はじめに
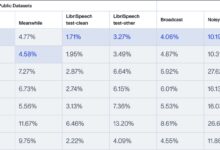
PengChengStarling (PengCheng Labs)は、多言語の自動音声認識(ASR)ツールで、異なる言語の音声を対応するテキストに変換することができる。icefallプロジェクトに基づいて開発されたこのツールキットは、データ処理、モデル学習、推論、微調整、デプロイメントを含む完全な音声認識プロセスを提供する。pengChengStarlingは、中国語、英語、ロシア語、ベトナム語、日本語、タイ語、インドネシア語、アラビア語を含む8言語のストリーミング音声認識をサポートしている。主な用途は、音声アシスタント、翻訳ツール、字幕生成、音声検索などです。モデルサイズはWhisper-Large v3の20%で、推論速度はWhisper-Large v3の7倍です。
特徴は、統一されたフレームワークで多言語の音声入力を処理できること、リアルタイムの音声認識をサポートしていること、話しながら認識できること、国際会議の録音をテキスト化できること、多言語ビデオで自動的に字幕を生成できること、多言語カスタマーサービスシステムであること、などである。

機能一覧
- データ処理:複数のデータセットの前処理をサポートし、必要な入力フォーマットを生成。
- モデルトレーニング:多言語音声認識タスクをサポートするための柔軟なトレーニング設定を提供します。
- 推論:ストリーミング音声認識をサポートした効率的な推論速度。
- 微調整:特定のタスク要件に合わせてモデルの微調整をサポートします。
- デプロイメント: モデルを簡単にデプロイできるように、PyTorchとONNX形式で提供します。
ヘルプの使用
設置プロセス
- クローン・プロジェクト・ウェアハウス
git clone https://github.com/yangb05/PengChengStarling
cd PengChengStarling
- 依存関係をインストールします:
pip install -r requirements.txt
export PYTHONPATH=/tmp/PengChengStarling:$PYTHONPATH
データ準備
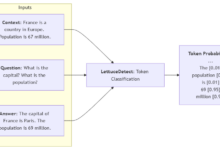
学習プロセスを開始する前に、まず生データを目的の入力フォーマットに前処理する必要がある。通常、これはzipformer/prepare.py正鵠を得るmake_*_listメソッドを使用してデータリストファイル。スクリプトが完了すると、各データセットに対応するカットとfbankフィーチャーが生成され、PengChengStarlingの入力データとして使用される。
モデルトレーニング
- トレーニング・パラメーターの設定
コンフィグ・トレインディレクトリでトレーニングに必要なパラメーターを設定する。 - トレーニングを開始する:
./train.sh
推論
- 推論データの準備:データを目的の形式に前処理する。
- 推論を始める:
./eval.sh
微調整
- 微調整されたデータを準備する:データを目的の形式に前処理する。
- 微調整を開始する:
./train.sh --finetune
展開
PengChengStarlingはPyTorchの状態辞書とONNX形式の2つの形式でモデルを提供します。あなたのニーズに応じて、適切なフォーマットを選択することができます。