簡単
人工知能の分野で。基本モデル(大規模言語モデルや視覚言語モデルなど)は、技術の進歩を牽引する中心的な存在となっている。しかし、これらのモデルをいかに効果的に強化するか。一般化能力現実のシナリオの複雑さと可変性に適応するという課題は、依然として大きなものである。現在教師あり微調整(SFT)と強化学習(RL)は、広く採用されている2つのポストトレーニングメソッドであるが、モデルの汎化能力を向上させる上での具体的な役割や効果は、まだ明らかになっていない。
この論文は徹底的な比較研究本研究では、SFTとRLが基礎となるモデルの汎化能力に与える影響を系統的に探ります。我々は、以下の2つの重要な側面に焦点を当てている:
- テキストルールに基づく汎化: というシステムを設計した。 総合ポイント 算数推論カードゲームでは、さまざまなルールバリエーションにおけるモデルのパフォーマンスを評価する。
- 視覚的な一般化: を使用した。 V-IRL タスクは、実世界の視覚入力に基づくナビゲーション環境であり、視覚入力の変化に対するモデルの適応能力をテストする。
一連の厳密な実験と分析そして、次のような重要な結論に達した:
- RLは、ルールと視覚的汎化の両方でSFTを上回る: RLは、新しいルールを効率的に学習・適用することができ、視覚入力のバリエーションがあっても良好なパフォーマンスを維持する。対照的に、SFTは学習データを記憶する傾向があり、未知のバリエーションに適応することが難しい。
- RLは視覚認識を向上させる: 視覚言語モデリング(VLM)において、RLは推論を向上させるだけでなく視覚認識も向上させるが、SFTは視覚認識を低下させる。
- SFTはRLのトレーニングに欠かせない: SFTは、バックボーンモデルに優れた命令追従能力がない場合に、RL学習を成功させるための重要な要素である。SFTはモデルの出力形式を安定させ、RLがその性能をフルに活用できるようにする。
- 検証の反復回数を増やすことで、RLの汎化性が向上する: RL学習では、検証の反復回数を増やすことで、モデルの汎化度をさらに向上させることができる。
これらの調査結果将来のAI研究と応用のための貴重な洞察を提供する本研究では、RLが複雑なマルチモーダル課題においてより大きな可能性を持つことを示した。本研究は、SFTとRLの異なる役割を明らかにするだけでなく、より強力で信頼性の高い基礎モデルを構築するために、これら2つのアプローチをより効果的に組み合わせる方法に関する新たなアイデアも提供する。
あなたがAIの研究者であれ、エンジニアであれ、AIの未来に興味を持つ読者であれ、本稿はあなたに洞察と実践的な指針を提供する。 SFTとRLの謎をさらに深く掘り下げ、基礎となるモデルの一般化への重要な道筋を明らかにしよう。
原文ママhttps://tianzhechu.com/SFTvsRL/assets/sftvsrl_paper.pdf
速読
1. ルール汎化においてRLがSFTを上回る
結論
RLはテキストベースのルールを効率的に学習し汎化することができるが、SFTは学習データを記憶する傾向があり、未知のルール変種に適応することが難しい。
例
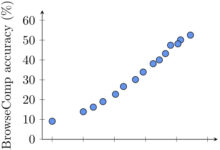
RLは、GeneralPointsタスクとV-IRLタスクの両方において、分布外(OOD)性能でSFTを上回った。
- ジェネラルポイント(GP-L):
- RLだ。 成功率は15.0%で、最初のチェックポイントの11.5%から上昇した。 +3.5%.
- SFT。 成功率は3.4%で、最初のチェックポイントの11.5%から減少した。 -8.1%.
- v-irl(v-irl-l):
- RLだ。 ステップあたりの精度は91.8%で、最初のチェックポイントでの80.8%より向上した。 +11.0%.
- SFT。 ステップあたりの精度は1.3%で、最初のチェックポイントの80.8%から低下した -79.5%.

図6:各サブグラフについて、RLとSFTは同じ計算量で学習され、共有された初期チェックポイント(Initと表示)がベースラインとして設定される。詳細設定については付録C.3を参照。
2. RLは視覚的なOODタスクでも汎化されるが、SFTのパフォーマンスは低い。
結論
視覚的モダリティを含むタスクでも、RLは未知の視覚的バリアントにも汎化できるのに対し、SFTはパフォーマンス低下に見舞われる。
例
GeneralPoints-VIタスクとV-IRL-VLタスクにおいて:
- GeneralPoints-VI(GP-VI):
- RLだ。 成功率は41.2%で、最初のチェックポイントでの23.6%から上昇した。 +17.6%.
- SFT。 成功率は13.7%で、最初のチェックポイントでは23.6%だった。 -9.9%.
- v-irl-vl(v-irl-vl):
- RLだ。 ステップあたりの精度は77.8%で、最初のチェックポイントでの16.7%より向上していた。 +61.1%.
- SFT。 ステップあたりの精度は11.1%で、最初のチェックポイントの16.7%から低下した -5.6%.

図7:図5および図6と同様に、視覚的分布の外側で評価した性能ダイナミクス(線で示す)と最終的な性能(棒で示す)を示す。V- IRL VLN small benchmark test (Yang et al., 2024a)における従来の最先端性能はオレンジ色で示されている。詳細な評価セットアップ(および曲線の平滑化)については付録C.3を参照のこと。
3. RLはVLMの視覚認識を向上させる
結論
RLはモデルの推論を向上させるだけでなく、視覚認識も向上させるが、SFTは視覚認識を低下させる。
例
GeneralPoints-VIタスクで:
- RLだ。 訓練計算量が増えるにつれて、視覚認識精度と全体的な成功率の両方が向上する。
- SFT。 学習計算量が増えるにつれて、視覚認識精度と全体的な成功率は低下する。
 図8:GP-VLの異なるバリエーションにおける強化学習(RL)と教師あり微調整(SFT)の認識率と成功率の比較。 グラフは、分布内データ(赤)と分布外データ(青)にそれぞれ対応する認識率(y軸)と1画面成功率(x軸)の性能を示している。 データ点の透明度(カラーバー)は学習計算量を表す。 線(⋆-◦ )で結ばれたデータペアは、同じチェックポイントを用いて評価される。 この結果から、強化学習(RL)は学習後の計算量が増えるほど認識率と総合精度が向上するのに対し、教師あり微調整(SFT)は逆の傾向を示していることがわかります。
図8:GP-VLの異なるバリエーションにおける強化学習(RL)と教師あり微調整(SFT)の認識率と成功率の比較。 グラフは、分布内データ(赤)と分布外データ(青)にそれぞれ対応する認識率(y軸)と1画面成功率(x軸)の性能を示している。 データ点の透明度(カラーバー)は学習計算量を表す。 線(⋆-◦ )で結ばれたデータペアは、同じチェックポイントを用いて評価される。 この結果から、強化学習(RL)は学習後の計算量が増えるほど認識率と総合精度が向上するのに対し、教師あり微調整(SFT)は逆の傾向を示していることがわかります。
4. RLのトレーニングにはSFTが必要
結論
SFTは、バックボーンモデルのコマンド追従性が低い場合のRLトレーニングに必要である。
例
エンド・ツー・エンドのRLをSFTの初期化なしで訓練後のLlama-3.2に直接適用した実験はすべて失敗に終わった。
- 失敗のケーススタディ
- このモデルは、RL訓練に関連する情報や報酬を取り出すことができない、長く、脱線した、構造化されていない回答を生成する。
- 例えば、このモデルはコードを書くことによって24点ゲームを解こうとするが、コード生成が完了せず、検証失敗となる。
![]()
図20:図11と同様のキューを用いてモデルの反応を記録した。この結果から、Llama-3.2-Vision-11Bは指示に正しく従えないことがわかる。コードを使ってパズルを解こうとしたが、限られた文脈の長さの中で完了できなかった長い回答は省略した。
5. 検証の反復回数を増やすと、RLの汎化能力が向上する。
結論
RL学習では、検証の反復回数を増やすことで、モデルの汎化が向上する。
例
GeneralPoints-Language(GP-L)タスクで:
- 1 検証の繰り返し。 OODのパフォーマンスが向上するのは +0.48%.
- 3回の検証を繰り返す。 OODのパフォーマンスが向上 +2.15%.
- 5回の検証を繰り返す。 OODのパフォーマンスが向上 +2.99%.
- 10回の検証を繰り返す。 OODのパフォーマンスが向上 +5.99%.

図10:学習計算量をスケールアップする方法として、検証反復回数(VIter)を変化させたRL実験を記録した(色は透明)。
6. SFTは推論マーカーにオーバーフィットし、認識マーカーを無視する
結論
SFTは推論されたマーカーに過剰にフィットし、同定されたマーカーに過小にフォーカスする傾向があるが、これはおそらく推論されたマーカーの頻度が高いためであろう。
例
GeneralPoints-VIタスクでは、ハイパーパラメータを調整しても、SFTはRLに匹敵する分布内性能を達成できなかった。
- SFTアブレーション研究。
- 学習率とその他の調整可能な要素で調整した後、SFT成功率はいずれも30%を超えず、増加傾向は見られなかった。

図16:GeneralPoints-VL SFTのアブレーション試験。 学習率についてアブレーション実験を行い、すべての実験について分布内、単一スクリーンの成功率(%)を報告する。 どの実験も30%以上の成功率はなく、増加傾向は見られなかった。
7. RLはオーバーフィッティングのチェックポイントからOODのパフォーマンスを回復できない
結論
過適合のチェックポイントから初期化した場合、RLはモデルのOOD性能を回復することができなかった。
例
V-IRL-VLタスクで:
- オーバーフィッティングチェックポイントからのRL初期化
- 初期の1ステップあたりの精度は1%より低く、RLはOOD性能を改善できない。

図 19:分布外シングルステップ精度(%)-GFLOPs:通常のバリアントの V-IRL-VL モデル(過適合の初期チェックポイントを使用)。評価指標の詳細については付録 C.3 を参照。
概要
本論文は、一連の実験と分析を通じて、汎化可能な知識の学習におけるRLの優位性と、SFTが訓練データを記憶する傾向を実証する。また、本論文は、RL学習におけるSFTの重要性と、検証の反復回数を増やすことがRLの汎化能力にプラスの影響を与えることも明らかにしている。これらの知見は、将来、より頑健で信頼性の高いベースモデルを構築するための貴重な洞察を提供する。