AIの急速な発展の中で、デジタルヒューマン(Digital Humans)が成熟し、低コストで迅速に生成できるようになった。その商業的応用シーンの広さから、注目を集めている。バーチャルリアリティ(VR)、拡張現実(AR)、映画・テレビ制作、ゲーム開発、ブランドプロモーションなど、デジタルヒューマンは重要な役割を担っています。
大きく分けると、3Dモデリング(モーションキャプチャーを含む)のデジタルピープル、静止した2D画像のデジタルピープル(実在の人物を含む)、リアルフェイススワッピングタイプのデジタルピープルがある。
本論文は個人的なイメージのクローニングのイメージのクラスのデジタル人に焦点を合わせる、静的な2Dイメージのデジタル人に属する、3つの基本的な機能が含まれている:実像、声のクローニング、口の同期。
注1:いくつかのプロジェクトは、音声生成(クローン)部分が含まれていない、これはポイントではありません、別々に展開することができますしてください、多くの優れた市場があるAIボイス・クローニング・プロジェクト.
注2:現在、2D静止人物の品質は、主に口の同期と「映像の動き」の自然さで異なります。これは別途最適化することができます。リップシンクノード
注3:顔交換+ボイス・クローニングも、デジタル人物を生成する高速な方法であり、人前で話す人のイメージや声を変えずに維持するのに適しているため、以下の番組には含まれていない。高度なビデオ・フェイス・スワップ技術は、普及すると危険なので紹介しない。
AIGCPanel: デジタルマンインテグレーションシステムのオープンソースクローン。
AigcPanelは、electron+vue3+typescriptの技術スタックで開発された、すべてのユーザーのためのワンストップAIデジタルヒューマン制作システムであり、Windowsシステムでのワンクリック導入をサポートしています。本システムはユーザーフレンドリーな設計を核心としており、技術的基礎の弱いユーザーでも簡単に使いこなすことができます。主な機能として、ビデオデジタル人間合成、音声合成、音声クローンなどがあり、完璧なローカルモデル管理機能を提供する。システムは多言語インターフェース(簡体字中国語と英語を含む)をサポートし、MuseTalkやcosyvoiceのようないくつかの成熟したモデルのためのワンクリックスタートアップパッケージを統合しています。特に特筆すべきは、ビデオ合成においてビデオと音声のリップシンクマッチングをサポートし、音声合成において豊富な音声パラメータ設定オプションを提供することである。オープンソースプロジェクトとして、AigcPanelはAGPL-3.0プロトコルに基づきリリースされており、コンプライアンスを重視し、違法・非合法なビジネスでの使用を明確に禁じています。

DUIX: リアルタイムのインタラクションを実現するインテリジェントなデジタルピープル、マルチプラットフォームのワンクリック導入をサポート
DUIX(Dialogue User Interface System)は、シリコン・インテリジェンスが開発したAI主導のデジタル・ヒューマン・インタラクション・プラットフォームです。オープンソースのデジタル・ヒューマン・インタラクション機能により、開発者は大規模モデル、自動音声認識(ASR)、音声合成(TTS)機能を簡単に統合し、デジタル・ヒューマンとのリアルタイムのインタラクションを実現することができます。DUIXはAndroidやiOSなどの複数のプラットフォームへのワンクリック導入をサポートしており、あらゆる開発者が様々な業界に適用可能なインテリジェントでパーソナライズされたデジタル・ヒューマン・エージェントを簡単に作成することができます。低い導入コスト、低いネットワーク依存性、多様な機能性により、このプラットフォームは、ビデオ、メディア、カスタマーサービス、金融、ラジオ、テレビなど、さまざまな業界のニーズを満たすことができます。

EchoMimic:音声によるリアルな肖像画アニメーション
EchoMimicは、音声によってリアルな肖像画アニメーションを生成することを目的としたオープンソースプロジェクトです。AntグループのTerminal Technologies部門によって開発されたこのプロジェクトは、編集可能なマーカーポイント条件を利用し、音声と顔のマーカーポイントを組み合わせたダイナミックなポートレート動画を生成します。EchoMimicは、複数の公開データセットと専有データセットで包括的に比較され、定量的評価と定性的評価の両方で優れた性能を実証しています。
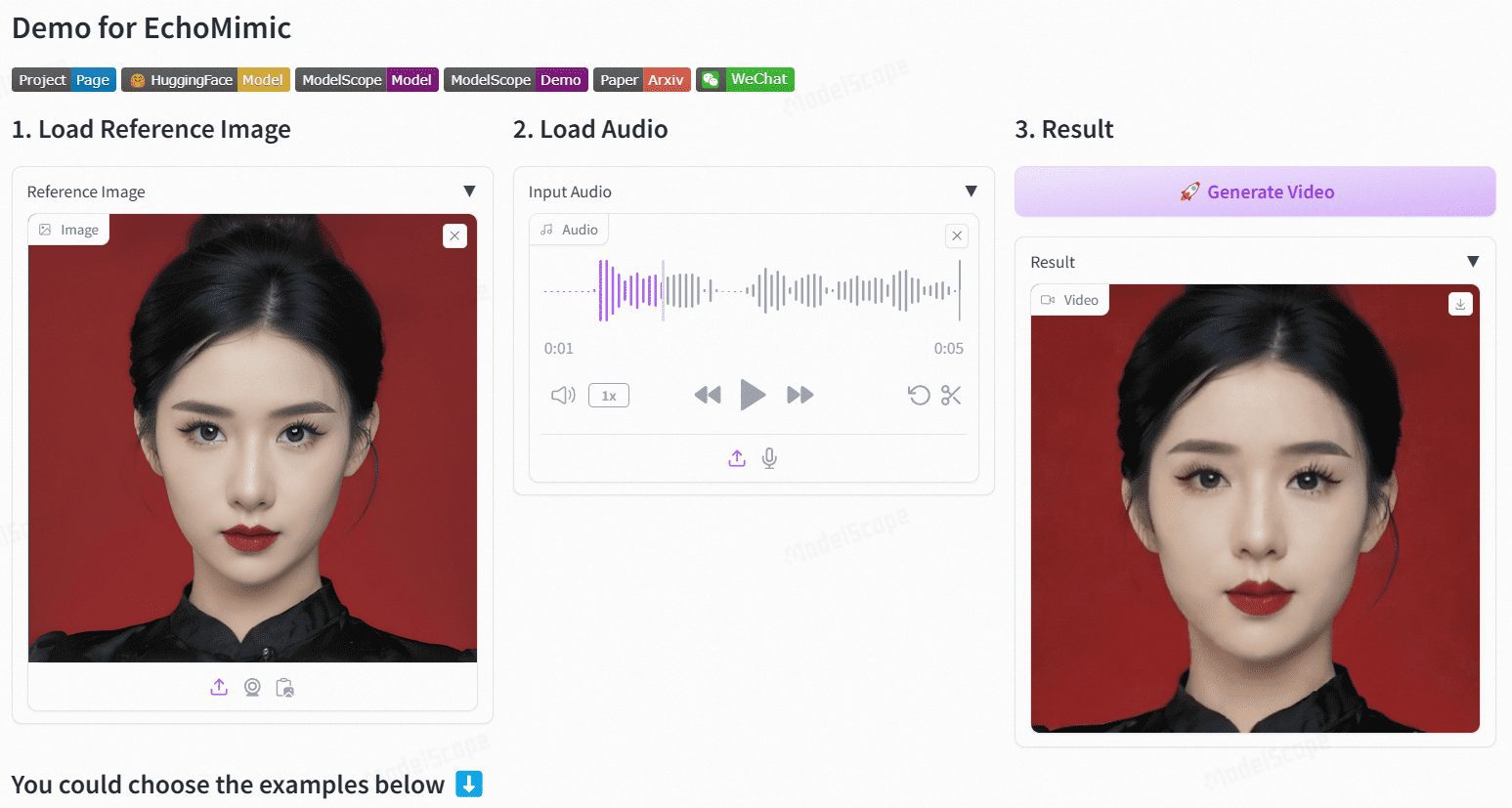
Sonic: デジタル・ポップアップのための、デジタル・ヒューマン、音声駆動による表情豊かなアニメーション・ビデオ生成のための新しいオープンソース・ソリューション
Sonicは、グローバルなオーディオ知覚に焦点を当てた革新的なプラットフォームで、オーディオによって駆動される鮮やかなポートレートアニメーションを生成するように設計されている。テンセントと浙江大学の研究者チームによって開発されたこのプラットフォームは、音声情報を使って表情や頭の動きを制御し、自然で流れるようなアニメーション動画を生成する。Sonicのコアテクノロジーには、コンテキストを強化した音声学習、モーション分離コントローラ、時間を意識したポジションシフト融合モジュールなどがある。これらの技術により、Sonicは様々なスタイルの画像や様々なタイプの音声入力を用いて、安定したリアルな長尺動画を生成することができます。
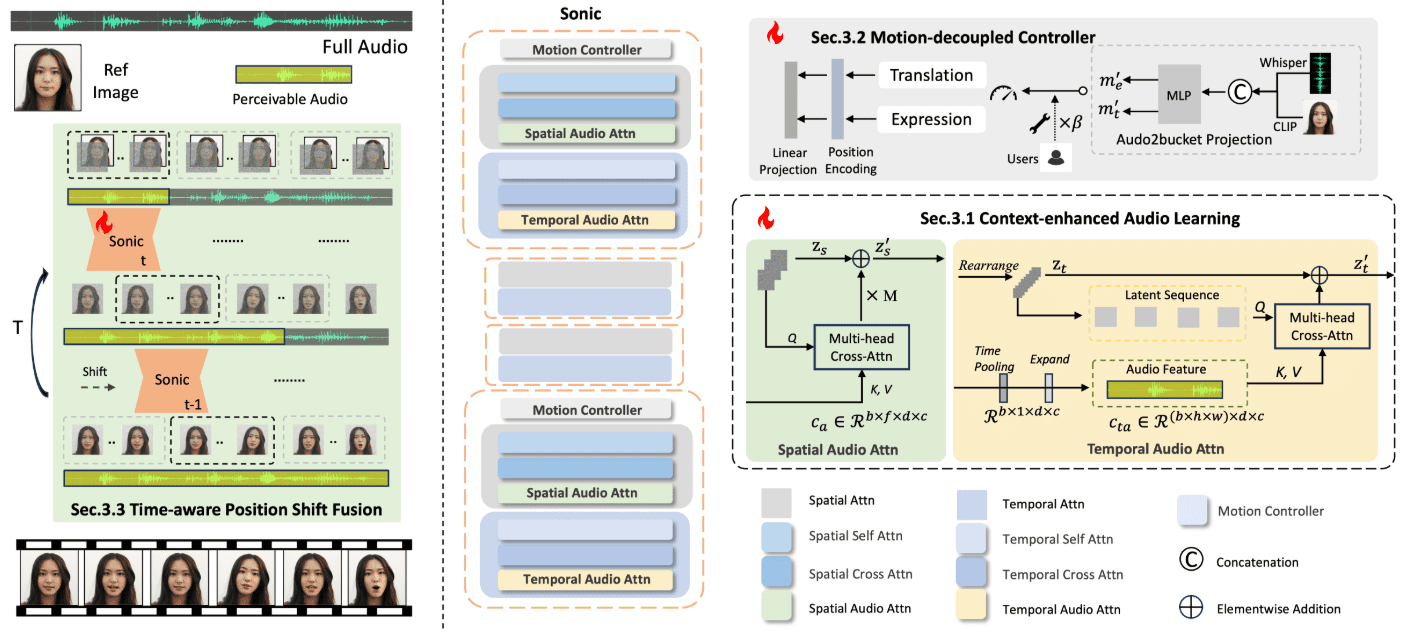
Hallo2: リップシンク/表情シンクされたポートレートビデオのオーディオ駆動型生成 (Windows ワンクリックインストール)
ハロ2 Hallo2は、復旦大学と百度(バイドゥ)が共同開発したオープンソースプロジェクトで、音声駆動型の生成により高解像度のポートレートアニメーションを生成する。このプロジェクトでは、先進的なGenerative Adversarial Networks (GAN)と時間的アライメント技術を活用し、4K解像度と最大1時間の動画生成を実現している。Hallo2はまた、生成コンテンツの多様性と制御性を高めるため、テキストプロンプトもサポートしている。
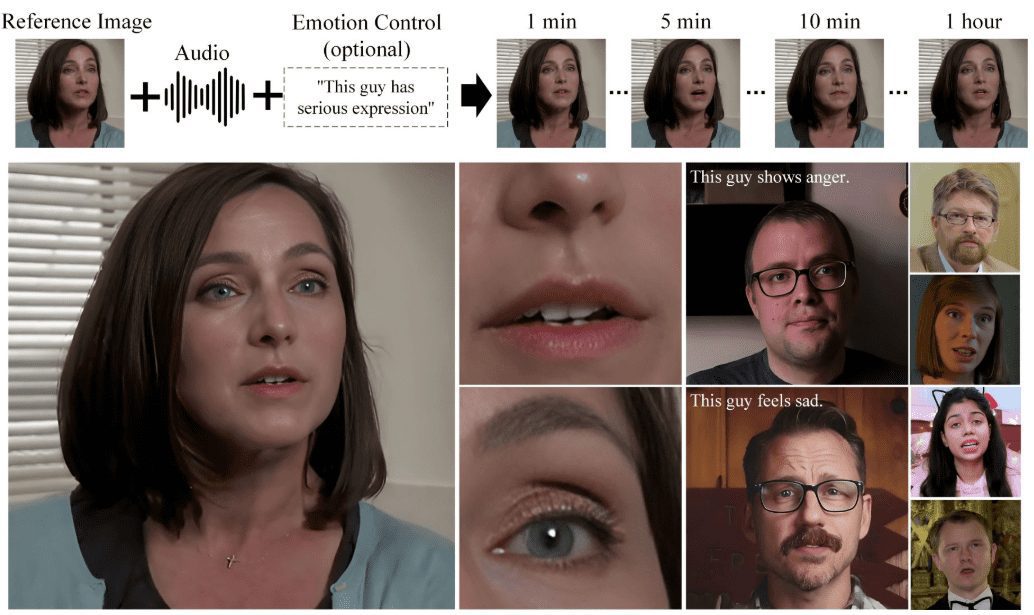
VideoChat:カスタムイメージとトーンクローニングによるリアルタイムの音声対話型デジタルパーソンは、エンドツーエンドの音声ソリューションとカスケードソリューションをサポートします。
VideoChatは、オープンソース技術に基づくリアルタイム音声対話デジタルヒューマンプロジェクトで、エンドツーエンドの音声スキーム(GLM-4-Voice - THG)とカスケードスキーム(ASR-LLM-TTS-THG)をサポートしています。このプロジェクトでは、ユーザーがデジタルヒューマンのイメージと音色をカスタマイズすることができ、音色のクローニングと唇の同期、ビデオストリーミング出力、最初のパケット遅延は3秒と低い。ユーザーはオンライン・デモでその機能を体験したり、詳細な技術文書を通じてローカルに導入して使用することができる。
TalkingAvatar:AIアバターを作成・編集するためのAIアバター・ビデオ・プラットフォーム。
トーキングアバター は、完全なAIデジタルパーソン・ソリューションを提供する最先端のAIアバター・プラットフォームです。ビデオコンテンツを作成、編集、パーソナライズする画期的な方法をユーザーに提供します。高度なAI技術により、ユーザーは簡単にビデオを書き換えたり、声のクローンを作ったり、唇を同期させたり、カスタムビデオを作成することができます。既存のビデオの吹き替えでも、ゼロから新しいストーリーの作成でも、TalkingAvatarがカバーします。

SadTalker: 写真にしゃべらせる|口パク音声|合成口パク動画|無料デジタルピープル
SadTalkerは、1枚の静止ポートレート写真と音声ファイルを組み合わせて、パーソナライズされたメッセージや教育コンテンツなど、幅広いシナリオに対応するリアルなトーキングヘッドビデオを作成するオープンソースツールです。ExpNetやPoseVAEなどの3Dモデリング技術を革新的に使用することで、微妙な表情や頭の動きを捉えることに優れています。ユーザーはSadTalkerの技術を、メッセージング、教育、マーケティングなど、個人的なプロジェクトにも商業的なプロジェクトにも使用できます。

AniPortrait:音声による画像やビデオの動きで、リアルなデジタル音声ビデオを生成
AniPortraitは、音声によってリアルな似顔絵アニメーションを生成する革新的なフレームワークです。Tencentゲーム・ノウ・ユアセルフ・ラボのHuawei、Zechun Yang、Zhisheng Wangによって開発されたAniPortraitは、音声と参照用の肖像画像から高品質なアニメーションを生成することができ、以下のようなことも可能です。顔の再現のためにビデオを提供する.高度な3D中間表現と2Dフェイシャルアニメーション技術を使用することで、このフレームワークは、映画やテレビの制作、バーチャルキャスターやデジタルピープルなど、さまざまな応用シーンで自然で滑らかなアニメーション効果を生成することができます。

MuseV+Muse Talk:完全なデジタルヒューマンビデオ生成フレームワーク|ポートレートからビデオへ|ポーズからビデオへ|リップシンク
MuseVは、長さ無制限で忠実度の高いアバター動画生成を目的としたGitHub上の公開プロジェクトです。拡散技術に基づき、Image2Video、Text2Image2Video、Video2Videoなど様々な機能を提供する。モデル構造の詳細、ユースケース、クイックスタートガイド、推論スクリプト、謝辞が掲載されています。

DreamTalk:1枚のアバター画像で表情豊かなトーキングビデオを生成!
DreamTalkは、清華大学、アリババグループ、華中科技大学が共同開発した拡散モデル駆動型の表現力豊かなトーキングヘッド生成フレームワークです。ノイズ除去ネットワーク、スタイル認識リップエキスパート、スタイル予測器という3つの主要コンポーネントで構成され、音声入力に基づいて多様でリアルなトーキングヘッドを生成することができる。このフレームワークは、多言語やノイズの多い音声を扱うことができ、高品質な顔の動きと正確な口の同期を提供する。

Translation Starter: オープンソース動画コンテンツ翻訳同期ツール|言語変換|リップシンク
Translation StarterはSync Labsによって開発されたオープンソースプロジェクトで、開発者が動画コンテンツの多言語サポートを素早く統合できるようにするためのものです。開発者がリップシンクによる動画翻訳を必要とするアプリケーションを簡単に作成するために必要なAPIとドキュメントを提供します。Sync LabsのPerfect Lip Sync、Open AIのWhisper Translation Technology、Eleven LabsのSound Synthesisといった強力なAI技術に基づいています。