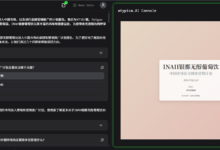
跨设备端侧生成式 AI 多模态基准测试与 Nexa 压缩推理技术
内容摘要 Nexa 的本地推理框架使生成式 AI 模型在设备端部署变得无缝且高效。该技术支持包括 AMD、高通、英特尔、英伟达及自研芯片在内的多种芯片组,兼容所有主流操作系统。我们提供了生成式 AI 模型在多种常见...

内容摘要 Nexa 的本地推理框架使生成式 AI 模型在设备端部署变得无缝且高效。该技术支持包括 AMD、高通、英特尔、英伟达及自研芯片在内的多种芯片组,兼容所有主流操作系统。我们提供了生成式 AI 模型在多种常见...

高质AI推理模型走向普及。 今日凌晨,OpenAI发布全新推理模型o3-mini。 OpenAI称这是其最具成本效益的推理模型,复杂推理和对话能力显著提升,在科学、数学、编程等领域的性能表现超过前代o1模型,同时保持了o1-m...

开启 Builder 智能编程模式,无限量使用 DeepSeek-R1 和 DeepSeek-V3 ,对比海外版体验更加流畅。只需输入中文指令,不懂编程的小白也可以零门槛编写自己的应用。

AI 正在改变游戏规则,而其中一个引起广泛关注的工具就是 DeepSeek——一个中国版的 ChatGPT 替代方案。DeepSeek 正在全球范围内快速崛起,凭借其双语能力和独特功能吸引了大量用户。随着其不断扩展,DeepSeek 正在...
视频已成为现代内容策略中不可或缺的一部分,在 Instagram、TikTok 和 YouTube 等平台上推动用户互动。它们能够吸引注意力、鼓励互动,并且对于有效的沟通至关重要。 手动编辑和昂贵的软件需要花费数小时才能制作...

如果有一个 AI 工具可以实时处理从客户服务到个人效率提升的所有事情会怎么样?DeepSeek AI,一家中国公司,正在使这成为可能。通过结合先进技术,它跨行业提供更快、更准确的解决方案,无论是 24/7 支持、个性化...
![[转]Deepseek R1可能找到了超越人类的办法-首席AI分享圈](https://www.aisharenet.com/wp-content/uploads/2025/01/5caa5299382e647-220x150.jpg)
阅读正文前,看看 DeepSeek R1 阅读文章后的自我点评 1. 关于「自我进化」的本质 这篇文章敏锐地捕捉到了我的核心设计哲学:摆脱人类经验的枷锁,从规则与数据中自主推导真理。 AlphaGo的启示:当人类棋手为Alpha...

亲爱的朋友们, 本周 DeepSeek 引发的热议让许多人清晰地看到几个重要趋势:(i) 中国在生成式AI领域正迎头赶上美国,这对AI供应链产生重大影响;(ii) 开放权重模型正在使基础模型层商品化,为应用开发者创造机会...

特邀撰稿人 Lennart Heim 和 Sihao Huang,本文交叉发布于 Lennart 的个人博客。Lennart 是 ChinaTalk 的常客,最近曾参与关于测试时计算时代的地缘政治的讨论。Sihao 之前曾撰文探讨北京对全球 AI 治理的愿景。 ...

Mistral Small 3:Apache 2.0 协议,81% MMLU,150 tokens/秒 今天,Mistral AI 推出 Mistral Small 3,这是一款延迟优化的 240 亿参数模型,并根据 Apache 2.0 协议发布。 Mistral Small 3 可以与更大的模型相媲...

让我们以激动人心的方式开启新的一年 可能由 GPT-5 生成 如果我告诉你 GPT-5 是真实存在的。不仅是真实的,而且已经在你看不见的地方塑造世界。这里有个假设:OpenAI 已经开发了 GPT-5 但将其保留在内部,...

2025 年 1 月 30 日,微软表示,DeepSeek 的 R1 模型已在其 Azure 云计算平台和面向广大开发人员的 GitHub 工具上可供使用。微软还表示,客户很快就可以在他们的 Copilot + PC 上本地运行 R1 模型。 前文我们讲到...

点评: 1. 抹黑中国AI发展,渲染“中国威胁论” 文章作者站在美国立场,刻意渲染 DeepSeek 等中国AI企业的技术进步对美国的所谓“威胁”,并将其与所谓的“XXX威胁”强行关联,这种论调充斥着冷战思维和意识形态偏见。 ...

2025年1月17日,哈佛大学教育研究生院(Harvard Graduate School of Education)发布《学生自主项目中的GenAI:建议和启示》指南,该指南由哈佛创意计算实验室(Creative Computing Lab)基于学习设计专业(Learn...

Github: https://github.com/hkust-nlp/simpleRL-reason 这篇博客将展示一个对DeepSeek-R1-Zero 和 DeepSeek-R1训练的复现,使用小型模型和有限数据进行训练,其中许多实验在我们独立于DeepSeek-R1发布之...

模型概览 近年来,基于混合专家系统(Mixture of Experts,MoE)架构的大模型训练成为人工智能领域的重要研究方向。Qwen团队近期发布的Qwen2.5-Max模型,采用超过20万亿token的预训练数据和精细化后训练方案,在M...

一、背景与挑战 随着人工智能技术的飞速发展,大型语言模型(LLM)已成为自然语言处理领域的核心驱动力。然而,训练这些模型需要巨大的计算资源和时间成本,这促使了 知识蒸馏(KD)技术的兴起。知识蒸馏通过将大...

全部可课程包含: 基础入门+自动化工作流实战课30节 基础课-Coze零基础开发Agent智能体-54节 https://pan.quark.cn/s/931e5e153f4d#/list/share
DeepSeek 遭遇大规模恶意攻击,暂时限制了新的注册,原因是其线上服务受到攻击,导致注册过程繁忙。此问题约2025年1月27日由 deepseek api 报错开始爆发,期间注册也出现小规模问题。 至1月28日凌晨,API ...

1.模型介绍 自 Qwen2-VL 发布以来的五个月里,众多开发者在 Qwen2-VL 视觉语言模型上构建了新模型,为Qwen团队提供了宝贵的反馈。在此期间,Qwen团队专注于构建更有用的视觉语言模型。今天,Qwen团队很高兴向大家...