o3が個人的な洞察をお伝えします。テストタイムについて スケーリングの法則 私たちが考えていたよりもずっと早く、前進している。AGIを追求するOpenAIのやり方が曲者なのだ。
集中学習と近道思考
なぜそうなのか?つの例を通して探ってみよう。
最初の例は強化学習である。RLでは、割引係数が重要な役割を果たす。これは、意思決定のステップが進めば進むほど、得られる報酬が徐々に減少することを意味する。したがって、強化学習の目標は通常、可能な限り短い時間と少ないステップで報酬を最大化することである。この戦略の核心では、「近道」、つまり報酬をできるだけ早く得ることに重点が置かれている。
2つ目の例は、大規模なモデルを微調整するプロセスである。ファインチューニングされていない学習済みモデルは、しばしば明確な方向性や制御ができない。モデルに "中国の首都はどこですか?"と尋ねると、まず "いい質問ですね "と言うかもしれない。と尋ねると、モデルはまず「いい質問だ」と答え、それから脱線して、最終的に「北京」という答えを出すかもしれない。しかし、微調整されたモデルに同じ質問をすると、答えはストレートで明確だ。
この微調整されたモデルは、最適化戦略によって近道を手に入れる方法を示している。それは人間の進化の道程に似ており、常に最小限のエネルギー消費と最短経路を目指している。
なぜ推論なのか?
推理のサンプリングプロセスをツリーに見立てたとしよう:

O1レプリケーションの旅:パート1
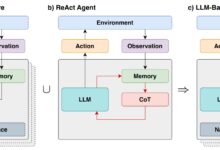
左側は、私たちが過去に追求してきた近道学習:正しい結果を得るための最小限のステップ。右側は、OpenAI o1に代表される「内省的、回顧的」パラダイムである。
o1が検索を実行するとき、モデルは常に反映とバックトラックを繰り返し、このプロセスはしばしば追加のオーバーヘッドを伴うことを知っています。問題なのは、モデルが実際に何度も何度も正しい答えを出すことができるのであれば、誰が複雑な検索に時間とお金を費やしたいと思うだろうか、ということだ。OpenAIはバカではないし、近道がより良いことは誰もが知っている!
問題が難しければ難しいほど、潜在的なアイデアのツリーは広くなり、各ステップでの探索スペースは広がり、近道が正解につながる可能性は低くなる。ではどうすればいいのか?直感的に考えるには、枝刈りをすることだ!先に終点に到達しそうもない木のノードを切り落として探索空間を圧縮し、木を狭いものに戻す。例えば、現在の多くの取り組みがこれを試みている:

選好最適化の連鎖(CPO)
選好最適化の連鎖とは、思考ツリーから選好データを自然に構築し、DPOを使って最適化することで、モデルが終点に到達するツリーノードを選択する確率を高くすることである。

アウトカム教師付きバリュー・モデル(OVM)
アウトカム監視価値モデルは、推論をMDPプロセスとしてモデル化するもので、現在のステップで正しい答えに到達する確率(価値)が、戦略の最適化を導くために使用される。
なぜOpenAIは従来の近道を選んだのか?
o1の話に戻りますが、なぜ従来の近道という考えを打ち破り、ツリー検索という「回り道」を選んだのですか?
過去において、(Exploit)モデルの基本的な能力を利用する傾向があったとすれば、既存のGPT-4モデルは対話と単純な推論のニーズのほとんどを満たすことができたと考えられる。そして、これらのタスクは、よくサンプリングされ、プリファレンスが評価され、反復的に最適化される。
しかしこの視点は、数学的推論(AIME、Frontier Math)、コード生成(SWE-Bench、CodeForce)など、より複雑なタスクの必要性を無視している。-その報酬は非常にまばらで、最終的に正しい答えに到達して初めて報酬が明らかになる。
その結果、従来の近道学習は、この種の複雑なタスクに対処するのにはもはや適さない。正しい経路をサンプリングすることさえできないのに、モデルが正しい経路を選択する確率を最適化しようなどということができるだろうか?
本稿のタイトルにある「モンテカルロのアイデア」に戻ると、これは実は同じことであることがわかる。強化学習に対するモンテカルロ・アプローチの核心は、複数回のサンプリングによってポリシーの値を推定し、モデルを最適化することにある。しかし、このアプローチには自然な限界がある。サンプリングされたポリシーが最適なパスをサンプリングできなければ、モデルの最適化は常に局所最適で終わってしまう。これが、MCラーニングでより探索的な戦略を選択する理由である。
そこでOpenAIは、従来の近道思考から強化探索(Explore)に移行することで、強化学習のスケールを打ち破ることを選んだ。
o1 ブレークスルー:探査から最適化へ
そこでOpenAIはo1パラダイムを提案した。この変更により、モデルは複雑なタスクに直面したときに、徐々にまばらな報酬を得るようになる!そしてこれらの報酬を通じて、戦略を継続的に最適化することができる。この探索のプロセスは面倒で非効率的に見えるかもしれないが、モデルのさらなる最適化の基礎を築くものである。
では、o1はどこから来たのか?最近、o1を再現する研究も多く登場しているが、彼らは何をしているのだろうか?探索に使われる行動方針がオンポリシー・アプローチだとすると、現在のモデル(GPT-4oなど)とのサンプリングになるが、これはやはり効率が悪すぎる。
そこで彼らは全員一致でオフ・ポリシー方式を選択した:
OpenAIは、Long CoTのデータに注釈を付けるために博士課程の学生を雇うために多額の資金を費やしている。お金がなければどうすればいいのか? それなら、人間と機械が協力してデータに注釈を付ければいい(手作業でo1を抽出する)。それなら、R1 / QwQを抽出するか、他の方法(Critique、PRMなど)を考えるしかない。 また、o1を積極的に再現している大手メーカーや研究所には、探査の最終目標は依然として最適化であることを忘れないでほしいと思います!
余談だが、o1が真の思考の連鎖を隠し、サマリーのショートカット版しか見せていないことを皆が非難している一方で、サマリーが最適化戦略の鍵となるデータであることは明らかではない。サマリーは戦略を最適化するための重要なデータなのだ!というのも、これらのデータを抽出するためのもう1つの前提条件、つまり基礎となるモデルが十分に強固であることが必要だからです。
OpenAIはまた、探索のコストをユーザーに転嫁している。初期段階で探索的データにアノテーションを付けるには多くのコストがかかるが、o1では、ユーザーが利用する過程で、必ずユーザーにより多くのデータがアノテーションされる!
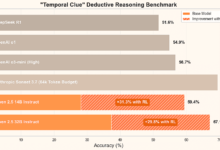
o1からo3への急速な進化
o1は数ヶ月前に発売されたばかりだが、ここにきてo3が登場した。
GPT-4が0から1への進歩、すなわち単純なタスクから報酬を得ることを表しているとすれば、o1は1から10への飛躍を表している。これは、さらなる戦略の最適化のために、かつてない量の高品質なデータを提供することになる。
そのため、誰もが予想していたよりも早く進展している:

これは探索戦略の応用に成功しただけでなく、AGIに向けたAI技術の重要な一歩でもある。