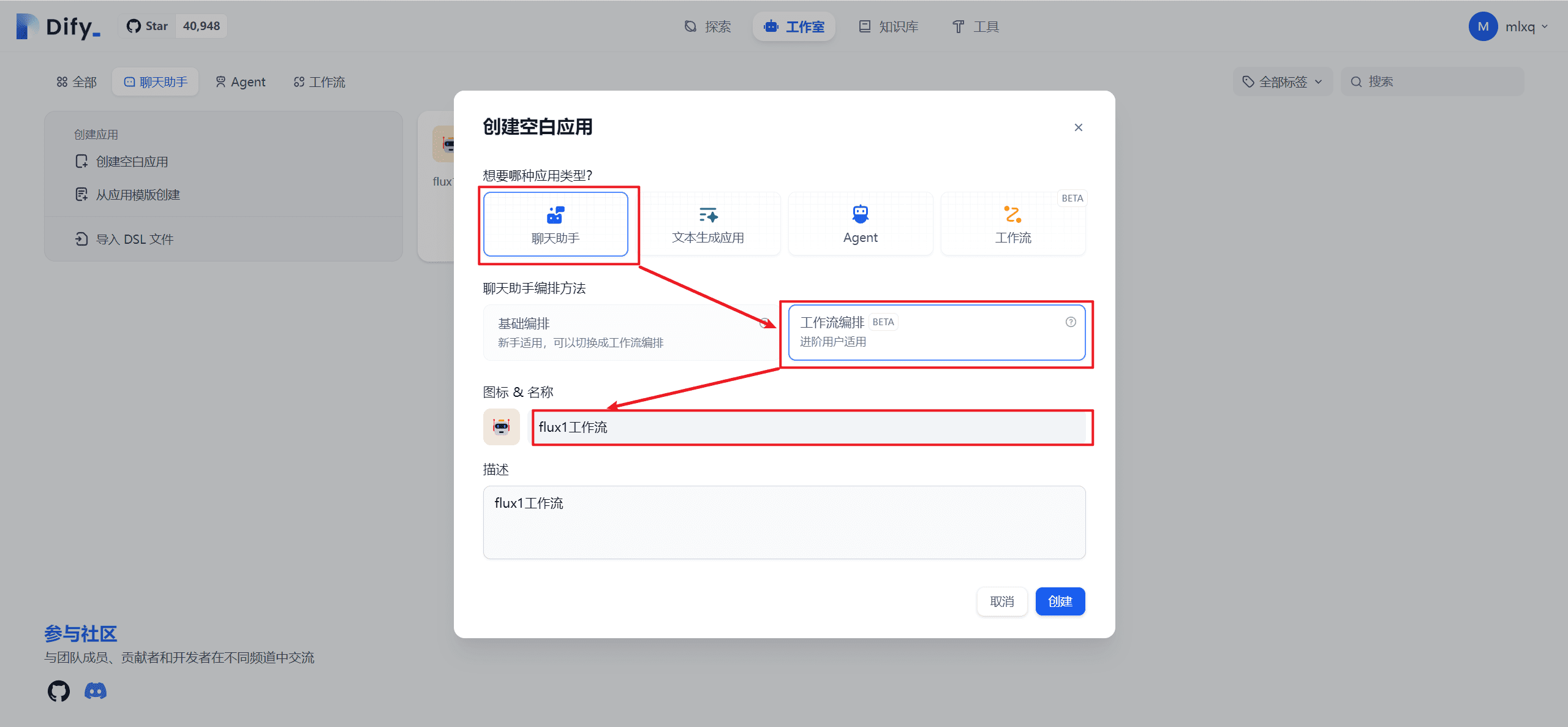
ローカルGPUなしのプライベート展開 DeepSeek-R1 32B

に関して ディープシーク-R1 日常的なオフィスでの使用には、公式サイトで直接使用するのが最良の選択ですが、その他の懸念事項や特別なニーズがある場合は...で使用しなければならない。 DeepSeek-R1 のローカル展開 (ワンクリックインストーラを使用)ここにある白のチュートリアルはあなたにぴったり。
もしあなたが貧弱な構成のコンピューターを持っていて、それでもプライベートDeepSeek-R1を使ってデプロイしたいのなら......。それなら、フリーのGPUを使うことを検討してください。 無料のGPUパワーでDeepSeek-R1オープンソースモデルをオンライン展開しかし、致命的な欠点があります、つまり、無料のGPUは14Bしかインストールできませんが、32Bをインストールすると、非常にカードになりますが、テストした後、DeepSeek-R1 32B以上の出力品質をインストールするだけで、毎日の仕事のニーズを満たすことができます。
だから...私たちがやろうとしているのは、フリーGPUを効率的に稼働している DeepSeek-R1 32Bの定量バージョン.彼が来る
無料のGPUでは、2〜6ワード/秒の出力で行うことができます(問題の複雑さに応じて出力速度が変動する)、この方法の欠点は、随時サービスをオンにする必要があることです。
unslothチーム 定量化バージョン DeepSeek-R1

アンロス 付属のQwen-32B-Q4_K_Mのバージョンは20GBに圧縮されており、これはすでにコンシューマーグレードのシングルカードで動作可能な容量だ。.
定量化バージョンに必要なコンピューター性能の簡単なまとめ
ディープシーク-R1-ディスティル-クウェン-32B-GGUFモデルの異なる定量的バージョンの説明
各ファイルの接尾辞(Q2_K_L、Q4_K_Mなど)は、異なる定量化を表す。主な違いは以下の通りである:
q2_k_l、q3_k_m、q4_k_m、q5_k_m、q6_k、q8_0
Q2そしてQ3そしてQ4そしてQ5そしてQ6そしてQ8は計算するビット数を表す(例えばQ4(4ビット計算を示す)。KそれにM定量的な戦略や精度のレベルが違うのかもしれない。Q8_0通常8ビットの量子化で、FP16の精度に近く、計算負荷は高いが推論の質は高い。
DeepSeek-R1-Distill-Qwen-32B-F16
F16示す16ビット浮動小数点(FP16)は計算されていないモデルで、精度は最も高いが、ビデオメモリを最も消費する。
クオンティマイゼーションのコンセプトについてはこちらをご覧ください:モデル量子化とは:FP32、FP16、INT8、INT4データ型の説明
正しいバージョンの選び方は?
- 低ビデオメモリデバイス(民生用GPUなど) →選択Q4、Q5の定量化例
Q4_K_MもしかしたらQ5_K_Mパフォーマンスと精度のバランス。 - 極端に少ないメモリーデバイス(CPU動作など) →選択Q2またはQ3の定量化例
Q2_K_LもしかしたらQ3_K_Mメモリフットプリントを削減する。 - 高性能GPUサーバー→選択Q6またはQ8の定量化例
Q6_KもしかしたらQ8_0より質の高い推論を得ることができる。 - 最も効果的→選択
F16バージョンは、かなりのストレージ(約60GB以上)を必要とする。
フリーGPU推奨インストールバージョン
Q2_K_L
DeepSeek-R1 32Bのインストールを開始します。
GPUをインストールするまで無料で入手する方法から オーラマ 読み飛ばす、あるいは読む:無料のGPUパワーでDeepSeek-R1オープンソースモデルをオンライン展開前回のチュートリアルとの違いは、インストール・コマンドを少し変えただけだからだ。
Ollamaで特定の量子化されたバージョンをインストールする方法に直行する。ありがたいことに、Ollamaはインストール・プロセス全体を極限まで簡略化しており、覚えるべきインストール・コマンドは1つだけだ。
1.huggingface定量的バージョニングモデルの基本コマンド形式のインストール
次のインストール・コマンドの書式を覚えておいてください。
ollama run hf.co/{username}:{reponame}
2.定量版の選択
すべての量的バージョンのリスト: https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main
このインストールでは、Q5_K_M(デモ用です。この場合も、GPU推奨の無料版をインストールしてください!(Q5のインストールには23Gのハードディスク容量が必要です。)
3.スプライス取り付けコマンド

{ユーザー名}=unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF
{レポ名}=Q5_K_M
完全なインストール・コマンドを取得するためにスプライスする:ollama run hf.co/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q5_K_M
4.Ollamaでインストールを実行する
インストール・コマンドを実行する

ネットワーク障害が発生するかもしれない(幸運を祈る)。
まだ動作しませんか?以下のコマンドを実行してみてください(国内のミラーアドレスに切り替えてください):ollama run https://hf-mirror.com/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q5_K_M
公式アドレスを使ってからミラーアドレスを使うのではなく、ミラーアドレスを使ってダウンロードすればいいのでは?
統合されたインストールの方が速いからだ!
もちろん、この数値化されたバージョンは必要ないかもしれないが、より最近の一般的な無修正バージョンはこちら: ollama run huihui_ai/deepseek-r1-abliterated:14b
5.Ollamaを外部リリースにアクセス可能にする
ターミナルでコマンドを入力して、Ollamaポートを確認する。
ollama serve
11414または6399
ngrokのインストール
curl -sSL https://ngrok-agent.s3.amazonaws.com/ngrok.asc \ | tee /etc/apt/trusted.gpg.d/ngrok.asc >/dev/null \ && echo "deb https://ngrok-agent.s3.amazonaws.com buster main" \ | tee /etc/apt/sources.list.d/ngrok.list \ && apt update \ && apt install ngrok
キーとパーマネント・リンクを入手
ngrok.comにアクセスしてアカウントを登録し、ホームページでキーとパーマネントリンクを入手する。

キーをインストールし、外部アクセスアドレスを有効にする
クライアントで以下のコマンドを入力する:
ngrok config add-authtoken 这里是你自己的密钥
外部アクセスを開くには、次のコマンドを入力し続ける:6399このポートは皆と異なる場合があります、チェックし、自分自身を変更する
ngrok http --url=condor-known-ferret.ngrok-free.app 6399
成功すると、ターミナルに次のように表示されます。

https://condor-known-ferret.ngrok-free.app、モデル・インターフェースのアクセス・アドレスです。これを開くと、以下の内容が表示されます。

利用する
https://condor-known-ferret.ngrok-free.app如何使用?
これを行う最も簡単な方法は、以下をインストールすることである。 ページアシスト このツールは、ブラウザのプラグインとしてインストールされる。
コンフィグ
見せる ページアシスト その後、以下のインターフェイスが表示されます。

通常、モデルは自動的にロードされます。

試験

© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません