を立ち上げた。
VDR-2B-マルチV1ビジュアル文書検索に最適な多言語埋め込みモデルです。平易な英語版もあります。vdr-2b-v1をオープンソース化した。VDR-マルチリンガル・トレインこのデータセットには50万件の高品質なサンプルが含まれています。このデータセットには50万個の高品質なサンプルが含まれており、視覚的文書検索のためのオープンソースの多言語合成データセットとしては最大である。

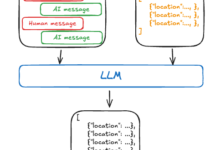
誇らしげに贈る VDR-2B-マルチV1 (🤗) このモデルは、複数の言語とドメインにまたがる視覚的文書検索のために設計された多言語埋め込みモデルである。このモデルは、文書ページのスクリーンショットを密な一方向表現にエンコードするように設計されており、OCRやデータ抽出パイプライン、チャンキングを必要とせずに、視覚的にリッチな多言語文書の検索とクエリを効果的に行うことができる。
VDR-2B-マルチV1 モデルは以下に基づいている。 MrLight/dse-qwen2-2b-mrl-v1 このモデルはLlamaIndexと共同で構築された。このモデルはLlamaIndexと共同で構築された。 mcdse-2b-v1 次のイテレーション次の反復は VDR-2B-マルチV1 このモデルを訓練するために使用された学習と方法は拡張され改善され、その結果、より強力で優れたモデルが誕生した。
- 🇮🇹 イタリア語、🇪🇸 スペイン語、🇬🇧 英語、🇫🇷 フランス語および🇩🇪 ドイツ語: これらは合わせて、50万個の高品質なサンプルを含む、新しい大規模なオープンソースの多言語トレーニングデータセットを形成している。
- ビデオメモリが少なく、推論が速いSynthetic Visual Document Retrieval (ViDoRe) ベンチマークにおいて、768個の画像ブロックを持つ英語のみのモデルは、2,560個の画像ブロックを持つ基本モデルよりも優れた性能を発揮しました。この結果、推論が3倍高速化し、グラフィックス・メモリの使用量が大幅に削減されました。
- クロスランゲージ検索実際のシナリオでは、こちらの方がはるかに優れています。例えば、イタリア語のクエリを使ってドイツ語の文書を検索することができます。
- マトリョーシカは学びを表現したベクターのサイズを3分の1に縮小しても、98%の埋め込み品質を維持できます。これにより、保存コストを削減しながら、検索速度を劇的に向上させることができます。
使用状況
🎲 今すぐ試してみてください!
VDR-2B-マルチV1以下はその例である。 ハギング・フェイス・スペース で検索!
SentenceTransformersとLlamaIndexを直接統合することにより、以下のようなことが可能になる。 VDR-2B-マルチV1 エンベッドの生成がこれまで以上に簡単になりました。わずか数行のコードで始められます:
ラマインデックス経由
pip install -U llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
model = HuggingFaceEmbedding(
model_name="llamaindex/vdr-2b-multi-v1", device="cpu", # "mps" for
device="cpu"、macは# "mps"、nvidia GPUは "cuda"
trust_remote_code=True、
)
image_embedding = model.get_image_embedding("image.png")
query_embedding = model.get_query_embedding("Chi ha inventato Bitcoin?")
via SentenceTransformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
model_name_or_path="llamaindex/vdr-2b-multi-v1"、
device="cuda"、
trust_remote_code=True, # SentenceTransformerの推奨値です。
# これらはモデルの推奨kwargsですが、CUDAを持っていない場合は必要に応じて変更してください。
model_kwargs={
"torch_dtype": torch.bfloat16, "device_map": torch.
「device_map": "cuda:0", "attn_implementation".
「attn_implementation": "flash_attention_2".
},
)
embeddings = model.encode("image.png")
トレーニングデータセット
ビジュアル文書検索のための優れた一方向モデルを学習するには、高品質のデータが必要であるが、現在のマルチモーダルな既製データセットは乏しく、多言語にも対応していない。
その結果、ゼロからの構築にかなりの時間を費やした。オリジナルのデータセットには、50万件の多言語クエリ画像サンプルが含まれており、インターネット上の公開PDFを使用してゼロから収集・生成された。各画像に関連するクエリは、視覚言語モデリング(VLM)を用いて合成的に生成された。比較として、我々のデータセットは、マルチモーダル視覚文書検索のための最大のオープンソースの合成データセット(すなわち、「視覚言語モデリング(VLM)」)よりもはるかに大きい。 ColPaliトレーニングデータセット (廃棄された文書の)10倍のサンプル数。

データ収集
検索エンジンの言語フィルタリング機能を使って、指定された言語の文書だけをクロールします。この "トピックによる検索 "技術により、モデルは多くの異なるトピックやドメインを見てきており、実際のシナリオでうまく機能することが保証される。
クロールの結果、約5万件の多言語文書が得られた。前回の mcdse-2b-v1 モデルで使われているアプローチとは対照的に、ページはランダムに抽出されません。その代わり、各PDFの各ページが文書レイアウト分析モデルにかけられ、そのページがより多くのテキスト要素を含んでいるのか、それとも視覚的要素を含んでいるのかを判断します。その結果、そのページがテキストのみ、ビジュアルのみ、混在のいずれかに分類される。その後、このマークアップのステップを使用して約 10 万ページがサンプリングされ、ページタイプ別に均等に分散されていることが確認されました。
合成世代
クエリはgemini-1.5-proとQwen2-VL-72Bを用いて生成された。タスクは、特定の質問と一般的な質問である。モデルのトレーニングには特定の質問のみが使用されるが、ラージ・ランゲージ・モデル(LLM)にこの2つを区別させることで、通常、情報検索のトレーニングにはより強力な特定の質問が使用される。
問題が生成されると、さらにクリーンアップのステップを経て、トレーニングに十分な問題が生成される。これには以下が含まれる:
- 言語が正しいことを確認する
- フォーマットに関する問題の修正
- マークダウンの削除
- 質問は1つだけにする
- 基本フレーズの削除(例:「図1に従って」、「本書」、...など)
フィルタリングとハード・ネガティブ・ケース・マイニング
このクリーンアップ・ステップにより、クエリが構文的に正しく、いくつかの厳格なガイドラインに従っていることが保証される。しかし、クエリが情報検索に十分であることを保証するものではない。
悪い質問を除外するために、voyage-3埋め込みモデルを使用して、それぞれの幅広いクエリを埋め込み、インデックスを作成しました。それぞれの特定の質問に対して、インデックスを検索しました。関連する幅広い質問が最初の100の結果に表示された場合、そのクエリは「良い」とラベル付けされます。この方法は、エントロピーが低い、重複している、または類似しすぎている質問を削除します。平均して、40%のクエリが各言語データセットから削除されました。
その後、voyage-3を用いて、特定の問題についてのみ、閾値を0.75に固定したハードなネガティブ例を採掘した。また nvidia/NV-Retriever-v1 で説明されているように、ポジティブ・ケースを意識したネガティブ・ケース・マイニングの実験が行われたが、このデータセットでは、ネガティブ・ケースを生成するのが簡単すぎる/遠すぎるようだ。
ダウンロード
(vdr-multilingual-train 🤗トレーニングデータセットは現在オープンソースで、Hugging Faceで直接入手可能です。学習データセットには496,167のPDFページが含まれ、そのうち280,679のみが(上述の方法で)フィルタリングされたクエリに関連付けられている。クエリのない残りの画像は、依然としてハードネガ例として使用されている。
| 多言語主義 | # フィルターを通したクエリ | # アンフィルタード・クエリー |
|---|---|---|
| 英語 | 53,512 | 94,225 |
| スペイン語 | 58,738 | 102,685 |
| イタリア語 | 54,942 | 98,747 |
| ドイツ語 | 58,217 | 100,713 |
| フランス語 | 55,270 | 99,797 |
| 合計 | 280,679 | 496,167 |
データセットは5つの異なるサブセットで構成されており、それぞれが言語に対応している。こちらから直接閲覧できます:
データセットは5つの異なるサブセットで構成され、それぞれが言語に対応している。ここで直接調べることができる:
または ロードデータセット 言語を個別にダウンロードする言語のサブセットを指定します:
from datasets import load_dataset
italian_dataset = load_dataset("llamaindex/vdr-multilingual-train", "it", split="train")
english_dataset = load_dataset("llamaindex/vdr-multilingual-train", "en", split="train")
French_dataset = load_dataset("llamaindex/vdr-multilingual-train", "fr", split="train")
german_dataset = load_dataset("llamaindex/vdr-multilingual-train", "de", split="train")
スペイン語_dataset = load_dataset("llamaindex/vdr-multilingual-train", "es", split="train")
評価

このモデルは、ViDoReベンチマークと、テキストのみ、ビジュアルのみ、およびハイブリッドページのスクリーンショットで多言語機能をテストできるカスタム構築の評価セットで評価されています。評価データセットはHugging Face (vdr-multilingual-test 🤗(多言語テスト).
評価の汚染を避けるため、これらのデータセットからのページがトレーニングセットに現れないようにした。これらのデータセットはトレーニングデータセットと同じ方法で収集、生成されたが、サンプルサイズはより小さい。フィルタリングのステップはすべて手作業で行われ、各クエリが評価され、照合され、(必要であれば)改良され、高品質のデータが確保された。
すべての査定は 1536 Viベクターと併用できる。 最大768トークン を計算するために表される画像の解像度。 NDCG@5 演奏するスコア。
| 平均して | フランス語(テキスト) | フランス語(ビジュアル) | フランス語(混合) | |
|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 93.5 | 94.7 | 90.8 | 95.1 |
| VDR-2B-マルチV1 | 95.6 | 95.6 | 93.3 | 97.9 |
| +2.2% |
| 平均して | ドイツ語(テキスト) | ドイツ語(ビジュアル) | ドイツ語(混合) | |
|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 93.0 | 93.4 | 90.0 | 95.5 |
| VDR-2B-マルチV1 | 96.2 | 94.8 | 95.7 | 98.1 |
| +3.4% |
| 平均して | イタリア語(テキスト) | イタリア語(視覚) | イタリアン(ミックス) | |
|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 95.1 | 95.1 | 94.0 | 96.2 |
| VDR-2B-マルチV1 | 97.0 | 96.4 | 96.3 | 98.4 |
| +2% |
| 平均して | スペイン語(テキスト) | スペイン語(ビジュアル) | スペイン語(混合) | |
|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 96.7 | 97.2 | 94.7 | 98.2 |
| VDR-2B-マルチV1 | 98.1 | 98.3 | 96.9 | 99.1 |
| +1.4% |
| 平均して | 英語(テキスト) | 英語(ビジュアル) | 英語(混合) | |
|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 98.0 | 98.3 | 98.5 | 97.1 |
| VDR-2B-マルチV1 | 98.1 | 97.9 | 99.1 | 97.3 |
| +0.1% |
多言語モデルは、すべての言語とすべてのページタイプでベースモデルを上回り、平均+2.3%の改善となった。また、ViDoReベンチマークでも若干の改善が見られた(+0.5%)。を微調整しました。 VDR-2B-マルチV1 特に非英語の純粋視覚ページやハイブリッドページにおいて、性能の飛躍的な向上が見られた。例えば、ドイツ語のピュアビジュアル検索では、NDCG@5がベースモデルに比べて+6.33%向上している。
また、英語のサブセット(vdr-2b-v1).フルViDoReベンチマーク(768枚の画像を使用)では トークン (評価用)、多言語バージョンと英語のみバージョンの両方がベースモデルを上回る。
| 平均して | シフトプロジェクト | 政府 | ヘルスケア | エネルギー | アイ | ドクヴカ | アルキシブカ | tatdqa | インフォブカ | タブフクワッド | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 83.6 | 79.8 | 95.7 | 96.9 | 92.0 | 98.2 | 56.3 | 85.2 | 53.9 | 87.5 | 90.3 |
| VDR-2B-マルチV1 | 84.0 | 82.4 | 95.5 | 96.5 | 91.2 | 98.5 | 58.5 | 84.7 | 53.6 | 87.1 | 92.2 |
| vdr-2b-v1 | 84.3 | 83.4 | 96.9 | 97.2 | 92.6 | 96.8 | 57.4 | 85.1 | 54.1 | 87.9 | 91.3 |
より速い推論

平易な英語 vdr-2b-v1 このモデルはまた、ViDoReベンチマークの合成データセットにおいて、30%の画像トークン(768対2560)のみを使用しながら、基本モデルの性能に匹敵します。これにより、推論速度が実質的に3倍向上し、グラフィックスメモリの使用量が大幅に削減されます。
| 平均して | シフトプロジェクト | 政府 | ヘルスケア | エネルギー | アイ | |
|---|---|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 (2560 画像トークン) | 93.0 | 82 | 96 | 96.4 | 92.9 | 97.5 |
| vdr-2b-v1(768イメージトークン) | 93.4 | 83.4 | 96.9 | 97.2 | 92.6 | 96.8 |
クロスランゲージ検索
モデルは各言語で個別に訓練されたが、言語横断検索でも改善された。この能力をテストするために、ドイツ語の評価セットのクエリをDeepLを使用してイタリア語に翻訳した。ドキュメント・ページのスクリーンショットはオリジナルのドイツ語のままである。
| 平均して | イタリア語 → ドイツ語 (テキスト) | イタリア語 → ドイツ語(視覚) | イタリア語→ドイツ語(混合) | |
|---|---|---|---|---|
| DSE-QWEN2-2B-MRL-V1 | 93.1 | 92.6 | 93.5 | 93.3 |
| VDR-2B-マルチV1 | 95.3 | 95.0 | 95.8 | 95.1 |
| +2.3% |
このモデルは、すべての文書タイプにおいて、平均+2.31 TP3Tの改善と、大幅に優れた性能を発揮している。これらの検索機能は、特にヨーロッパのような言語的に分散した地域における、実際のユースケースにとって非常に重要である。例えば、複雑な欧州の拘束に関する決定、取扱説明書、金融資産のKID、医薬品の添付文書など、複雑な多言語ソースを言語に依存せずに検索することができます。
MRLとバイナリ埋め込み
このモデルはマトリョーシカ表現学習(MRL)を用いて学習される。学習時に使用される損失関数は、これら全ての次元のパフォーマンスを追跡するようにキャリブレーションされており、モデルに最も重要な認識情報を事前にロードすることができます。これにより、サイズや予算に応じて埋め込み次元を効率的に絞り込むことができます。MRLの詳細については、Hugging Faceのウェブサイトをご覧ください。このブログ記事これについてはきちんとした説明があった。
異なるベクトル次元におけるモデルの検索能力をテストするため、イタリア語→ドイツ語のクロス言語ベンチマークで評価した。
NDCG@5(浮動小数点)
| 平均して | イタリア語 → ドイツ語 (テキスト) | イタリア語 → ドイツ語(視覚) | イタリア語→ドイツ語(混合) | |
|---|---|---|---|---|
| 1536 Vi | ||||
| DSE-QWEN2-2B-MRL-V1 | 93.1 | 92.6 | 93.5 | 93.3 |
| VDR-2B-マルチV1 | 95.3 | 95.0 | 95.9 | 95.1 |
| +2.3% | ||||
| 1024 V | ||||
| DSE-QWEN2-2B-MRL-V1 | 92.2 | 90.9 | 92.3 | 93.5 |
| VDR-2B-マルチV1 | 94.6 | 93.1 | 95.7 | 95.1 |
| +2.5% | ||||
| 512 Vi | ||||
| DSE-QWEN2-2B-MRL-V1 | 89.8 | 87.9 | 89.4 | 92.2 |
| VDR-2B-マルチV1 | 93.0 | 91.1 | 93.4 | 94.5 |
| +3.4% |
NDCG@5(バイナリー)
| 平均して | イタリア語 → ドイツ語 (テキスト) | イタリア語 → ドイツ語(視覚) | イタリア語→ドイツ語(混合) | |
|---|---|---|---|---|
| 1536 Vi | ||||
| DSE-QWEN2-2B-MRL-V1 | 89.8 | 88.2 | 90.3 | 90.8 |
| VDR-2B-マルチV1 | 92.3 | 89.6 | 94.1 | 93.3 |
| +2.8% | ||||
| 1024 V | ||||
| DSE-QWEN2-2B-MRL-V1 | 86.7 | 84.9 | 88.2 | 86.9 |
| VDR-2B-マルチV1 | 90.8 | 87.0 | 92.6 | 92.8 |
| +4.6% | ||||
| 512 Vi | ||||
| DSE-QWEN2-2B-MRL-V1 | 79.2 | 80.6 | 81.7 | 75.4 |
| VDR-2B-マルチV1 | 82.6 | 77.7 | 86.7 | 83.3 |
| +4.0% |
1024次元浮動小数点ベクトルは、品質とサイズのバランスが非常に良い。1536次元バイナリ・ベクトルも同様で、ベクトルあたりのバイト数は10倍少なくなっていますが、検索品質は97%を維持しています。興味深いことに、1536個のバイナリ・ベクトルは、ベース・モデルの1536個の浮動小数点ベクトルの性能とほぼ一致する。
結論と次のステップ
私たちは信じている。 VDR-2B-マルチV1 歌で応える vdr-2b-v1 は多くのユーザーにとって有用であることがわかるだろう。
私たちの多言語モデルはこの種のものとしては初めてであり、多言語・異言語シナリオにおけるパフォーマンスを大幅に向上させ、MRLと二値定量化のおかげで、検索はこれまで以上に効率的かつ高速になりました。これにより、特にヨーロッパのような言語的に分散した地域において、新たなユースケースと機会が開かれると信じています。
この英語版のみのバージョンは、基礎となるモデルの大幅な改良を意味し、メモリを削減し、同じ(またはそれ以上の)検索品質を維持しながら、文書を3倍速く埋め込むことができるようになった。
すべては新しい VDR-マルチリンガル・トレイン このデータセットには50万件の高品質なサンプルが含まれています。このデータセットには50万件の高品質なサンプルが含まれており、視覚的文書検索のための最大の多言語オープンソース合成データセットである。
今後の研究では、私たちのモデルを新しい特定のドメインに適応させた場合に、どのようなパフォーマンスを発揮するかを探っていく。これはまだ開発の初期段階であり、結果を公表する前にさらなる作業が必要であるが、初期のテストではむしょうに少ないデータと計算資源で、印象的な検索効果が得られる。
今後のアップデートにご期待ください!