InboxPilot:学习公司内部知识自动化处理电子邮件的AI工具
综合介绍 InboxPilot是一款专为企业设计的AI电子邮件自动化工具,通过利用公司内部数据来智能撰写和发送电子邮件回复。它不仅能节省时间,还能提高客户服务的效率和质量。该工具特别适用于处理大量的支持请求、信...
 首席AI分享圈
首席AI分享圈
综合介绍 InboxPilot是一款专为企业设计的AI电子邮件自动化工具,通过利用公司内部数据来智能撰写和发送电子邮件回复。它不仅能节省时间,还能提高客户服务的效率和质量。该工具特别适用于处理大量的支持请求、信...

在前两代视频模型(CogVLM2-Video和GLM-4V-PLUS)的基础上,我们进一步优化了视频理解技术,推出了GLM-4V-Plus-0111 beta版本。该版本引入了原生可变分辨率等技术,提升了模型对不同视频长度和分辨率的适应能力。...

开启 Builder 智能编程模式,无限量使用 DeepSeek-R1 和 DeepSeek-V3 ,对比海外版体验更加流畅。只需输入中文指令,不懂编程的小白也可以零门槛编写自己的应用。

综合介绍 HyperUGC 是一个创新的平台,利用人工智能技术生成高质量的用户生成内容(UGC)视频。该平台旨在替代昂贵的内容创作者,通过AI虚拟形象在几分钟内生成真实且具有吸引力的视频内容。HyperUGC 适用于多个...

综合介绍 KlipML 是一个先进的AI视频创作平台,旨在帮助用户快速生成专业视频。无论是营销内容、教育视频还是社交媒体短片,KlipML 都能通过其强大的AI功能简化视频制作过程。平台提供AI代理、AI视频生成、AI字幕...

综合介绍 Wepost 是一个专为忙碌的营销人员设计的内容营销平台,利用人工智能技术帮助用户创建高质量的品牌内容。该平台集成了内容规划、创建、发布和分析功能,旨在简化工作流程并提高内容营销的效率。用户可以...
综合介绍 Llasa-3B是由香港科技大学音频实验室(HKUST Audio)开发的一个开源文本转语音(TTS)模型。该模型基于Llama 3.2B架构,经过细致调优,提供高质量的语音生成,不仅支持多种语言,还能实现情感表达和个性...

综合介绍 Fast GraphRAG 是由 Circlemind AI 开发的一款开源工具,旨在通过知识图谱和 PageRank 算法实现高效、精确的检索增强生成(RAG)。该工具能够智能适应用户的使用场景、数据和查询需求,提供可解释、低成...
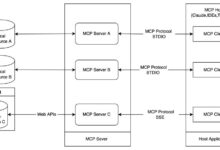
初识MCP MCP(Model Context Protocol),是一个开发的协议,标准化了应用程序如何为大模型提供上下文。MCP提供了一个标准的为LLM提供数据、工具的方式,使用MCP会更容易的构建Agent或者是基于LLM的复杂工作流。 ...

1.引言 两个月前,Qwen团队升级了 Qwen2.5-Turbo,使其支持最多一百万个Tokens的上下文长度。今天,Qwen正式推出开源的 Qwen2.5-1M 模型及其对应的推理框架支持。以下是本次发布的亮点: 开源模型: 本次发布了两...

2025开年,AI行业掀起大模型“推理潮”,自OpenAI发布o1后,各式推理模型不断涌现,模型的高阶推理能力迎来爆发增强,其应用价值也愈发获得业界的广泛关注。 近日,网易有道正式推出国内首个输出分步式讲解的推理模...

综合介绍 TinyZero 是一个基于 veRL 的强化学习模型,旨在复现 DeepSeeK-R1 Zero 在倒计时和乘法任务中的表现。令人惊讶的是,该项目仅需 30 美元的运行成本(使用 2xH200,每小时 6.4 美元,不到 5 小时),就能...

综合介绍 Hugging Face的Open R1项目是一个完全开源的DeepSeek-R1复现项目,旨在构建R1管道的缺失部分,使每个人都能复现并在其基础上进行构建。该项目设计简单,主要包括训练和评估模型以及生成合成数据的脚本。...
该提示词来源于AI编程工具 CodeGuide ,利用此提示词和最新的 Deepseek-R1 模型,实现了类似 o1 的响应效果,替代 o1 思考过程,整体 API 成本降低了 50%。 该提示词技巧非常简单:1.使用 XML 标签而不是 Markdow...

提示词 Please perform a comprehensive security audit of the Cerebr-main browser extension, including analysis of its source code, permissions, network traffic patterns, and data handling. Check for...
综合介绍 Open Operator 是一个开源项目,旨在通过AI智能体在浏览器中进行自动化操作。该项目由 Browserbase 开发,结合了 Stagehand 和 Browserbase 的技术,使得用户能够通过自然语言指令控制浏览器的行为。Ope...
综合介绍 Cerebr 是一个功能强大的 Chrome 浏览器 AI 助手扩展,旨在提升用户的工作效率和学习体验。Cerebr 的设计理念源于对简洁、高效浏览器 AI 助手的需求,凭借其极简设计和强大功能脱颖而出。Cerebr 集成了 ...

综合介绍 TubeTube是一个开源的YouTube视频下载工具,由MattBlackOnly开发。该工具使用yt-dlp作为核心下载引擎,支持多线程下载,能够快速同时下载多个视频。用户可以通过YAML文件自定义下载位置和格式,支持音频...

综合介绍 LangWatch 是一个专为大语言模型(LLM)操作而设计的综合平台,提供监控、分析、评估、数据集管理和提示优化等功能。该平台基于斯坦福大学的 DSPy 框架,旨在帮助用户更好地管理和优化 LLM 管道。LangWa...

1. 引言:图像生成的新时代 在当今的数字时代,图像生成技术已经取得了令人瞩目的进步。无论你是设计师、艺术家,还是仅仅想要创造个性化内容的普通人,图像生成工具都能帮助你将创意变为现实。然而,传统的图像...