Basalt:快速构建和优化AI应用中的提示词
综合介绍 Basalt 是一个专注于提示词构建与管理的平台,旨在帮助团队高效打造高质量的 AI 提示词并将其应用于产品中。它提供无代码编辑器、智能优化建议和版本管理功能,让产品经理、工程师及领域专家能够快速设...
 首席AI分享圈
首席AI分享圈
综合介绍 Basalt 是一个专注于提示词构建与管理的平台,旨在帮助团队高效打造高质量的 AI 提示词并将其应用于产品中。它提供无代码编辑器、智能优化建议和版本管理功能,让产品经理、工程师及领域专家能够快速设...
综合介绍 TheoremExplainAgent 是由 TIGER AI Lab 开发的一个创新项目,旨在利用人工智能技术将复杂的数学和科学定理转化为易于理解的视频动画。该工具基于大语言模型(LLM)的推理能力,结合动画生成和语音合成...

开启 Builder 智能编程模式,无限量使用 DeepSeek-R1 和 DeepSeek-V3 ,对比海外版体验更加流畅。只需输入中文指令,不懂编程的小白也可以零门槛编写自己的应用。

综合介绍 Cloudflare Workers MCP 是由 Cloudflare 开发的一个开源项目,托管于 GitHub,旨在帮助开发者快速构建并部署基于 Cloudflare Workers 的 MCP(Model Context Protocol,模型上下文协议)服务器。这个工...

备受瞩目的 AI 巨头 OpenAI 近日宣布推出其最新的旗舰级语言模型 GPT-4.5 的研究预览版,再次引发科技界的广泛关注。这款被寄予厚望的新模型,初期将面向软件开发者和 ChatGPT Pro 订阅用户开放,预示着新一轮 AI...

在人工智能领域,创新公司 Perplexity 此前推出了一款号称是 “全球首个对话式 AI 搜索引擎” 的产品,这款搜索引擎可以被看作是结合了 Google 搜索引擎的广泛信息检索能力与 ChatGPT 的对话式交互特点,这无疑给传...

综合介绍 3FS(Fire-Flyer File System)是由DeepSeek团队开发的一款开源并行文件系统,专为现代SSD和RDMA网络设计,旨在大幅提升数据访问效率。它在180节点集群中实现了6.6 TiB/s的聚合读取吞吐量和3.66 TiB/min...

好久没有分享AI美女写真提示词,之前一直使用 fooocus 画美女写真,这次试试 星流 ,这是一款适合商用的AI图像创作工具,可以在画布中完成所有基础图像编辑工作。 星流基础模型中包含两款预设“人像摄影”模型,都...
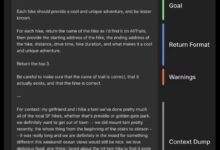
在人工智能时代,撰写有效的提示词(prompt)是一项重要的技能。无论是让 AI 生成文本、图片,还是获取准确的信息,一个优秀的提示词能大幅提高 AI 产出的质量和相关性。本文将基于 "The Anatomy of an o1 Prompt...
综合介绍 DeepChat 是一个开源的智能助手项目,由 ThinkInAIXYZ 团队在 GitHub 上开发。它旨在通过强大的 AI 技术连接用户与数字世界,提供高效、自然的聊天体验。支持 Windows、macOS、Linux 等多平台使用,具备...

2025年2月26日,SuperCLUE发布项目级代码生成(SuperCLUE-Project)测评基准首期榜单。 测评方案见:项目级代码生成测评基准发布。本次测评基于大模型“裁判团”的合作,全方位评价了国内外12个大模型在项目级代码...
综合介绍 Dify Connect MCP 是一个开源项目,托管在 GitHub 上,旨在为 Dify 平台的用户提供一个便捷的工具,通过模型上下文协议(Model Context Protocol, MCP)实现与 Dify 工作流的无缝连接。该项目由 difybas...

综合介绍 秒哒是百度智能云推出的一款创新型无代码开发工具,旨在帮助用户通过自然语言快速构建应用程序,无需掌握复杂的编程技能。依托百度强大的AI技术与大模型支持,该平台能够将用户的创意想法转化为实际可用...
综合介绍 DualPipe 是由 DeepSeek-AI 团队开发的一项开源技术,专注于提升大规模 AI 模型训练的效率。它是一个创新的双向流水线并行算法,主要用于在 DeepSeek-V3 和 R1 模型训练中实现计算与通信的完全重叠,有...
综合介绍 AutoDev 是一个由 Unit Mesh 团队开发的开源项目,托管在 GitHub 上,旨在通过人工智能技术提升开发者的编程效率。它是一个功能强大的编码助手,支持多种编程语言,包括 Java、Kotlin、Python 等,提供...

在人工智能科技领域,语言模型 (Language Models, LMs) 已经成为驱动创新的核心力量。从预训练到实际应用,语言模型都依赖于纯文本数据进行运作。无论是进行万亿 tokens 级别的训练,还是支持数据密集型的人工智...

信息爆炸的时代,知识管理成为提升个人竞争力的关键。 无论你身处哪个行业,每天都需要面对海量的信息、文档、学习资料,如何高效地检索、利用这些知识,成为了每个人都亟待解决的问题。 Khoj,正是为解决这一痛...

综合介绍 LLPlayer 是一款专为语言学习者设计的开源媒体播放器,托管于 GitHub,由开发者 umlx5h 创建。它集成了多种实用功能,如双语字幕显示、AI 自动生成字幕、实时翻译和单词查询等,旨在帮助用户通过观看视...

摘要 精心设计的提示对于提升大语言模型(LLMs)的推理能力,同时使其输出与不同领域的任务要求保持一致至关重要。然而,手动设计提示需要专业知识和反复试验。现有的提示优化方法旨在自动化这一过程,但它们严重...

在人工智能浪潮的推动下,语音技术迎来了前所未有的发展机遇。 ElevenLabs,作为一家专注于 AI 语音生成领域的科技公司,凭借其先进的人工智能技术,成功地将文本转化为了 流畅自然、高度逼真 的语音。更令人惊叹...