, e especialmente recomendado para Macs equipados com o Apple Silicon, o objetivo do AivisSpeech é tornar a tecnologia avançada de síntese de fala facilmente acessível a todos para contar histórias, transmitir notícias e muito mais.

Lista de funções
- Gerar um discurso japonês emocionalmente rico
- Suporta uma ampla gama de modelos de síntese de som
- Interface de usuário fácil de usar
- Compatível com os sistemas Windows e macOS
- Suporte a modelos de síntese áudio-vocal no formato AIVMX
- Fornece documentação detalhada e perguntas frequentes.
Usando a Ajuda
Processo de instalação
- Visite a página do AivisSpeech no GitHub para fazer o download da versão mais recente do instalador.
- Selecione o pacote de instalação correspondente de acordo com o sistema operacional (Windows ou macOS).
- Execute o instalador e siga as instruções para concluir a instalação.
Processo de uso
- Abra o software AivisSpeech e vá para a tela principal.
- No menu "Settings" (Configurações), selecione "Sound Synthesis Module Management" (Gerenciamento do módulo de síntese de som) para adicionar um modelo de síntese de som.
- Selecione o modelo de síntese de som desejado e clique no botão "Append" (Anexar).
- Digite o texto a ser sintetizado na interface principal e selecione a emoção e o estilo de voz apropriados.
- Clique no botão "Generate" (Gerar) e aguarde a conclusão da síntese de fala.
- Após a conclusão da síntese, você pode reproduzir, salvar ou exportar o arquivo de fala gerado.
Funções detalhadas
- Gerar um discurso japonês emocionalmente ricoVoz: Ao selecionar diferentes emoções e estilos de voz, os usuários podem gerar uma voz que atenda a necessidades emocionais específicas.
- Suporta uma ampla gama de modelos de síntese de somAivisSpeech suporta modelos de síntese acústica no formato AIVMX, permitindo que os usuários adicionem e gerenciem diferentes modelos conforme necessário.
- Interface de usuário fácil de usarA interface do software foi projetada para ser simples e intuitiva, para que os usuários possam começar facilmente.
- Compatível com os sistemas Windows e macOSAivisSpeech é fácil de instalar e usar, tanto para usuários do Windows quanto do macOS.
- Fornece documentação detalhada e perguntas frequentes.Os usuários podem encontrar instruções detalhadas e respostas a perguntas frequentes na documentação oficial para ajudar a resolver rapidamente os problemas de uso.
problemas comuns
- Como faço para adicionar um novo modelo de síntese de som?
- No menu "Settings" (Configurações), selecione "Sound Synthesis Modelling" (Modelagem de síntese de som), clique no botão "Append" (Anexar) e selecione o arquivo de modelo que deseja adicionar.
- Quais sistemas operacionais são compatíveis com o software?
- O AivisSpeech é compatível com o Windows 10, Windows 11 e macOS 13 Ventura e superior.
- Para quais formatos os arquivos de voz gerados podem ser exportados?
- Os arquivos de voz gerados podem ser exportados para o formato WAV para facilitar a edição e o uso posterior.
- Como faço para resolver os problemas encontrados durante a instalação?
- Consulte o guia de instalação e as perguntas frequentes na documentação oficial ou envie um problema na página do GitHub para obter ajuda.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados

Nenhum comentário...