序文
この2年間で、検索・拡張生成(RAG、Retrieval-Augmented Generation)技術は徐々に強化された知能の中核的な要素となってきた。検索と生成の2つの機能を組み合わせることで、RAGは外部知識を導入することができ、その結果、複雑なシナリオにおける大規模モデルの適用により多くの可能性を提供することができる。しかしながら、実用的な着地シナリオにおいては、検索精度の低さ、ノイズ干渉、想起の完全性、不十分な専門性などの問題がしばしば発生し、深刻なLLM錯覚につながる。本論文では、実際の着陸シナリオにおけるRAGの知識処理と検索の詳細に焦点を当て、最終的に想起精度を向上させるためにRAG Pineline linkを最適化する方法について述べる。
RAGスマートQ&Aアプリを素早く構築するのは簡単だが、実際のビジネスシナリオに落とし込むには多くの準備が必要だ。
1.RAGキープロセス・ソースコードの解釈
センター知識処理歌で応えるラグ主要なプロセスをいくつか紹介しよう:
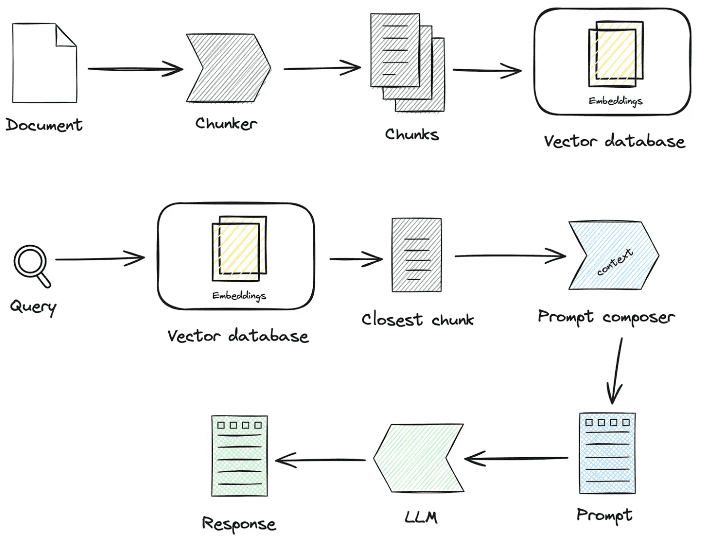
1.知識処理
知識ロード→知識スライシング→情報抽出→知識処理(埋め込み/グラフ/キーワード)→知識ストレージ
- ナレッジ・ローディング
#知識ファクトリーでインスタンス化 知識ファクトリ -> create() -> load() -> ドキュメント - ナレッジ - マークダウン - pdf - docx - txt - html - pptx - URL - ...
拡大する方法
from abc import ABC from typing import リスト, Any class Knowledge(ABC): def load(self) -> List[Document]. def load(self) -> List[Document]. """データローダから知識をロードする。"""" パス クラスメソッド def document_type(cls) -> Any. """ドキュメントタイプを取得する。""" """ドキュメントタイプを取得する""" クラスメソッド def support_chunk_strategy(cls) -> リスト[ChunkStrategy]。 """サポートされているチャンクストラテジーを返す。""" return [ ChunkStrategy.CHUNK_BY_SIZE、 ChunkStrategy.CHUNK_BY_PAGE, """ return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy. CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_PAGE ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER、 ChunkStrategy.CHUNK_BY_SIZE ChunkStrategy.CHUNK_BY_SEPARATOR、 ChunkStrategy.CHUNK_BY_SEPARATOR, ] ChunkStrategy.CHUNK_BY_SEPARATOR. クラスメソッド def default_chunk_strategy(cls) -> ChunkStrategy. """ デフォルトのチャンク戦略を返す 戻り値 ChunkStrategy: デフォルトのチャンク戦略 """ return ChunkStrategy.CHUNK_BY_SIZE
- ナレッジスライス
ChunkManager: ユーザーが指定したチャンキングポリシーとチャンキングパラメータに基づいて、ロードされた知識データを対応するチャンクプロセッサにルーティングし、割り当てを行う。
class ChunkManager. 「チャンクのマネージャー。 def __init__( self. knowledge: Knowledge, chunk_parameter. chunk_parameter: Optional[ChunkParameters] = None、 extractor: Optional[Extractor] = None、 ). """ 与えられた知識で新しいChunkManagerを作成します。 Args: knowledge: (Knowledge) 知識データソース。 chunk_parameter: (Optional[ChunkParameters]) チャンクパラメータ。 chunk_parameter: (Optional[ChunkParameters]) チャンクパラメータ。 extractor: (Optional[抽出器]) 要約に使用する抽出器。 """ self._knowledge = 知識 self._extractor = 抽出子 self._chunk_parameters = chunk_parameter または ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().名前 ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
拡張方法:インターフェイスで新しいスライス戦略をカスタマイズしたい場合
- 新しいスライス戦略
- 新しいスプリッター実装ロジック
class ChunkStrategy(Enum).
"""チャンク戦略Enum."""
chunk_by_size: _strategy_enum_type = (
RecursiveCharacterTextSplitter、"""RecursiveCharacterTextSplitter、"""チャンク戦略列挙型。
[
{
「param_name": "chunk_size"、
「param_type": "int"、
param_name": "chunk_size", "param_type": "int", "default_value": 512, "description": "データチャンクのサイズ".
"description": "処理に使用されるデータチャンクのサイズ"、
},
{
"param_name": "chunk_overlap", "param_type": "int": "chunk_type": "chunk_overlap", {
「param_type": "int", "default_value": 50
param_type": "int", { "default_value": 50、
"説明": "隣接するデータチャンク間のオーバーラップ量", }。
}
], "チャンクサイズ".
"チャンクサイズでドキュメントを分割", ), "chunk_value": 50
)
chunk_by_page: _strategy_enum_type = (
PageTextSplitter, _STRATEGY_ENUM_TYPE = (
[].
"page".
"ページごとにドキュメントを分割する"、
)
chunk_by_paragraph: _strategy_enum_type = (
ParagraphTextSplitter、 [
[
{
「param_name": "separator"、
「param_type": "string"、
"説明": "段落区切り"、
段落", "説明": "段落区切り", }。
"段落"、"段落による文書の分割"、"説明"。
"段落で文書を分割"。
)
chunk_by_separator: _strategy_enum_type = (
SeparatorTextSplitter、 [
[
{
"param_name": "separator"、
「param_type": "string"、
},
{
「param_name": "enable_merge", "param_type": "parameter_type", }, {
「param_type": "boolean", "default_value": False
「default_value": False、
"description": (
"セパレータで分割した後に chunk_size に従ってマージするかどうか"
"セパレータで分割した後、chunk_sizeに従ってマージするかどうか"
),
}
], "separator", " "セパレーターによる分割。", }, }。
"separator", "split document by separator"、
"セパレーターによる文書の分割".
)
chunk_by_markdown_header: _strategy_enum_type = (
MarkdownHeaderTextSplitter、
[],
「マークダウン・ヘッダー"、
"マークダウン・ヘッダでドキュメントを分割する"、
)
- 知識抽出
- ベクトル抽出→埋め込み、実装
埋め込みコネクタ
抽象メソッド def embed_documents(self, texts: List[str]) -> List[List[float]]. """検索ドキュメントを埋め込む""" 抽象メソッド def embed_query(self, text: str) -> List[float]. """クエリテキストを埋め込む。""" 非同期 def aembed_documents(self, texts: List[str]) -> List[List[float]]. """非同期に検索ドキュメントを埋め込む。"""" return await asyncio.get_running_loop().run_in_executor()。 なし, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]. """非同期の埋め込みクエリテキスト。"""" return await asyncio.get_running_loop().run_in_executor( なし, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}。
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen 埋め込みモデル, dbgpt/model/parameter.py をご覧ください。
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}。
## qianfan 埋め込みモデル, dbgpt/model/parameter.py をご覧ください。
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key} です。
- 知識グラフ抽出→知識グラフ
クラス TripletExtractor(LLMExtractor).
"""TripletExtractorクラス"""
def __init__(self, llm_client: LLMClient, model_name: str).
"""TripletExtractorを初期化する。"""".
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT).
TRIPLET_EXTRACT_PT = (
"以下にテキストを示します。
"可能な限り多くの知識トリプレットを" "抽出します。
「(主語、述語、目的語)の形式で抽出しなさい。\n"
ストップワードは避けてください。 主語、述語、目的語が1つもないことはあり" "ません。
"---------------------\n"
例
「本文:アリスはボブの母親です。
"三つ子:◆n(Alice, is mother of, Bob)◆n"
"文:アリスはリンゴを2個持っている。"
"三つ子:〚アリスはリンゴを2個持っています〛〛"
"文:アリスはボブからリンゴを1個もらいました。"ⅳ"
"三つ子:(ボブ、りんごを1個あげる、アリス)˶"
"文:アリスはボブに押された。"
"三つ子:(ボブ,押す,アリス)˶"
"文:ボブの母アリスはリンゴを2個持っています。"
"三つ子:(Alice, is mother of, Bob)ⅳ(Alice, has 2, apple)ⅳ"
"文:大きなサルが高い果物の木に登って、桃を3個とりました。"
"三つ子:♪猿、果物の木に登って)♪猿、桃を3個採りました"♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪"
"文:アリスはリンゴを2個持っていて、1個をボブにあげます。"
"三つ子:◆n"
"(アリス, 2個, りんご)ⅹ(アリス, 1個, ボブ)ⅹ"
"文:Philzは1982年にバークレーで設立されたコーヒーショップです。"
"三つ組:◆n"
"(Philz,は,コーヒーショップです)ⅳ(Philz,は,バークレーで創業しました)ⅳ"
"(フィルズ、1982年創業)Ⅼ"
"---------------------\n"
"テキスト:{text}n"
"三つ子:◆n"
)
-
- 逆インデックス抽出→キーワードセグメンテーション
- esのデフォルト辞書を使用することもできるし、esのプラグインモードを使用して辞書をカスタマイズすることもできる。
- 逆インデックス抽出→キーワードセグメンテーション
- ナレッジ・ストレージ
全体的な知識の持続性は一様に達成されるインデックス・ストア・ベース現在、ベクトル・データベース、グラフ・データベース、フルテキスト・インデキシングの3種類の実装を提供している。
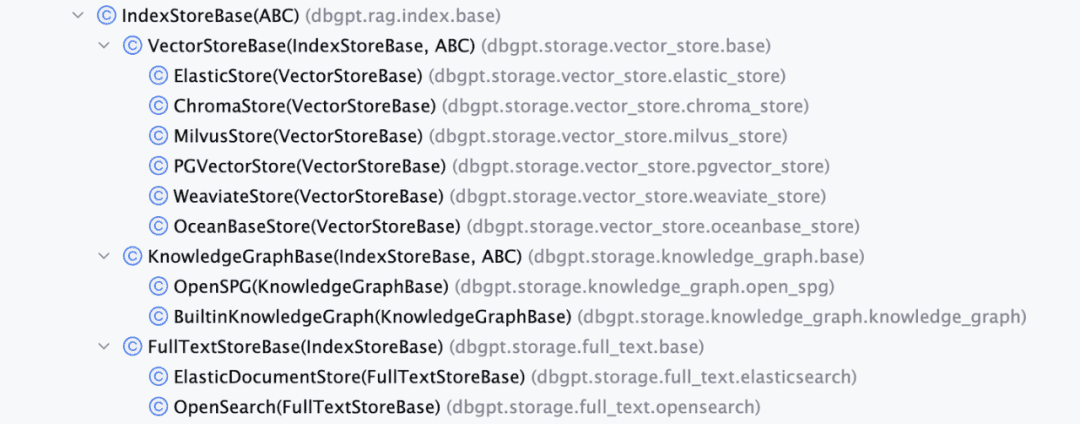
- VectorStore、ベクターデータベースのメインロジックはload_document()にあり、インデックススキーマの作成、ベクターデータの一括書き込みなどが含まれる。
# 基本クラス階層 - ベクターストアベース - クロマストア - Milvusストア - Oceanbaseストア - ElasticsearchStore - PGVectorStore # 基本クラス定義 class VectorStoreBase(IndexStoreBase, ABC). """ ベクターストア基底クラス。 """ 抽象メソッド def load_document(self, chunks: List[Chunk]) -> List[str]. """ インデックスデータベースにドキュメントをロードする。 """ パス 抽象メソッド async def aload_document(self, chunks: List[Chunk]) -> List[str]. """ 非同期にインデックスデータベースにドキュメントをロードする。 """ パス 抽象メソッド def similar_search_with_scores( self. text: str、 topk: int、 score_threshold: float、 filters: Optional[MetadataFilters] = None、 ) -> List[Chunk]. """ インデックスデータベースのスコアで同様の検索を行う。 """ パス def similar_search( def similar_search( text: str、 topk: int, filters: Optional[MetadataFilters] = None, def filters: Optional[MetadataFilters] = None、 ) -> List[Chunk]. """ インデックスデータベースで同様の検索を行う。 """ 戻り値 self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore、具象グラフ・ストアは、3値書き込みの実装を提供する。これは一般に、具象グラフ・データベースのクエリー言語を呼び出すことで行われる。例えば
TuGraphストア特定のCypher文が生成され、三項に基づいて実行される。
-
- グラフ・ストレージ・インターフェース GraphStoreBase は、グラフ・ストレージのための統一された抽象化を提供する。
MemoryGraphストア歌で応えるTuGraphストアを実装し、開発者がアクセスできるようにNeo4jインターフェースも提供している。
- グラフ・ストレージ・インターフェース GraphStoreBase は、グラフ・ストレージのための統一された抽象化を提供する。
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None.
"""トリプレットを追加"""
# ノードとリレーションシップをマージするクエリを作成する。
subj_query = f "MERGE (n1:{self._node_label} {{id:'{subj}'}})""
obj_query = f "MERGE (n2:{self._node_label} {{id:'{obj}'}})""
rel_query = (
f "MERGE (n1:{self._node_label} {{id:'{subj}'}})""
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# クエリの実行
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
-
- FullTextStore: es のインデックスを構築し、es 組み込みの単語分割アルゴリズムで単語分割を行い、es で keyword->doc_id の転置インデックスを構築する。
{
"分析": {
"analyser": {
"default": {
"タイプ": "標準"
}
}, "similarity": { "default": { "type": "standard" }.
"類似性": {
"custom_bm25": {
"タイプ": "BM25",
"k1": self._k1、
「b": self._b
}
}
}
self._es_mappings = { {プロパティ
"properties": {
「content": {
"type": "text", "similarity": "custom_bm25
"類似度": "custom_bm25"
},
「メタデータ": {
"タイプ": "キーワード"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2.知識検索
question -> rewrite -> similarity_search -> rerank -> context_candidates
次に、知識検索ですが、現在のコミュニティ検索ロジックは主に以下のステップに分かれています:クエリ書き換えパラメータを設定した場合、現在、大きなモデルを通して質問の書き換えのラウンドを与えます。リランクモデルを設定すると、粗いスクリーニングの後に細かいスクリーニングを行い、候補値をよりユーザの質問に関連したものにします。
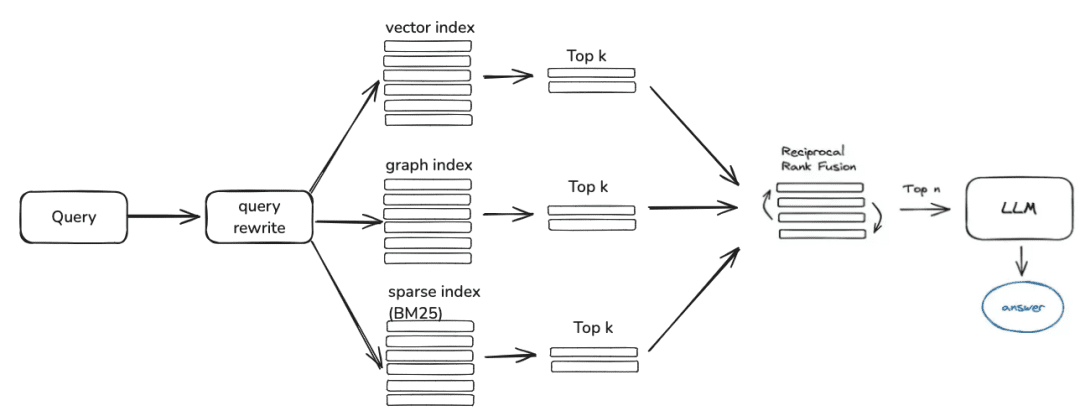
- エンベッディングレトリバー
クラス EmbeddingRetriever(BaseRetriever). """埋め込みレトリバー"""" def __init__( self, __init__( index_store: IndexStoreBase、 top_k: int = 4、 query_rewrite: Optional[QueryRewrite] = None、 rerank: Optional[Ranker] = None、 retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING、 ). EMBEDDING, ): パス 非同期 def _aretrieve_with_score( self. self, query: str, score_threshold: float, score_with_score( score_threshold: float, filters: Optional[MetadataFilters] = None, }. filters: Optional[MetadataFilters] = None, ) -> List[Chunk]. ) -> List[Chunk]. """ スコア付きの知識チャンクを取得します。 Args: query (str) Args: query (str): クエリテキスト。 score_threshold (float): スコアのしきい値。 filters: メタデータのフィルタ。 戻り値: List[Chunk]: スコアを持つチャンクのリスト List[Chunk]: スコアを持つチャンクのリスト。 """ queries = [クエリ] new_queries = await self._query_rewrite.rewrite( origin_query=query、 context=context、 nums=1 ) queries.extend(new_queries) 候補_with_score = [ self._similarity_search_with_score( query、 score_threshold、 filters, root_tracer.get_current_span_id() root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score、 new_candidates_with_score, query ) return new_candidates_with_score
-
- index_store: 特定のベクトル・データベース
- top_k: 返されるチャンク候補の数。
- query_rewrite: クエリ書き換え関数
- rerank: 並べ替え機能
- query:オリジナルクエリー
- score_threshold: スコア、デフォルトでは類似度スコアがしきい値以下のコンテキストをフィルタリングする。
- フィルターがある:
オプション[MetadataFilters]。メタデータ情報フィルターは、主に属性情報を通して前面にいくつかの不一致の候補情報をふるいにかけるために使用することができます。
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum). """ベクターストアメタデータフィルタ条件"""" AND = "かつ" OR = "または" クラス MetadataFilter(BaseModel). """メタデータフィルター""" key: str = フィールド( ..., description="フィルタリングするメタデータのキー"" ) オペレーター: FilterOperator = Field( default=FilterOperator.EQ、 説明="メタデータフィルタのオペレータ" ) 値:Union[str, int, float, List[str], List[int], List[float]] = Field( ..., 説明="フィルタリングするメタデータの値" )
- グラフ ラグ
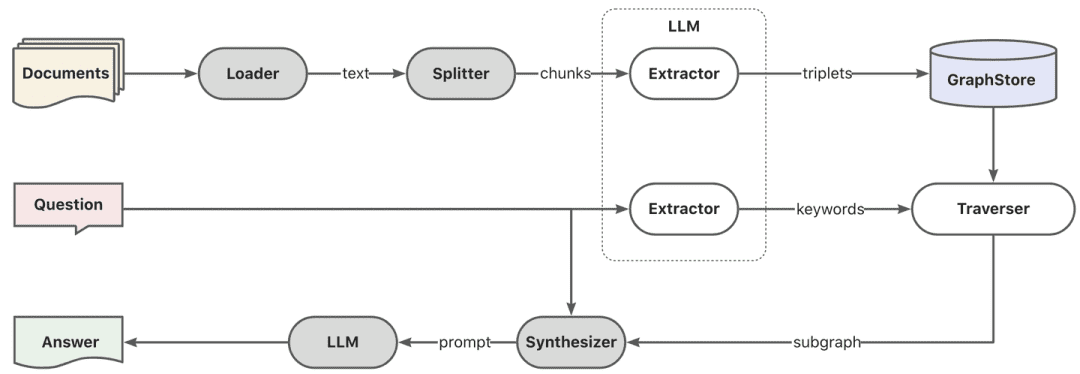
まず、キーワードの抽出はモデルを通じて行われ、ここでは単語分割のための伝統的なnlp技法、または単語分割のための大きなモデルを通じて行うことができ、次に、キーワードは、キーワード候補リストを見つけるために、展開を行うために同義語に従って行われ、キーワード候補リストに従って局所部分グラフを呼び出すために、探索法を呼び出す方がよい。
keyword_extract_pt = (
"以下は質問です。 質問が与えられたら、テキストから" "キーワードを抽出しなさい。
質問が与えられたら、テキストから最大" "のキーワードを抽出する。 使用できるキーワードの抽出に焦点を" "当てる。
質問に対する答えを検索するのに" "最適なキーワードを抽出することに集中する。
"キーワードの同義語や別名をできるだけ多く生成する"
「大文字、複数形、一般的な表現などを考慮する。
「一般的な表現などを考慮する。
「ストップワードは避ける。
「キーワードと類義語をカンマ区切りで入力してください。
「キーワードと類義語はセミコロンで区切る。
"---------------------\n"
例
「本文:アリスはボブの母親です。
"キーワード:Alice,mother,Bob;mummy"
"例:Philzは1982年にバークレーで創業したコーヒーショップです。
"キーワード:Philz,コーヒーショップ,バークレー,1982;コーヒーバー,コーヒーハウス"
"---------------------\n"
"テキスト:{text}n"
"キーワード:{text}n"
)
def explore(
self, subs.
subs: List[str], direct: Direction = Direction.
direct: 方向 = 方向.
depth: オプション[int] = なし, fan: オプション[int] = なし、
fan: Optional[int] = None, fan: Optional[int] = None、
limit: Optional[int] = None、
) -> グラフ.
"""グラフ上で探索する。""""
DBSchemaレトリバーこれは、ChatDataシナリオのスキーマリンク検索でもある。主にスキーマリンク方式で二段階の類似性検索を行い、最初に最も関連性の高いテーブルを見つけ、次に最も関連性の高いフィールド情報を見つける。
長所:この2段階検索は、大型ワイドテーブルの経験に関するコミュニティからのフィードバックに対応するためのものでもある。
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> リスト[チャンク]。
"""類似検索""
# スコアによる類似検索を行う
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# '分離された'メタデータを持つチャンクをフィルタリングする
not_sep_chunks = [ チャンクを指定する。
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [ 分離されたチャンク
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# 分離されたチャンクがなければ、分離されていないチャンクを返す
if not separated_chunks: return not_sep_chunks
return not_sep_chunks
# 分離されたチャンクからフィールドを取り出すためのタスクリストを作成する
タスク = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# 並行性制限を3にしてタスクを同時実行する
separated_result = run_tasks(tasks, concurrency_limit=3)
# 結果を結合して返す
戻り値 not_sep_chunks + separated_result
-
- table_vector_store_connector: 最も関連性の高いテーブルを検索する。
- field_vector_store_connector: 最も関連性の高いフィールドを検索する。
2.知識処理、知識検索の最適化アイデア
現在、RAGスマートクイズアプリにはいくつかのペインポイントがある:
- 知識ベース内の文書が増えると、検索にノイズが入り、想起精度は高くならない
- 不完全なリコールと完全性の欠如
- リコールとユーザーの質問意図はほとんど関連性がない
- 静的なデータにしか答えられず、知識に動的にアクセスできないため、退屈で間抜けな回答アプリケーションになってしまう。
1. 知識処理の最適化
非構造化/半構造化/構造化データの処理は、RAGアプリケーションの上限を決定する準備が整っているので、まずは知識処理、インデックス作成段階、そしてアイデアの方向性の主な最適化において、多くのきめ細かいETL作業を行う必要がある:
- 非構造化→構造化:知識情報を構造的に整理する。
- より豊かで多様な意味情報を抽出する。
1.1 ナレッジ・ローディング
目的:異なるタイプのデータをより多様な方法で識別するためには、ドキュメントの正確な構文解析が必要である。
最適化の推奨
- docxやtxtなどのテキストは、pdfやmarkdown形式で処理する前に、テキストの内容をよりよく抽出するための認識ツールを使用できるようにすることをお勧めします。
- テキストからテーブル情報を抽出する。
- 次の階層関係ツリーや他のインデックス作成方法のために、マークダウンやpdfのタイトルの階層情報を保持する。
- 画像リンク、数式、その他の情報を保持し、マークダウン形式に統一する。
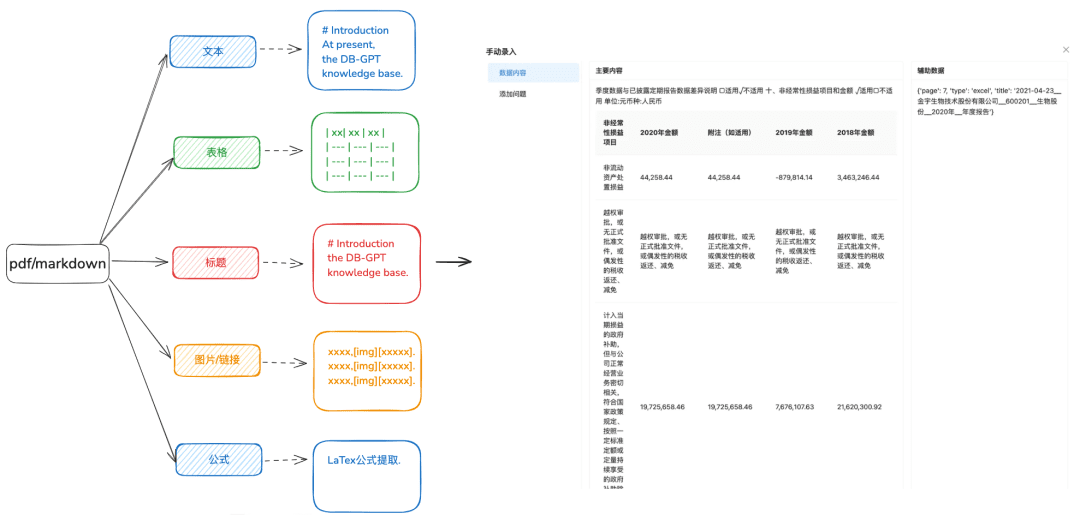
1.2 チャンクをできるだけそのままスライスする
目的:文脈の完全性と関連性を維持する。
チャンキングによって、LLMへのテキスト入力がトークンの制限を超えないようにする。
最適化の推奨
- 画像と表は別々のチャンクとして抽出され、表と画像のキャプションはメタデータのメタデータに保持される。
- 文書コンテンツは、ヘッダー階層またはMarkdownヘッダーに従って可能な限り分割され、可能な限りチャンクの整合性が保たれます。
- カスタムセパレーターがある場合は、カスタムセパレーターでスライスできます。
1.3 多様な情報抽出
文書の埋め込みベクトル抽出に加えて、他の多様な情報抽出は、文書のデータを強化し、大幅にRAGリコール効果を向上させることができます。
- ナレッジマップ
-
- 利点:1.NativeRAGの完全性の欠如に対処し、まだ錯覚の問題があり、知識の境界の完全性、知識の構造と意味論の明快さを含む知識の正確さは、類似検索の能力を意味的に補完するものである。
- シナリオ:知識の準備に制約が必要で、知識間の階層関係が明確に確立できる厳格な専門領域(ヘルスケア、O&Mなど)向け。
- どうすれば達成できるか:
1.大きなモデルに依存して、(エンティティ,リレーションシップ,エンティティ)の3項関係を抽出する。
2.知識グラフを構築するために、手動またはカスタムSOPプロセスによるビジネスルールを通じて、事前品質、構造化された知識の準備、クリーニング、抽出に頼る。
-
- ドク・ツリー
-
- 適用可能なシナリオ:コンテキストの完全性が不十分であるという問題を解決するだけでなく、セマンティクスとキーワードのみに基づいてマッチングを行い、ノイズを減らすことができる。
- 実現方法:タイトルレベルでチャンクのツリーノードを構築して多項ツリー構造を形成し、各レベルノードにはドキュメントのタイトルのみを格納し、リーフノードには特定のテキストコンテンツを格納する。このように、ツリー・トラバーサル・アルゴリズムを使用すると、ユーザーの質問が関連する非リーフ・タイトル・ノードにヒットした場合、関連する子ノードのデータを呼び出すことができる。こうすることで、チャンクの整合性不足の問題は発生しない。
-
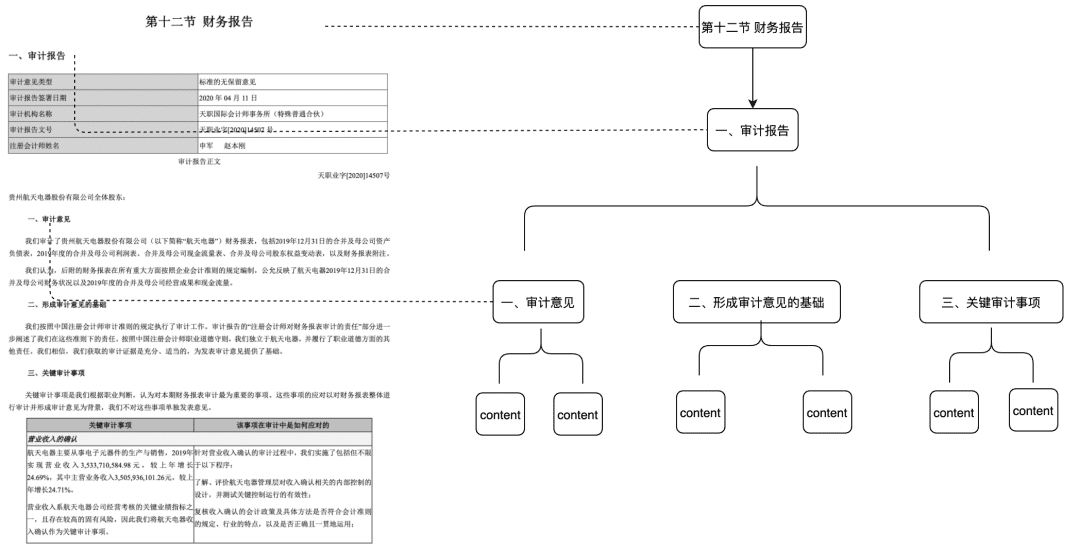
フィーチャーのこの部分は、来年早々にもコミュニティに投入する予定だ。
- QAペアの抽出には、定義済みまたはモデル抽出法によるQAペア情報のフロントエンド抽出が必要である。
-
- 適用されるシナリオ
-
-
- 検索および直接リコールの質問を打つ機能は直接ユーザーがほしい答えを、あるFAQのシナリオに適当取り出す、リコールの完全性は十分なシナリオでない。
-
-
- どうすれば達成できるか:
-
-
- 事前定義:各チャンクにいくつかの質問を事前に追加します。
- モデル抽出:コンテキストが与えられたら、モデルにQAペア抽出を行わせる。
-
- メタデータ抽出
-
- 実現方法:自社のビジネスデータの特性に応じて、タグ、カテゴリー、時間、バージョン、その他のメタデータ属性など、保持するデータの特性を抽出する。
- 適用可能なシナリオ:メタデータの属性に基づいて検索を事前にフィルタリングし、ノイズの大部分を取り除くことができる。
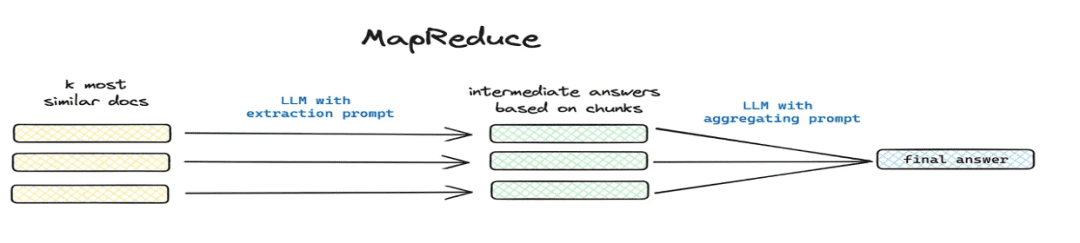
- 要約と抜粋
-
- 適用シナリオ:解決
この記事の内容は?属結論から言うとなどの世界的な問題シナリオがある。 - 実装方法:Mapreduceなどによる分割抽出、モデルによる各チャンクのサマリー情報の抽出。
- 適用シナリオ:解決
1.4 知識処理のワークフロー
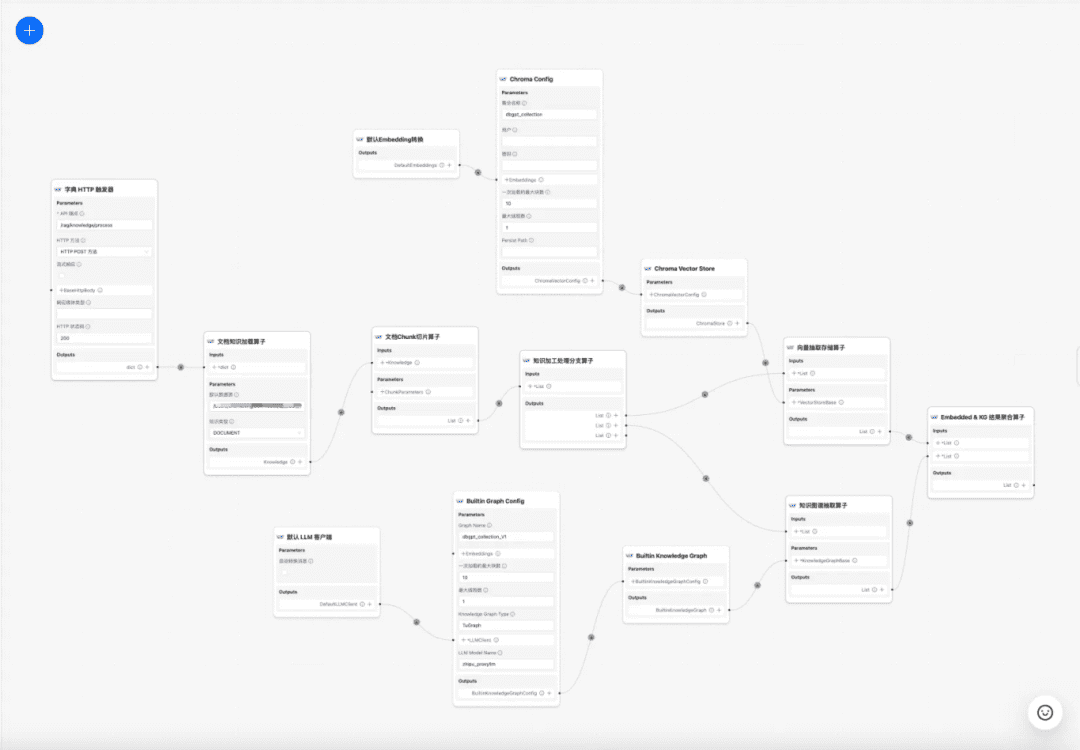
現在のところ DB-GPT 知識ベースは、文書のアップロード→構文解析→スライシング→埋め込み→知識グラフ三項抽出→ベクトルデータベース保存→グラフデータベース保存などの知識処理機能を提供するが、文書から複雑でパーソナライズされた情報を抽出する機能は持っていないため、知識処理ワークフローテンプレートを構築することで、複雑で、視覚的で、ユーザ定義可能な知識抽出、変換、処理プロセスを完成させることが望まれている。そこで、複雑で、視覚的で、ユーザー定義可能な知識抽出、変換、処理プロセスを完成させる知識処理ワークフローテンプレートを構築することが望まれている。
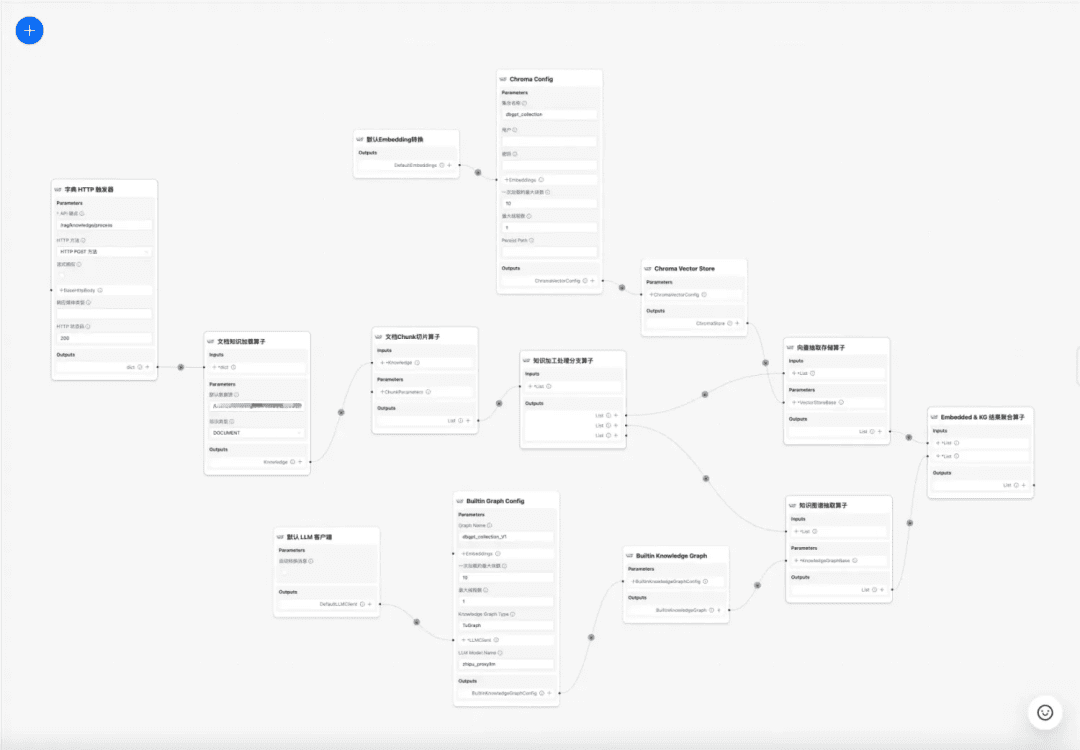
知識処理のワークフロー:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2.RAGプロセスの最適化RAGプロセスの最適化は、静的な文書のRAGと動的なデータの取得RAGに細分化され、現在のRAGのほとんどは、非構造化文書の静的な資産をカバーするだけでなく、Q&Aの多くのシナリオの実際のビジネスは、動的なデータ+静的な知識データを取得するツールを介して一緒にシナリオに答えるために、静的な知識を取得するだけでなく、RAGする必要があります。ツール資産ライブラリのツールの情報を取得し、動的データの取得を実行します。
2.1 静的知識RAGの最適化
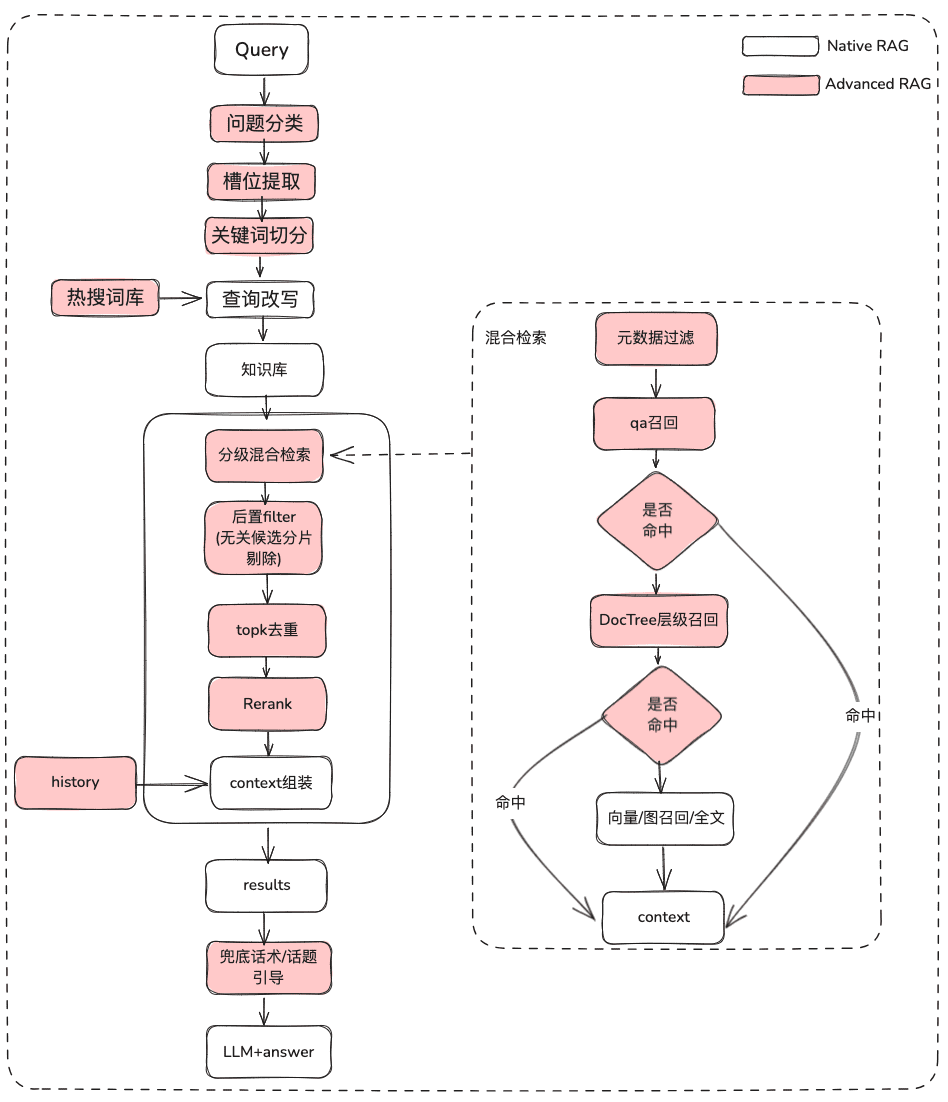
(1) 当初の問題の処理
目的:ユーザーのセマンティクスを明確にし、ユーザーの元の質問を、あいまいで意図的でないクエリから、意味の豊かな検索可能なクエリに最適化する。
- 生問題の分類。
-
- LLMの分類(
LLMExtractor) - 埋め込み+ロジスティック回帰を構築して2タワーモデルを実装する text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md at main - eosphoros-ai/DB-GPT-Hub
- LLMの分類(
-
-
- 先端: 良質の埋め込まれたモデルが必要、bge-v1.5-large を推薦して下さい
-
- ユーザーに質問を返し、意味が明確でない場合は、質問を明確にするためにユーザーに質問を投げ返す。
-
- 検索可能なシソーラスを使用して、意味的な関連性に基づいてユーザーに質問のショートリストを提案します。
- スロットの抽出。ユーザーの質問から、意図、ビジネス属性などの重要なスロット情報を取得することを目的とする。
-
- LLM抽出(
LLMExtractor)
- LLM抽出(
- 質問を書き換える
-
- ホット・サーチ・シソーラスの書き換え
- 重層的相互作用
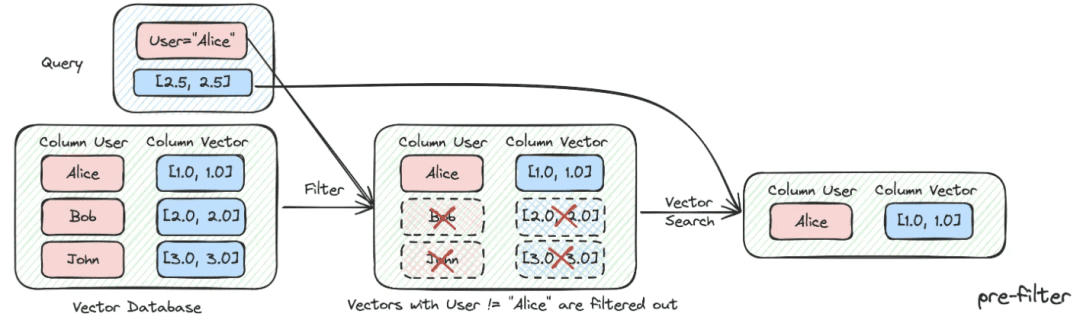
(2) メタデータのフィルタリング
インデックスを多くのチャンクに分割し、同じ知識空間に格納すると、検索効率が問題になる。例えば、ユーザが「浙江伊呉科技有限公司」の情報を求めるとき、他の会社の情報は思い出したくない。したがって、最初に会社名のメタデータ属性でフィルタリングできれば、効率と関連性が大幅に向上する。
非同期 def aretrieve( self, query: str, async query: str, async filters: Optional[MetadataFilters] = None ) -> List[Chunk]. """ 知識チャンクを取得します。 引数。 Args: query (str): 非同期クエリテキスト。 filters (Optional[MetadataFilters]): メタデータフィルター。 List[Chunk]: チャンクのリスト。 List[Chunk]: チャンクのリスト。 """ return await self._aretrieve(query, filters)
(3) マルチ・ストラテジー・ハイブリッド・リコール
- 優先度リコールに従って、さまざまなリトリーバーに優先順位を定義し、リトリーブされたらすぐにコンテンツを返す。
-
- キューに書き込まれるqa_retrieverやdoc_tree_retrieverのような異なる検索を定義し、キューの先入れ先出し特性によって優先的な検索を実現する。
-
クラスRetrieverChain(BaseRetriever)。 """レトリバーチェーンクラス""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, None retrievers: Optional[List[BaseRetriever]] = None、 executor: Optional[Executor] = None、 ). """レトリーバーチェーンのインスタンスを作成する。""" self._retrievers = retrievers または []. self._executor = executor または ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None). """実行 回収 与えられたクエリ、スコア閾値、フィルタで"""" for retriever in self._retrievers: candidate_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores. return candidates_with_scores
- 多知識インデックス/空間並列想起
-
- 想起の完全性を確保するために、さまざまな知識の索引形式による並列想起によって候補リストを取得する。
-
(4) ポストフィルター
粗いスクリーニングの候補者リストを通過した後、細かいスクリーニングでどのようにノイズを濾過するのか?
- 無関係な候補スライスの選別
-
- 適時性拒否
- ビジネス属性はカリングを満たさない
-
- トップク・デデュープ
- 並べ替え 粗いスクリーニングの想起だけでは不十分で、この時点で、検索結果の並べ替えを行うための戦略が必要である。例えば、組み合わせの関連性、マッチングなどの要素を再調整し、よりビジネスシナリオに沿った並べ替えを行うのである。このステップの後、LLMに結果を送り、最終的な処理を行うので、この部分の結果は非常に重要である。
- オープンソースのモデルや、ビジネス・セマンティックの微調整が可能なモデルなど、関連する並べ替えモデルを使用したファイン・スクリーニング。
## 再ランクモデル # RERANK_MODEL = bce-reranker-base #####RERANK_MODEL_PATH を設定しない場合、DB-GPT は RERANK_MODEL に基づいて EMBEDDING_MODEL_CONFIG からモデルパスを読み込みます。 # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 ##### 返す再ランク結果の数 # rerank_top_k = 5
-
- ビジネス RRF加重複合スコア カリング 異なる指標化されたリコールに基づく
スコア = 0.0 for q in queries: if d in result(q): if d in result(q) if d in result(q): score += 1.0 / (k + rank(result(q), d)) score += 1.0 / (k + rank(result(q), d)) スコアを返す # ここで # k はランキング定数 # q はクエリ集合中のクエリ # d は q の結果集合の文書である。 # result(q)はqの結果集合である。 # rank(result(q), d)はresult(q)内のdのランクで1から始まる。
(5) ディスプレイの最適化 + 客引き / トピック・リーダーシップ
- マークダウン書式を使ってモデルを出力させる
以下に示す既知の情報に基づき、規範的な制約に従い、ユーザーの質問に専門的かつ簡潔に答えなさい。 規範となる制約 1.既知の情報に画像、リンク、テーブル、コードブロック、その他の特別なマークダウンタグフォーマットが含まれている場合、回答には必ずこれらの画像、リンク、テーブル、コードタグのオリジナルテキストを含め、例えばそれらを破棄したり修正したりしないでください: - 画像フォーマット: ``. - リンク形式: `[xxx](xxx)` - 表形式: `|xxx|xxx|xxx`` - コード形式: ``xxx``. 2.提供された内容から答えが得られない場合、``知識ベースから提供された内容はこの質問に答えるには十分ではありません''と言ってください。 3.回答は1.2.3.に従って要約し、Markdown形式で表示することが望ましい。
2.2 動的知識RAGの最適化
ドキュメンテーションの知識は比較的静的であり、パーソナライズされた動的な情報に答えることはできない。
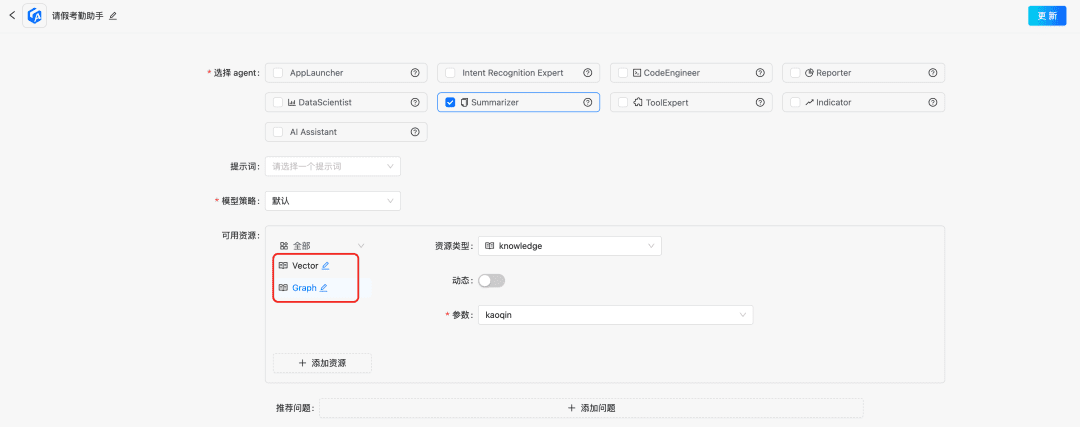
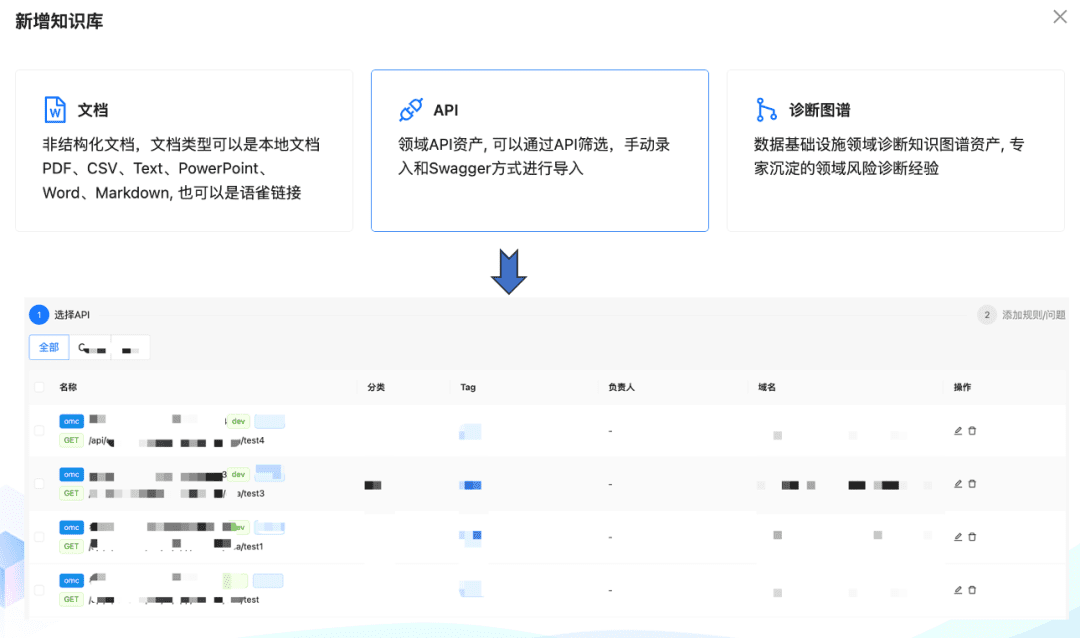
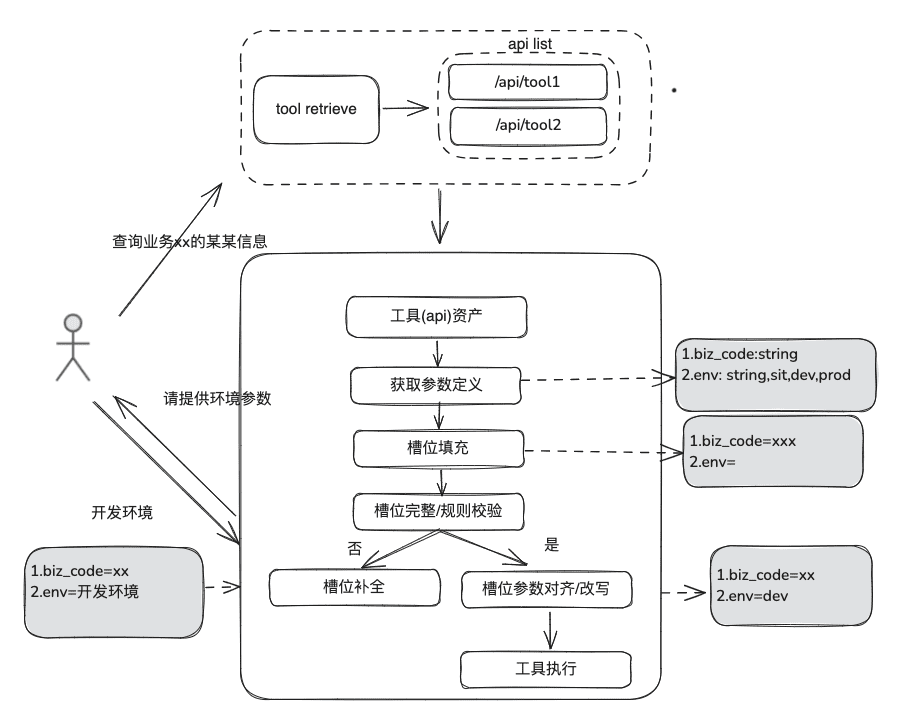
(1) ツール・アセット・ライブラリ
エンタープライズドメインのツール資産ライブラリを構築し、ツールAPI、様々なプラットフォームに散在するツールスクリプトを統合することで、インテリジェンスのエンドツーエンドの利用機能を提供する。例えば、静的知識ベースに加えて、ツールライブラリをインポートすることでツールを処理できる。
(2) ツール・リコール
ツール・リコールは、静的知識のためのRAGリコールの考え方に従ったものであり、ツール実行の結果を得るために、完全なツール実行ライフサイクルが使用される。
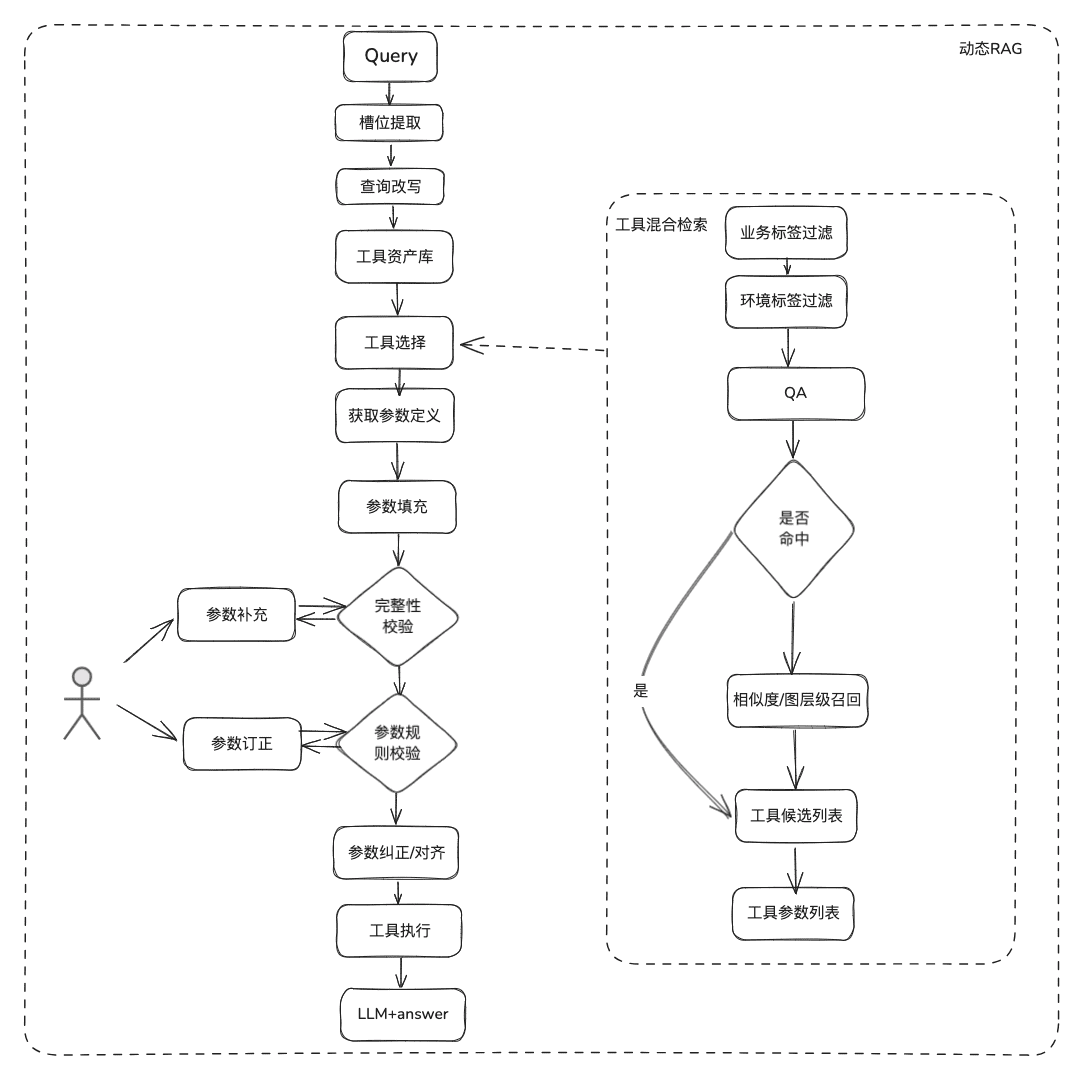
- スロットの抽出:従来のnlpでLLMを取得し、一般的なビジネスタイプ、環境マーカー、ドメインモデルパラメーターなど、ユーザーの問題を解析する。
- ツール選択:スタティックRAGに沿ったリコールで、ツール名リコールとツールパラメーターリコールという2つのメインレイヤーがある。
-
- ツール・パラメーター・リコールは、TableRAGのアイデアと同様、最初にテーブル名をリコールし、次にフィールド名をリコールする。
-
- パラメータ充填:スロットから抽出されたパラメータを、リコールのツールパラメータ定義に合わせる必要がある。
-
- コードで入力することもできるし、モデルに入力させることもできる。
- 最適化のアイデア:様々なプラットフォームツールの同じパラメータのパラメータ名は統一されておらず、ガバナンスに行くのは不便なので、まずドメインモデルデータ拡張のラウンドを実施することができ、全体のドメインモデルを取得した後、必要なパラメータが存在することを提案します。
-
- パラメータ校正
-
- 完全性チェック:パラメータ数の完全性チェックを行う。
- パラメータ・ルール・チェック:パラメータ名の型、パラメータ値、列挙などのルール・チェックを行う。
-
- パラメータ修正/調整、この部分は、主にユーザーとの対話の数を減らすために、ケースルール、列挙ルールなどを含む、ユーザーパラメータのエラー修正を自動完了することです。
2.3 RAGレビュー
スマートQ&Aプロセスを評価する際には、想起関連性の精度とモデルQ&Aの関連性を別々に評価し、RAGプロセスの改善すべき点を特定するために、それらを合わせて検討する必要がある。
指標の評価:
評価メトリクス LLMEvaluationMetric ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric(レトリーバー評価メトリック │ ├──RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └──RetrieverHitRateMetric
ラグRetrieverEvaluationMetric:-
レトリバー命中率メトリクスヒット率はRAGを測定する。レトリーバー検索結果の上位k個の文書に現れる想起の割合。レトリーバーMRRMetric:平均順位各クエリの精度は、検索結果における最も関連性の高い文書のランキングを分析することで算出される。具体的には、すべてのクエリに対する関連文書の逆順位の平均である。例えば、最も関連性の高い文書が1位であれば、その逆順位は1、2位であれば1/2、といった具合である。レトリーバー類似度メトリック類似度メトリクスは、想起されたコンテンツと予測されたコンテンツとの類似度を計算するために計算される。
-
モデル・ジェネレーション回答指標。
回答関連性メトリックインテリジェントボディアンサーは、インテリジェントボディアンサーの回答がユーザーの質問にどの程度マッチするかによって、関連性を評価します。関連性の高い回答は、モデルがユーザーの質問を理解することを必要とするだけでなく、質問に密接に関連する回答を生成することも必要とします。これはユーザーの満足度とモデルの有用性に直接影響します。
3.RAGランディング・ケース共有
1.データ・インフラ分野のRAG
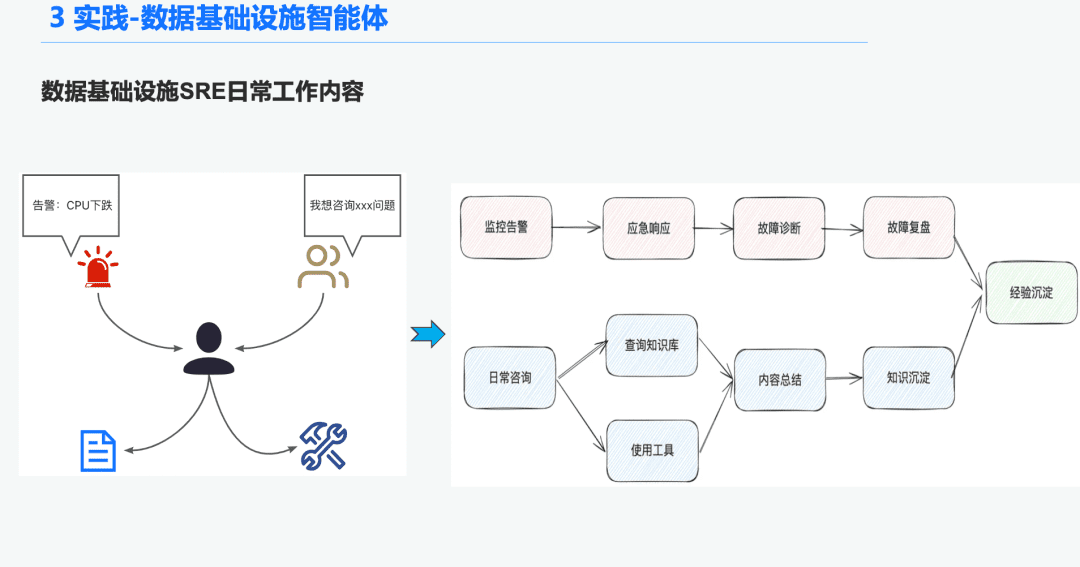
1.1 O&Mインテリジェンス機関の背景
データインフラストラクチャの分野では、毎日大量のアラートを受け取る運用 SRE が多いため、緊急事態への対応に多くの時間が費やされ、それがトラブルシューティングにつながり、さらにトラブルシューティングのレビューにつながり、それが経験につながる。また、ユーザーからの問い合わせに対応する時間もあり、ツールの使用に関する知識と経験を駆使して質問に答える必要がある。
そこで私たちは、データ・インフラストラクチャーのための一般的なインテリジェンスを構築することで、アラーム診断や質問への回答といったこれらの問題を解決したいと考えています。
1.2 厳格かつ専門的なRAG
従来のRAG+エージェント技術は、汎用的で決定論的でないシングルステップのタスクシナリオを解決することができる。しかし、データインフラの分野で専門的なシナリオに直面した場合、検索プロセス全体が決定論的で専門的かつ現実的でなければならず、ステップバイステップの推論が必要となる。
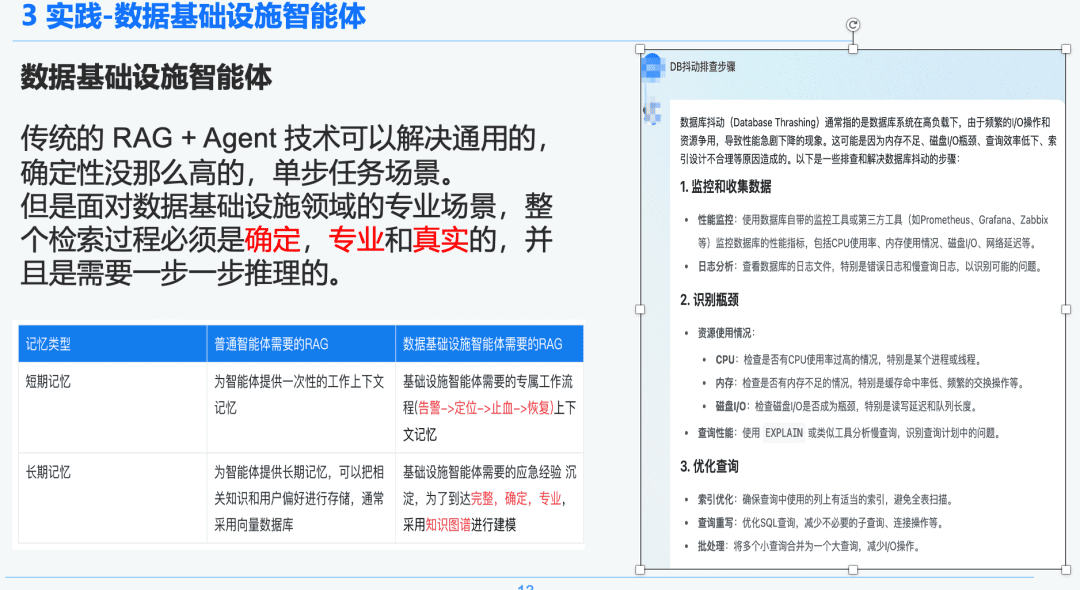
右側は、NativeRAGによる一般化された要約である。これは、それほど多くのドメイン知識を持たないC-suiteユーザーにとっては有益な情報かもしれないが、専門家にとっては、この答えの部分はあまり意味をなさないだろう。
そこで、一般的なインテリジェンスとデータインフラストラクチャのインテリジェンスの違いをRAGで比較する:
- 汎用インテリジェンス:従来のRAGは、それほど知的な厳密さや専門知識を必要とせず、カスタマーサービス、観光、プラットフォームのQ&Aボットなど、一部のビジネスシナリオに適している。
- データ・インフラ・インテリジェンス本体:RAGプロセスは厳格で専門的であり、(警報→発見→止血→回復)を含むコンテキストを持つ専用のRAGワークフローと、階層関係を確立するために専門家によって促されたQ&Aと緊急対応経験の構造化された抽出を必要とする。そのため、私たちはナレッジグラフをデータベアラーとして選択しました。
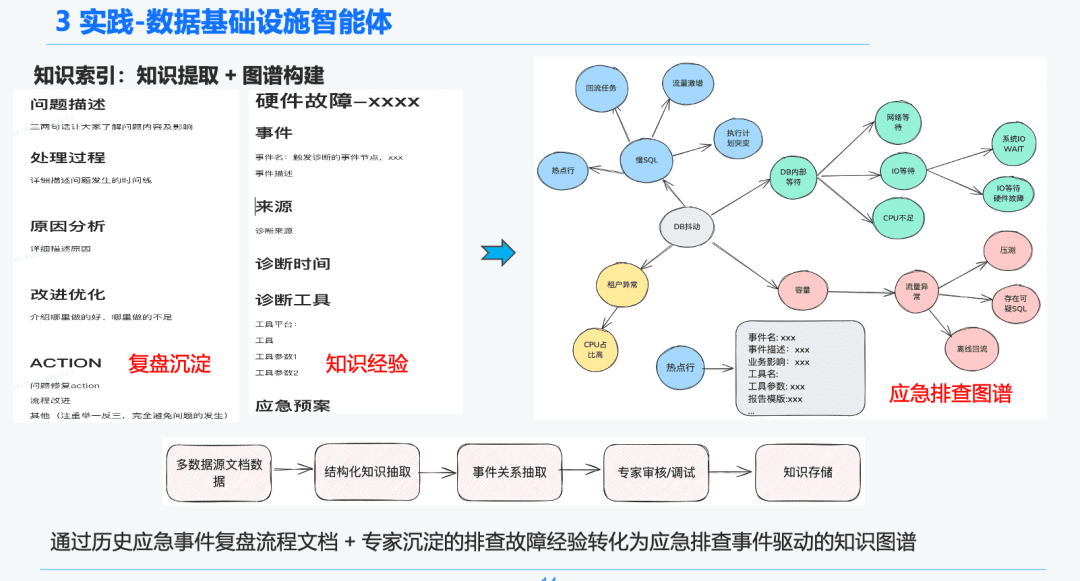
1.3 知識処理
データインフラの決定性と特異性に基づき、知識グラフを組み合わせて緊急対応経験を診断するための知識ベアラとして使用することを選択した。SREの緊急トラブルシューティングイベントの知識経験 緊急レビュープロセスと組み合わせることで、DB緊急イベントドリブンナレッジグラフを確立しました。DBジッターを例として、SQLが遅い問題、容量の問題など、DBジッターに影響を与えるいくつかのイベントを取り上げ、各緊急イベント間の関係を確立しました。
最後に、緊急事態のルールを正規化することで、複数のソースからの知識→知識の構造化抽出→緊急事態の関係抽出→専門家によるレビュー→知識の蓄積という段階的な標準化された知識処理システムを確立した。
1.4 知識検索
インテリジェントボディ検索フェーズでは、静的知識検索の担い手としてGraphRAGを使用するため、DBジッタ異常を特定した後、DBジッタ異常ノードに関連するノードを分析の基礎として見つけます。各ノードには、知識抽出フェーズにおける各イベントのメタデータ情報(イベント名、イベント説明、関連ツール、ツールパラメータなど)も保持されています。
そのため、実行ツールの実行ライフサイクルリンクを通して、トラブルシューティングのための緊急診断の基礎として使用する動的データを得るために、リターン結果を得ることができる。この動的・静的ハイブリッド・リコール・アプローチにより、データ・インフラ・インテリジェンスの実行の確実性、専門性、厳密性は、純粋で単純なRAGリコールよりも保証される。
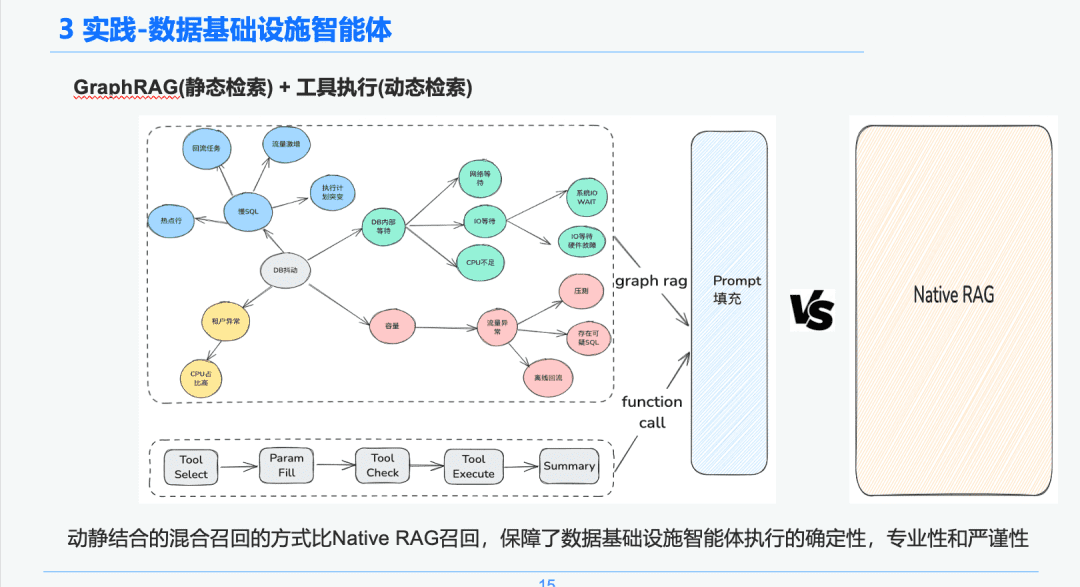
1.5 AWEL + 代理店
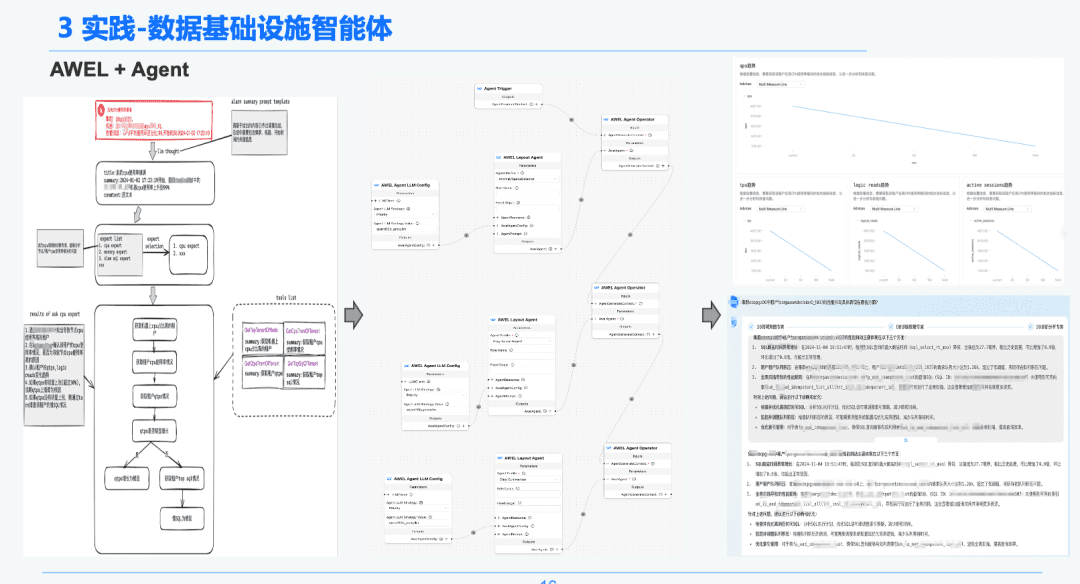
最後に、コミュニティAWEL+AGENT技術を通じて、AGENTオーケストレーションのパラダイムは、意図→緊急診断専門家→診断根本原因分析専門家の専門家を作成するために使用されている。
各エージェントは異なる機能を持っています。 インテントエキスパートは、ユーザのインテントを特定し、解析し、アラートメッセージを特定する責任を持ちます。 診断エキスパートは、GraphRAGを通して分析する根本原因ノードを特定し、特定の根本原因情報を取得する必要があります。分析エキスパートは、各原因ノードのデータ+履歴分析レビューレポートを組み合わせて、診断分析レポートを作成する必要がある。
2.財務報告分析分野におけるRAG
最新の実践DB-GPTに基づく財務報告分析アシスタントを構築するには?
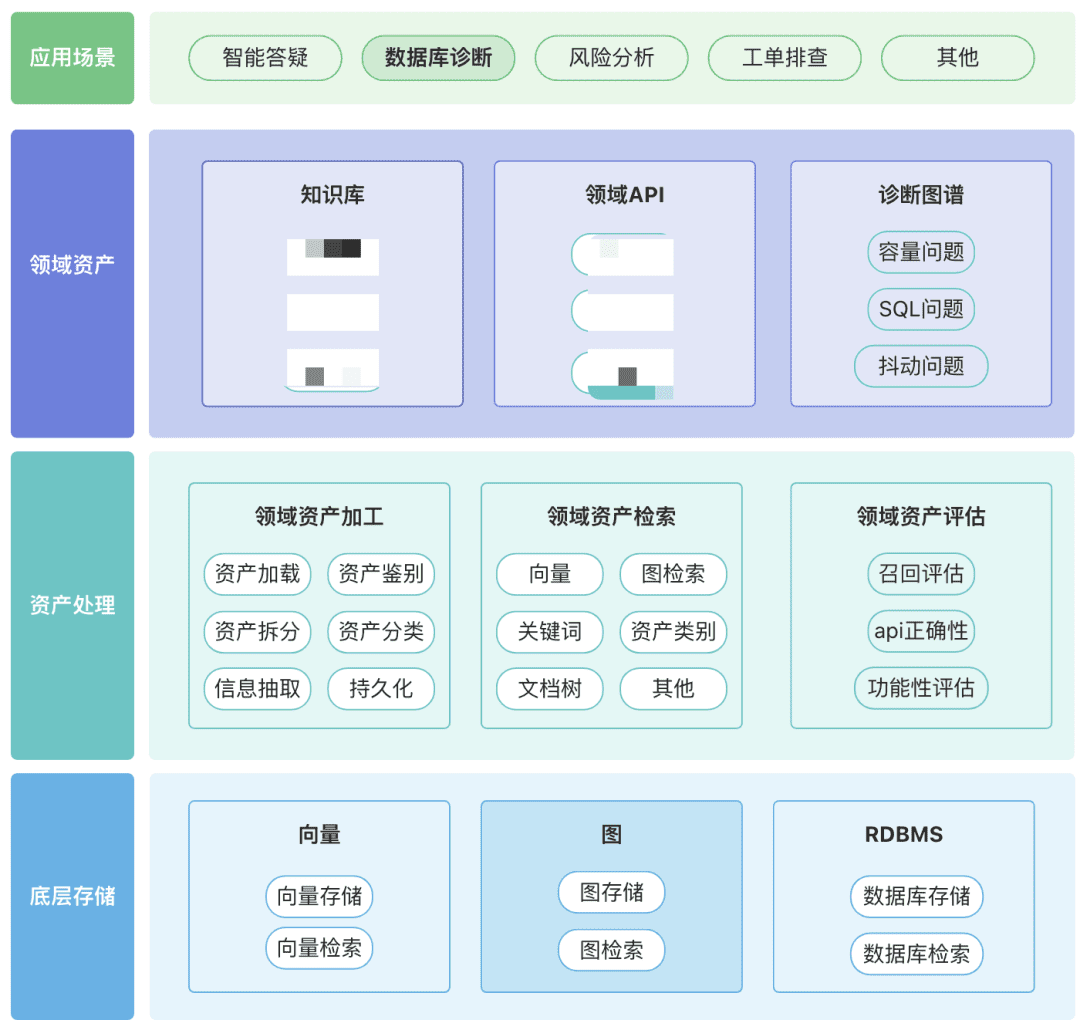
ナレッジアセット、ツールアセット、ナレッジグラフアセットなど、あなたのドメインに関連するドメインアセットのリポジトリを構築することができます。
- ドメイン資産:ドメイン資産には、ナレッジベース、API、ツールスクリプトが含まれる。
- 資産処理、資産データリンク全体には、ドメイン資産処理、ドメイン資産検索、ドメイン資産評価が含まれる。
-
- 非構造化→構造化:構造化された方法で分類され、正しく整理された知識情報。
- より豊かな意味情報を抽出する。
-
- 資産の回収:
-
- 願わくば、単一検索ではなく、階層化された優先順位検索であってほしい。
- できれば、いくつかのルールのビジネス・セマンティクスを通して。
-