

传统网络爬虫框架功能多样,但在处理数据时常需要额外进行清洗与格式化,这使得它们与大语言模型(LLM)的集成相对复杂。许多工具的输出(如原始 HTML 或未结构化的 JSON)包含大量噪声,不适合直接用于检索增强生成(RAG)等场景,因为这会降低 LLM 处理的效率和准确性。
Crawl4AI 提供了一种不同的解决方案。它专注于直接生成干净、结构化的 Markdown 格式内容。这种格式保留了原文的语义结构(如标题、列表、代码块),同时智能地去除了导航、广告、页脚等无关元素,非常适合作为 LLM 的输入或用于构建高质量的 RAG 数据集。Crawl4AI 是一个完全开源的项目,使用时不需要 API 密钥,也没有设置付费门槛。
安装和配置
建议使用 uv 创建并激活一个独立的 Python 虚拟环境来管理项目依赖。uv 是一个基于 Rust 开发的新兴 Python 包管理器,以其显著的速度优势(通常比 pip 快 3-5 倍)和高效的并行依赖解析能力而受到关注。
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
环境激活后,使用 uv 安装 Crawl4AI 核心库:
uv pip install crawl4ai
安装完成后,运行初始化命令,该命令会负责安装或更新 Playwright 所需的浏览器驱动(如 Chromium),并执行环境检查。Playwright 是一个由 Microsoft 开发的浏览器自动化库,Crawl4AI 利用它来模拟真实用户交互,从而能够处理动态加载内容的 JavaScript 重度网站。
crawl4ai-setup
如果遇到浏览器驱动相关问题,可以尝试手动安装:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
根据需要,可以通过 uv 安装包含额外功能的扩展包:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
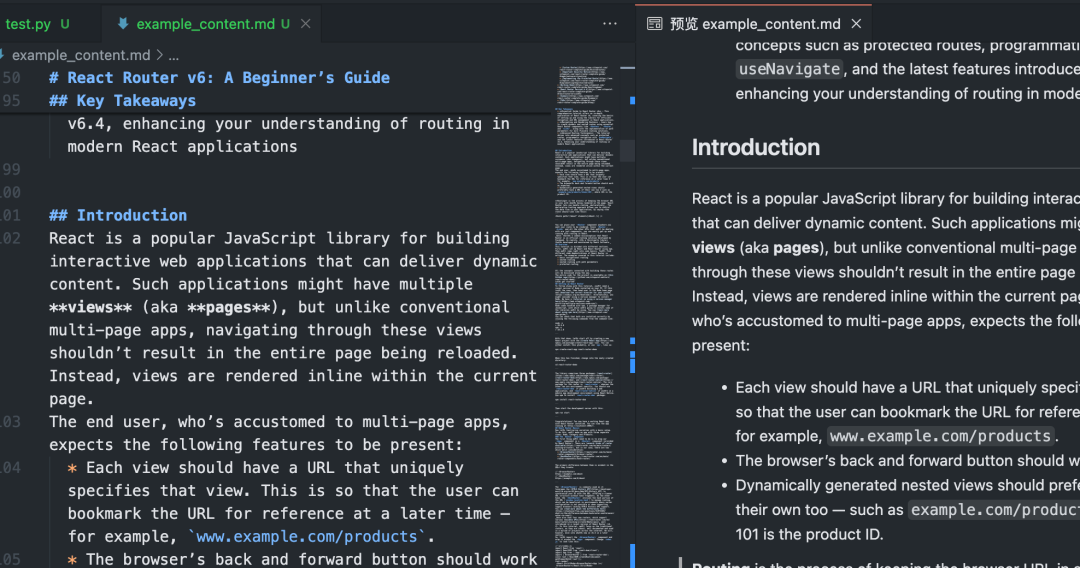
基础爬取实例
以下 Python 脚本展示了 Crawl4AI 的基本用法:爬取单个网页并将其转换为 Markdown。
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
执行此脚本后,Crawl4AI 会启动 Playwright 控制的浏览器访问指定 URL,执行页面 JavaScript,然后智能识别并提取主要内容区域,过滤干扰元素,最终生成干净的 Markdown 文件。
批量与并行爬取
处理多个 URL 时,Crawl4AI 的并行处理能力可以大幅提升效率。通过配置 CrawlerRunConfig 中的 concurrency 参数,可以控制同时处理的页面数量。
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
注意: 上述代码使用了 arun_many 方法,这是处理大量 URL 列表的推荐方式,它比循环调用 arun 更高效。arun_many 需要一个配置列表,每个配置对应一个 URL。如果所有 URL 使用相同的基本配置,可以通过 clone() 方法创建副本并设置特定 URL。
结构化数据提取 (基于选择器)
除了 Markdown,Crawl4AI 还能使用 CSS 选择器或 XPath 提取结构化数据,非常适合数据格式规整的网站。
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
这种方式无需 LLM 介入,成本低且速度快,适用于目标元素明确的场景。
AI 增强的数据提取
对于结构复杂或无固定模式的页面,可以利用 LLM 进行智能提取。
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
AI 提取提供了极大的灵活性,能够理解内容并按需生成结构化输出,但会产生额外的 API 调用成本(如果使用云服务 LLM)和处理时间。选择本地模型(如 Mistral, Llama)可以降低成本并保护隐私,但对本地硬件有一定要求。
进阶配置与技巧
Crawl4AI 提供丰富的配置选项来应对复杂场景。
浏览器配置 (BrowserConfig)
BrowserConfig 控制浏览器本身的启动和行为。
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
爬取运行配置 (CrawlerRunConfig)
CrawlerRunConfig 控制单次 arun() 或 arun_many() 调用的具体行为。
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
处理 JavaScript 和动态内容
得益于 Playwright,Crawl4AI 能很好地处理依赖 JavaScript 渲染的网站。关键配置:
wait_until: 设置为"networkidle"或"load"通常比默认的"domcontentloaded"更适合动态页面。wait_for: 等待特定元素或JavaScript条件满足。js_code: 在页面加载后执行自定义JavaScript,例如点击按钮、滚动页面。scan_full_page: 自动处理常见的无限滚动页面。delay_before_return_html: 在提取前增加一个短暂延时,确保所有脚本执行完毕。
错误处理与调试
- 检查
result.success: 每次爬取后务必检查此属性。 - 查看
result.status_code和result.error_message: 获取失败原因。 - 设置
headless=False: 在BrowserConfig中设置,可以观察浏览器操作,直观诊断问题。 - 启用
verbose=True: 在BrowserConfig中设置,获取更详细的运行日志。 - 使用
try...except: 包裹arun()或arun_many()调用,捕获可能出现的Python异常。
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
遵守 robots.txt
进行网络爬取时,尊重网站的 robots.txt 文件是基本的网络礼仪,也能避免 IP 被封禁。Crawl4AI 可以自动处理。
在 CrawlerRunConfig 中设置 check_robots_txt=True:
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI 会自动下载、缓存并解析 robots.txt 文件,如果规则禁止访问目标 URL,arun() 会失败,result.success 为 False,status_code 通常是 403,并附带相应错误信息。
会话管理 (Session Management)
对于需要登录或保持状态的多步骤操作(如表单提交、分页导航),可以使用会话管理。通过在 CrawlerRunConfig 中指定相同的 session_id,可以在多个 arun() 调用之间复用同一个浏览器页面实例,保留 cookies 和 JavaScript 状态。
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
更高级的会话管理包括导出和导入浏览器的存储状态(cookies, localStorage),允许在不同脚本运行之间保持登录状态。
Crawl4AI 提供了强大而灵活的功能集,通过合理配置,可以高效、可靠地从各种网站提取所需信息,并为下游的 AI 应用准备好高质量的数据。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...