視覚エージェント:複数の視覚的ターゲット検出タスクを解決する視覚インテリジェンス
概要 Vision Agentは、LandingAI(Enda Wuのチーム)によって開発され、GitHubでホストされているオープンソースプロジェクトである。高度なエージェントフレームワークとマルチモーダルモデルを使用し、簡単なプロンプトで効率的なコードを生成します。

概要 Vision Agentは、LandingAI(Enda Wuのチーム)によって開発され、GitHubでホストされているオープンソースプロジェクトである。高度なエージェントフレームワークとマルチモーダルモデルを使用し、簡単なプロンプトで効率的なコードを生成します。

概要 Make Senseは、コンピュータ・ビジョン・プロジェクト用のデータセットを素早く準備できるように設計された、無料のオンライン画像注釈ツールです。複雑なインストールは不要で、ブラウザからアクセスするだけで使用でき、複数のオペレーティングシステムをサポートし、小規模なディープラーニングプロジェクトに最適です。ユーザはこのツールを使って...

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

総合的な紹介 YOLOv12は、GitHubユーザーのsunsmarterjieによって開発されたオープンソースプロジェクトで、リアルタイムのターゲット検出技術に焦点を当てています。このプロジェクトは、YOLO (You Only Look Once)シリーズのフレームワークに基づいており、従来の畳み込みニューラルネットワーク(CNN)のパフォーマンスを最適化するための注意メカニズムの導入だけでなく、検出...

包括的な紹介 VLM-R1は、Om AI Labによって開発され、GitHubでホストされているオープンソースの視覚言語モデリングプロジェクトです。このプロジェクトはDeepSeekのR1アプローチにQwen2.5-VLモデルを組み合わせたもので、強化学習(R1)と教師あり微調整(SFT)技術により、視覚におけるモデルのパフォーマンスを大幅に向上させています...
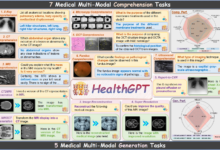
包括的な紹介 HealthGPTは、異種知識適応による統一的な医療視覚理解と生成能力の達成を目指す、先進的な医療グランドビジュアル言語モデルである。このプロジェクトの目標は、医療画像処理を大幅に改善する統一的な自己回帰フレームワークに医療視覚理解と生成能力を統合することである...

包括的な紹介 MedRAXは、胸部X線(CXR)解析用に設計された最先端のAIインテリジェンスです。最先端のCXR解析ツールとマルチモーダルな大規模言語モデルを統合し、追加トレーニングなしで複雑な医療クエリを動的に処理します。MedRAXは、モジュール設計と強力な技術基盤により、...

包括的な紹介 Agentic Object Detectionは、Landing AIによる先進的なターゲット検出ツールです。このツールは、データのラベリングやモデルのトレーニングを必要とせず、テキストプロンプトを使用して検出することにより、従来のターゲット検出のプロセスを大幅に簡素化します。ユーザーは画像をアップロードし、検出プロンプトを入力するだけで、AIが...

一般的な紹介 CogVLM2は清華大学データマイニング研究グループ(THUDM)によって開発されたオープンソースのマルチモーダルモデルで、Llama3-8Bアーキテクチャをベースとしており、GPT-4Vに匹敵するか、それ以上の性能を提供するように設計されている。このモデルは画像理解、多ラウンド対話、ビデオ理解をサポートし、最大8Kの長さのコンテンツを扱うことができる。

Comprehensive Introduction Video Analyzerは、コンピュータ・ビジョン、音声転写、自然言語処理技術を組み合わせて、ビデオ・コンテンツの詳細な説明を生成する総合的なビデオ解析ツールです。このツールは、動画から主要なフレームを抽出し、音声コンテンツを書き起こし、自然言語を生成します。

一般的な紹介 Twelve Labsは、動画理解に特化したマルチモーダルAI企業であり、高度なAI技術を通じて、ユーザーが大量の動画コンテンツを理解し、処理できるよう支援することに専念している。そのコア・テクノロジーには、アクション、オブジェクト、画面上のテキストなど、動画から主要な特徴を抽出できる動画検索、生成、埋め込みが含まれる。