オリジナル:https://arxiv.org/abs/2409.09030
抄録
近年、大規模言語モデル(Large Language Models: LLM)は著しい成功を収め、様々な下流タスク、特にソフトウェア工学(Software Engineering: SE)領域のタスクにおいて広く利用されている。我々は、LLMとSEを組み合わせた多くの研究において、インテリゲンチャの概念が明示的または暗黙的に採用されていることを発見した。しかし、既存の研究の発展的な系譜を整理し、既存の研究が様々なタイプのタスクを最適化するためにどのようにLLMに基づく知的体の技術を組み合わせているかを分析し、SEにおけるLLMに基づく知的体の枠組みを明らかにするための詳細な研究論文は不足している。本論文では、LLM知能とSEの組み合わせに関する研究の最初のサーベイを紹介し、知覚、記憶、行動の3つの主要モジュールを含む、SEにおけるLLM知能のフレームワークを提案する。また、2つの領域を組み合わせる際に遭遇する現在の課題を要約し、それらに対処するための将来の機会を提案する。関連論文のGitHubリポジトリはこちら:https://github.com/DeepSoftwareAnalytics/Awesome-Agent4SE.
1 はじめに
近年、大規模言語モデル(LLM)は目覚ましい成功を収め、特にソフトウェアエンジニアリング(SE)領域における様々なタスクにおいて、多くの下流タスクで広く利用されている Zheng et al.アハメッドらのコードに要約されている。2024)、サンら(2023b)、ハルダーとホッケンマイアー(2024)、マオら(2024); Guoら(2023); Wangら(2021)、コード生成 Jiang et al.2023a)、胡ら(2024b)、ヤンら(2023a)、ティアンとチェン(2023)、Liら(2023e); Wangら(2024b)、コード翻訳 Pan et al.2024脆弱性の検出と修復 Zhou et al.2024)、イスラムとナジャフィラード(2024); de Fitero-Dominguezら(2024); Leら(2024)、リウら(2024b)、チェンら(2023aなど)。LLMとSEを組み合わせた研究の多くで、AI分野から明示的または暗示的にインテリジブルの概念が導入されている。明示的な使用は、その論文が直接的に知的財産に関連する技術の応用に言及していることを意味し、暗黙的な使用は、知的財産の概念は使用されているが、別の用語を使用したり、別の形で提示されている可能性があることを意味する。
インテリゲンチア・ワンら(2024c)は、知覚、推論、行動の実行が可能な知的実体を表す。環境の状態を感知し、目標や設計に基づいて行動を選択することで、特定のパフォーマンス指標を最大化し、さまざまなタスクや目標を達成するための重要な技術的基盤として機能する。LLMベースの知能は通常、LLMを知能の認知的中核として使用し、自動化、インテリジェント制御、人間とコンピュータの相互作用などのシナリオにおいて、言語理解・生成、学習・推論、文脈認識・記憶、マルチモーダリティといったLLMの強力な能力を活用して優れています。様々な分野の発展に伴い、伝統的な知能とLLMベースの知能の概念は徐々に明確になり、自然言語処理(NLP)の分野で広く使用されている。2023).しかし、既存の研究では、SEにおいてこの概念が明示的または暗黙的に使用されているものの、知的体の明確な定義はまだない。既存の研究が様々なタスクを最適化するためにどのようにインテリジェントボディの技術を組み込んでいるかを分析し、既存の研究の発展系を整理し、SEにおけるインテリジェントボディの枠組みを明確にするための詳細な研究論文が不足している。
本稿では、大規模言語モデル(Large Language Model: LLM)ベースのエージェントとソフトウェア工学(Software Engineering: SE)の組み合わせに関する研究を詳細に分析し、両者を組み合わせる際に直面する現在の課題をまとめるとともに、既存の課題に対する今後の研究の可能性を提案する。具体的には、まず、LLMベースのエージェント技術のSEへの応用に関連する論文を収集し、フィルタリングと品質評価の後、115の論文を得た。次に、従来のエージェントの定義(Wang et al.2024cXi et al.2023を参照)、SEにおけるLLMベースのエージェントの一般的な概念的枠組みを示す。 2セクション知覚、記憶、行動の3つの重要な要素を含む)。まず知覚モジュールを紹介する(セクション 2.1 セクションこのモジュールは、文字入力、視覚入力、聴覚入力など、さまざまなモダリティからの入力を扱うことができる。次に、記憶モジュールを紹介する。 2.2 セクション)、このモジュールには意味記憶、筋書き記憶、手続き記憶が含まれ、エージェントが理性的な意思決定をするのを助ける。最後に、行動モジュールを紹介する。 2.3 セクションこのモジュールには、推論、検索、学習などの内部動作と、環境との相互作用などの外部動作が含まれる。
次に、SEにおけるLLMベースのエージェントの課題と可能性について詳述する。 3セクション).具体的には、LLMエージェントがSEにおける現在の課題に対処するために、以下のような将来の研究機会を提案する:
- 既存の研究のほとんどは、トークンに基づくテキスト入力知覚モジュールを主に研究しており、他のモダリティの研究は不足している。
- 多くの新しいタスクは依然としてLLM学習の範囲外であり、SE領域における複雑なタスクは複数の能力を持つエージェントを必要とする。したがって、LLMベースのエージェントがどのように新しい役割を担い、複数の役割の能力を効果的にバランスさせることができるかを探求することが重要である。
- SEの領域には、外部検索の基礎となる、コードに関連する豊富な知識を含む権威のある認知された知識ベースが欠けている。
- LLMエージェントの錯覚を緩和することは、エージェント全体のパフォーマンスを向上させ、エージェントの最適化はLLMエージェントの錯覚問題を緩和する。
- マルチエージェントコラボレーションのプロセスでは、同期と様々な情報の共有のために、多大な計算リソースと追加の通信オーバーヘッドが必要となる。マルチエージェントコラボレーションの効率を向上させるテクニックを探求することも、今後の課題である。
- SE分野の技術は、エージェント分野の発展にも寄与するものであり、今後、SE分野の先端技術をエージェントにどのように取り込み、エージェントとSE分野の双方の発展を促進させるか、さらなる取り組みが必要である。
さらに、SEの技術、特にコードに関連する技術は、エージェントの分野も発展させることができ、この2つの全く異なる分野が相互に補強し合う関係であることを示している。しかし、SEの技術をエージェントに応用する研究はほとんど行われておらず、関数呼び出しやHTTPリクエスト、その他のツールなど、SEの単純な基本的な技術が研究の中心となっている。したがって、本稿では、SE 分野のエージェント関連の研究に焦点を当て、セクション 3.6セクション今後の研究の機会として、SE技術のエージェントへの応用について簡単に述べる。

2 大言語モデル(LLM)に基づくSEエージェント
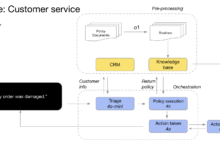
データ収集期間中に得られた研究を照合・分析した後、我々は大規模言語モデル(LLM)に基づくソフトウェアエンジニアリング(SE)エージェントのフレームワークを提案する。図に示すように 2 知覚、記憶、行動である。具体的には、知覚モジュールは外部環境からマルチモーダルな情報を受け取り、LLMが理解し処理できる入力形式に変換する。行動モジュールには内部行動と外部行動があり、それぞれLLMからの入力に基づく推論による決定と、外部環境との相互作用から得られるフィードバックに基づく決定の最適化を担う。記憶モジュールには、意味記憶、状況記憶、手続き記憶が含まれ、LLMが推論された決定を行うのに役立つ有用な情報を追加で提供することができる。また、行動モジュールは、推論と検索操作のためのより効果的な記憶情報を提供するために、行動を学習することによって、記憶モジュール内の異なる記憶を更新することができる。さらに、マルチエージェントコラボレーションは、タスクの一部を担当する複数の単一エージェントから構成され、協調協力によってタスクを完了させる。本節では、LLMベースのSEエージェントフレームワークにおける各モジュールの詳細を示す。

図2:SEにおけるエージェントフレームワークの概要。
2.1 知覚
知覚モジュールは、LLMベースのエージェントを外部環境に接続し、外部入力の処理の中心となる。このモジュールは、テキスト、視覚、聴覚などの様々なモーダル入力を処理し、LLMエージェントが理解し処理できる埋め込み形式に変換し、LLMエージェントの推論と意思決定行動の基礎を築く。次に、知覚モジュールにおける様々なモーダル入力の詳細を示す。
2.1.1 テキスト入力
自然言語処理(NLP)におけるテキスト入力形式がコードの特性を考慮するのとは異なり、SEにおけるテキスト入力形式は、次のような特性に基づいてテキストを含む。 トークン 入力、ツリー/グラフベースの入力、ハイブリッド入力がある。
トークン・ベースの入力。トークン・ベースの入力(Ahmed et al. 2024Al-Kaswan et al. 2023:: Arakelyan et al. 2023Beurer-Kellner et al. 2023:: アルカーニとアジム。 2022Li et al. 2022bGu et al. 2022Du et al. 2021これはコードを自然言語テキストとして直接扱い、トークン列をLLMへの入力として直接使用するもので、コードの特性は無視される。
ツリー/ダイアグラムベースの入力。自然言語とは対照的に、コードには厳密な構造と構文規則があり、通常は特定のプログラミング言語の構文に従って記述される。コードの特徴に基づき、ツリー/グラフベースの入力(Ma et al. 2023b, aZhang et al. 2023g:: Ochs et al. 2023Bi et al. 2024Shi et al. 2023a, 2021王と李。 2021)は、コードを抽象構文木のような木構造や、制御フローグラフのようなグラフ構造に変換し、コードに関する構造化された情報をモデル化することができる。しかし、LLMベースのSEエージェントに関する現在の研究では、このようなモダリティは検討されていない。
ハイブリッド入力。混合入力(Niu et al. 2022Hu et al. 2024aGuo et al. 2022)は、複数のモダリティを組み合わせて、異なるタイプの情報をLLMに提供する。例えば、トークン・ベースとツリー・ベースのハイブリッド入力を含めることで、コードに関する意味的情報と構造的情報を組み合わせることができ、コードのより良いモデリングと理解につながる。しかし、SEにおけるLLMベースのエージェントに関連する研究では、このモダリティはまだ検討されていない。
2.1.2 ビジュアル入力
視覚入力は、UIスケッチやUML設計図のような視覚的な画像データをモーダル入力として使用し、画像をモデル化・分析することで推論的な判断を行う。NLP関連の多くの研究がこのモダリティを探求している。例えば、Driessら(2023)は、PaLM-Eを提案している。PaLM-Eは、視覚、連続状態推定、テキスト入力エンコードと絡み合ったマルチモーダル文章を入力とする、具現化されたマルチモーダル言語モデルである。伝統的なソフトウェア工学の領域にも、UIコード検索(Behrang et al.2018Reiss et al.2014Xie et al.2019)は、有用なコード・スニペットを見つけるためのクエリーとしてUIスケッチを使用している。しかし、LLMの入力としての視覚的モデリングに関する研究はまだ少ない。
2.1.3 聴覚入力
聴覚入力は、音声などの聴覚データを入力として、音声の形でLLMと対話する。伝統的なソフトウェア工学の領域では、ビデオ検索のプログラミングなど、聴覚入力のタスクがある(Bao et al.2020)は、有用なコード・スニペットのソースとしてビデオを使用している。しかし、LLMのための聴覚入力に関する研究も比較的不足している。
2.2 メモリ
記憶モジュールには、意味記憶、状況記憶、手続き記憶があり、これらはLLMが理性的な判断を下すのに役立つ、さらなる有用な情報を提供することができる。次に、これら3種類の記憶それぞれの詳細を紹介する。
2.2.1 意味記憶
セマンティック・メモリは、LLMエージェントが認識した世界の知識を保存するもので、通常、ドキュメント、ライブラリ、API、その他の知識を含む外部知識検索リポジトリの形で保存される。多くの研究がセマンティック・メモリの応用を研究している(Wang et al.2024bZhang et al.2024エグバリとプラデル2024Patel et al.2023Zhou et al.2022レンら2023Zhang et al.2023d).具体的には、ドキュメントとAPIは、外部知識ベースで最も一般的に見られる情報である。例えば、Zhouら(2022)は、DocPromptingと呼ばれる新しい自然言語からコードへの生成法を提案した。これは、関連する文書断片を検索することによって、自然言語の意図に基づいて文書を明示的に利用するものである。2024)は、CODEAGENTBENCHと呼ばれる手動照合ベンチマークを構築し、ドキュメント、コードの依存関係、実行環境情報を含むコードベースレベルでのコード生成に特化した。2023)は、KPCと呼ばれる新しい知識駆動型プロンプトベースの連鎖コード生成アプローチを提案した。このアプローチは、LLMのコード生成を支援するために、APIドキュメントから抽出されたきめ細かい例外処理の知識を利用する。ドキュメント以外にも、APIは外部の知識ベースにおける一般的な情報でもある。例えば、EghbaliとPradel(2024)は、De-Hallucinatorと呼ばれるLLMベースのコード補完技術を提案した。この技術は、コードの接頭辞とモデルの初期予測に関連するプロジェクト固有のAPI参照を自動的に識別し、これらの参照に関する情報をヒントに追加する。2023dAPI検索ツールを生成プロセスに組み込むことで、モデルが自動的にAPIを選択し、検索ツールを使って提案を得ることができる。さらに、他の情報も扱った研究もある。例えば、Patelら(2023)は、コンテキストに基づいてコードを生成する際のさまざまなLLMの能力と限界について調べた。2024b) エンハンスメント関数とそれに対応するドキュメント文字列を使用して、選択したコードLLMを微調整する。
2.2.2 状況記憶
状況記憶には、過去の意思決定プロセスから得られた経験的情報と同様に、現在のケースに関連するコンテンツが記録される。現在のケースに関連するコンテンツ(例えば、検索データベースで見つかった関連情報、In-context learning (ICL)技術を通じて提供されたサンプルなど)は、LLMの推論に追加的な知識を提供することができるため、多くの研究がLLMの推論プロセスにこの情報を導入している(Zhong et al.2024Li et al.2023cフェンとチェン。2023Ahmed et al.2023Wei et al.2023aレンら2023Zhang et al.2023bエグバリとプラデル2024Shi et al.2022).例えば、Liら(2023c)は、AceCoderと呼ばれる新しいヒンティング技術を提案した。これは、類似のプログラムをヒントの例として選択し、ターゲットコードに関連する大量のコンテンツ(アルゴリズムやAPIなど)を提供するものである。2023)はAdbGPTを提案した。AdbGPTは学習やハードコーディングを必要としない軽量なアプローチであり、コンテキスト内学習技術を用いてエラー報告に基づいてエラーを自動的に再現する。2023)は、意味的事実を含めることで、LLMがコード要約タスクのパフォーマンスを向上させることを発見した。2023aCoeditorと呼ばれる新しいモデルは、複数ラウンドの自動コード編集セットアップにおいて、同じコードベースに対する最近の変更に基づいてコード領域への編集を予測する。さらに、過去の相互作用情報などの経験的情報を導入することで、LLMベースのエージェントがコンテキストをより良く理解し、正しい意思決定を行うことができる。過去の推論や意思決定プロセスから得た経験的な情報を利用して、繰り返しクエリを実行し、答えを修正することで、より正確な答えを得る研究もある。例えば、Renら(2023)は、知識駆動型プロンプト連鎖ベースのコード生成アプローチであるKPCを提案した。KPCは、コード生成をAI連鎖に分解し、反復的なチェック・書き換えステップを持つ。2023b)は、反復検索生成パイプラインにおいてコード補完のためにコードベースレベルの情報を効率的に利用するための、シンプルで汎用的かつ効果的なフレームワークであるRepoCoderを提案した。2024)は、LLMベースのコード補完技術であるDe-Hallucinatorを提案した。De-Hallucinatorは、ヒントの文脈情報を漸進的に増加させることによって適切なAPI参照を検索し、その予測をより正確にするためにクエリモデルを反復する。
2.2.3 手続き記憶
ソフトウェア工学におけるエージェントの手続き記憶は、ラージ言語モデル(LLM)の重みに格納された暗黙的な知識と、エージェントのコードに書かれた明示的な知識から構成される。
暗黙知はLLMのパラメータに格納される。既存の研究は通常、大量のデータを使ってモデルを訓練することで、様々な下流タスクのための豊富な暗黙知を持つ新しいLLMを提案している。2023)は、SEドメインにおけるコードのLLMを、その所属タイプ(企業、大学、研究チーム、オープンソースコミュニティ、個人、匿名の貢献者を含む)に応じて整理した。
明示的知識 エージェントのコードに記述され、エージェントが自動的に実行できるようにする。いくつかの作品、Patel et al.2023)、シンら(2023)、Zhangら(2023a)は、エージェントコードのさまざまな構築方法を研究した。具体的には、Patelら(2023)は、ライブラリ機能を指定するために、デモ、説明、実装を含む3種類のコンテクスト監督を使用している。2023)は、典型的な3つのASEタスクにおいて、微調整されたLLMを用いた3つの異なる手がかり工学的手法(すなわち、基本的な手がかり、文脈学習、タスク固有の手がかり)の有効性を調査した。 Zhangら(2023aによって、さまざまな手がかりデザイン(すなわち、基本的な手がかり、補助的な情報の手がかり、連鎖的な思考の手がかり)の使用を調査した。 チャットGPT ソフトウェアの脆弱性検出のパフォーマンス。
2.3 ムーブメント
行動モジュールは、内部行動と外部行動の2種類で構成される。外部アクションは、人間/エージェントとの対話やデジタル環境とのインタラクションなど、外部環境とインタラクションしてフィードバックを得るものであり、内部アクションは、推論、検索、学習アクションなど、LLMからの入力に基づいて推論・決定を行い、得られたフィードバックに基づいて決定を最適化するものである。次に、各アクションについて詳しく説明する。
2.3.1 内部活動
内部アクションには、推論アクション、検索アクション、学習アクションがある。別に、推論アクションは問題を分析し、推論し、LLMエージェントからの入力に基づいて意思決定を行う。検索アクションは、知識ベースから関連情報を検索し、推論アクションが正しい決定を下すのを助ける。一方、学習アクションは、意味記憶、手続き記憶、状況記憶を学習・更新することで、継続的に知識を学習・更新し、推論と意思決定の質と効率を向上させる。
推論アクション。 LLMエージェントがタスクを完了するためには、厳密な推論プロセスが重要であり、連鎖思考(CoT)は推論の効果的な方法である。CoTの助けを借りて、LLMは問題を深く理解し、複雑なタスクを分解し、高品質の答えを生成することができます。図に示すように 3 このように、既存の研究では、単純なCoT/計画、SCoT、ブレーンストーミング、ツリーCoTなど、さまざまな形のCoTが研究されている。具体的には、単純なCoT/計画とは、問題の推論プロセスを記述するプロンプトの段落である。初期の研究では、LLMがより良い問題解決のために連鎖的思考を生み出すよう導くために、プロンプトに簡単な文章が含まれていた。例えば、Huら(2024bプリントデバッグ」手法を用いたLLMデバッグを導くための文脈学習アプローチを提案する。LLM 技術の発展に伴い、CoT の設計はより複雑になっている。開発者がテストシナリオの実現可能性を検証するプロセスに触発されて、Su et al.2023)は、LLMからヒューマノイドの知識と論理的推論を抽出するために、Chain of Thought (CoT)推論を設計した。2023)は、CodeChainと呼ばれる新しいフレームワークを提案した。このフレームワークは、以前の反復で生成された代表的なサブモジュールの数によって導かれる自己修正連鎖を生成する。2024)は、実行中にコードの構文エラーを検証するためのテストケースを生成するCodeCoTを提案し、セルフチェック・フェーズを通じて、連鎖思考とコード生成のセルフチェック・プロセスを組み合わせた。2023)は、新しいプロンプト技法を提示し、洗練された思考誘導プロンプトとプロンプトに基づくフィードバックを設計し、LLMのコード生成性能を向上させる方法を初めて探求した。
このようなコードの特性を考慮し、コードの構造情報を導入する構造化CoT(Chain of Thought)を提案する研究もある。図に示すように 3 (b)に示すように、構造化CoTは、ループや分岐などの構造を含む擬似コード的な形で推論プロセスを提示する。例えば、Liら(2023a)は、ソースコードの豊富な構造情報を効果的に利用できる構造化CoT(SCoT)と、新しいコード生成ヒンティング技術であるSCoTヒンティングを提案した。2023)は、推論構造の理解を深め、AI知能の戦略に構造化推論を組み込むために、内在的および外在的機能の構築を使用する一般的なフレームワークモデルを提案している。さらに、いくつかの研究は、図に示すように、ブレーンストーミングやツリーCoTなどの他の形態のCoTを提案している。 3 (c)と(d)である。ブレーンストーミングは、入力に基づいて関連キーワードを生成することに基づいている。例えば、Liら(2023e)は、コード生成のための新しいブレーンストーミングフレームワークを提案した。このフレームワークでは、ブレーンストーミングのステップを利用してさまざまなアイデアを生成・選択し、コード生成前のアルゴリズム推論を容易にする。ツリーCoTは、FengとChen(2023)が提案されている。これは、完了ノード、新規ノード、新たに派生したノード、保留中のノードなど、様々な状態のツリー内のノードを動的に探索し、CoTを更新する。
さらに、いくつかの研究では、大規模な言語モデルに基づいて、知能の推論能力と推論効率を向上させるための他の技法が検討されている。例えば、Wangら(2024aTOOLGENは、トリガ挿入とモデル微調整フェーズ(オフライン)とツール統合コード生成フェーズ(オンライン)から構成される。TOOLGENは、ツールの自動補完をトリガする場所と特別なトークンTokenをマークする場所を推測するために、与えられたコードコーパスの拡張を利用する。2023a)は、軽量言語モデルを用いてコード生成CoTを自動生成する新しい手法COTTONを考案した。 Zhangら(2023c)は、自己推論デコーディングを提案した。自己推論デコーディングは、トークンのドラフトを生成し、これらのドラフトから出力されたトークンを、オリジナルのビグラムモデルを用いて、1回のフォワードパスで検証する新しい推論スキームである。2023)は適応的解法フレームワークを導入し、問題の難易度に応じて戦略的に解法を調整することで、計算効率を向上させるだけでなく、全体的な性能も向上させる。

図3:異なるアプローチのCoT。(a)はネイティブCoT/プランで、ビッグランゲッジモデルにキューに基づいてステップバイステップで考えさせることによって得られ、問題の分析と解決ステップの詳細なプロセスを含む。(b)は構造化CoT(SCoT)であり、コード機能を組み合わせて、ダイアグラム内の分岐構造やループ構造を含むコードフレームワークを生成する。青字の抄録は、SCoTに基づいて具体的なコードを生成する大規模な言語モデルの説明を要約したものである。(c)はブレーンストーミングの結果であり、問題の記述を分析し、アルゴリズム、データ構造、数学の知識を使用して解決策のアイデアを提供する。(d)はツリーCoTの例で、CoTを動的に探索し反復更新することで、問題を漸進的に分解し完成させる。
検索操作。検索オペレーションは、推論オペレーションが適切な判断を下せるように、知識ベースから関連情報を取り出す。検索に使用される入力と、検索によって得られる出力コンテンツのタイプは様々である。表 1 このように、入力と出力は、テキスト、コード、またはテキストとコードを含む混合メッセージのいずれかである。具体的には、以下のカテゴリに分類できる。通常、要件は、関連するコードまたは使用されるAPIを取得するための入力として使用され、応答コードを生成するためにプロンプトに追加される。例えば、Zan et al.2022a)は、APIRetrieverとAPICoderモジュールを含む新しいフレームワークを提案している。具体的には、APIRetrieverは有用なAPIを検索し、APICoderは検索されたAPIを使ってコードを生成する。2024) ヒントによって適切なAPIリファレンスを取得し、取得したヒントを使用してモデルに繰り返しクエリを実行する。(2) テキスト-テキスト。要求を入力として、タスクを完了するための関連文書や類似の質問を取得することもある。例えば、Zhou et al.2022)は、関連する文書断片を検索することで、与えられたNLの意図に明示的に応答する自然言語からコードへの生成手法であるDocPromptingを紹介した。 Zhangら(2024コードベース・レベルでの効率的なコード生成のために関連情報を取得する外部ツールを統合し、情報検索、コード・シンボル・ナビゲーション、コード・テストのためのソフトウェア成果物とのインタラクションをサポートする。(3) コード-コード。コードは、類似または関連するコードを検索するための入力として使用することもでき、ターゲットコードを生成するためのリファレンスを提供する。例えば、Zhangら(2023b)は、単純で、汎用的で、効果的なフレームワークであるRepoCoderを提案している。RepoCoderは、反復的な検索生成プロセスを使用して、類似性に基づくコードベースレベルの情報を検索する。(4) ハイブリッド・コード。関連するコードを検索するために、単一のタイプの情報(例えば、テキストやコード)を入力として使用することに加えて、検索精度を向上させるために、複数のタイプの情報をハイブリッド情報に組み合わせることができる。例えば、Liら(2022a)は、生成モデル(ピアツーピアセクションの生成)によって生成されたコードスニペットで文書クエリを補強し、コードを検索するために補強されたクエリを使用することによって、強力なコード生成モデルを利用している。2023d) オンラインの検索エンジンや文書検索ツールを使用して、APIの選択とコード生成に役立つ適切な推奨APIを入手する。また、検索は単一のタイプの情報に限定されない。(5) コード・ハイブリッド。コードを入力として使用し、様々な関連情報を検索する。例えば、Nashidら(2023)は、プロンプト作成のためのCEDARと呼ばれる新しい技術を提案した。これは、埋め込みや頻度分析に基づいて、開発者のタスクに関連するコードプレゼンテーションを自動的に検索するものである。2023)文脈学習パラダイムを使用して、コード注釈例のプールから異なるコード注釈例を選択することにより、コードに対するマルチインテント注釈を生成する。(6) テキストミキシング。要件を入力として使用し、関連するコードや類似の問題を検索して参照する。例えば、Li et al.2023b)は、LAIL (LLM-Aware In-context Learning)を提案した。LAILは、コード生成に使用する例を選択するための新しい学習ベースの選択手法である。2023c)は、AceCoderと呼ばれる新しいメカニズムを導入し、プロンプトの例として類似プログラムの需要検索を使用し、大量の関連コンテンツ(アルゴリズム、APIなど)を提供する。
以前の研究によると、Liら(2022c); Zhaoら(2024)、胡ら(2023a)、既存の検索手法はスパースサーチ、デンスサーチに分類される。2024e)、その他の方法はHayati et al.2018)、Zhangら(2020)、ポエジアら(2022)、Yeら(2021)、シュウら(2022).図. 4 はスパース検索とデンス検索のパイプラインを示す。密検索法は、入力を高次元ベクトルに変換し、意味的類似度を比較することで、最も類似度の高いk個のサンプルを選択する。 BM25 やTF-IDFのようなメトリクスを使って、サンプル間のテキストの類似性を評価することができる。さらに、様々な代替検索方法が検討されている。例えば、自然言語テキスト間の編集距離を計算することに焦点を当てた研究もある Hayati et al.2018)、あるいはコード断片の抽象構文木(AST) Zhang et al.2020)、ポエジアら(2022).また、検索に知識グラフを利用する手法もある。2021)、シュウら(2022).
密な検索手法と疎な検索手法は、最も支配的な2つの検索手法である。このうち、密な検索手法は通常、疎な検索手法よりも性能が良い。しかし、スパース検索はより効率的である傾向があり、場合によっては密な検索に匹敵する性能を達成できる。そのため、多くの研究では効率性を考慮してスパース検索法を選択している。

表1:入力と出力によって分類されたさまざまなタイプの検索操作。

図4:様々な検索手法のフローチャート。左は密検索法のフローであり、様々なモデルを用いてテキストを高次元埋め込みベクトルに変換し、意味的類似度を比較することで最も類似したサンプルを検索することができる。右はスパース検索法のフローで、テキストの類似度のみを比較し、意味的な類似度は無視する。
学習行動。学習行動とは、推論と意思決定の質と効率を向上させるために、意味記憶と手続き記憶を学習し、知識を更新し続けることである。(1)知識を用いて意味記憶を更新する。意味記憶は主に知識ベース内に存在し、基礎となる世界知識を記憶している。知識ベースは、認識されたコード知識を用いて知識ベースを更新するか、新しい知識ベースを構築することで更新できる。例えば、Liaoら(2023)は、A3-CodGenと呼ばれる新しいコード生成フレームワークを提案し、検索されたライブラリから得られる3種類の情報(現在のコードファイルからローカルに認識された情報、他のコードファイルからグローバルに認識された情報、サードパーティのライブラリ情報)を利用して、より高品質なコードを生成することを提案した。2024)は、Large Language Models (LLMs)に基づく新しい脆弱性検出技術Vul-RAGを提案し、LLMsを介して既存のCVEインスタンスから多次元知識を抽出し、脆弱性知識ベースを構築する。(2) 暗黙知の更新。暗黙知は大規模言語モデルのパラメータに格納されるため、モデルを微調整することでLLMパラメータを更新できる。これまでの研究では、事前に訓練されたモデルの微調整を監視するために新しいデータを構築し、モデルの全パラメータを更新するのが一般的であった Xia et al.2023b)、ウェイら(2023a属b); Taoら(2024); Wangら(2024d)、リウら(2023a); Wangら(2023d); Shiら(2023b).しかし、パラメー タのスケールが大きくなるにつれて、モデルの微調整にかかるコストは増大する。パラメータを効率的に微調整するテクニックを探ろうとした研究もある Weyssow et al.2023); Shiら(2023c).例えば、Weyssowら(2023)は、自動コード生成シナリオのための大規模言語モデルのためのパラメータ効率微調整(PEFT)技術に関する包括的な研究を行った。2023b)が挿入され、事前に訓練されたモデルを微調整する代わりに、効率的に微調整された構造アダプターを微調整する。現在の研究のほとんどは、モデルを微調整するために効率的な微調整技術を使用している Guo et al.2024); Shiら(2023d).
(3) エージェントコードの更新。エージェントコードとは、エージェントがその行動と意思決定プロセスを導くために実行するプログラムやアルゴリズムを指す。ビッグランゲージモデルに基づくエージェントは、適切なプロンプトをエージェントコードとして構築することで、環境の認識、推論、意思決定、操作の実行方法を制御する。多くの研究は、ビッグ・ランゲージ・モデルの出力を入力命令と整合させるために、命令整合技術を使用している。例えば、Muennighoffら(2023)は、Gitのコミットの自然な構造を利用して、コードの変更を人間の指示と対にし、それらの指示を使って調整を行う。2023b)は、大規模な言語モデルを一般的なコード編集に適応させるために設計された、最初の命令チューニングデータセットInstructCoderを構築した。これらの高品質なデータは、新しい知識をもたらし、より大きな言語モデルの意味記憶を更新することができる。2023)は、StarCoder上で8つの一般的なプログラミング言語を使って大規模な実験を行い、プログラミング言語が命令チューニングによってお互いを強化できるかどうかを探った。
2.3.2 外部活動
人間/エージェントとの対話 エージェントは人間や他のエージェントと対話することができ、対話中に豊富な情報をフィードバックとして受け取ることで、エージェントの知識を拡大し、ビッグ・ランゲージ・モデルの回答をより正確にすることができる。例えば、Lu et al.2024); Jainら(2023)、ポールら(2023); Shojaeeら(2023)、リウら(2023b); Wangら(2023e); Muら(2023); Madaanら(2023ジャインら(2023RLCFは、異なる大規模言語モデルからのフィードバックを使用して、生成されたコードを参照コードと比較し、強化学習によって事前に訓練された大規模言語モデルをさらに訓練する。2023)は、自動的なフィードバックを提供する重要なモデルと相互作用するためのフレームワークである。2023b)は、大規模言語モデルが判別モデリングからどのような恩恵を受けるかを検討し、明らかにした。2023)は、コード修復のために特別に設計された新しいデータセットを構築し、Preference-Optimised Tuning and Selection.PPOCoderによって有用なフィードバックを自動的に生成できるモデルを得るために使用した。2023)は、批評家と演奏家という2つの要素から構成され、これら2つのモデルの相互作用を通じてPPOを用いて最適化される。2023b)は、実データやコンパイラとの対話を通じて生成されたオンライン・キャッシュ・データを利用する他のモデルと相互作用し、勾配フィードバックを通じて損失を計算し、モデルの重みを更新する。2023e)は、大規模な言語モデルとのチャットによって要件を絞り込む手法であるChatCoderを提案した。2023aClarifyGPTは、コード、文書文字列、正式なコメント間の一貫性をチェックするツールである。2023)は、ユーザー入力のあいまいな要求を洗練させるために、的を絞った明確化の質問を生成するよう、別の大規模な言語モデルを促す。2023)は人間や他のエージェントと相互作用し、外部からのフィードバックを生成することができる。2023)は、教師付き学習データ、追加学習、強化学習を一切行わずに、単一の大規模言語モデルを生成、修正、フィードバック提供として使用している。2023c)は、ビッグ・ランゲージ・モデルと補完エンジンの相互作用を通じて、パッチの候補を合成する。具体的には、Repilotはビッグ・ランゲージ・モデルから提供される提案に基づいて、実行不可能なトークンを削除する。2023c)は、GPT-4でシミュレートされたユーザーからの自然言語フィードバックを用いて、多ラウンド対話タスクを解く大規模言語モデルの能力を評価できるベンチマークテストであるMINTを紹介した。2023b)は、大規模な言語モデルに基づき、効率的な人間のワークフローをマルチエージェントコラボレーションに組み込む革新的なメタプログラミングフレームワークであるMetaGPTを提案した。2023aAgentCoderは、プログラマ・エージェント、テスト設計者・エージェント、テスト実行エージェントという特殊なエージェントを持つマルチエージェント・フレームワークを含む、新しいコード生成ソリューションである。
デジタル環境 エージェントは、OJプラットフォーム、ウェブページ、コンパイラ、その他の外部ツールのようなデジタルシステムと相互作用することができ、相互作用中に得られた情報は、自分自身を最適化するためのフィードバックとして使用することができる。具体的には、コンパイラが最も一般的な外部ツールである。2023); Shojaeeら(2023)、リウら(2023b); Wangら(2022); Zhang et al.2023e).例えば、RLCF Jain et al.2023PPOCoderは、コンパイラ由来のフィードバックを使って事前に訓練された大規模な言語モデルを学習することで、生成するコードが一連の正しさチェックをパスしているかどうかをチェックする。2023)は、深層強化学習(RL)によってコード生成モデルを微調整するモデル最適化のための追加知識として、コンパイラのフィードバックと構造アライメントを組み込むことができる。2023b)はコンパイラと相互作用してトレーニングデータのペアを生成し、オンラインキャッシュに保存する。2022)は、コンパイラのフィードバックをコンパイル可能なコード生成に利用するCOMPCODERを提案した。2023e)は、大規模な言語モデルから生成されたコードの実行結果を用いて、競合プログラミングタスクのコード品質を向上させる生成・編集アプローチであるSelf-Editを提案した。さらに、知的エージェントの能力を拡張するために、検索エンジンや補完エンジンなどのツールを構築した研究も多い。2024a); Zhang et al.2024); Agrawalら(2023); Wei et al.2023c); Zhang et al.2023f王ら(2024aTOOLGENは、自動補完ツールをコードの大規模言語モデル生成プロセスに統合し、未定義変数や欠落メンバーなどの依存性エラーに対処するための手法である。2024CodeAgentは、大規模言語モデリングのための新しいエージェントフレームワークで、5つのプログラミングツールを統合し、ソフトウェアドキュメントとのインタラクションによる情報提供、コードシンボルナビゲーション、リポジトリレベルの効果的なコード生成のためのコードテストを可能にする。2023)は、モニターが静的解析を用いてデコードをガイドするモニターガイドデコーディング法であるMGDを提案した。2023c)は、ビッグ言語モデルと補完エンジンの相互作用を通じて、パッチの候補を合成する。具体的には、RepilotはCompletion Engineが提供する提案に基づいてTokenを補完する。
3 課題と機会
ソフトウェア工学における大規模言語モデル(LLM)ベースのエージェントに関する研究内容を分析した結果、これら2つの領域の統合は、その発展を制限する多くの課題にまだ直面していることが明らかになった。本節では、ソフトウェア工学におけるLLMベースのエージェントが現在直面している課題を詳細に議論し、既存の課題の分析に基づいて将来の研究の機会について議論する。
3.1 感覚モジュールの探索不足
例:No.1 2.1 節で述べたように、ソフトウェア工学における知覚モジュールのためのLLMベースのエージェントの研究は十分ではない。自然言語とは異なり、コードは特殊な表現であり、通常のテキストとして扱ったり、抽象構文木(AST)や制御フローグラフ(CFG)などのコード特徴を持つ中間表現に変換したりすることができる。Ahmed et al.2024); Al-Kaswanら(2023); Arakelyanら(2023); Beurer-Kellnerら(2023)、アルカーニとアジム(2022)コードは通常テキストとみなされ、ソフトウェア工学で働くLLMベースのエージェントにおいて、ツリー/グラフィカルベースの入力モダリティを探求する研究はまだ不足している。さらに、視覚と聴覚の入力モダリティもまだ十分に研究されていない。
3.2 ロールプレイング・スキル
LLMベースのエージェントは、しばしば様々なタスクで異なる役割を果たすことを要求され、それぞれが特定のスキルを必要とする。例えば、エージェントは、コードを生成するように要求されたときにはコードジェネレータとして、コードテストを実行するときにはコードテスターとして動作する必要があるかもしれない。さらに、シナリオによっては、エージェントは一度に複数の能力を持つ必要がある。例えば、コード生成シナリオでは、エージェントはコードジェネレータとテスタの両方として動作する必要があるため、コードを生成しテストする能力を持つ必要がある(Huang et al. 2023b).ソフトウェア工学の領域では、LLM学習では不十分なニッチタスクや、テスト生成シナリオ、フロントエンド開発、リポジトリレベルの問題解決など、エージェントに複数の能力を要求する複雑なタスクが数多く存在する。したがって、エージェントが新しい役割を効果的に採用し、マルチロールパフォーマンスの要求を管理できるようにする方法に関する研究を進めることは、今後の研究の有望な方向性を示している。
3.3 不十分な知識検索ベース
外部知識検索ベースは、エージェントの記憶モジュールにおける意味記憶の重要な一部であり、エージェントが対話できる重要な外部ツールである。自然言語処理(NLP)の分野では、外部検索ベースとしてウィキペディアのような知識ベースがある(Zhao et al. 2023).しかし、ソフトウェア工学の分野では、様々なプログラミング言語の基本構文、一般的に使用されるアルゴリズム、データ構造やオペレーティングシステムに関する知識など、コードに関連する豊富な知識を含む権威ある知識ベースは存在しない。将来の研究では、エージェントの外部検索の基礎として使用できる、包括的なコード知識ベースを開発する努力がなされるであろう。この知識ベースは、利用可能な情報を充実させ、推論と意思決定プロセスの質と効率を向上させる。
3.4 LLMベースのエージェントにおける幻想現象
LLMベースのエージェントに関連する多くの研究は、LLMをエージェントの認知的中核と見なしており、エージェントの全体的な性能は、基礎となるLLMの能力と密接に関係している。既存の研究(Pan et al. 2024Liu et al. 2024a)は、LLMベースのエージェントが、ソフトウェアエンジニアリングタスクを完了する際に、存在しないAPIを生成するような幻覚を引き起こす可能性があることを示唆している。同時に、エージェントの最適化は、LLMベースのエージェントの幻覚を逆に軽減することができ、エージェントの性能と幻覚軽減の間の双方向の関係を強調している。LLMにおける幻覚現象についてはいくつかの研究があるが、LLMベースのエージェントにおける幻覚に対処するには大きな課題が残っている。LLMベースのエージェントに存在する幻覚のタイプを探求し、これらの幻覚の原因を深く分析し、幻覚緩和の効果的な方法を提案することは、今後の研究の重要な機会である。
3.5 マルチインテリジェンス・コラボレーションの効率性
マルチインテリジェンス・コラボレーションでは、特定のタスクを遂行するために個々のインテリジェンスがそれぞれ異なる役割を果たすことが求められ、その後、各インテリジェンスの判断結果が組み合わされて、より複雑な目標に共に取り組むことになる Chen et al.2023b); Hongら(2023a)、黄ら(2023b); Wangら(2023a).しかし、このプロセスは通常、各インテリジェンスに大量の計算リソースを必要とするため、リソースの浪費と効率の低下につながる。さらに、個々のインテリジェンスは様々な情報を同期して共有する必要があるため、通信コストが追加され、コラボレーションのリアルタイム性と応答性に影響する。計算リソースの効率的な管理と割り当て、インテリジェンス間の通信コストの最小化、個々のインテリジェンスの推論オーバーヘッドの削減は、マルチインテリジェンスコラボレーションの効率を向上させる上で重要な課題です。これらの課題に取り組むことは、今後の研究に大きな機会を提供する。
3.6 大規模言語モデルに基づくインテリジェンシアへのソフトウェア工学技術の適用
ソフトウェア工学分野の技術、特にコーディングは、インテリジェント分野を大きく発展させる可能性を秘めており、両分野が相互に有益な関係にあることを示唆している。例えば、ソフトウェアのテスト技術は、大規模な言語モデルに基づいて、インテリジェンティアの異常な動作や潜在的な欠陥を特定するために適応させることができる。さらに、ソフトウェアツール(APIやライブラリなど)の改善も、大規模言語モデルに基づくインテリジェンティアのパフォーマンスを向上させることができ、特にツールを使用する機能を持つインテリジェンティアのパフォーマンスを向上させることができる。さらに、インテリジェント・ボディ・システムを効率的に管理するために、パッケージ管理技術を適応させることができる。例えば、インテリジェント・ボディ・システム内の異なるインテリジェンスのアップデートを監視・調整するためにバージョン管理を適用し、互換性とシステムの完全性を高めることができる。
しかし、この分野の研究はまだ限られている。したがって、より複雑なSE技術をインテリジェントな身体システムに組み込むことを探求することは、両分野の進歩を促進する可能性のある、今後の研究の有望な方向性を示している。
4 結論
大きな言語モデルベースの知能をソフトウェア工学と組み合わせる研究を深く分析するために、まず、大きな言語モデルベースの知能をソフトウェア工学分野のタスクと組み合わせる多くの研究を収集した。そして、データ収集期間中に得られた研究を照合・分析した後、知覚、記憶、行動の3つの重要なモジュールを含む、ソフトウェア工学における大きな言語モデルベースの知能のフレームワークを提示する。最後に、フレームワークの各モジュールに関する詳細な情報を提示し、ソフトウェア工学における大規模言語モデルベースのインテリゲンチャが直面している現在の課題を分析し、今後の研究の可能性を指摘する。