

Markdownify MCP Server: MCPプロトコルに基づき、様々なコンテンツをMarkdownフォーマットに変換します。
一般的な紹介 Markdownify MCP Serverはモデルコンテキストプロトコルに基づいたオープンソースツールで、GitHubでホストされており、開発者のZach Caceresによって作成されました。複数のファイルタイプ(PDF、画像、音声、オフィス文書など)を...

一般的な紹介 Markdownify MCP Serverはモデルコンテキストプロトコルに基づいたオープンソースツールで、GitHubでホストされており、開発者のZach Caceresによって作成されました。複数のファイルタイプ(PDF、画像、音声、オフィス文書など)を...
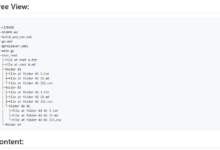
一般的な紹介 CodeWeaverは、コード・ライブラリを単一の見やすいMarkdownドキュメントに編むために設計されたコマンドライン・ツールです。ディレクトリを再帰的にスキャンし、各ファイルの内容をコードブロックに埋め込むことで、プロジェクトのファイル階層を構造化した表現を生成します。このツールは、...

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

包括的な紹介 Kreuzbergは、PDFファイルのテキスト抽出を簡素化するライブラリで、シンプルで手間のかからないテキスト抽出ソリューションを提供するように設計されています。このライブラリは、テキスト抽出を必要とするRAG(Retrieval-Augmented Generation)サービスに特に適しています。
包括的な紹介 Instructorは、大規模言語モデル(LLM)からの構造化された出力を処理するために設計された一般的なPythonライブラリです。Pydanticをベースに構築されており、データ検証、再試行、ストリーミング応答を管理するための、シンプルで透過的、そしてユーザーフレンドリーなAPIを提供します。

包括的な紹介 zChunkはZeroEntropyが開発した新しいチャンキング戦略で、一般的なセマンティック・チャンキングのソリューションを提供する。このストラテジーはLlama-70Bモデルに基づいており、チャンクの生成を促すことでドキュメントのチャンキングプロセスを最適化し、情報検索時に高いS/N比を維持します。

総合紹介 Pulseは、文書処理とデータ抽出に特化したインテリジェントなプラットフォームで、企業や開発者がさまざまな複雑な文書を効率的に解析・処理できるように設計されています。高度なコンピュータビジョンとマルチモーダル処理技術により、Pulse はテキスト、画像、表、その他のフォーマットからドキュメントを正確に処理することができます。
包括的な紹介 Rowfillは、ナレッジワーカーのために設計されたオープンソースの文書処理プラットフォームです。Rowfillは、高度なAI技術を使用して、複雑な文書、画像、PDFからデータを抽出、分析、処理します。Rowfillは、ネイティブのLarge Language Models(LLM)とOpenAIのビジュアルモデルをサポートしており、データを確実に隠蔽します。

一般的な紹介 PPTX2MDは、PowerPointのPPTXファイルをMarkdown形式に変換するために設計されたオープンソースのツールです。GitHubユーザーのssineによって開発されたこのツールは、見出し、リスト、テキストフォーマット(太字、斜体、色、ハイパーリンクなど)、画像、テーブルを様々なフォーマットで保持することができます。

概論 Repomix(以前はRepopackとして知られていた)は、コードベース全体を単一のAIフレンドリーなファイルにパッケージ化するために設計されたオープンソースツールである。このツールを使うことで、開発者は自分のコードベースを大規模な言語モデル(Claude、ChatGPT、Geminiなど)が解析や処理のために簡単に利用できるようにすることができる...

概要 Yekは、リポジトリやディレクトリからテキストファイルを読み込んでチャンキングし、大規模言語モデル(LLM)で使用するためにシリアライズするRustベースの高速ツールです。このツールはデフォルトで .gitignore ルールを使って不要なファイルをスキップし、Git の履歴を使って重要なファイルを推測します。
概要 LlamaParseは、PDF、PowerPoint、Word文書、スプレッドシートなどの複雑な文書を処理し、構造化データに変換できる強力な文書解析ツールです。LlamaParseには、スタンドアロンのREST API、Pythonパッケージ、TypeScr...
包括的な紹介 UnDatas.IOは、非構造化データの解析と処理に特化したプラットフォームです。高度な技術を駆使して、ドキュメントのレイアウトを自動的に識別し、表、画像、数式、テキストを分類し、データ処理プロセスを大幅に簡素化します。このプラットフォームは、データの並べ替えにかかる時間を大幅に節約するだけでなく、...
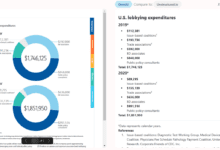
包括的な紹介 Zeroxは、ビジュアルモデルを通してPDF、DOCX、画像やその他のドキュメントをMarkdown形式に変換するために設計されたオープンソースプロジェクトです。このプロジェクトはgetomni-aiチームによって開発され、シンプルで効率的なOCR(光学式文字認識)ソリューションを提供します。ZeroxはNodeとPythonプログラミング言語をサポートし、...
一般的な紹介 SemHashは、意味的類似性によるデータセットの重複排除のための軽量で柔軟なツールである。Model2Vecの高速な埋め込み生成とVicinityの効率的なANN(近似最近傍)類似性検索を組み合わせている。SemHashは単一データセットの重複排除(例えば、トレーニング...

概要 Parseurは、PDF、電子メール、その他のドキュメントからテキストデータを自動的に抽出するために設計された、AIデータ抽出ソフトウェアのリーディングカンパニーです。Parseurを使用すると、ユーザーは簡単に非構造化データを構造化データに変換し、様々なアプリケーションに送信することができます。このソフトウェアは広く...

包括的な紹介 Weco AI Functionsは、ユーザーが迅速にAIファンクションを構築し、展開できるように設計された強力なプラットフォームです。タスクを記述するだけで、ユーザーはA/Bテストや観察モニタリングで構造化された出力パターンを生成できます。このプラットフォームは、コード不要のプロトタイピングをサポートし、技術者でないユーザーでも...

包括的な紹介 NV Ingest (NVIDIA Ingest)は、何十万もの複雑で厄介な非構造化PDFやその他の企業ドキュメントを解析するために設計された、アーリーアクセスのマイクロサービス群です。NVIDIA Ingestは、これらのドキュメントをメタデータとテキストに変換し、検索システムに埋め込むことができます。

概要 Trellisは、複雑な非構造化データソースを構造化SQLフォーマットに変換することに特化したデータプラットフォームです。Trellisは、その強力なAIエンジンを通じて、財務文書、音声通話、電子メールなどの幅広いデータソースを処理し、データチームやオペレーションチームが使用できるSQLに変換することができます...
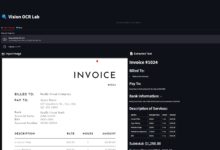
包括的な紹介 Ollama OCRは、Ollamaプラットフォームが提供する最先端の視覚言語モデルを使用して画像からテキストを抽出する、強力な光学式文字認識(OCR)ツールキットです。このプロジェクトは、Pythonパッケージとして利用できるほか、ユーザーフレンドリーなStreamlitウェブ・アプリケーション・インターフェースを提供しています。このツールキットは複数の...

 Artbreeder: 教材のための優れたイメージコントロールとイメージスタイルブレンドツール!2025-04-13
Artbreeder: 教材のための優れたイメージコントロールとイメージスタイルブレンドツール!2025-04-13 Conch Speech (MiniMax Audio): 自然な音声を生成するAIツール2025-04-08
Conch Speech (MiniMax Audio): 自然な音声を生成するAIツール2025-04-08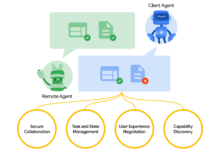 A2A:グーグル、AIインテリジェンス間の通信のためのオープンプロトコルを公開2025-04-10
A2A:グーグル、AIインテリジェンス間の通信のためのオープンプロトコルを公開2025-04-10 mcp-ui: MCPプロトコルに基づいたクリーンなAIチャットインターフェース2025-04-08
mcp-ui: MCPプロトコルに基づいたクリーンなAIチャットインターフェース2025-04-08 WeClone:WeChatのチャットログと音声を使ったデジタル・ドッペルゲンガーの育成2025-04-08
WeClone:WeChatのチャットログと音声を使ったデジタル・ドッペルゲンガーの育成2025-04-08 AstrBot:WebUIを備えたAIチャットボット・アクセス・プラットフォーム2025-04-08
AstrBot:WebUIを備えたAIチャットボット・アクセス・プラットフォーム2025-04-08