わずか140億(14B)のパラメータを持つPhi-4は、革新的な学習方法と高品質なデータにより、いくつかの大規模モデルに匹敵する、あるいはそれを上回る性能を示しています。本論文では、Phi-4のアーキテクチャ、特徴、トレーニング方法、実世界のアプリケーションやベンチマークにおける性能について詳しく説明します。
https://github.com/xinyuwei-david/david-share.git
I. 能力を測る指標を見る

o1とPhi-4を比較する3つの質問を測定する。
最初の質問だ:
ピーフォー

o1

二つ目の質問だ:
ファイ-4

o1:
3つ目の質問だ:
ファイ-4

o1.
和が90であることが分かっている5つの連続した偶数の平均を求めなさい。ステップ1:未知数の設定この5つの連続した偶数を最初の偶数: ( n - 4 )2番目の偶数: ( n - 2 )3番目の偶数: ( n )第4の偶数: ( n + 2 )5番目の偶数: ( n + 4 )(偶数は互いに2ずつ異なるので、隣り合う偶数はこのように表すことができる)。ステップ2:方程式の合計タイトルによれば、5つの数字の合計は90である:[(n - 4) + (n - 2) + n + (n + 2) + (n + 4) = 90]ステップ3:方程式の簡略化類は友を呼ぶ:[5n = 90]ステップ4:nについて解く[n = frac{90}{5} = 18]ステップ5:5つの偶数を見つける最初の偶数: ( 18 - 4 = 14 )2番目の偶数:(18 - 2 = 16)3番目の偶数: ( 18 )第4の偶数:( 18 + 2 = 20)5番目の偶数: (18 + 4 = 22)ステップ6:平均値の算出平均は合計を数で割ったものに等しい:[text{mean} = frac{14 + 16 + 18 + 20 + 22}{5} = frac{90}{5} = 18]回答これら5つの連続する偶数の平均は18である。
こうして見ると、やはりファイ4の推理は正しい。
ファイ-4 モデル・アーキテクチャ
1.トランス・ベースのデコーダー・アーキテクチャ
ファイ-4は、以下のようなシステムを採用している。 変圧器 な デコーダのみ このアーキテクチャはGPTファミリーのモデルに似ている。このアーキテクチャは、テキストシーケンスの長期的な依存関係を効果的に捕捉するために自己注意メカニズムを利用し、自然言語生成タスクに優れている。
2. パラメーターのサイズとレイヤー数
- パラメータの総数: 140億ドル(14B) パラメーター
- モデルフロアの数:40
3.コンテキストの長さ
- 最初のコンテキストの長さ: 4,096 トークン
- 中期トレーニングの延長: トレーニングの中間段階で、ファイ-4のコンテキストの長さは次のように延長された。 16,000 トークン(16K)は、このモデルの長文処理能力を向上させる。
4.用語集と辞書
- スプリッター: OpenAIの tiktokenスプリッター同社は多言語をサポートし、より優れたスプリットワード効果を持っている。
- 用語集のサイズ: 100,352これには、予約された未使用のトークンも含まれる。
III.注意のメカニズムと位置コーディング
1.グローバルな注意メカニズム
ファイ4使用 フルアテンションメカニズムつまり、自己アテンションはコンテクストのシーケンス全体に対して計算される。これは、先行モデルであるPhi-3-mediumが2,048個のコンテクストを使用するのとは対照的である。 トークン 一方、Phi-4は4,096個のトークン(初期)と16,000個のトークン(拡張)のコンテクストに対して直接グローバルな注意の計算を行い、長距離依存性を捉えるモデルの能力を向上させている。
2.ロータリーポジションエンコーディング(RoPE)
より長いコンテクストをサポートするために、ファイ4はトレーニングの途中で次のように変更された。 ロータリー・ポジション・エンベデッド(RoPE) 基本周波数の
- 基本周波数の調整: RoPEの基本周波数を 250,00016Kのコンテキスト長に対応するため。
- 役割 RoPEは、長いシーケンスにおける位置エンコーディングの有効性を維持するのに役立ち、より長いテキストで良好なパフォーマンスを維持することを可能にする。
IV.トレーニングの戦略と方法
1.データ品質の優先順位付けの概念
ファイ-4のトレーニング・ストラテジーは以下に基づいている。 データの質 を中核としています。インターネット上の有機的なデータ(例:ウェブコンテンツ、コードなど)を用いて事前に訓練された他のモデルとは異なり、ファイ-4は訓練プロセス全体を通して戦略的に以下のデータを導入する。 合成データ.
2.合成データの作成と応用
合成データ は、ファイ-4の事前トレーニングと中間トレーニングで重要な役割を果たした:
- 複数のデータ生成技術:
- マルチエージェント・プロンプティング: データの多様性は、データを共同生成する複数の言語モデルやエージェントの使用によって豊かになる。
- セルフ・リビジョン・ワークフロー: モデルは初期出力を生成した後、自己評価と修正を繰り返し、出力の質を向上させる。
- 指導の逆転: 既存の出力から対応する入力命令を生成することで、モデルが命令を理解し生成する能力を高める。
- 合成データの利点:
- 構造化された進歩的な学習: 合成データは、難易度と内容を正確にコントロールし、モデルが複雑な推論と問題解決スキルを学習するよう徐々に導く。
- トレーニング効率の向上: 合成データを生成することで、モデルの弱点に的を絞ったトレーニングデータを提供することができる。
- データ汚染を避ける: 合成データが生成されるため、学習データにレビューセットの内容が含まれるリスクは回避される。
3.オーガニック・データのファイン・スクリーニングとフィルタリング
合成データに加え、ファイ4は複数のソースから高品質なデータを慎重に選択し、フィルタリングすることに重点を置いている。 オーガニック・データ::
- データソース ウェブコンテンツ、書籍、コードライブラリ、学術論文などの紹介。
- データのフィルタリング:
- 低品質なコンテンツを削除する: 自動および手動の方法を使用して、無意味、不正確、重複または有害なコンテンツをフィルタリングする。
- データ汚染を防ぐ: ハイブリッドn-gramアルゴリズム(13-gramと7-gram)が重複排除と汚染排除に使用され、トレーニングデータにレビューセットの内容が含まれないようにした。
4.データミキシング戦略
Phi-4は、トレーニングデータの構成において、以下の比率で最適化された:
- 合成データ: 手中に収める 40%.
- ウェブ・リライト 手中に収める 15%新しいトレーニングサンプルの場合、高品質のウェブコンテンツから書き換えられて新しいトレーニングサンプルが生成されます。
- オーガニック・ウェブのデータ: 手中に収める 15%ウェブコンテンツは、その価値のために選ばれた。
- コードデータ: 手中に収める 20%公開コードベースと生成されたコード合成データを含む。
- ターゲットを絞った買収: 手中に収める 10%学術論文、専門書、その他価値の高いコンテンツを含む。
5.多段階トレーニングプロセス
トレーニング前の段階:
- 目的 基礎となる言語理解と生成能力をモデル化する。
- データ量: 予約する 10兆(10T) トークン
中期トレーニング段階:
- 目的 長文処理を改善するために文脈の長さを拡張する。
- データ量: 2,500億ドル(2,500B) トークン
トレーニング後の段階(微調整):
- スーパーバイズド・ファイン・チューニング(SFT): 高品質なマルチドメインデータを使用した微調整により、モデルの指示に従う能力と回答の質が向上する。
- 直接選好最適化(DPO): 用いる Pivotalトークン・サーチ(PTS) などの方法で、モデル出力をさらに最適化する。
V. 革新的なトレーニング手法
1.ピボタル・トークン・サーチ(PTS)
PTSの方法論 は、ファイ4のトレーニングプロセスにおける大きな革新である:
- 原則: 生成プロセスにおいて、答えの正しさに大きな影響を与える重要なトークンを特定することで、これらのトークンに関する予測を最適化することを目標としたモデルです。
- アドバンテージだ:
- トレーニング効率の向上: 結果に最も大きな影響を与える部分に最適化を集中させることで、効果は倍増する。
- モデル性能の向上: 重要な意思決定ポイントでモデルが正しい選択をするのを助け、アウトプットの全体的な質を向上させる。
2.直接選好最適化(DPO)の改善
- DPO方式: モデルの出力が人間の嗜好とより一致するように、嗜好データを使って直接最適化が行われる。
- イノベーション・ポイント
- PTSとの組み合わせ: DPOにPTSで生成されたトレーニングデータのペアを導入することで、最適化が改善される。
- 指標の評価: キー・トークンに関するモデルのパフォーマンスを評価することで、最適化をより正確に測定する。
モデルの特徴と利点
1.優れたパフォーマンス
- 小さなモデル、大きな能力: パラメータ・スケールは 14Bしかし、Phi-4は、いくつかのレビューベンチマーク、特に推論と問題解決タスクで好成績を収めている。
2.優れた推理力
- 数学と科学の問題解決: ある ジーピーキューエーそして数学 このようなベンチマークテストでは、ファイ-4は教師モデルよりもさらに良いスコアを出している。 GPT-4o.
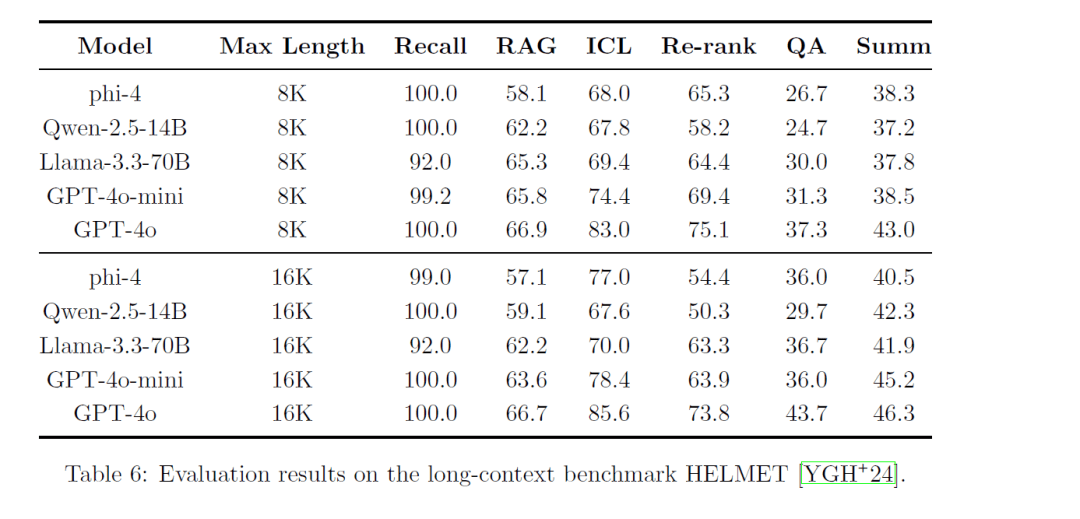
3.長い文脈処理能力
- コンテキストの長さの延長: トレーニングの途中でコンテキストの長さを拡大することで、次のようになる。 16,000 トークン、ファイ4は長文や長距離の依存関係をより効率的に処理できる。
4.多言語サポート
- 複数の言語をカバー: トレーニングデータは ドイツ語, スペイン語, フランス語, ポルトガル語, イタリア語, ヒンディー語, 日本語 その他多くの言語
- 言語横断的な能力: 翻訳や言語横断クイズなどのタスクを得意とする。
5.セキュリティとコンプライアンス
- 責任あるAIの原則: 開発プロセスは、マイクロソフトの「責任あるAIの原則」に厳格に従い、モデルのセキュリティと倫理に焦点を当てている。
- データの汚染除去とプライバシー保護: 厳密なデータ重複排除とフィルタリング戦略により、機密コンテンツがトレーニングデータに含まれないようにする。
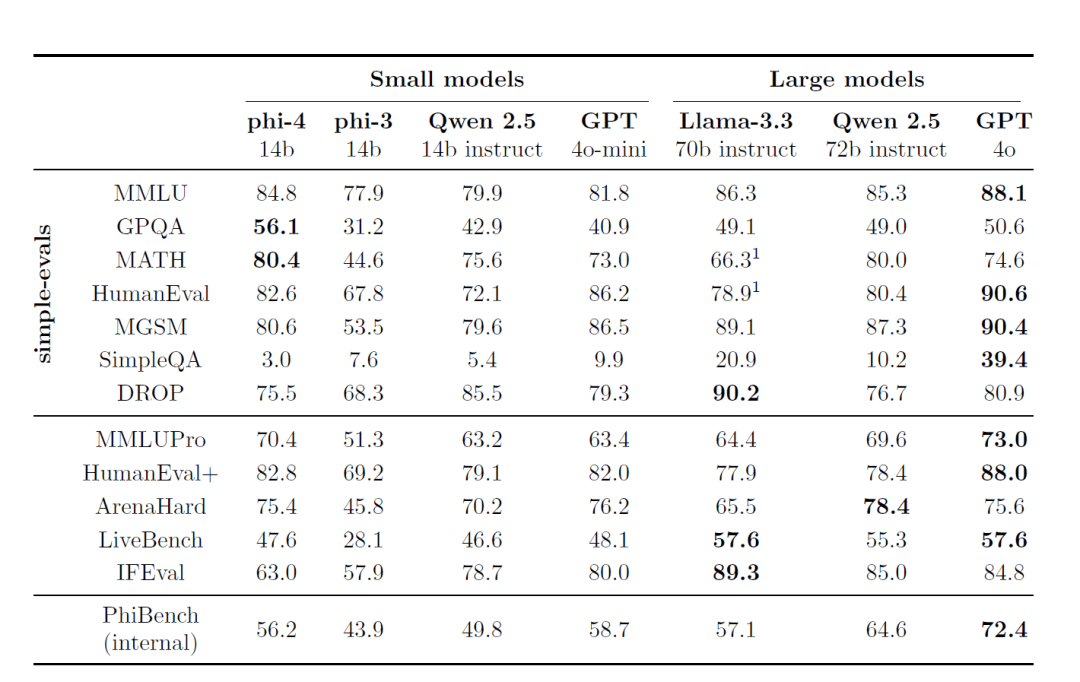
ベンチマークとパフォーマンス
1.外部ベンチマーキング
Phi-4は、一般に公開されているいくつかのレビューベンチマークでトップクラスの性能を示している:
- MMLU(マルチタスク言語理解): 複雑なマルチタスクの理解力テストで優秀な成績を収める。
- GPQA(大学院レベルのSTEMクイズ): は、難しいSTEMクイズで優秀な成績を収め、一部の大型模型よりも高い得点を獲得した。
- MATH(数学競技): 数学的な問題解決において、ファイ-4は強力な推論能力と計算能力を発揮する。
- HumanEval / HumanEval+(コード生成): コード生成と理解タスクにおいて、ファイ-4は同サイズのモデルを凌駕し、さらに大きなモデルに近づいている。
2.内部評価スイート(PhiBench)
モデルの能力と欠点を知るために、チームは専門的な内部評価スイートを開発した。 ファイベンチ::
- 多角化という課題: コードデバッグ、コード補完、数学的推論、エラー識別を含む。
- モデルの最適化に関するガイダンス: PhiBenchのスコアを分析することで、チームはモデルの改良を目標とすることができた。
セキュリティと責任
1.厳格なセキュリティ調整戦略
ファイ4の開発は、マイクロソフトの 責任あるAIのための原則トレーニング中や微調整中のモデルの安全性と倫理性に重点を置いている:
- 有害なコンテンツからの保護: ポストトレーニングフェーズに安全微調整データを含めることで、モデルが不適切なコンテンツを生成する確率を減らす。
- レッドチームテストと自動評価 広範なレッドチームテストと自動化されたセキュリティ評価が実施され、数十の潜在的なリスクカテゴリーが網羅された。
2.データの汚染除去とオーバーフィッティングの防止
- データ除染戦略の強化: 13-gramと7-gramのハイブリッドアルゴリズムを使用し、学習データとレビューベンチマークの重複の可能性を排除し、モデルのオーバーフィッティングを防ぐ。
IX.トレーニングリソースと時間
1.トレーニング時間
公式報告書にはファイ-4の総トレーニング時間は明記されていないが、考えてみてほしい:
- モデルスケール: 14Bパラメータ。
- トレーニングデータの量: プレトレーニングフェーズ10Tトークン、ミッドトレーニング250Bトークン。
トレーニングの全過程にかなりの時間を要したことが推測できる。
2. GPUリソースの消費
| GPU | 1920 H100-80G |
| トレーニング時間 | 21日 |
| トレーニングデータ | 9.8T トークン |
X. 用途と限界
1.適用シナリオ
- Q&Aシステム: Phi-4は、複雑なクイズタスクで優れたパフォーマンスを発揮し、あらゆる種類のインテリジェントなクイズアプリケーションに適しています。
- コードの生成と理解: プログラミング作業に優れており、コードの個別指導、自動生成、デバッグなどの場面で使用できる。
- 多言語翻訳と処理: グローバル化した言語サービスのための多言語サポート。
2.潜在的な限界
- 知識カットオフ: モデルの知識はトレーニングデータで途切れ、トレーニング後に発生した事象については何も知らないかもしれない。
- ロングシークエンスに挑戦: コンテキストの長さが16Kに拡張されたとはいえ、より長いシーケンスを扱う際にはまだ課題があるかもしれない。
- リスク管理: 厳格なセキュリティ対策にもかかわらず、モデルは敵対的な攻撃を受けたり、不適切なコンテンツを不用意に生成したりする可能性がある。
Phi-4の成功は、大規模言語モデルの開発におけるデータの質とトレーニング戦略の重要性を実証しています。革新的な合成データの生成方法、慎重な学習データの混合戦略、高度な学習技術により、Phi-4は小さなパラメータサイズを維持しながら優れた性能を達成しています:
- 推理力はずば抜けている: 数学、科学、プログラミングの分野に秀でる。
- 長文処理: コンテキストの長さが長くなったことで、このモデルは長いテキストを処理するタスクで有利になった。
- 安全と責任: 責任あるAIの原則を厳守することで、モデルの安全性と倫理性を確保している。
Phi-4は、小さなパラメトリック定量モデルの開発における新たなベンチマークを設定し、データの質と学習ストラテジーに焦点を当てることで、より小さなパラメータスケールでも優れた性能を達成できることを実証した。
参考文献:/https://www.microsoft.com/en-us/research/uploads/prod/2024/12/P4TechReport.pdf