AI Engineering Academy: 2.2 Implementação básica do RAG
apresentar (alguém para um emprego etc.)
Geração aprimorada de pesquisa (RAG) é uma técnica poderosa que combina os benefícios de modelos de linguagem grandes com a capacidade de recuperar informações relevantes de uma base de conhecimento. Essa abordagem melhora a qualidade e a precisão das respostas geradas, baseando-as em informações específicas recuperadas.a Este caderno tem o objetivo de fornecer uma introdução clara e concisa ao RAG e é adequado para iniciantes que desejam entender e implementar essa técnica.
Processo RAG
início
Caderno de anotações
Você pode executar o Notebook fornecido neste repositório. https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
aplicativo de bate-papo
- Instalar dependências:
pip install -r requirements.txt - Execute o aplicativo:
python app.py - Importação dinâmica de dados:
python app.py --ingest --data_dir /path/to/documents
servidor (computador)
Use o seguinte comando para executar o servidor:
python server.py
O servidor fornece dois pontos de extremidade:
/api/ingest/api/query
locomotiva
Os modelos de linguagem tradicionais geram texto com base em padrões aprendidos com dados de treinamento. No entanto, eles podem ter dificuldades para fornecer respostas precisas quando confrontados com consultas que exigem informações específicas, atualizadas ou especializadas. O RAG aborda essa limitação introduzindo uma etapa de recuperação que fornece ao modelo de linguagem o contexto relevante para gerar respostas mais precisas.
Detalhes metodológicos
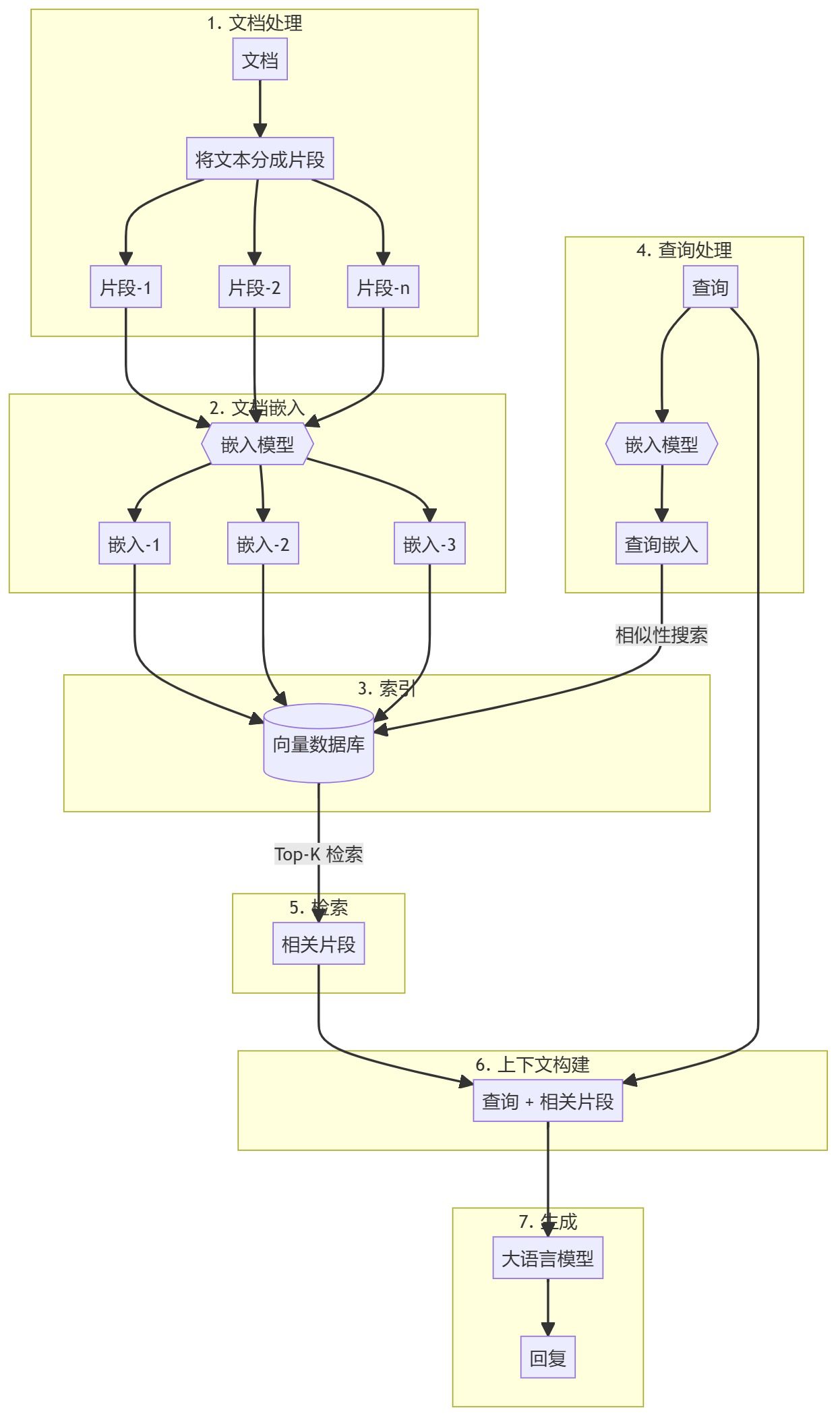
Pré-processamento de documentos e criação de armazenamento de vetores
- Agrupamento de documentosPré-processamento: pré-processe e divida os documentos da base de conhecimento (por exemplo, PDFs, artigos) em partes gerenciáveis. Isso cria um corpus pesquisável para processos de recuperação eficientes.
- Gerar incorporaçãoCada bloco é convertido em uma representação vetorial usando uma incorporação pré-treinada (por exemplo, a incorporação da OpenAI). Em seguida, esses documentos são armazenados em um banco de dados de vetores (por exemplo, Qdrant) para uma pesquisa de similaridade eficiente.
Fluxo de trabalho do Retrieval Augmentation Generation (RAG)
- Entrada de consulta:: Os usuários fornecem consultas que precisam ser respondidas.
- etapa de pesquisaIncorporação: incorpora a consulta como um vetor usando o mesmo modelo de incorporação dos documentos. Em seguida, executa uma pesquisa de similaridade no banco de dados de vetores para encontrar o bloco de documentos mais relevante.
- Etapas de geraçãoModelo de linguagem: os blocos de documentos recuperados são passados como contexto adicional para um modelo de linguagem grande (por exemplo, GPT-4). O modelo usa esse contexto para gerar respostas mais precisas e relevantes.
Principais recursos do RAG
- relevância contextualO modelo RAG pode gerar respostas contextualmente mais relevantes e precisas ao gerar respostas com base nas informações reais recuperadas.
- escalabilidadeA etapa de recuperação pode ser estendida para lidar com grandes bases de conhecimento, permitindo que o modelo extraia conteúdo de grandes quantidades de informações.
- Flexibilidade de casos de usoRAG pode ser adaptado a uma variedade de cenários de aplicativos, incluindo perguntas e respostas, geração de resumos, sistemas de recomendação e muito mais.
- Precisão aprimorada:: A combinação de recuperação e geração geralmente produz resultados mais precisos, especialmente para consultas que exigem informações específicas ou frias.
Vantagens desse método
- Combinando as vantagens da recuperação e da geraçãoRAG: O RAG combina de forma eficaz uma abordagem baseada em recuperação com um modelo generativo para a descoberta precisa de fatos e a geração de linguagem natural.
- Tratamento aprimorado de consultas de cauda longaO método tem um desempenho particularmente bom para consultas que exigem informações específicas e incomuns.
- Adaptação de domínioMecanismos de recuperação podem ser ajustados para domínios específicos para garantir que as respostas geradas sejam baseadas nas informações mais relevantes e precisas específicas do domínio.
chegar a um veredicto
O Retrieval-Augmented Generation (RAG) é uma fusão inovadora de tecnologias de recuperação e geração que aprimora efetivamente os recursos de um modelo de linguagem, baseando o resultado em informações externas relevantes. Essa abordagem é particularmente valiosa em cenários de resposta que exigem respostas precisas e conscientes do contexto (por exemplo, suporte ao cliente, pesquisa acadêmica etc.). À medida que a IA continua a evoluir, o RAG se destaca por seu potencial de criar sistemas de IA mais confiáveis e sensíveis ao contexto.
pré-condições
- Preferencialmente Python 3.11
- Jupyter Notebook ou JupyterLab
- Chave da API do LLM
- Qualquer LLM pode ser usado. Neste notebook, usamos o OpenAI e o GPT-4o-mini.
Com essas etapas, você pode implementar um sistema RAG básico que incorpora informações atualizadas do mundo real para aumentar a eficiência dos modelos de linguagem em uma variedade de aplicativos.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...