Introdução geral
Discurso do peixe O Derived Project Fish Agent é um sistema revolucionário de clonagem de fala de IA de ponta a ponta, desenvolvido com base na arquitetura do modelo V0.1 3B. Como um sistema de processamento de clonagem de fala de ponta a ponta, sua característica mais importante é que ele foi projetado com uma arquitetura inovadora sem tags semânticas, que pode realizar diretamente a conversão de fala para fala sem depender de codificadores/decodificadores semânticos tradicionais, como o Whisper. Com latência ultrabaixa (tão baixa quanto 150 ms), o sistema é capaz de capturar e gerar com precisão informações de áudio ambiente para obter efeitos de clonagem de fala quase em tempo real. O Fish Agent permite o download de modelos pré-treinados e suporta treinamento de implantação local e invocação de serviços em nuvem, oferecendo aos desenvolvedores e usuários um plano de uso flexível. Com funções integradas de reconhecimento e síntese de fala e um sistema preciso de controle de tom, o Fish Agent é capaz de criar uma experiência de interação de voz natural e suave.
Arquitetura de ponta a ponta, clonagem de som de amostra zero, modelo compacto com 3 bilhões de parâmetros, suporte para multilinguismo e resposta rápida. Os dados de treinamento incluem 700.000 horas de áudio multilíngue. Baseado no pré-treinamento contínuo do Qwen-2.5-3B-Instruct. O modelo, denominado Fish Agent versão 3B, integra automaticamente os componentes ASR e TTS, eliminando a necessidade de modelos externos e permitindo um verdadeiro processamento de ponta a ponta, diferenciando-o do processo tradicional de três estágios (ASR + LLM + TTS).
-1")
Experiência: https://huggingface.co/spaces/fishaudio/fish-agent
Lista de funções
- Clonagem de voz de latência ultrabaixa: tempo de resposta de 150 ms, suporta conversão de voz em tempo real
- Arquitetura de marcação semântica livre: uma solução inovadora de processamento de fala de ponta a ponta
- Controle preciso do tom: ajuste preciso do tom por meio de áudio de referência
- Processamento de áudio ambiente: reprodução de alta fidelidade de informações sonoras ambientais
- Modelos pré-treinados abertos: suporte para implantação e treinamento localizados
- API do serviço de nuvem: forneça chamadas de interface de nuvem convenientes
- Treinamento personalizado: oferece suporte ao treinamento personalizado de modelos de som
Usando a Ajuda
1. requisitos do sistema
- Python 3.8 ou superior
- GPU NVIDIA (recomendado)
- 8 GB ou mais de memória do sistema
- Suporte a CUDA (recomendado)
2. etapas de instalação
- Preparação ambiental
# Criar ambiente virtual
python -m venv fish-agent-env
source fish-agent-env/bin/activate # Linux/Mac
# ou
fish-agent-env\Scripts\activate # Windows
- Instalação do Fish Agent
# Instalação direta
pip install fish-agent
# ou a partir da fonte
git clone https://github.com/fishaudio/fish-agent
cd fish-agent
pip install -e .
3. fluxo de uso
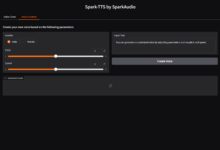
3.1 Uso de serviços on-line
Agora você pode experimentar nossa demonstração do SmartBody on-line seguindo a documentação para o bate-papo em inglês ao vivo, bem como para o bate-papo local em inglês e chinês.
A demonstração é uma versão inicial de teste alfa, a velocidade de inferência precisa ser otimizada e há muitos bugs a serem corrigidos. Se você encontrar um bug ou quiser corrigi-lo, ficaremos felizes em receber perguntas ou solicitações de pull.
https://fish.audio/zh-CN/demo/live/
3.2 Implementação local
- ativação do serviço
from fish_agent import VoiceAgent
# Inicializar o Fish Agent
agent = VoiceAgent()
# Iniciar o serviço local
agent.start_server(port=7860)
- Exemplo de clonagem de discurso
# Carregar áudio de referência
reference_audio = "path/to/reference.wav"
agent.load_reference(reference_audio)
# Gerar voz clonada
text = "Esta é uma voz de teste"
output_path = "output.wav"
agent.generate_speech(text, output_path)
- Configurações de conversão em tempo real
# Iniciar conversão de voz em tempo real
agent.start_realtime_conversion(
input_device=0, ID do dispositivo de entrada do #
output_device=1, ID do dispositivo de saída do #
reference_audio="path/to/reference.wav"
)
4. configuração avançada de recursos
4.1 Ajuste do parâmetro de tom
- Parâmetros de controle de tom:
- Inclinação: -12 a 12
- Velocidade da fala: 0,5 a 2,0
- Emotion_intensity: 0 a 1,0
4.2 Processamento em lote
# Processamento de texto em lote
texts = ["text1", "text2", "text3"]
agent.batch_process(texts, output_dir="outputs/")
4.3 Chamadas de API
Exemplo de chamada à API do #
importar solicitações
url = "https://speech.fish.audio/api/v1/generate"
payload = {
"text": "Texto a ser convertido", "reference_audio": "arquivo de áudio codificado em base64
"reference_audio": "arquivo de áudio codificado em base64"
}
response = requests.post(url, json=payload)
5 Precauções de uso
- A qualidade do áudio de referência tem um impacto significativo nos resultados da clonagem, e é recomendável usar gravações nítidas sem ruído de fundo
- Recomenda-se que um único processamento de texto seja limitado a 200 palavras ou menos.
- A conversão em tempo real requer um bom microfone para obter melhores resultados
- O uso comercial requer autorização específica
- Recomenda-se atualizar o modelo regularmente para obter o desempenho ideal
6. resolução de problemas comuns
- Problemas de saída de áudio
- Verificação das configurações do dispositivo de saída de áudio
- Verificar a configuração do volume do sistema
- Confirmar o suporte ao formato de áudio
- otimização do desempenho
- Verifique se a GPU está ativada corretamente
- Ajuste dos parâmetros do lote
- Limpeza regular do cache
- Relacionado à instalação
- Verificando a compatibilidade da versão do Python
- Confirmar a configuração do ambiente CUDA
- Considere um ambiente conda
- Uso da API
- Verificar o status da conexão de rede
- Confirmação da configuração de permissão da API
- Verificar a resposta do servidor