
SemHash: データクリーニング効率を向上させるセマンティックテキスト重複排除の高速実装
一般的な紹介 SemHashは、意味的類似性によるデータセットの重複排除のための軽量で柔軟なツールである。Model2Vecの高速な埋め込み生成とVicinityの効率的なANN(近似最近傍)類似性検索を組み合わせている。SemHashは単一データセットの重複排除(例えば、トレーニング...
一般的な紹介 SemHashは、意味的類似性によるデータセットの重複排除のための軽量で柔軟なツールである。Model2Vecの高速な埋め込み生成とVicinityの効率的なANN(近似最近傍)類似性検索を組み合わせている。SemHashは単一データセットの重複排除(例えば、トレーニング...

概要 Parseurは、PDF、電子メール、その他のドキュメントからテキストデータを自動的に抽出するために設計された、AIデータ抽出ソフトウェアのリーディングカンパニーです。Parseurを使用すると、ユーザーは簡単に非構造化データを構造化データに変換し、様々なアプリケーションに送信することができます。このソフトウェアは広く...

GizAIは、AI生成、ノート作成、クラウドストレージ機能を統合したワンストッププラットフォームです。ユーザーは、GizAIで画像、動画、音声、テキスト、キャラクター、ストーリー、ゲームを生成し、プラットフォーム上で共同メモやクラウドストレージを取ることができます。GizAIは、ユーザーのプライバシーを保護し、同意なしにAIトレーニングにユーザーデータを使用しない一方で、ユーザーの生産性と創造性を高めるための幅広いAIツールを提供しています。 GizAIは、Stripe Atlasで設立されたGiz Inc.によって運営され、Google for Startups Cloud、Microsoft for Startups Founders Hub、AWS Activate、Paddle AI LaunchPadなどによってサポートされています。先進的なジェネレーティブAI技術の利用はすべての人の権利であると考え、無料の広告付きプランを提供し、ユーザーがコンテンツを生成、コラボレーション、共有できるようにしている。

包括的な紹介 NV Ingest (NVIDIA Ingest)は、何十万もの複雑で厄介な非構造化PDFやその他の企業ドキュメントを解析するために設計された、アーリーアクセスのマイクロサービス群です。NVIDIA Ingestは、これらのドキュメントをメタデータとテキストに変換し、検索システムに埋め込むことができます。

概要 Trellisは、複雑な非構造化データソースを構造化SQLフォーマットに変換することに特化したデータプラットフォームです。Trellisは、その強力なAIエンジンを通じて、財務文書、音声通話、電子メールなどの幅広いデータソースを処理し、データチームやオペレーションチームが使用できるSQLに変換することができます...
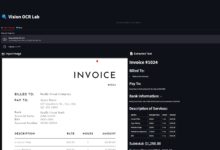
包括的な紹介 Ollama OCRは、Ollamaプラットフォームが提供する最先端の視覚言語モデルを使用して画像からテキストを抽出する、強力な光学式文字認識(OCR)ツールキットです。このプロジェクトは、Pythonパッケージとして利用できるほか、ユーザーフレンドリーなStreamlitウェブ・アプリケーション・インターフェースを提供しています。このツールキットは複数の...
包括的な紹介 llmstxt-generatorは、大規模言語モデル(LLM)の学習と推論のための高品質なテキストデータセットを準備することに特化した、専門的なウェブコンテンツの抽出と統合ツールです。Mendable AIによって開発されたこのツールは、@firecrawl_devによって提供されたウェブクローリング技術とGPT-4-miniを使用しています。

ExtractThinkerは、大規模言語モデル(LLM)を活用してドキュメントから構造化データを抽出・分類し、ORMのようなシームレスなドキュメント処理ワークフローを提供する、柔軟なドキュメントインテリジェンスツールです。Tesseract OCR、Azure Form Recog...など、複数のドキュメントローダーをサポートしています。

包括的な紹介 HtmlRAGは、RAG(Retrieval Augmented Generation)システムにおけるHTML文書の処理を改善することに焦点を当てた、革新的なオープンソースプロジェクトである。このプロジェクトは、RAGシステムにおけるHTMLフォーマットの使用が、プレーンテキストよりも効率的であるという新しいアプローチを提案する。このプロジェクトは、HTML文書の検索から検索結果の表示までの完全なデータ処理フローを包含している。
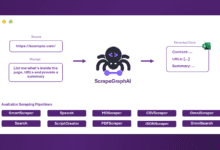
包括的な紹介 ScrapeGraphAIは、ラージ・ランゲージ・モデリング(LLM)とダイレクト・グラフ・ロジックを巧みに組み合わせ、ウェブサイトやローカル・ドキュメントのスクレイピング・パイプラインを作成する革新的なPythonウェブ・スクレイピング・ライブラリです。このツールのユニークさは、シンプルさとパワーの完璧なバランスにある。

総合紹介 Vision Parseは、最先端の視覚言語モデル(Vision Language Models)技術を巧みに組み合わせ、PDF文書を高品質なMarkdown形式のコンテンツにインテリジェントに変換する画期的な文書処理ツールです。このツールは、一流の視覚言語モデルを幅広くサポートしています。